Spring Bean 的生命周期
Spring Bean 的生命周期涉及到 Spring 框架中对象的创建、初始化、使用和销毁等关键过程。
在Spring框架中,Bean的生命周期经历以下几个阶段:
1)实例化: Spring 根据配置文件或注解等方式创建 Bean 实例,并将其存储在容器中。
2)属性赋值: Spring 自动将Bean的属性值从配置文件或注解等方式中注入到 Bean 实例中。
3)初始化: Spring 调用 Bean 实例的 init-method方法,完成一些初始化的操作,例如建立数据库连接等。
4)使用: Bean 实例已经可以正常使用,供应用程序调用。
5)销毁: Spring 调用 Bean 实例的 destroy-method 方法,完成一些资源的释放和清理操作,例如关闭数据库连接等。
Bean生命周期详解
1)解析类得到 BeanDefinition。
2)如果有多个构造方法,则推断构造方法。
3)确定好构造方法后,进行实例化得到一个对象。
4)对对象中加了 @Autowired 注解的属性进行属性填充。
5)回调 Aware 方法,如 BeanNameAware,BeanFactoryAware。
6)调用 BeanPostProcessor 的初始化前的方法。
7)调用初始化方法。
8)调用 BeanPostProcessor 的初始化后的方法,在这里进行 AOP。
9)如果当前创建的 Bean 是单例的,则会把 Bean 放入单例池里。
10)使用 Bean。
11)Spring 容器关闭时调用 DisposableBean 中的 destroy() 方法。
Bean作用域
Spring 框架提供了以下几种常见的 Bean 作用域:
1)Singleton(单例): Spring 默认的作用域。在 Singleton 作用域下,Spring 容器只会创建 Bean 的一个实例,并在整个应用程序的生命周期内都共享这个实例。
2)Prototype(原型): 每次请求该 Bean 时,Spring 容器都会创建一个新的实例,并返回该实例。即每次调用 getBean() 方法时都会返回一个新的 Bean实例。适用于那些需要状态的 Bean,例如控制器对象、线程安全的对象等。
3)Request(请求): 在 Web 应用中,每个HTTP请求都会创建一个新的 Bean 实例。该作用域仅在 Web 环境中有效,用于在每个 HTTP 请求处理期间创建新的Bean 实例。适用于那些需要在每个请求中保持状态的 Bean。
4)Session(会话): 在 Web 应用中,每个用户会话都会创建一个新的 Bean 实例。该作用域仅在 Web 环境中有效,用于在每个用户会话期间创建新的 Bean 实例。适用于那些需要在整个会话期间保持状态的 Bean。
5)Global Session(全局会话): 该作用域仅在基于 portlet 的 Web 应用中有效。在 portlet 环境中,每个全局会话都会创建一个新的 Bean 实例。
其他补充
在 Spring 框架中,Bean 的生命周期指的是在容器中创建、初始化、使用和销毁 Bean 的整个过程。Spring 容器负责管理 Bean 的生命周期,主要包括以下几个阶段:
-
实例化:容器根据配置信息或者注解创建 Bean 的实例。
-
属性设置:容器将 Bean 的属性值注入到 Bean 实例中,包括通过构造函数注入、属性的注入或者其他特定的注入方式。
-
初始化:在 Bean 实例化并设置好属性之后,Spring 容器可以调用特定的初始化方法进行一些额外的初始化工作。这个初始化方法可以通过 XML 配置文件中的 init-method 属性或者注解中的
@PostConstruct来指定。 -
使用:此时 Bean 已经完全初始化,可以被应用程序使用了。
-
销毁:当容器关闭时,或者通过编程的方式销毁 Bean 时,容器会调用 Bean 的销毁方法进行资源的释放和清理工作。这个销毁方法可以通过 XML 配置文件中的destroy-method 属性或者注解中的
@PreDestroy来指定。
强调以下几点:
1)Aware 回调方法: 在 Bean 实例化后,Spring 会调用一些 Aware 接口中的方法,如 BeanNameAware、BeanFactoryAware 等,让 Bean 可以感知到自己的一些环境信息或容器的存在。
2)BeanPostProcessor 的作用: BeanPostProcessor 接口提供了在 Bean 实例化之后和初始化之前以及初始化之后的回调方法,允许开发者在 Bean 初始化的不同阶段进行一些自定义的操作,例如 AOP 功能就是通过 BeanPostProcessor 实现的。
3)DisposableBean 和 InitializingBean 接口: 这两个接口分别定义了在 Bean 销毁前和初始化后的操作方法。通常情况下,建议使用注解方式 (@PostConstruct 和 @PreDestroy) 来替代这两个接口,因为注解方式更加灵活和方便。
4)Bean 作用域的选择: 在使用 Bean 时,要根据实际需求选择合适的作用域。Singleton 适用于那些无状态的 Bean,Prototype 适用于有状态的 Bean,而 Request 和 Session 则适用于 Web 应用中需要保持状态的 Bean。Global Session 则适用于特定的 Web 环境。
5)Spring 容器管理 Bean 生命周期的好处: Spring 容器负责管理 Bean 的生命周期,使得开发者可以专注于业务逻辑而不用关心对象的创建、初始化和销毁过程,同时也提供了灵活的扩展机制,可以通过各种扩展点来实现自定义的逻辑。
1)确保 Bean 的正确实例化和初始化:
- 使用依赖注入(Dependency Injection, DI):通过注入的方式,将依赖关系从程序代码中解耦,由容器负责注入,确保 Bean 正确地被实例化和初始化。
- 定义合适的构造函数和初始化方法:在 Bean 的定义中指定构造函数和初始化方法,容器会调用这些方法来创建和初始化 Bean。
- 利用注解或 XML 配置:通过注解(如 `@Autowired`、`@PostConstruct`)或在 XML 文件中配置 Bean 的属性和初始化方法,确保 Bean 按预期初始化。
- 使用 Bean 的生命周期回调方法:Spring 提供了多种生命周期回调方法,如 `init-method` 和 `destroy-method`,可以在 Bean 的生命周期中特定时刻执行自定义逻辑。
2)Bean 的生命周期中可能存在的安全风险:
- 实例化阶段:如果 Bean 的构造函数或其他初始化方法不安全,可能会引入安全漏洞。
- 属性填充阶段:如果属性注入不正确或被篡改,可能导致安全风险。
- 初始化阶段:自定义初始化方法可能引入安全漏洞。
- 使用阶段:Bean 在运行时可能被不当使用,例如方法被未授权调用。
- 销毁阶段:如果销毁方法不安全,可能会导致资源泄露或数据完整性问题。
3)加强对 Bean 生命周期的管理和监控:
- 配置文件安全:确保配置文件(如 XML 或 properties 文件)的安全,防止未授权访问和修改。
- 使用安全的依赖注入:避免使用不安全的依赖注入方法,如基于类的自动装配,而应使用基于注解的精确控制。
- 监控和审计:通过日志记录、审计和监控工具跟踪 Bean 的生命周期事件,及时发现异常行为。
- 限制 Bean 的作用域:根据需要设置 Bean 的作用域(如 singleton、prototype),以控制其生命周期和可见性。
- 安全的销毁方法:确保 Bean 的销毁方法正确释放资源,避免资源泄露。
- 使用安全框架和库:利用现有的安全框架和库,如 Spring Security,来增强 Bean 的安全性。
- 定期安全审查:对 Bean 的实现和配置进行定期安全审查,确保没有新的安全漏洞被引入。
如何防止接口重复请求?
1、 请求队列:维护一个请求队列,每次发送请求前检查队列中是否已经存在相同的请求。如果存在相同请求,则不再发送,直接使用队列中的请求结果。这种方法可以确保相同请求只发送一次。
class RequestQueue {
constructor() {
this.queue = {};
}
addRequest(url, callback) {
if (this.queue[url]) {
// 如果队列中已有相同请求,则直接使用之前的请求结果
this.queue[url].callbacks.push(callback);
return;
}
this.queue[url] = {
callbacks: [callback],
// 假设这里使用fetch进行请求
promise: fetch(url).then(response => {
const data = response.json();
this.queue[url].callbacks.forEach(cb => cb(data));
delete this.queue[url]; // 请求完成后从队列中移除
})
};
}
}
// 使用
const queue = new RequestQueue();
queue.addRequest('https://api.example.com/data', data => {
console.log(data);
});
2、 请求取消:在发送请求前,记录当前正在进行的请求,并在发送新请求时先取消之前的请求。可以使用 Axios 等库提供的取消请求功能来实现。
import axios from 'axios';
let cancelTokenSource;
function fetchData() {
if (cancelTokenSource) {
cancelTokenSource.cancel('Operation canceled by the user.'); // 取消之前的请求
}
cancelTokenSource = axios.CancelToken.source();
axios.get('https://api.example.com/data', {
cancelToken: cancelTokenSource.token
}).then(response => {
console.log(response.data);
}).catch(function (thrown) {
if (axios.isCancel(thrown)) {
console.log('Request canceled', thrown.message);
} else {
// 处理错误
}
});
}
// 调用fetchData时会取消之前的请求(如果存在)
fetchData();
3、 防抖(Debounce):使用防抖函数控制请求的发送频率,确保在一段时间内只发送一次请求。这样可以避免频繁的重复请求。
4、 节流(Throttle):与防抖类似,节流函数可以控制一段时间内请求的频率,但不会像防抖那样在每次触发事件后立即执行,而是在固定间隔内执行一次。
5、 请求标识:为每个请求设置唯一标识,当新请求到来时,先检查是否存在相同标识的请求,如果存在则不发送新请求。
6、 缓存请求结果:对于相同的请求,在第一次请求返回结果后将结果缓存起来,后续相同的请求可以直接使用缓存的结果,而不再发送重复请求。
7、 使用状态管理库:在 Vue 应用中,可以结合状态管理库(如 Vuex、Pinia)来管理请求状态,确保只有一个请求在进行,避免重复请求。
// Vuex store配置
const store = new Vuex.Store({
state: {
isFetching: false,
data: null
},
mutations: {
FETCH_START(state) {
state.isFetching = true;
},
FETCH_END(state, data) {
state.isFetching = false;
state.data = data;
}
},
actions: {
fetchData({ commit }) {
if (this.state.isFetching) {
return; // 如果已经在请求数据,则不再发送新请求
}
commit('FETCH_START');
return fetch('https://api.example.com/data').then(response => {
return response.json();
}).then(data => {
commit('FETCH_END', data);
return data;
});
}
}
});
// 在Vue组件中使用
this.$store.dispatch('fetchData').then(data => {
console.log(data);
});假如有几十个请求,如何控制并发?
什么是并发
并发(Concurrency)是指在同一时间段内执行多个任务的能力。
在单核处理器上,并发任务会快速切换执行,从而使得多个任务看起来同时运行;而在多核处理器上,并发任务则可以真正地同时执行。
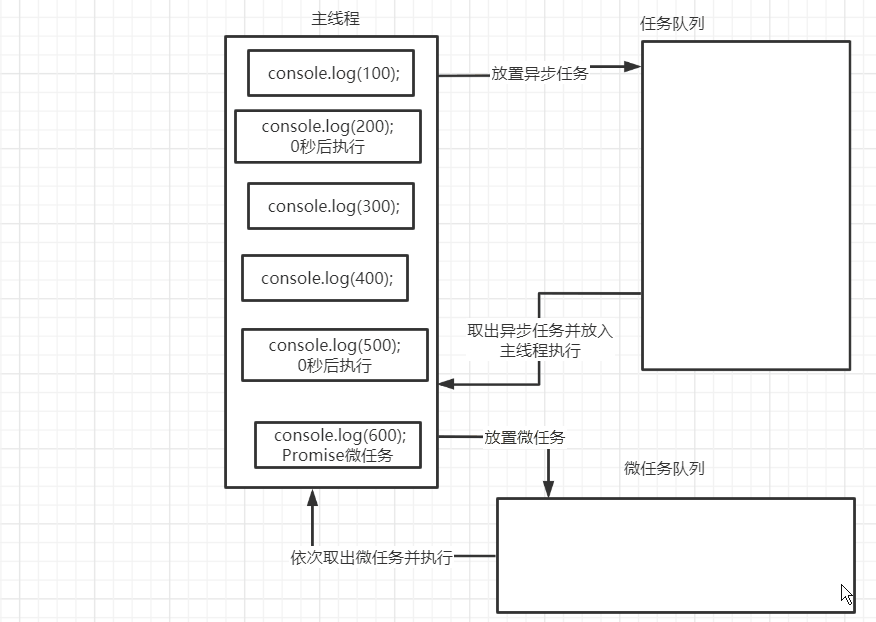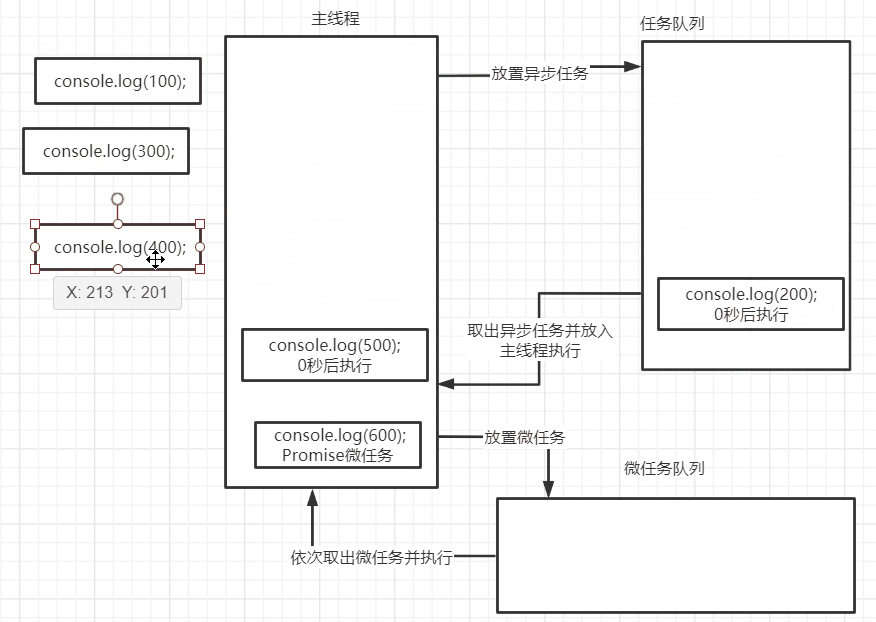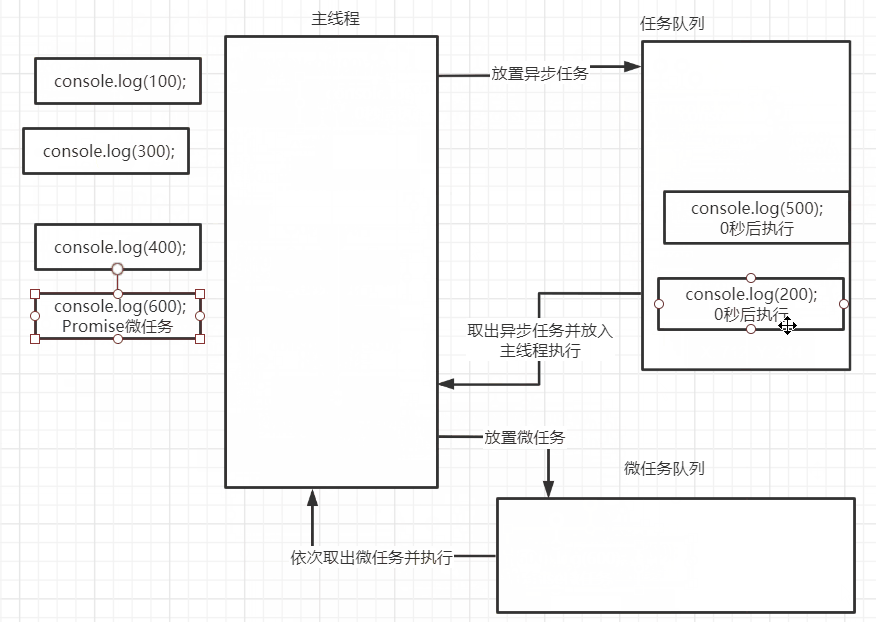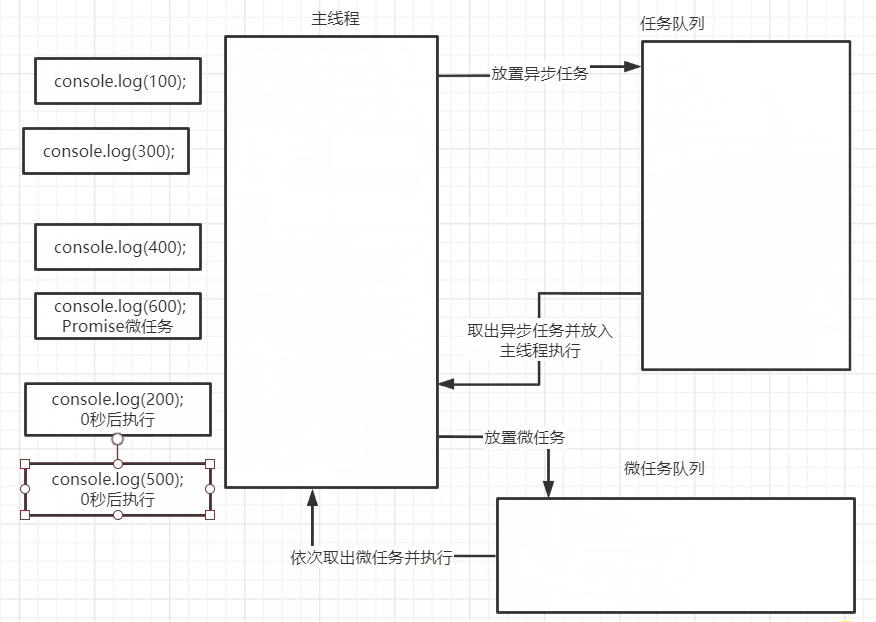
为什么需要控制并发
虽然并发可以提高程序的效率和响应速度,但如果不加以控制,很容易造成资源竞争、死锁、系统过载等问题。
因此,在处理大量并发请求时,必须合理地控制并发数量,以保证系统的稳定性和性能。
常见的并发控制方法
常见的并发控制方法包括:
-
限流(Rate Limiting):限制在一定时间内允许通过的请求数量。
-
信号量(Semaphore):使用信号量来控制并发执行的数量。
-
队列(Queue):使用队列将请求按顺序排队处理。
-
线程池(Thread Pool):使用线程池来限制并发执行的线程数量。
使用 JavaScript 实现并发控制
Promise.all 示例
在 JavaScript 中,可以使用 Promise.all 来处理多个并发请求。以下是一个简单的示例:
const fetch = require('node-fetch');
const urls = [
'https://jsonplaceholder.typicode.com/posts/1',
'https://jsonplaceholder.typicode.com/posts/2',
'https://jsonplaceholder.typicode.com/posts/3',
// ... 更多 URL
];
Promise.all(urls.map(url => fetch(url).then(response => response.json())))
.then(results => {
console.log('所有请求完成:', results);
})
.catch(error => {
console.error('请求失败:', error);
});并发限制示例
使用 Promise.all 时,如果请求数量非常多,可能会导致资源耗尽问题。可以通过自定义并发控制函数来限制并发请求的数量。以下是一个示例:
const fetch = require('node-fetch');
const urls = [
'https://jsonplaceholder.typicode.com/posts/1',
'https://jsonplaceholder.typicode.com/posts/2',
'https://jsonplaceholder.typicode.com/posts/3',
// ... 更多 URL
];
function limitConcurrency(urls, limit) {
const results = [];
const executing = [];
async function enqueue() {
if (urls.length === 0) return Promise.resolve();
const url = urls.shift();
const promise = fetch(url).then(response => response.json());
results.push(promise);
const e = promise.then(() => executing.splice(executing.indexOf(e), 1));
executing.push(e);
let r = Promise.resolve();
if (executing.length >= limit) {
r = Promise.race(executing);
}
await r;
return enqueue();
}
return enqueue().then(() => Promise.all(results));
}
limitConcurrency(urls, 2)
.then(results => {
console.log('所有请求完成:', results);
})
.catch(error => {
console.error('请求失败:', error);
});总结
合理地控制并发不仅可以提高程序的效率,还能保证系统的稳定性和安全性。
手机扫码登录实现原理
1、手机登录和PC登录的原理
1.1 手机登录原理

(a)用户在手机客户端上输入账号和密码并且携带设备信息一起请求服务器
(b)服务器接收到请求后,验证用户的账号和密码是否正确,如果不正确则给予异常的提示;如果正确就生成token给客户端
(c)手机客户端通过携带token和设备的信息的方式请求服务器,服务器验证token是否有效,token有效的情况下验证是否为之前申请登录的客户端设备,如果不是之前申请登录的设备也不允许访问服务器
手机登录中需要携带设备的信息是为了防止token泄露后,攻击者使用其他的设备携带当前的token访问服务器资源。
1.2 PC登录原理
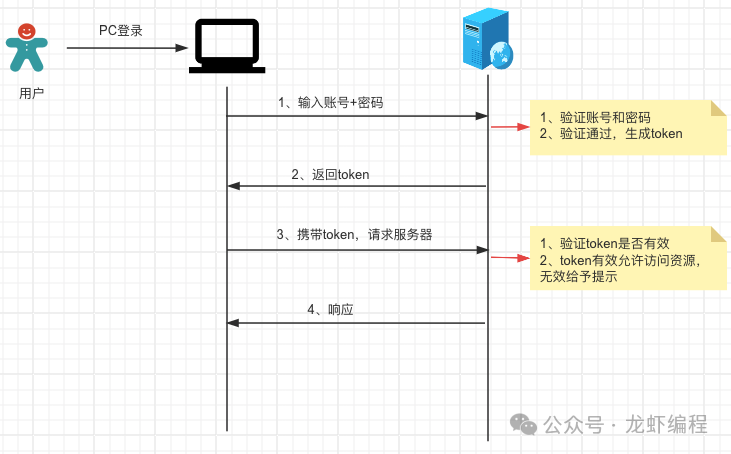
(a)PC端输入账号和密码请求登录服务器
(b)服务器接收到请求后,验证用户的账号和密码是否正确,如果不正确则给予异常的提示;如果正确就生成token给客户端
(c)PC端携带token请求访问服务器,服务器验证token是否有效,token有效可以处理请求并返回响应
2、手机扫码登录的原理
手机扫码登录的实质是通过已经在APP上登录的用户帮助PC端的应用到服务器上申请pc-token,拿到pc-token后就和PC端登录服务器的原理一样了。手机扫码登录的完整流程如下:

2.1 生成二维码

用户打开PC端的应用后PC端会向服务器申请二维码Id,服务器此时会生成一个唯一的二维码Id,然后服务器将二维码Id、二维码过期时间等信息存放Redis中并且返回二维码Id给PC端。
PC端获取到二维码Id后利用其生成一个用户可扫描的二维码,当然PC端需要监听到二维码的状态变更信息(服务器上对二维码的变更操作需要实时的通知PC端)。
2.2 用户扫描二维码
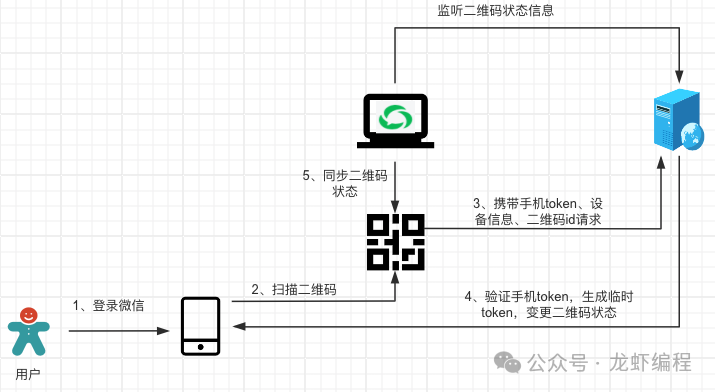
生成二维码之后,用户使用手机上已登录的APP扫描这个二维码,扫描后会发送一个携带手机token、设备信息和二维码id的请求访问服务器。
当服务器接收到登录请求后会验证手机token的有效性,如果手机token是有效的并且token也是当前的设备申请的,此时服务器会生成一个临时的token并修改二维码的状态为等待用户确认登录的状态,然后返回token信息给手机客户端,手机客户端此时会弹出用户确认的按钮。与其同时服务器会通知客户端当前的二维码状态处于等待用户确认登录的状态。
2.3 用户手机上确认登录

用户在手机上点击确认登录后会发送一个携带临时token的请求到服务器上,服务器验证临时token是否有效,如果临时token是有效的,服务器就会生成一个pc-token以及修改二维码的状态为登录状态的一系列操作。服务器将pc-token和二维码状态等信息缓存到Redis中,然后服务器还要推送pc-token和二维码变更信息到PC端,PC端感知到二维码状态变更之后就隐藏二维码和跳转到主页中。
通过以上的步骤就是实现了一套完整的手机扫码登录流程,在这个过程中每次的二维码信息变更都是服务器推送给PC客户端的,那么服务器如何做到推送数据给PC客户端呢?这里实现服务器和客户端通信的方案有很多种,如常见有WebSocket、SSE和客户端轮询等方案。
整理常见的实时消息推送方案
总结:
(1)手机扫码登录中二维码的状态变更涉及到服务器和客户端之间的通信问题,有多种实现方案
(2)手机扫码登录中核心是已在APP上登录的用户使用APP帮助PC客户端拿到服务器颁发的pc-token来实现PC端的登录
大文件的断点下载、分片下载

如果内存只有4G内存,此时资源就下载不下来,并且由于下载占用了大部分的内存资源进而整个服务因为内存不足不可用。那么有没有什么方案可以解决大文件下载的问题呢?下面介绍一种分片下载的方案。
分片下载的核心思想是将服务器上的大文件拆分成若干个小文件,等这些小份文件都下载好了之后,最后将小文件合并成一个完整的大文件。如下图所示:

这里有个问题就是如何将一个大文件分成小文件(分片)下载呢?其实这个很简单,我们可以使用前端一个比较重要的请求首部——Range,它可以帮助我们实现分片下载。
1、认识Range
Range首部会告诉服务器返回文件哪一部分,同时它也支持一次性请求多个部分,服务器会以multipart文件的形式将结果返回。如果服务器返回的是范围响应的时候,服务器使用206状态码通知客户端,如果服务器发现请求不合法会使用416状态码通知客户端。下面列举几种常见的Range获取资源形式
(1)指定部分下载,下图的配置Range告诉服务器下载文件的0-1000字节的数据,

(2)指定多个部分下载,下图配置告诉服务器下载文件的--1000字节、1500-1900字节之间的数据。

(3)下载整个文件资源,配置如下图所示:

经过上面的分析,我们知道了可以使用request添加Range首部的方式可以实现分片获取文件资源。
2、大文件分片下载
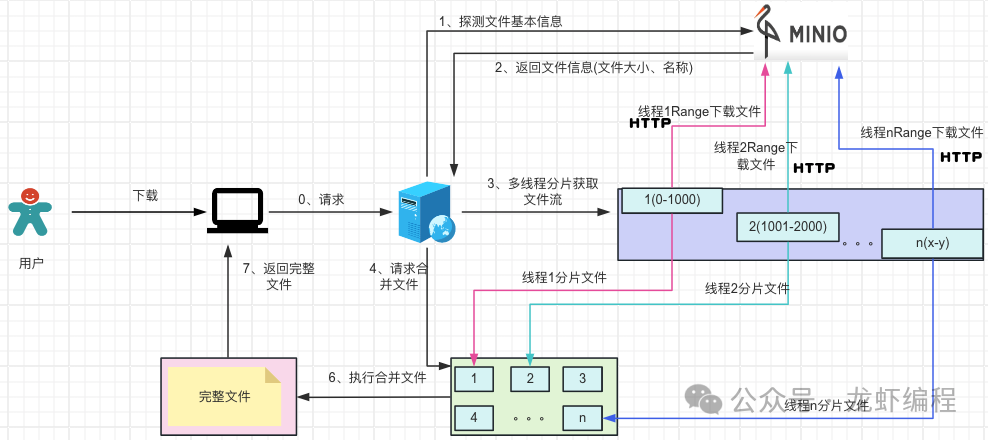
分片下载文件的核心流程:
(1)后端先探测Minio上的文件。探测其实就是先下载文件的很小一部分数据(如Range设置成bytes=0-10)目的是用来获取文件的基本信息(如文件的大小、文件的名称、文件的唯一编码等等),如下图所示:

(2)拿到文件的基本信息后,后端设置每个分片的固定的大小,然后探测出来的根据文件的大小确定分片的数据量,开启和分片数量一致的线程通过http携带Range方式来获取分片文件的资源
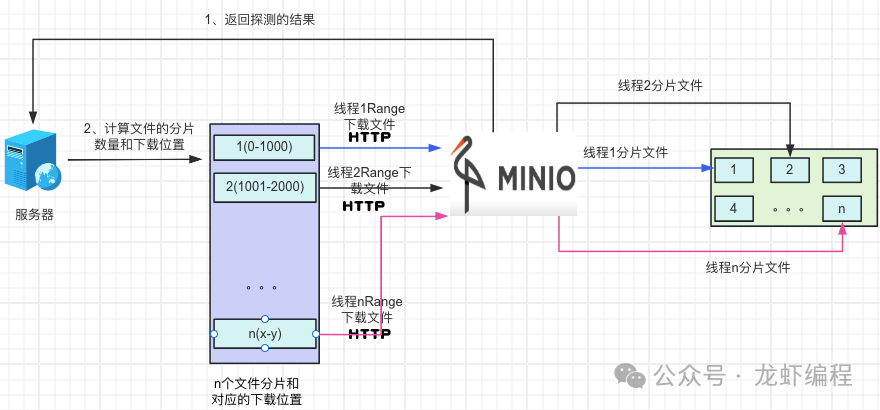
(3)待最后的一个文件下载结束后开始做合并文件的操作,由于是多线程下载文件资源,可能会出现在合并的时候,某些文件还没有下载好,此时需要让合并文件的线程睡眠一小段时间等待文件下载结束后再去合并文件资源。

通过上面的整体分片下载流程分析之后,下面实现这套流程。
3、分片下载具体的落地实现
现在采用分片下载的方式从Minio上下载指定的文件,文件如下:

分片下载的搭建过程和代码如下:
(1)maven配置
<!--swagger--><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.7.0</version></dependency><!--swagger ui--><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger-ui</artifactId><version>2.7.0</version></dependency><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><!--minio--><dependency><groupId>io.minio</groupId><artifactId>minio</artifactId><version>8.4.3</version><exclusions><exclusion><groupId>com.squareup.okhttp3</groupId><artifactId>okhttp</artifactId></exclusion></exclusions></dependency><dependency><groupId>com.squareup.okhttp3</groupId><artifactId>okhttp</artifactId><version>4.8.1</version></dependency><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.11</version></dependency>
(2)Swagger配置
@Configuration@EnableSwagger2public class SwaggerConfig {@Beanpublic Docket webApiConfig(){//设置分片下载的swagger请求头List<Parameter> operationParameters = Lists.newArrayList();operationParameters.add(new ParameterBuilder().name("Range").description("Range").modelRef(new ModelRef("string")).parameterType("header").defaultValue("bytes=0-").hidden(true).required(true).build());return new Docket(DocumentationType.SWAGGER_2).groupName("龙虾编程").apiInfo(webApiInfo()).select()//接口中由/admin /error就不显示.paths(Predicates.not(PathSelectors.regex("/admin/.*"))).paths(Predicates.not(PathSelectors.regex("/error.*")))//扫描指定的包.apis(RequestHandlerSelectors.basePackage("com.longxia")).build().globalOperationParameters(operationParameters);}private ApiInfo webApiInfo(){return new ApiInfoBuilder().title("龙虾编程——分片下载") //swagger页面上大标题.description("龙虾编程——分片下载") //描述.version("1.0").contact(new Contact("龙虾编程", "http://www.baidu.com", "1733150517@qq.com")).build();}}
(3)Minio配置
yaml:------------------------yaml start------------------------#minio配置minio:access-key: 9ItcodDEOrXFYcxnKmFusecret-key: kxv4FFO3oMhzTEyPdkE24HKOAbudGdK2WJPAyvclurl: http://192.168.201.167:9002 #访问地址bucket-name: longxiabucket-name-slice: slice-file------------------------yaml end--------------------------------Bean的配置:------------------------bean配置 start------------------------@Configurationpublic class MinIOConfig {@Value("${minio.url}")private String url;@Value("${minio.access-key}")private String accessKey;@Value("${minio.secret-key}")private String secretKey;@Beanpublic MinioClient minioClient() {return MinioClient.builder().endpoint(url).credentials(accessKey, secretKey).build();}}
(1)文件的基本信息类
@Getterclass FileInfo {//文件的大小private long fSize;//文件的名称private String fName;public FileInfo(long fSize, String fName) {this.fSize = fSize;this.fName = fName;}}
(2)下载单个分片文件去minio上下载
@GetMapping("/singlePartFileDownload")public void singlePartFileDownload(@RequestParam("fileName")String fileName, HttpServletRequest request, HttpServletResponse response) throws Exception {InputStream is = null;OutputStream os = null;GetObjectResponse stream = null;try {// 获取桶里文件信息StatObjectResponse statObjectResponse = minioClient.statObject(StatObjectArgs.builder().bucket("longxia").object(fileName).build());// 分片下载long fSize = statObjectResponse.size();// 获取长度response.setContentType("application/octet-stream");fileName = URLEncoder.encode(fileName, utf8);response.addHeader("Content-Disposition", "attachment;filename=" + fileName);//根据前端传来的Range 判断支不支持分片下载response.setHeader("Accept-Range", "bytes");//文件大小response.setHeader("fSize", String.valueOf(fSize));//文件名称response.setHeader("fName", fileName);response.setCharacterEncoding(utf8);// 定义下载的开始和结束位置long startPos = 0;long lastPos = fSize - 1;//判断前端需不需要使用分片下载if (null != request.getHeader("Range")) {response.setStatus(HttpServletResponse.SC_PARTIAL_CONTENT);String numRange = request.getHeader("Range").replaceAll("bytes=", "");System.out.println("请求头:" + request.getHeader("Range"));String[] strRange = numRange.split("-");if (strRange.length == 2) {startPos = Long.parseLong(strRange[0].trim());lastPos = Long.parseLong(strRange[1].trim());// 若结束字节超出文件大小 取文件大小if (lastPos >= fSize - 1) {lastPos = fSize - 1;System.out.println("请求头last:"+ lastPos);}} else {// 若只给一个长度 开始位置一直到结束startPos = Long.parseLong(numRange.replaceAll("-", "").trim());}}//要下载的长度long rangeLenght = lastPos - startPos + 1;//组装断点下载基本信息String contentRange = new StringBuffer("bytes").append(startPos).append("-").append(lastPos).append("/").append(fSize).toString();response.setHeader("Content-Range", contentRange);response.setHeader("Content-Lenght", String.valueOf(rangeLenght));os = new BufferedOutputStream(response.getOutputStream());//minio上获取文件信息stream = minioClient.getObject(GetObjectArgs.builder().bucket(statObjectResponse.bucket()) //文件所在的桶.object(statObjectResponse.object()) //文件的名称.offset(startPos) //文件的开始位置 默认从0开始.length(rangeLenght) //文件需要下载的长度.build());os = new BufferedOutputStream(response.getOutputStream());//将读取的文件写入到OutputStream中byte[] buffer = new byte[1024];long bytesWritten = 0;int bytesRead = -1;while ((bytesRead = stream.read(buffer)) != -1) {//已经读取的长度和本次读取的长度之和是否大于需要读取的长度(实质就是判断是否最后一行)if (bytesWritten + bytesRead > rangeLenght) {os.write(buffer, 0, (int) (rangeLenght - bytesWritten));break;} else {os.write(buffer, 0, bytesRead);bytesWritten += bytesRead;}}os.flush();response.flushBuffer();} finally {if (is != null) {is.close();}if (os != null) {os.close();}if(stream != null){stream.close();}}}
(3)保存单个分片的下载数据
private FileInfo download(long start, long end, long page, String fName) throws Exception {// 断点下载 文件存在不需要下载File file = new File(down_path, page + "-" + fName);// 探测必须放行 若下载分片只下载一半就需要重新下载 所以需要判断文件是否完整if (file.exists() && page != -1 && file.length() == per_page) {System.out.println("文件存在了咯,不处理了");return null;}// 需要知道 开始-结束 = 分片大小CloseableHttpClient client = HttpClients.createDefault();// httpclient进行请求HttpGet httpGet = new HttpGet("http://127.0.0.1:8080//download2/singlePartFileDownload?fileName=" + fName);// 告诉服务端做分片下载,并且告诉服务器下载到那个位置httpGet.setHeader("Range", "bytes=" + start + "-" + end);CloseableHttpResponse response = client.execute(httpGet);String fSize = response.getFirstHeader("fSize").getValue();fName = URLDecoder.decode(response.getFirstHeader("fName").getValue(), "utf-8");HttpEntity entity = response.getEntity();// 获取文件流对象InputStream is = entity.getContent();//临时存储分片文件FileOutputStream fos = new FileOutputStream(file);// 定义缓冲区byte[] buffer = new byte[1024];int readLength;//写文件while ((readLength = is.read(buffer)) != -1) {fos.write(buffer, 0, readLength);}is.close();fos.flush();fos.close();//判断是不是最后一个分片,如果不是最后一个分片不执行if (end - Long.parseLong(fSize) > 0) {try {System.out.println("开始合并了");this.mergeAllPartFile(fName, page);System.out.println("文件合并结束了");} catch (Exception e) {e.printStackTrace();}}return new FileInfo(Long.parseLong(fSize), fName);}
(4)开启多线程下载分片
@GetMapping("/fenPianDownloadFile")public String fenPianDownloadFile(@RequestParam("fileName")String fileName) throws Exception {//探测文件信息FileInfo fileInfo = download(0, 10, -1, fileName);if (fileInfo != null) {long pages = fileInfo.fSize / per_page;System.out.println("文件分页个数:" + pages + ", 文件大小:" + fileInfo.getFSize());for (int i = 0; i <= pages; i++) {pool.submit(new Download(i * per_page, (i + 1) * per_page - 1, i, fileInfo.fName));}}return "success";}#异步线程下载分片数据class Download implements Runnable {//开始下载位置long start;//结束下载的位置long end;//当前的分片long page;//文件名称String fName;public Download(long start, long end, long page, String fName) {this.start = start;this.end = end;this.page = page;this.fName = fName;}@Overridepublic void run() {try {//下载单个分片download(start, end, page, fName);} catch (Exception e) {e.printStackTrace();}}}
(5)合并文件
/*** 合并文件** @param fName 文件名称* @param page 分片的文件的页**/private void mergeAllPartFile(String fName, long page) throws Exception {// 归并文件位置File file = new File(down_path, fName);BufferedOutputStream os = new BufferedOutputStream(new FileOutputStream(file));for (int i = 0; i <= page; i++) {File tempFile = new File(down_path, i + "-" + fName);// 分片没下载或者没下载完需要等待while (!file.exists() || (i != page && tempFile.length() < per_page)) {Thread.sleep(1000);System.out.println("结束睡觉,再次查询文件等候已经下载完成了");}byte[] bytes = FileUtils.readFileToByteArray(tempFile);os.write(bytes);os.flush();tempFile.delete();}//删除探测文件File file1 = new File(down_path, -1 + "-" + fName);file1.delete();os.flush();os.close();}
启动Swagger测试:

所有分片都下载好之后的效果:

合并完整文件并删除分片之后的效果:

以上我们完成了分片下载的功能。
4、断点下载实现
断点下载就是在分片下载的基础上实现的,下载时候我们判断当前的分片是否是完整的下载(根据文件的大小为依据),最后一个分片根据文件大小我们不知道是否全部下载完成,所有最后一个分片直接去服务器上下载。

下面模拟一下断点下载的场景,分片下载之后,在合并的时候抛出异常,如下图所示:

下载好分片之后,在执行合并文件的时候抛出异常,如下如图所示:

重新执行分片下载,下载过程如下所示:

最后的结果:

这样就可以实现断点下载的效果了。至此我们完成从Minio上分片下载和端点下载文件的的功能。
总结:
(1)分片下载使用的是Range首部方式实现文件下载指定部分,等所有分片都下载结束后,再将整个文件都合并成完成文件,最后删除分片文件的数据。
(2)断点下载是在分片下载的基础上实现的,如果分片已经下载好了就不需要再次下载。
Spring动态代理
动态代理
动态代理是一种在运行时生成代理类的技术,它允许我们在不修改目标对象的情况下,通过代理对象来控制目标对象的行为。
Spring动态代理
在Spring框架中动态代理是一个非常重要的特性,它允许开发者通过代理对象来实现AOP编程,从而实现对目标对象的控制。
Spring动态代理实现方式
Spring中的动态代理主要有两种:JDK动态代理和CGLIB动态代理。
1.JDK动态代理
JDK动态代理是基于接口的代理,它只能为实现了接口的类创建代理对象。
JDK 动态代理是不需要第三方库支持,只需要 JDK 环境就可以进行代理,使用条件:
-
业务目标对象实现接口;
-
实现 InvocationHandler 接口;
-
使用 Proxy.newProxyInstance() 方法生成代理对象;
1.创建InvocationHandler对象
在创建代理对象时,我们需要先创建一个InvocationHandler对象。
InvocationHandler是一个接口,它有一个invoke方法,代理对象的所有方法调用都会被重定向到invoke方法中进行处理。
2.创建代理类
在创建代理对象时,我们需要通过Proxy类的静态方法newProxyInstance来创建代理类。
在创建代理类时,JDK动态代理会自动在内存中生成一个代理类,并在代理类中实现InvocationHandler接口的invoke方法。
3.调用代理类的方法
在代理类中,所有方法调用都会被重定向到InvocationHandler接口的invoke方法中进行处理。
invoke方法中会通过反射调用目标对象的方法,并在方法前后执行一些增强逻辑,从而实现对目标对象的控制。
下面是JDK动态代理的代码实现:
public class DynamicProxy implements InvocationHandler {private Object target;public DynamicProxy(Object target) {this.target = target;}@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {System.out.println("before method");Object result = method.invoke(target, args);System.out.println("after method");return result;}public static void main(String[] args) {RealSubject realSubject = new RealSubject();DynamicProxy dynamicProxy = new DynamicProxy(realSubject);Subject subject = (Subject) Proxy.newProxyInstance(realSubject.getClass().getClassLoader(),realSubject.getClass().getInterfaces(),dynamicProxy);subject.doSomething();}}interface Subject {void doSomething();}class RealSubject implements Subject {@Overridepublic void doSomething() {System.out.println("RealSubject do something.");}}
2.CGLIB动态代理
CGLIB动态代理是基于继承的代理,它可以为任何类创建代理对象,包括没有实现接口的类。
CGLIB(Code Generation Library)是一个基于ASM的字节码生成库,它允许我们在运行时对字节码进行修改和动态生成。
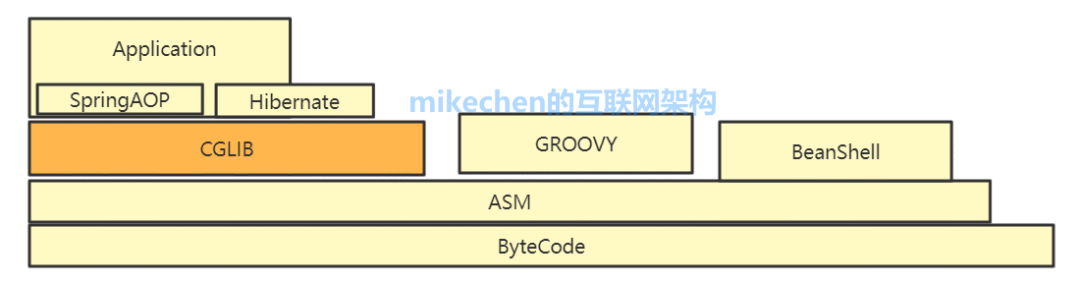
CGLIB动态代理的优点是可以为任何类创建代理对象,缺点是速度比JDK动态代理慢,效率相对较低。
下面是一个使用CGLIB动态代理的例子:
public class UserService {public void addUser(String name) {System.out.println("add user: " + name);}}public class UserServiceProxy implements MethodInterceptor {private Object target;public UserServiceProxy(Object target) {this.target = target;}public Object createProxy() {Enhancer enhancer = new Enhancer();enhancer.setSuperclass(target.getClass());enhancer.setCallback(this);return enhancer.create();}@Overridepublic Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {System.out.println("before method: " + method.getName());Object result = method.invoke(target, args);System.out.println("after method: " + method.getName());return result;}}public class Main {public static void main(String[] args) {UserService userService = new UserService();UserServiceProxy userServiceProxy = new UserServiceProxy(userService);UserService proxy = (UserService) userServiceProxy.createProxy();proxy.addUser("Tom");}}
Spring动态代理使用场景
Spring框架中广泛使用了动态代理技术,用于实现Spring AOP(面向切面编程)。
AOP是一种编程范式,通过将通用的功能,比如:事务管理、日志记录等与业务逻辑分离,使代码更易于维护和扩展。
网络 IO 阻塞
在网络通信中,当发送方和接收方的数据传输速度不均衡、网络出现拥塞、采用阻塞式 I/O 操作、处理方式低效或者网络延迟时,都可能导致网络 I/O 阻塞的发生。这些原因使得程序在进行网络通信时无法及时地发送或接收数据,导致程序性能下降和响应延迟。
原因
1)数据传输速度不均衡:在网络通信中,发送方和接收方的数据传输速度可能不一致。当发送方发送数据快于接收方处理数据的速度时,接收方的缓冲区可能会满,导致发送方的 I/O 操作被阻塞,直到接收方处理完数据。
2)网络拥塞:当网络中的流量过大或网络传输带宽不足时,会导致网络拥塞。在拥塞的情况下,数据包的传输可能会延迟或丢失,导致发送方的 I/O 操作被阻塞。
3)阻塞式I/O操作:在一些传统的网络编程模型中,例如阻塞式I/O,当进行网络读取或写入操作时,程序会一直等待直到数据就绪或发送完成。这种模型下,I/O 操作是同步阻塞的,会导致程序在等待数据的过程中被阻塞。
4)低效的处理方式:当程序在处理 I/O 操作时,可能存在一些低效的处理方式,例如使用循环轮询来检查数据的就绪状态。这种方式会导致 CPU 资源浪费,并且在等待数据就绪时会导致 I/O 操作阻塞。
5)网络延迟(Latency):数据在网络中传输需要一定的时间,称为网络延迟。当数据在传输过程中受到延迟,程序可能会在等待数据返回时被阻塞。
解决方案
1)多线程处理:使用多线程可以在进行网络通信时不阻塞主线程,从而提高程序的并发性能。通过将网络 I/O 操作放在单独的线程中进行,可以避免主线程被阻塞。
2)非阻塞 I/O(Non-blocking I/O):使用非阻塞 I/O 技术,程序可以在进行网络通信时立即返回,而不必等待数据的返回。通过轮询或事件驱动的方式,程序可以检查是否有数据可用,从而实现异步的网络通信。
3)异步 I/O(Asynchronous I/O):异步 I/O 允许程序在进行网络通信时不必等待数据的返回,而是通过回调或事件通知的方式在数据到达时进行处理。这种方式可以提高程序的并发性能和响应速度。
4)使用缓存和流控制:使用缓存可以减少对网络的频繁访问,提高了数据的读取和写入效率。同时,合理地使用流控制机制可以调整数据的传输速率,避免网络拥塞和阻塞。
Java 使用 IO
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.Socket;
import java.net.UnknownHostException;
public class NetworkIOExample {
public static void main(String[] args) {
String serverAddress = "127.0.0.1"; // 服务器地址
int serverPort = 8080; // 服务器端口
try {
// 创建Socket连接到服务器
Socket socket = new Socket(serverAddress, serverPort);
// 获取输出流,用于向服务器发送数据
OutputStream outputStream = socket.getOutputStream();
// 向服务器发送数据
String message = "Hello, Server!";
outputStream.write(message.getBytes());
outputStream.flush();
// 获取输入流,用于从服务器接收数据
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
// 从服务器接收数据并打印到控制台
String response = reader.readLine();
System.out.println("Server Response: " + response);
// 关闭连接
socket.close();
} catch (UnknownHostException e) {
System.err.println("Unknown host: " + serverAddress);
} catch (IOException e) {
System.err.println("I/O error: " + e.getMessage());
}
}
}
1)TCP(传输控制协议)和UDP(用户数据报协议)是网络通信中常用的两种传输层协议,它们的主要区别如下:
- 连接性:TCP 是面向连接的协议,意味着在数据传输之前,需要建立一个连接。而 UDP 是无连接的,数据可以直接发送给接收方,无需事先建立连接。
- 可靠性:TCP 提供了可靠的数据传输,通过序列号、确认应答、重传机制等确保数据的正确性和完整性。UDP 则不保证数据包的顺序和完整性,可能会出现数据丢失或重复。
- 流量控制:TCP 有流量控制机制,通过滑动窗口算法来控制数据的发送速率,避免网络拥塞。UDP 没有这样的流量控制机制。
- 速度和效率:由于 TCP 的可靠性机制,它在传输数据时会有更多的开销,因此通常比 UDP 慢。UDP 由于没有这些机制,通常更快,但牺牲了可靠性。
- 使用场景:TCP 通常用于需要可靠传输的场景,如网页浏览、文件传输等。UDP 则适用于实时应用,如视频会议、在线游戏等,这些场景对速度的要求高于可靠性。
2)在 Java 中实现异步 I/O 操作的几种方法:
- 使用 `java.nio` 包中的异步通道(Asynchronous Channels):Java 7 引入了 `AsynchronousServerSocketChannel` 和 `AsynchronousSocketChannel`,允许异步读写操作。
- 使用 `CompletableFuture`:Java 8 引入了 `CompletableFuture`,它提供了异步编程的强大功能,可以通过编写回调函数或使用 `thenApply`, `thenAccept`, `thenRun` 等方法来处理异步操作的结果。
- 使用反应式编程库,如 Project Reactor 或 RxJava:这些库提供了丰富的操作符来处理异步数据流,适合于构建响应式、异步的应用程序。
- 使用 `ExecutorService`:通过 `java.util.concurrent` 包中的 `ExecutorService`,可以创建线程池来执行异步任务,然后使用 `Future` 对象来获取异步操作的结果。
- 使用 Java 的异步 web 框架,如 Spring WebFlux:这些框架提供了异步处理 HTTP 请求的机制,适合于构建高性能的 web 应用程序。
其他补充
网络I/O阻塞的主要原因是在进行网络通信时,数据的传输速度无法保证,可能会出现网络延迟或者数据包丢失等情况,导致程序在等待数据的过程中被阻塞。
解决网络I/O阻塞问题的方法通常有以下几种:
-
多线程/多进程:通过使用多线程或者多进程的方式,可以在一个线程/进程中进行网络I/O操作,而在另一个线程/进程中执行其他任务,从而避免阻塞整个程序。
-
非阻塞I/O:使用非阻塞I/O模式,程序可以在发起I/O操作后立即返回,然后通过轮询或者事件通知等方式来检查I/O操作的完成状态,从而实现异步处理。
-
事件驱动/异步I/O:利用事件驱动模型或者异步I/O框架,可以在发起I/O操作后继续执行其他任务,而不必等待I/O操作完成,当I/O操作完成后会通过回调或者事件通知的方式来处理数据。
网络I/O和数据库I/O的区别和共同点如下:
区别:
-
数据源不同: 网络I/O是与网络通信相关的I/O操作,而数据库I/O是与数据库交互相关的I/O操作。
-
通信方式不同: 网络I/O通常是通过网络协议进行数据传输,而数据库I/O则是通过数据库协议与数据库服务器进行通信。
-
性能特点不同: 网络I/O受到网络环境的影响,可能会出现延迟、丢包等情况,而数据库I/O受到数据库性能和负载的影响,可能会出现数据库连接池耗尽、数据库锁等问题。
共同点:
-
阻塞问题: 网络I/O和数据库I/O都可能出现阻塞问题,导致程序性能下降。
-
异步处理: 都可以通过异步I/O等方式来解决阻塞问题,提高程序的并发能力和性能。
-
数据传输: 都涉及到数据的读取和写入操作,需要考虑数据的传输效率和安全性。
1)阻塞式I/O(Blocking I/O)和非阻塞式I/O(Non-blocking I/O):
- 阻塞式I/O:在阻塞式I/O中,当应用程序发起一个I/O操作(如读或写)时,如果没有数据可读或写,应用程序会一直等待,直到操作完成。在这段时间内,应用程序无法执行其他任务,因此是阻塞的。
- 非阻塞式I/O:在非阻塞式I/O中,应用程序发起I/O操作后,如果数据不可用,程序不会等待,而是立即返回,去做其他事情。过了一段时间后,程序再次检查I/O操作是否完成。这种方式下,程序可以在等待I/O完成的同时执行其他任务。
2)同步I/O(Synchronous I/O)和异步I/O(Asynchronous I/O):
- 同步I/O:在同步I/O操作中,应用程序会发起I/O请求,然后等待I/O操作完成,或者数据从内核复制到用户空间。在等待期间,应用程序可能阻塞,也可能非阻塞(如果是非阻塞I/O),但无论如何,它需要等待I/O操作完成才能继续执行。
- 异步I/O:在异步I/O操作中,应用程序发起I/O请求后,不需要等待I/O操作完成,就可以继续执行其他任务。当I/O操作完成后,系统会通知应用程序。这种方式下,应用程序的执行和I/O操作是并行进行的。
3)Java中常用的网络I/O类:
- `Socket` 和 `ServerSocket`:用于创建客户端和服务器端的套接字,进行基于TCP的网络通信。
- `DatagramSocket` 和 `MulticastSocket`:用于基于UDP的网络通信,其中 `MulticastSocket` 支持组播通信。
- `java.nio` 包中的 `ByteBuffer`、`SocketChannel`、`ServerSocketChannel`、`DatagramChannel`:提供了基于缓冲区的非阻塞I/O操作。
- `AsynchronousSocketChannel` 和 `AsynchronousServerSocketChannel`:用于异步网络通信。
- `Selector` 和 `SelectionKey`:用于 `java.nio` 包中的多路复用I/O,允许一个单独的线程来管理多个通道,从而管理多个网络连接。
- `HttpURLConnection`:用于发送HTTP请求和接收响应。
- `SocketTimeoutException`:用于处理网络I/O操作的超时情况。