计算的流动性
随手翻开一个公有云,都会发现有不同的计算实例,搭配不同的CPU、内存、网络和存储来应对不同业务的需求.
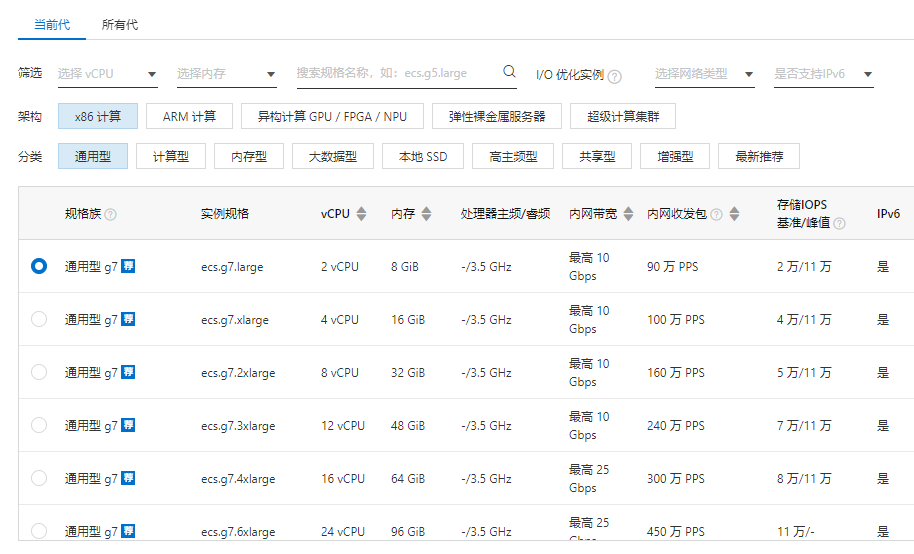
当云原生和大量的新技术出现后,作为公有云考虑的最重要的一件事情就是提供这些丰富服务的成本:
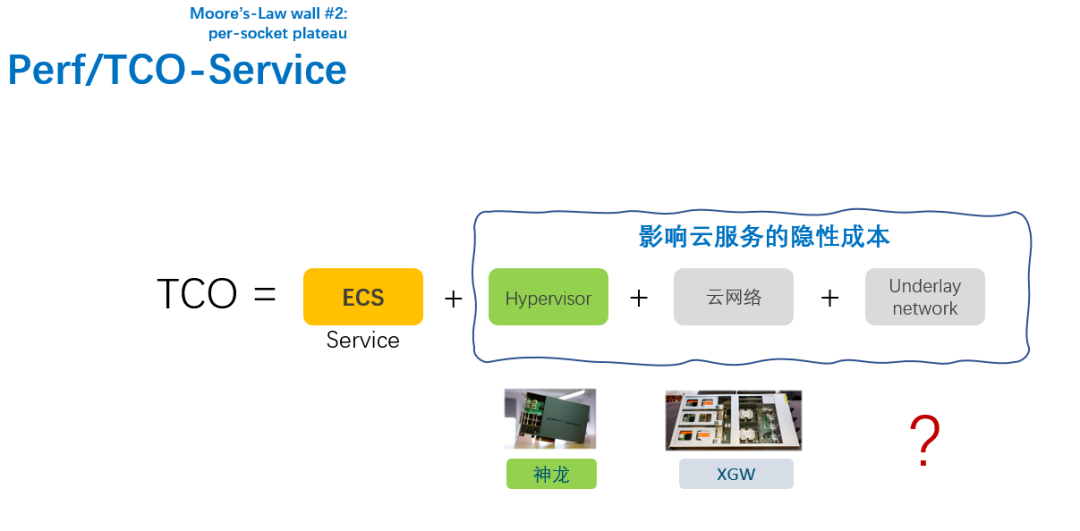
青云、Ucloud也都在A股上市了,市场给出的估值参考并不高,而且还在持续亏损。而阿里云即便是盈利,份额也在下滑。如果大家想想这么多年来对三大运营商动刀,搞增速降费
,同样也是鲸落万物生
。所以公有云市场作为基础设施的提供方是不会允许它有高额利润的. 这是一些公有云厂商做DPU的最根本的初衷.
流动性的诞生
冯诺依曼架构诞生时的I/O是纸带,然后逐渐才是键盘和显示器,这些决定了其标量处理架构的本质:
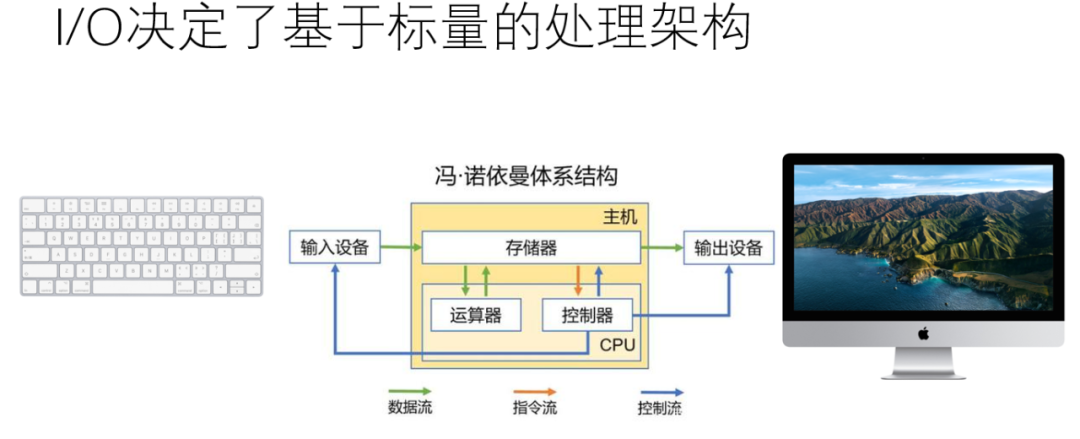
超标量结构,SIMD,或者VLIW暂时解决了一些问题。但是只能针对一些For-loop或者顺序执行的场景,有大量分支的逻辑计算场景就有些力不从心了。所以我们还是要从数据计算本身来看
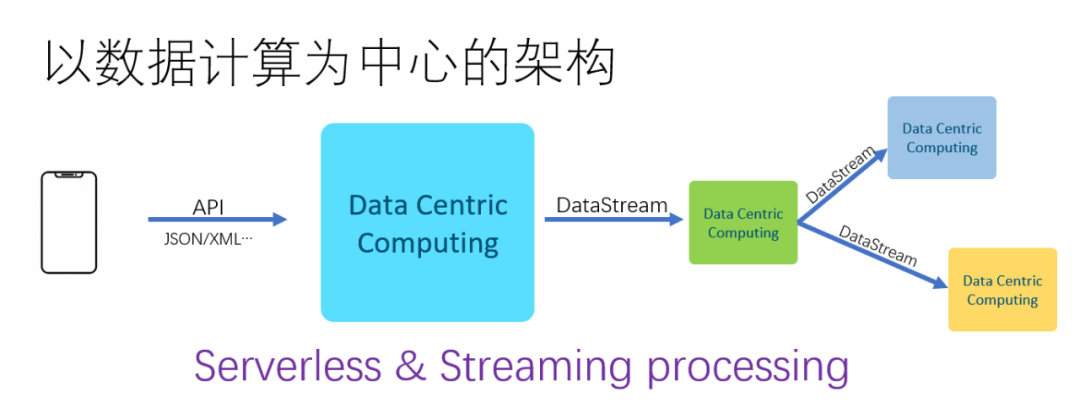
而在云时代,实际上大量的标量交互
已经发生在了前端
和终端
。我们可以很容易的用低代码
的方式构建表格,让最终用户填写数据。云端的交互更多的变成了一种API对结构体数据
的处理, 大量的计算伴随着数据的流动
发生。这就是流式计算
的处理方式,因此伴随着这样的计算方式,微服务Serverless流计算
这些东西,但是计算任务
的分割
如何处理是一个难题,这也是很多企业在微服务改造过程中遇到大量坑的地方.
因此下一代的云计算架构的核心是:
如何满足
计算
和数据
的流动性需求
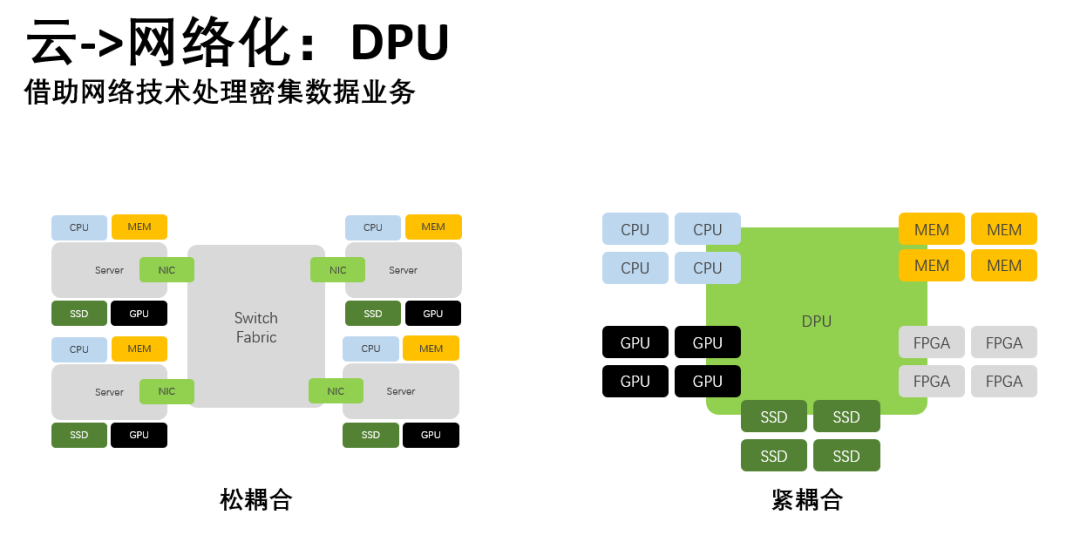
紧耦合
在数据中心内部,将底层网络变得更加简单,然后更多的功能集成到DPU
中采用计算存储
和网络
更加紧耦合的方式,这就是DPU的内生逻辑:
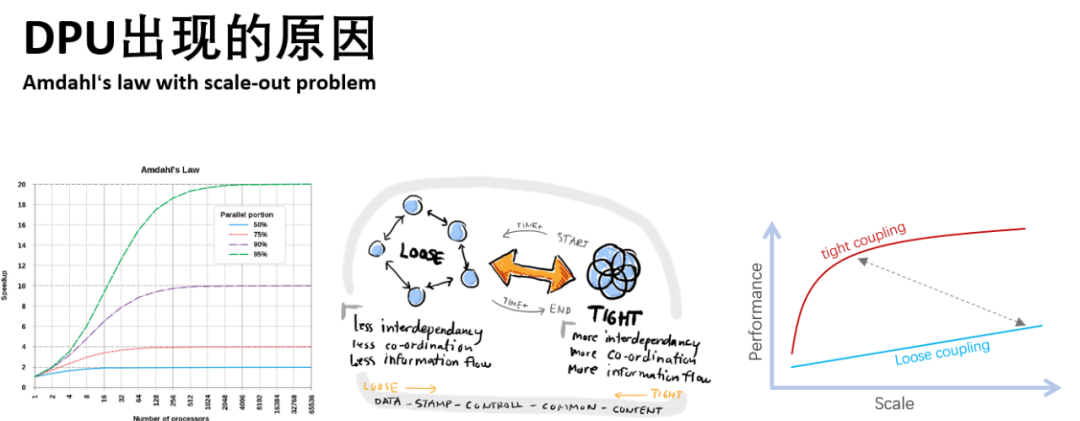
Amdahl定律大家都懂,Scale-Out的路似乎因为规模正在终结,因此在第五代分布式计算架构需要从计算机体系结构上考虑更加紧耦合的解决方案来获得性能的提升
(免费订阅,永久学习)学习地址: Dpdk/网络协议栈/vpp/OvS/DDos/NFV/虚拟化/高性能专家-学习视频教程-腾讯课堂
更多DPDK相关学习资料有需要的可以自行报名学习,免费订阅,永久学习,或点击这里加qun免费
领取,关注我持续更新哦! !
智能网卡提供了一些基本的连通性加速和批量数据解析、加解密、可靠传输等工作负载的加速,这些数据处理业务固然重要。但它并不是全部
紧耦合需要发生在一切有可能发生的地方,并且要以数据为中心,围绕着数据构建一个平衡的分布式系统才是第五代分布式计算架构的核心。
以数据为中心平衡调度才是整个系统架构的关键词。一方面是计算机体系结构上向以数据为中心的处理架构靠拢,通过一些紧耦合的架构追求单节点的性能。另一方面是整个数据中心或者整个阿里云作为一个操作系统更加均衡的调度数据处理任务。
解耦
IBM一直在提一个话题解耦
内存[2] ,事实上这也是我们整个体系结构设计上一直在考虑的话题. 去年花了几个月的时间实现了Ruta[3]就是为了内存解耦
获得一个无拥塞、无丢包的安全可信通信环境.
从IBM的视频来看,现在的架构处理器需要有多种总线连接,但是似乎无法很好的分配这些I/O:
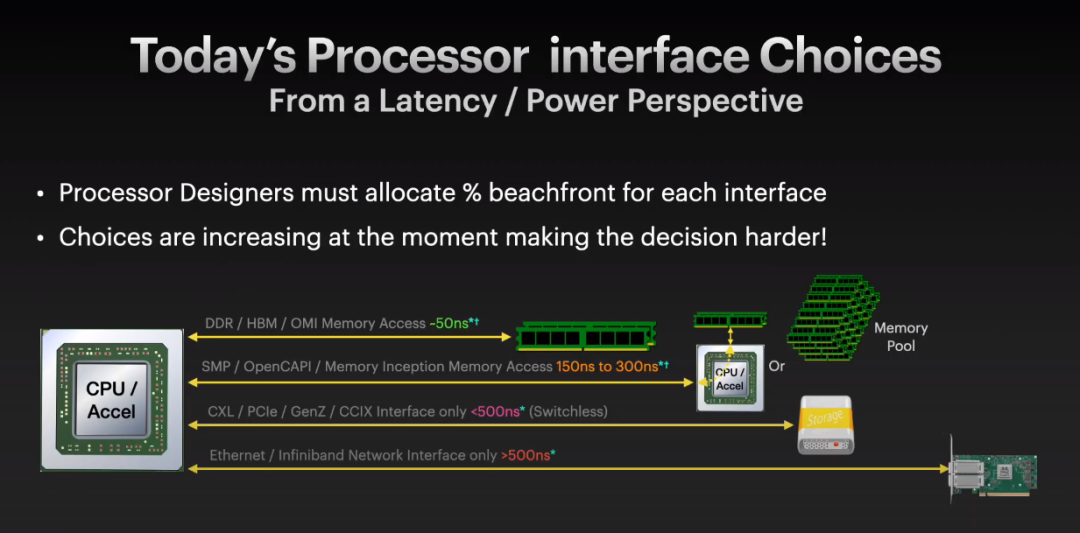
而从处理器的视角来看,其它总线都是串行
的,唯独内存
是并行总线

所以基于这样的想法,IBM构建了OMI接口,并使用串行总线连接内存子系统,可以看到使用8个OMI Channel的芯片和8个标准DDR4 Channel的芯片针脚使用率的对比

然后顺便用Power10和AMD Rome、nVidia Ampere做了对比,串行总线的确节省了die size和pin的数量
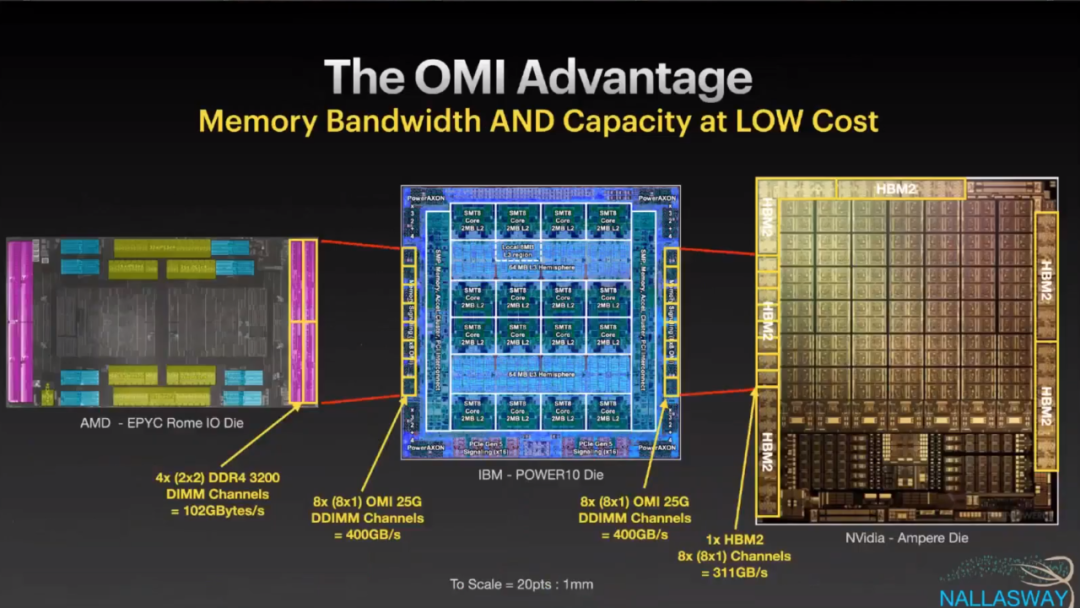
Power10的内存带宽:

最终内存总线也变成一个串行总线了:

解耦合后的架构来看,虽然给一些设备增加了一道访问内存的延迟,但是从处理器视角来看,所有的总线都被更替为内存总线干净了不少吧:
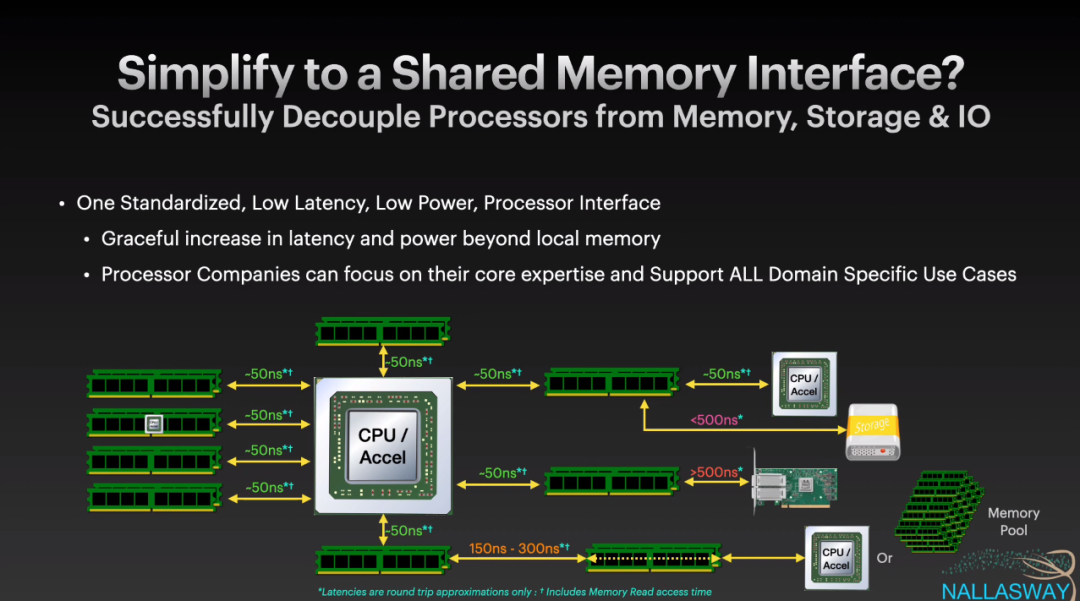
看到这个PPT想起网络的十二条军规中的一条:
It is always possible to add another level of indirection.推论:总是可以增加一层来迂回解决问题
正如最近某些教育机构没法教育娃了,但是可以加一个Overlay去教育家长呀:)
提供流动性
事实上不同的应用有不同的需求,这也是公有云要提供那么多实例类型的原因:
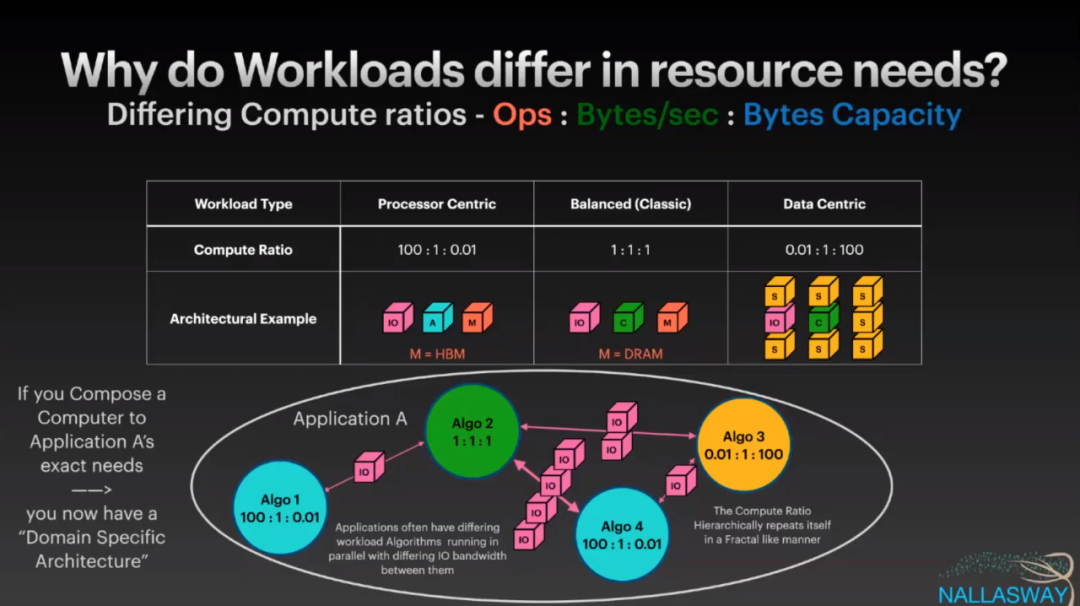
因此IBM有了一个想法,如何像拼乐高那样把这些需求动态的组合起来?
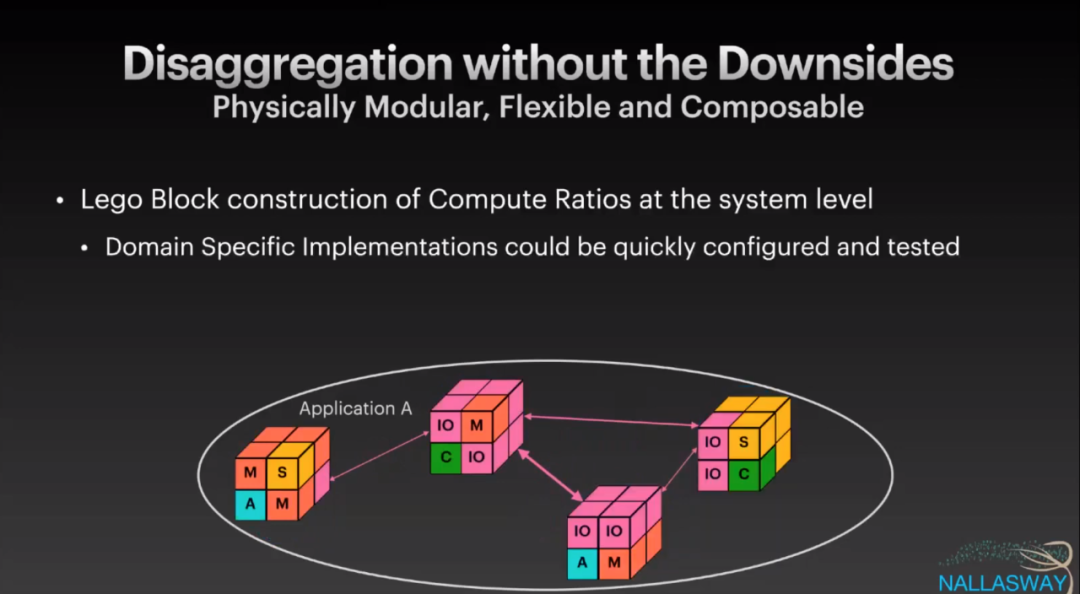
所以最终就需要一种分布式的方法来构建整个系统:

这里就要涉及到两种组合方式了, 一种是类似于Fungible的做法,将各种设备池化,另一种是Chiplet封装的技术,当然各自有一些优缺点.

然后IBM就提出了基于OCP OAM-HPC Module的方式来构建

利用通用的协议无感知的串口连接器来构建:
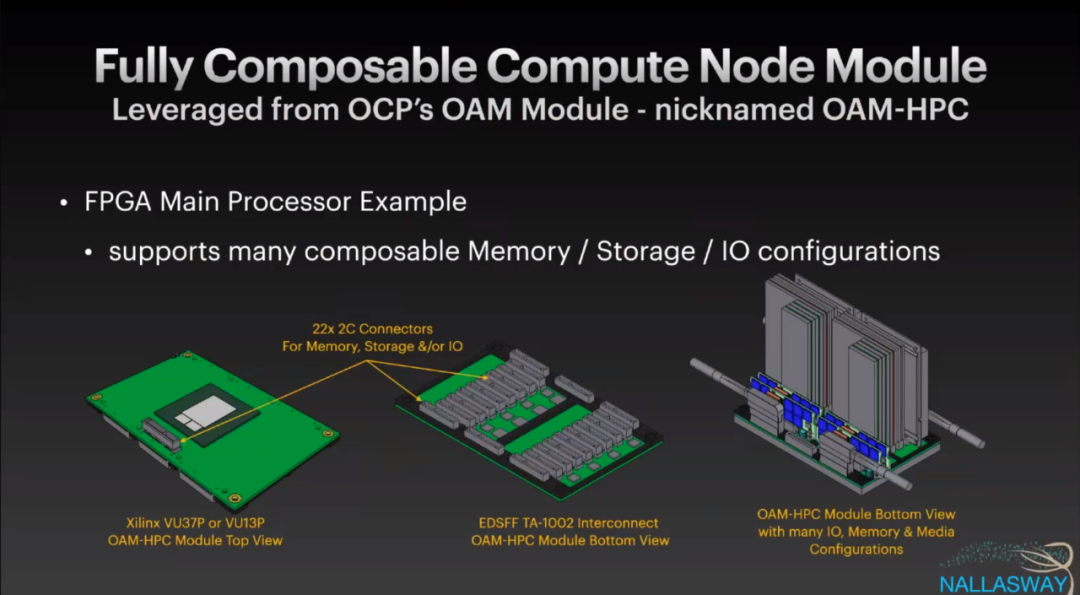
然后内存也可以池化了:

同时在Power10上还提供了内存多跳借用的机制:
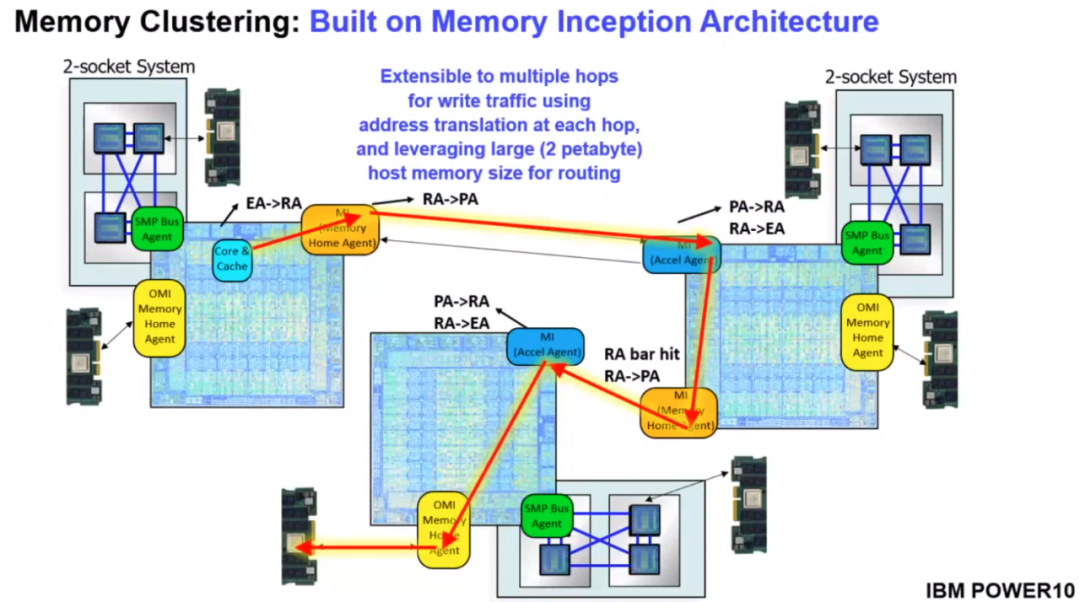
从这个角度来看,Power10实现了接口的统一,利用OCP-HPC相对标准的接口,同时提供了OMI、SMP、PCIe5.0等多种总线的互访,乐高块搭好了.

加法容易减法难
正如前文所述,总是可以增加一层来迂回解决问题,最后一条军规则是
12.在设计协议时,仅当无法再拿掉什么时才算完美,而不是无法再增加什么
增加一颗DPU、增加一个串行内存,看似解决了不少问题,但是冯诺依曼架构真正的瓶颈还没触碰到:
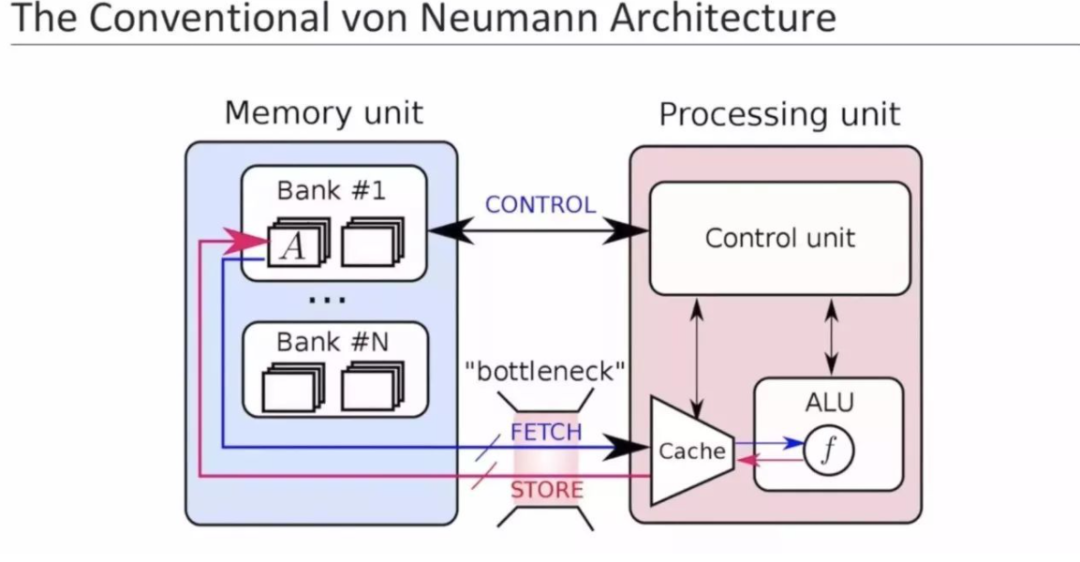
然后为了提升性能降低内存墙而设立的多级Cache逐渐也成了问题:

这些多级缓存犹如三峡的多级船闸:

DPU的实现,一定要告诉自己,做一个加法的时候,一定要顺手做两个减法。Clarence在做MPLS-SR的时候最大的成功就是利用SR剪掉了LDP、RSVP.但是SRv6至今并不成功的原因就是在v6 Option Header上的加法使得防火墙等很多节点还要做更多的加法、SID更长还要做uSID、gSID压缩的加法..
最终的减法,有OMI,有Ruta,有存内计算,还有操作系统...
Good, Fast, Cheap: Pick any two
Reference
[1]
夏寒:闲谈算法、云计算公司估值:https://mp.weixin.qq.com/s/JroLFecZzcvaDYFaohlqaQ
[2]
Decoupling Compute from Memory, Storage & IO with OMI:https://www.youtube.com/watch?v=c0DuGSwDpqY
[3]
Ruta:https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzUxNzQ5MTExNw==&action=getalbum&album_id=1364600286966415361#wechat_redirect
原文链接:https://www.modb.pro/db/193490
![[Redis] Spring Boot 使用Redis---RedisTemplate泛型约束乱码问题](https://img-blog.csdnimg.cn/fafcc1fdbbfd40a18740c2d6f7fadff2.png)