文章目录
- 在线体验
- 快速开始
- 一、项目介绍篇
- 1.1 PP-Structure概述
- 1.2 PP-Structure核心功能:表格识别
- 1.3 PP-Structure特点
- 1.4 模块介绍
- 1.4.1 TableDec.py
- 1.4.2 app.py
- 二、核心代码介绍篇
- 2.1 app.py
- 2.2 TableDec.py
- 2.3 扩展-模型选择
- 3.4.1 版面分析模型
- 3.4.2 表格识别模型
- 三、总结
在线体验
智能图片识别表格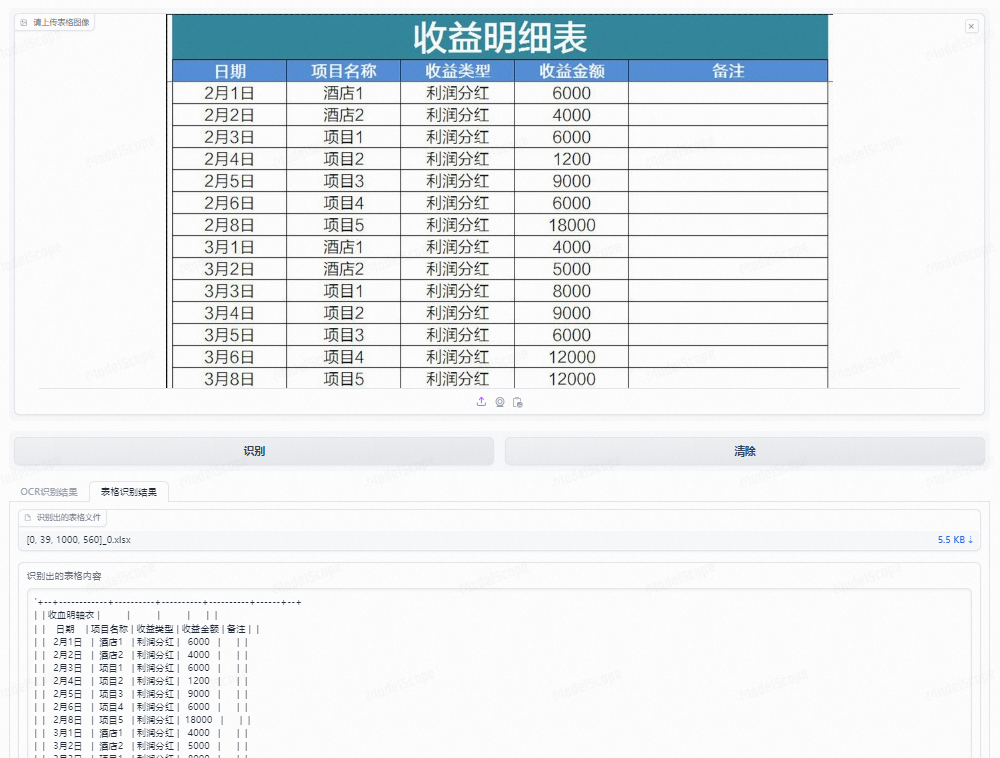
快速开始
- 创建
anaconda环境
conda create -n XXX python=3.10
- 安装依赖包
pip install -r requirements.txt
- 启动
app.py,访问网页 127.0.0.1:7860
python app.py
- 网页界面如下,可在示例图片中快速进行试验
一、项目介绍篇
在数字化办公的浪潮中,将图片中的数据转换成可编辑的Excel格式已成为一项日益增长的需求。PP-Structure,由飞桨PaddleOCR团队开发,提供了强大的文档分析能力,包括版面分析和表格识别,使得图片数据结构化输出成为可能。本文将深入探讨PP-Structure技术,分析其工作原理、实现过程,并探讨其在数字化办公中的应用价值。
1.1 PP-Structure概述
官方 github 地址:https://github.com/PaddlePaddle/PaddleOCR
PP-Structure是一款基于AI的图片到Excel转换工具,以其快速和高准确率的转换能力在技术社区中受到广泛关注。这一工具的内部逻辑和智能转化技术,为文档格式转换提供了一种全新的解决方案。
1.2 PP-Structure核心功能:表格识别
PP-Structure的核心功能是表格识别,它通过调用PP-Structure的PPStructure类实现表格识别功能,并将识别结果保存到临时文件中。此外,还实现了图片方向分类功能,用于判断图片是否需要旋转以适应版面分析。
1.3 PP-Structure特点
- 本地部署:支持本地部署,方便企业内部使用。
- 多模型支持:提供了多种模型以适应不同的识别需求,如PP-Structure和PP-StructureV2。
- 高准确率:基于SLANet在PubTabNet数据集上训练的模型,保证了识别的高准确率。
1.4 模块介绍
1.4.1 TableDec.py
- 整合了pp-structure的核心实现类
1.4.2 app.py
- gradio页面代码
二、核心代码介绍篇
2.1 app.py
path = os.path.join("./pp_models")
tdModel = TableDec(det_model_dir=os.path.join(path, "det"),
rec_model_dir=os.path.join(path, "rec"),
cls_model_dir=os.path.join(path, "cls"),
table_model_dir=os.path.join(path, "table"),
layout_model_dir=os.path.join(path, "layout"))
def dec_fn(image):
global tempdir
im_show, excel_file, execl_str = tdModel.run_dec(tempdir, image)
return im_show, excel_file, execl_str
if __name__ == "__main__":
# 使用临时文件夹保存数据
global tempdir
with tempfile.TemporaryDirectory() as tempdir:
with gr.Blocks() as app:
with gr.Column(variant="panel"):
image = gr.Image(label="请上传表格图像")
with gr.Row(variant="panel"):
btn = gr.Button(value="识别")
clear_bu = gr.ClearButton([image], value="清除")
with gr.Tabs():
with gr.Tab(label="OCR识别结果"):
ocr_res = gr.Image(label="OCR识别结果")
gr.Button(value="flag")
with gr.Tab(label="表格识别结果"):
table_res = gr.File(label="识别出的表格文件")
table_text = gr.TextArea(label="识别出的表格内容")
gr.Button(value="flag")
clear_bu.add([ocr_res, table_res, table_text])
btn.click(fn=dec_fn, inputs=image, outputs=[ocr_res, table_res, table_text])
# 添加演示用例
gr.Examples(examples='./examples', fn=dec_fn,
inputs=image,
outputs=[ocr_res, table_res, table_text],
cache_examples=True)
app.launch()
- 此段代码主要是用于生成前端页面,以及配置按钮点击事件触发时的回调函数
- 生成的csv文件会保存在临时文件夹中,关闭程序后文件会自动删除
2.2 TableDec.py
class TableDec:
def __init__(self, **kwargs):
self.table_engine = PPStructure(show_log=True, image_orientation=True, **kwargs)
def run_dec(self, savedirpath, image):
... use the PPStructure implementation to recognize the table structure and save the result to a temporary file ...
- 此段代码是表格识别的核心代码,通过调用PP-Structure的
PPStructure类实现表格识别功能,并将识别结果保存到临时文件中 - 此段代码还实现了图片方向分类功能,用于判断图片是否需要旋转
- 将识别结果保存到临时文件中,供前端页面展示
- 另外,还调用
excel_util.py的execl2text实现了读取excel文件并转换为展示文本
2.3 扩展-模型选择
- PP-Structure提供了多种模型以适应不同的识别需求。作为本项目可扩展性的探索方向,您可以在
TableDec中初始化PPStructure时携带structure_version属性用于选择不同的模型。例如:
self.table_engine = PPStructure(show_log=True, image_orientation=True, structure_version='PP-Structure', **kwargs)
- 目前支持
PP-Structure和PP-StructureV2两种模型,默认使用PP-StructureV2。- paddleocr设定的全局模型参数
DEFAULT_STRUCTURE_MODEL_VERSION = 'PP-StructureV2'
SUPPORT_STRUCTURE_MODEL_VERSION = ['PP-Structure', 'PP-StructureV2']
- 模型对应的下载链接和字典路径
{
'PP-Structure': {
'table': {
'en': {
'url': 'https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar',
'dict_path': 'ppocr/utils/dict/table_structure_dict.txt'
}
}
},
'PP-StructureV2': {
'table': {
'en': {
'url': 'https://paddleocr.bj.bcebos.com/ppstructure/models/slanet/en_ppstructure_mobile_v2.0_SLANet_infer.tar',
'dict_path': 'ppocr/utils/dict/table_structure_dict.txt'
},
'ch': {
'url': 'https://paddleocr.bj.bcebos.com/ppstructure/models/slanet/ch_ppstructure_mobile_v2.0_SLANet_infer.tar',
'dict_path': 'ppocr/utils/dict/table_structure_dict_ch.txt'
}
},
'layout': {
'en': {
'url': 'https://paddleocr.bj.bcebos.com/ppstructure/models/layout/picodet_lcnet_x1_0_fgd_layout_infer.tar',
'dict_path': 'ppocr/utils/dict/layout_dict/layout_publaynet_dict.txt'
},
'ch': {
'url': 'https://paddleocr.bj.bcebos.com/ppstructure/models/layout/picodet_lcnet_x1_0_fgd_layout_cdla_infer.tar',
'dict_path': 'ppocr/utils/dict/layout_dict/layout_cdla_dict.txt'
}
}
}
}
- 可以看到,
PP-StructureV2模型使用了layout和table两种模型,分别是:picodet_lcnet_x1_0_fgd_layout_cdla_infer和ch_ppstructure_mobile_v2.0_SLANet
3.4.1 版面分析模型
| 模型名称 | 模型简介 | 推理模型大小 | 下载地址 | dict path |
|---|---|---|---|---|
| picodet_lcnet_x1_0_fgd_layout | 基于PicoDet LCNet_x1_0和FGD蒸馏在PubLayNet 数据集训练的英文版面分析模型,可以划分文字、标题、表格、图片以及列表5类区域 | 9.7M | 推理模型 / 训练模型 | PubLayNet dict |
| ppyolov2_r50vd_dcn_365e_publaynet | 基于PP-YOLOv2在PubLayNet数据集上训练的英文版面分析模型 | 221.0M | 推理模型 / 训练模型 | 同上 |
| picodet_lcnet_x1_0_fgd_layout_cdla | CDLA数据集训练的中文版面分析模型,可以划分为表格、图片、图片标题、表格、表格标题、页眉、脚本、引用、公式10类区域 | 9.7M | 推理模型 / 训练模型 | CDLA dict |
| picodet_lcnet_x1_0_fgd_layout_table | 表格数据集训练的版面分析模型,支持中英文文档表格区域的检测 | 9.7M | 推理模型 / 训练模型 | Table dict |
| ppyolov2_r50vd_dcn_365e_tableBank_word | 基于PP-YOLOv2在TableBank Word 数据集训练的版面分析模型,支持英文文档表格区域的检测 | 221.0M | 推理模型 | 同上 |
| ppyolov2_r50vd_dcn_365e_tableBank_latex | 基于PP-YOLOv2在TableBank Latex数据集训练的版面分析模型,支持英文文档表格区域的检测 | 221.0M | 推理模型 | 同上 |
3.4.2 表格识别模型
| 模型名称 | 模型简介 | 推理模型大小 | 下载地址 |
|---|---|---|---|
| en_ppocr_mobile_v2.0_table_structure | 基于TableRec-RARE在PubTabNet数据集上训练的英文表格识别模型 | 6.8M | 推理模型 / 训练模型 |
| en_ppstructure_mobile_v2.0_SLANet | 基于SLANet在PubTabNet数据集上训练的英文表格识别模型 | 9.2M | 推理模型 / 训练模型 |
| ch_ppstructure_mobile_v2.0_SLANet | 基于SLANet的中文表格识别模型 | 9.3M | 推理模型 / 训练模型 |
三、总结
- 通过本项目,您可以了解到如何使用飞桨PP-Structure实现图片到Excel的转换。我们提供了环境配置、代码实现和模型选择的详细步骤。如果您在使用过程中遇到任何问题,欢迎在ModelScope创空间-智能图片识别表格上提出issue,我们会及时为您解答。
- 希望本项目能够帮助您提高工作效率,享受数字化办公的便捷。如果您觉得本项目对您有帮助,请给项目点个star,并持续关注我的个人主页ModelBulider的个人主页