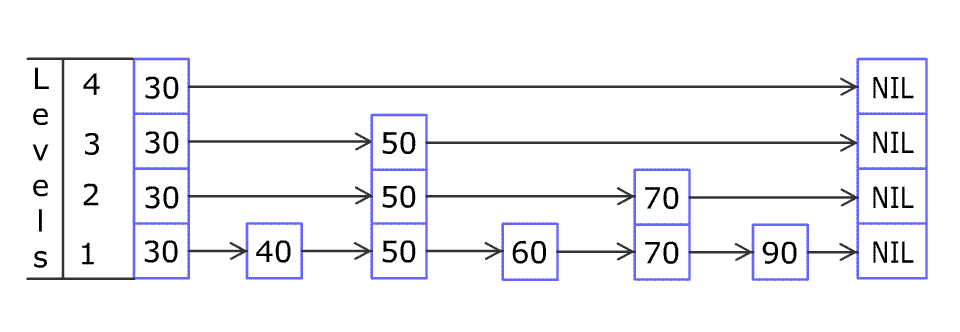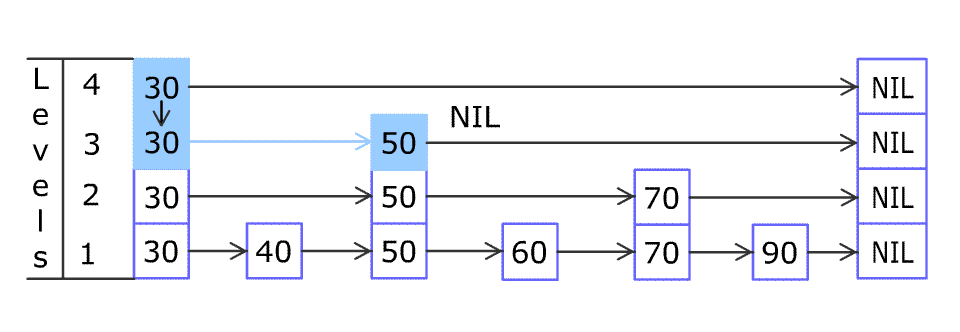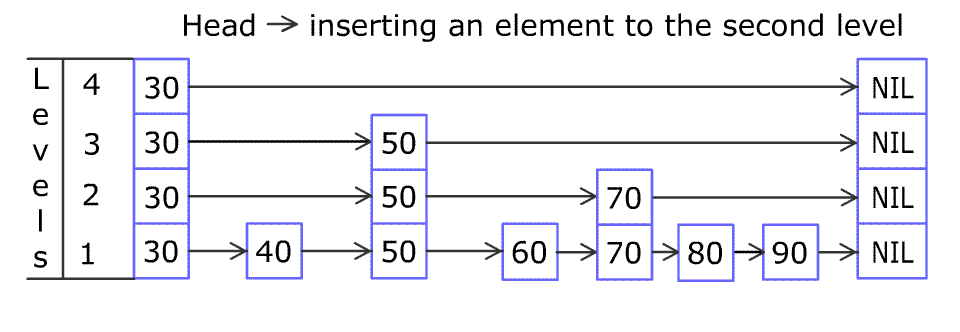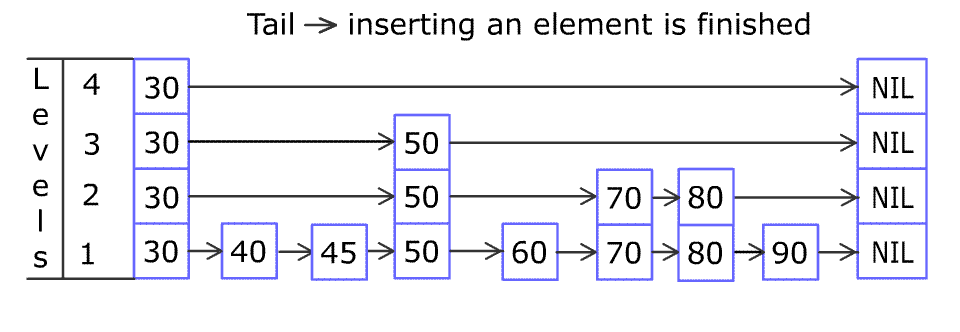
大模型知识
基础算法
机器学习
常见经典公式推导
LR手推、求导、梯度更新
SVM原形式、对偶形式
FM公式推导
GBDT手推
XGB推导
AUC计算
神经网络的反向传播
常见通用问题
评价指标
分类
结合混淆矩阵
准确率(Accuracy)
识别对了的正例(TP)与负例(TN)占总识别样本的比例。缺点:类别比例不均衡时影响评价效果。
精确率(Precision)
识别正确的正例(TP)占识别结果为正例(TP+FP)的比例
召回率(Recall)
识别正确的正例(TP)占实际为正例(TP+FN)的比例。
F1值
F1是召回率R和精度P的加权调和平均,顾名思义即是为了调和召回率R和精度P之间增减反向的矛盾,对R和P进行加权调和。
P-R曲线
PR曲线通过取不同的分类阈值,分别计算当前阈值下的模型P值和R值,以P值为纵坐标,R值为横坐标,将算得的一组P值和R值画到坐标上,就可以得到P-R曲线。当一个模型的P-R曲线完全包住另一个模型的P-R曲线,则前者的性能优于后者(如A>C,B>C)。
ROC
ROC曲线也称受试者工作特征。以FPR(假正例率:假正例占所有负例的比例)为横轴,TPR(召回率)为纵轴,绘制得到的曲线就是ROC曲线。与PR曲线相同,曲线下方面积越大,其模型性能越好。
AUC
含义一:ROC曲线下的面积即为AUC。面积越大代表模型的分类性能越好。
含义二:随机挑选一个正样本以及负样本,算法将正样本排在所有负样本前面的概率就是AUC值。 是排序模型中最为常见的评价指标之一。
**AUC的评价效果不受正负样本比例的影响。**因为改变正负样本比例,AOC曲线中的横纵坐标大小同时变化,整体面积不变。
回归
MAE(平均绝对误差)
MAE是平均绝对误差,又称L1范数损失。通过计算预测值和真实值之间的距离的绝对值的均值,来衡量预测值与真实值之间的真实距离。
MSE(Mean Square Error)
MSE是真实值与预测值的差值的平方然后求和平均,L2范数损失。通过平方的形式便于求导,所以常被用作线性回归的损失函数。
RMSE(Root Mean Square Error)
RMSE衡量观测值与真实值之间的偏差。常用来作为机器学习模型预测结果衡量的标准。 受异常点影响较大,鲁棒性比较差。
排序
AUC
随机挑选一个正样本以及负样本,算法将正样本排在所有负样本前面的概率就是AUC值。
AUC不受数据的正负样本比例影响,可以准确的衡量模型的排序能力,是推荐算法、分类算法常用的模型评价指标。
MAP(Mean Average Precision)
全局平均准确率,其中AP表示单用户TopN推荐结果的平均准确率。
NDCG
首先介绍CG(累计收益),模型会给推荐的每个item打分表示与当前用户的相关性。假设当前推荐item的个数为N个,我们把这N个item的相关分数进行累加,就是当前用户的累积增益:
显然CG不考虑不同位置对排序效果的影响,所以在此基础上引入位置影响因素,即DCG(折损累计增益),位置靠后的结果进行加权处理:
推荐结果的相关性越大,DCG越大,推荐效果越好。
NDCG(归一化折损累计增益),表示推荐系统对所有用户推荐结果DCG的一个平均值,**由于每个用户的排序列表不一样,所以先对每个用户的DCG进行归一化,再求平均。**其归一化时使用的分母就是IDCG,指推荐系统为某一用户返回的最好推荐结果列表,即假设返回结果按照相关性排序,最相关的结果放在前面,此序列的DCG为IDCG。
MRR(平均倒数秩)
MRR平均倒数排名,是一个国际上通用的对搜索算法进行评价的机制,即第一个结果匹配,分数为1,第二个匹配分数为0.5,第n个匹配分数为1/n,如果没有匹配的句子分数为0。最终的分数为所有得分之和。
聚类
聚类任务的评价指标分为内部指标(无监督数据)和外部指标(有监督数据)。
内部指标(无监督数据,利用样本数据与聚类中心之间的距离评价):
紧密度(Compactness)
每个聚类簇中的样本点到聚类中心的平均距离。紧密度越小,表示簇内的样本点越集中,样本点之间聚类越短,也就是说簇内相似度越高。
分割度(Seperation)
每个簇的簇心之间的平均距离。分割度值越大说明簇间间隔越远,分类效果越好,即簇间相似度越低。
轮廓系数 (Silhouette Coefficient)
对于一个样本集合,它的轮廓系数是所有样本轮廓系数的平均值。轮廓系数的取值范围是[-1,1],同类别样本距离越相近,不同类别样本距离越远分数越高。
外部指标(有监督数据,利用样本数据与真实label进行比较评价):
兰德系数(Rand index)
兰德系数是使用真实label对聚类效果进行评估,评估过程和混淆矩阵的计算类似
互信息(Mutual Information)
损失函数
分类损失函数
交叉熵损失(Cross-entropy loss function)
交叉熵损失函数经常用于分类问题中,特别是在神经网络做分类问题时,也经常使用交叉熵作为损失函数。交叉熵损失函数的输入数据通常是softmax或者sigmoid函数的输出。
优点:交叉熵当损失函数时,在模型效果差的时候学习速度比较快,在模型效果好的时候学习速度变慢。
log对数损失函数(logarithmic loss)
对数损失函数本质上是一种似然函数,主要在逻辑回归中使用。假设样本预测值和实际值的误差符合高斯分布,采用极大似然估计的方法,取对数得到损失函数
对数损失函数的健壮性不强,对噪声敏感。
**对数损失函数和交叉熵损失函数是等价的(推导路径不一致)。**交叉熵中未知真实分布相当于对数损失中的真实标记y,寻找的近似分布相当于对数损失的预测值。
**交叉熵函数与最大似然函数的联系和区别**
区别:交叉熵函数描述模型预测值和真实值的差距大小,越大代表越不相近;似然函数衡量在某个参数下,整体的估计和真实样本一致的概率,越小代表越不相近。
联系:交叉熵函数可以由最大似然函数在伯努利分布的条件下推导出来,或者说最小化交叉熵函数的本质就是对数似然函数的最大化。
回归损失函数
绝对值损失函数( Mean Absolute Error,MAE)
平均绝对误差即L1损失函数,平均绝对误差指的就是模型预测值 f(x) 与样本真实值 y 之间距离的平均值
MAE 大部分情况下梯度都是相等的,这意味着即使对于小的损失值,其梯度也是大的。不利于函数的收敛和模型的学习。
平方损失函数(Mean Square Error,MSE)
均方误差即L2损失,均方误差指的就是模型预测值 f(x) 与样本真实值 y 之间距离平方的平均值。
MSE 曲线的特点是光滑连续、可导,便于使用梯度下降算法,是比较常用的一种损失函数。而且,MSE 随着误差的减小,梯度也在减小,这有利于函数的收敛。
Huber Loss
Huber Loss 结合了 MSE 和 MAE 损失,在误差接近 0 时使用 MSE,使损失函数可导并且梯度更加稳定;在误差较大时使用 MAE 可以降低噪声数据的影响,使训练对 outlier 更加健壮。
优化器
梯度下降法(gradient descent)
选择最陡峭的地方下山——这是梯度下降法的核心思想:它通过每次在当前梯度方向(最陡峭的方向)向前“迈”一步,来逐渐逼近函数的最小值。
梯度下降法根据每次求解损失函数LL带入的样本数,可以分为:全量梯度下降(计算所有样本的损失),批量梯度下降(每次计算一个batch样本的损失)和随机梯度下降(每次随机选取一个样本计算损失)。
缺点:
- 学习率设定问题,如果学习速率过小,则会导致收敛速度很慢。如果学习速率过大,那么其会阻碍收敛,即在极值点附近会振荡。
- 模型所有的参数每次更新都是使用相同的学习速率。
- 陷入局部最小值和鞍点。
Momentum
为了解决随体梯度下降上下波动,收敛速度慢的问题,提出了Momentum优化算法,这个是基于SGD的
RMSprop
RMSprop使用指数加权平均来代替历史梯度的平方和:
RMSprop对梯度较大的方向减小其学习速率,相反的,在梯度较小的方向上增加其学习速率。
缺点:
仍然需要全局学习率:n
Adam
Adam是Momentum 和 RMSprop的结合,被证明能有效适用于不同神经网络,适用于广泛的结构。是目前最常用的优化方法,优势明显。
简单选择方法:
数据量小可以用SGD。 稀疏数据则选择自适应学习率的算法;而且,只需设定初始学习率而不用再调整即很可能实现最好效果。 Adagrad, Adadelta, RMSprop, Adam可以视为一类算法。RMSprop 与 Adadelta本质相同,都是为了解决Adagrad的学习率消失问题。 目前来看,无脑用 Adam 似乎已经是最佳选择。
过拟合问题
- 增加数据、添加噪声
- early stooping
- 数据均衡(过采样、将采样)
- 正则化(L1,L2)
1.解空间形状:加入正则化项即为约束条件:形成不同形状的约束解空间。
2 导数:L2的导数为2X,平滑。L1导数为X,-X,存在突变的极值点
3.先验:加入正则化项相当于引入参数的先验知识:L1引入拉普拉斯,L2引入高斯分布
L1可以做到特征筛选和得到稀疏解。L2加速训练 - Dropout
减小参数规模
随机丢弃产生不同网络,形成集成,解决过拟合,加速训练 - Batch normolization
加快训练、消除梯度消失(爆炸)、防止过拟合 不适用太小batch、CNN
样本不平衡
- 欠采样:随机欠采样、easysampling、KNN
- 过采样:随机过采样、SMOTE(人工合成)
- 数据增强
- 代价敏感学习:误分类代价不同
- 适合的评价指标:准确率、F值、AUC、G-Mean
距离衡量与相似度
- 欧几里得距离、马哈拉诺比斯距离、曼哈顿距离、切比雪夫距离、明可夫斯基距离、海明距离、编辑距离
- 余弦相似度、皮尔森相关系数、Jaccard相似系数、Tanimoto系数、对数似然相似度/对数似然相似率、互信息/信息增益,相对熵/KL散度、信息检索–词频-逆文档频率(TF-IDF)、词对相似度–点间互信息
特征选择的方法
-
目的:简化模型,降低过拟合,减少内存和计算开销,增强泛化
-
过滤方法:
覆盖率、皮尔逊相关系数、Fisher、最大方差阈值、卡方检验 -
封装方法: 完全搜索、启发式搜索(随机森林,KNN,SVM)
-
嵌入方法: 正则化项(L1)、输出模型特征重要性
常见激活函数
https://dongnian.icu/note/llm/llm_concept/02.%E5%A4%A7%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E5%9F%BA%E7%A1%80/6.%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0/6.%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0.html
- sigmoid和softmax
sigmoid只做值非线性变化映射到(0,1),用于二分类。
softMax变化过程计算所有结果的权重,使得多值输出的概率和为1。用于多分类。 指数运算速度慢。梯度饱和消失。 - tanh函数
双曲正切函数。以0为中心,有归一化的作用。 - ReLu和Leaky ReLu
大于0为1,小于0为0,计算速度快。
leaky输入为负时,梯度仍有值,避免死掉。
归一化
全部的归一化:
https://dongnian.icu/note/llm/llm_concept/02.%E5%A4%A7%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E5%9F%BA%E7%A1%80/2.layer_normalization/2.layer_normalization.html
batchNormalization与layerNormalization的区别
Batch Normalization 的处理对象是对一批样本, Layer Normalization 的处理对象是单个样本。Batch Normalization 是对这批样本的同一维度特征做归一化, Layer Normalization 是对这单个样本的所有维度特征做归一化。
BN、LN可以看作横向和纵向的区别。
经过归一化再输入激活函数,得到的值大部分会落入非线性函数的线性区,导数远离导数饱和区,避免了梯度消失,这样来加速训练收敛过程。
BatchNorm这类归一化技术,目的就是让每一层的分布稳定下来,让后面的层可以在前面层的基础上安心学习知识。
BatchNorm就是通过对batch size这个维度归一化来让分布稳定下来。LayerNorm则是通过对Hidden size这个维度归一。
BN的优点
- 可以使用更大的学习率,训练过程更加稳定,极大提高了训练速度。
- 可以将bias置为0,因为Batch Normalization的Standardization过程会移除直流分量,所以不再需要bias。
- 对权重初始化不再敏感,通常权重采样自0均值某方差的高斯分布,以往对高斯分布的方差设置十分重要,有了BatchNormalization后,对与同一个输出节点相连的权重进行放缩,其标准差σ也会放缩同样的倍数,相除抵消。
- 对权重的尺度不再敏感,理由同上,尺度统一由γ参数控制,在训练中决定。深层网络可以使用sigmoid和tanh了,理由同上,BN抑制了梯度消失。
- Batch Normalization具有某种正则作用,不需要太依赖dropout,减少过拟合。
决策树剪枝
- 预剪枝:提前结束决策树的增长:类目数量、方差 性能提升
- 后剪枝:决策树生长完成之后再进行剪枝
GBDT、XGB、LGB比较
- XGB比GBDT新增内容:
1.损失函数:加入正则化项:L1叶子节点数,L2叶子节点输出Score
2.导数:使用代价函数的二阶展开式来近似表达残差
3.基分类器:XGB支持线性分类器做基分类器
4.处理缺失值:寻找分割点时不考虑缺失值。分别计算缺失值在左右的增益。测试首出现缺失,默认在右。
5.近似直方图算法:采用加权分位数法来搜索近似最优分裂点 6.Shrinkage(缩减):将学习到的模型*系数,削减已学模型的权重
7.列采样:特征采样。
8.并行计算:特征预排序,特征分裂增益计算(均在特征粒度上) - LGB比XGB新增内容(GBDT+GOSS+EFB):
1.节点分裂准则:XGB一次分裂一层节点(浪费),LGB深度优先分裂(过拟合)
2.决策树算法:基于histogram直方图分箱操作。减存加速
3.直接支持类别特征,无需独热操作
4.特征并行,数据并行
5.GOSS:单边采样:保留大梯度样本,随机采样小梯度样本
6EFB:归并很少出现的特征为同一类
SVM
- 为什么要转化成对偶形式
方便核函数的引入(转化后为支持向量内积计算,核函数可以在低纬中计算高维的内积),改变复杂度(求W变成求a(支持向量数量)) - SVM的超参:C和gamma,C正则系数,gamma决定支持向量的数量
- SVM的核函数
有效性:核函数矩阵KK是对称半正定矩阵
常见核函数:线性核函数,多项式核函数,高斯核函数,指数核函数
区别:线性简单,可解释性强,只用于线性可分问题。多项式可解决非线性,参数太多。高斯只需要一个参数,计算慢,容易过拟合。 - 选择方式
特征维数高选择线性核
样本数量可观、特征少选择高斯核(非线性核)
样本数量非常多选择线性核(避免造成庞大的计算量)
EM
用于含有隐变量的概率模型参数的极大似然估计
深度学习
神经网络
https://zhuanlan.zhihu.com/p/351859343
RNN
RNN(循环神经网络)是一种使用循环连接处理顺序数据的神经网络。具体来说,它适合涉及序列的任务,例如自然语言处理、语音识别和时间序列分析。RNN 有一个内部存储器,允许它们保留来自先前输入的信息,并使用它根据整个序列的上下文做出预测或决策。
lstm
长短期记忆 (LSTM) 单元是一种循环 RNN 单元,旨在解决梯度消失问题并捕获长期依赖性。LSTM 单元包含记忆单元和门控机制来控制信息流。它们具有输入、输出和遗忘门,用于调节进出单元格的数据流,从而使 LSTM 能够随着时间的推移有选择地保留或丢弃信息。这使得 LSTM 能够捕获一些历史信息并克服传统 RNN 的局限性
LSTM的关键特性
-
记忆单元(Memory Cell):LSTM网络的核心是记忆单元,它可以在长时间内保持其状态。
-
门控机制(Gates)
:LSTM通过三种类型的门来控制信息流动,分别是遗忘门(Forget Gate)、输入门(Input Gate)和输出门(Output Gate)。
- 遗忘门:决定从单元状态中丢弃什么信息。
- 输入门:决定哪些新信息加入到单元状态。
- 输出门:决定基于当前单元状态的输出。
LSTM的工作原理
- 遗忘门:它通过一个Sigmoid层来决定哪些信息将被遗忘。这个门会查看前一个隐藏状态和当前的输入,输出一个在0到1之间的数值给每个在单元状态中的数字,1表示“完全保留”,0表示“完全遗忘”。
- 输入门:它包含两个部分:一个Sigmoid层和一个tanh层。Sigmoid层决定哪些值我们要更新,tanh层则创建一个新的候选值向量,这些值可以被加入到状态中。
- 更新单元状态:单元状态被更新,遗忘门告诉我们将丢弃什么旧信息,输入门告诉我们将加入什么新信息。
- 输出门:最后,输出是基于我们的单元状态的。首先,我们运行一个Sigmoid层来决定单元状态的哪些部分将输出。然后,将单元状态通过tanh(得到一个在-1到1之间的值)并将其乘以Sigmoid层的输出,以决定最终输出的哪些部分。
应用领域
transformer
https://zhuanlan.zhihu.com/p/338817680
Transformer是一种神经网络架构,主要用于序列到序列的任务,它引入了自注意力机制以处理输入序列。
损失函数:交叉熵损失函数
位置编码
位置编码主要分为绝对位置编码和相对位置编码两种,以前的语言模型使用绝对位置编码居多比如Bert、Roberta之类的,但是这些模型都会有个固定的最大长度512,不能后续扩展,需要来截断输入文本,这样会影响长文本的效果,后续的一些模型精力也主要放在相对位置编码的探索当中,相对位置编码能够显式的包含token之间的相对位置信息,也同时具有更加良好的外推性。
ROPE旋转位置编码是苏神提出来的一种相对位置编码,之前主要用在自研的语言模型roformer上,后续谷歌Palm和meta的LLaMA等都是采用此位置编码,通过复数形式来对于三角式绝对位置编码的改进。
Alibi 位置编码主要是Bloom模型采用,Alibi 的方法也算较为粗暴,是直接作用在attention score中,给 attention score 加上一个预设好的偏置矩阵,相当于 q 和 k 相对位置差 1 就加上一个 -1 的偏置。其实相当于假设两个 token 距离越远那么相互贡献也就越低。
https://dongnian.icu/note/llm/llm_concept/02.%E5%A4%A7%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E5%9F%BA%E7%A1%80/3.%E4%BD%8D%E7%BD%AE%E7%BC%96%E7%A0%81/3.%E4%BD%8D%E7%BD%AE%E7%BC%96%E7%A0%81.html
位置编码用于为模型提供输入序列中每个元素的位置信息,因为Transformer没有内建的关于元素位置的概念。它通常通过添加特定的位置编码向量来实现。
因为self-attention是位置无关的,无论句子的顺序是什么样的,通过self-attention计算的token的hidden embedding都是一样的,这显然不符合人类的思维。
transformer使用了固定的positional encoding来表示token在句子中的绝对位置信息。
编码器(Encoder)和解码器(Decoder)
编码器用于处理输入序列,将其编码为上下文表示,而解码器用于生成输出序列,利用编码器的信息来进行翻译、生成等任务。
输入数据
输入数据通常需要进行标记化和编码,以便与Transformer模型兼容。这包括将文本分词成标记,将标记转换为词嵌入向量,并添加位置编码。这样处理后,数据可以被送入Transformer模型进行训练和推理。
残差连接
残差连接允许信息在不同层之间流动,减轻了深层神经网络中的梯度消失问题。在Transformer中,它有助于保持输入序列的信息流,并促进更好的信息传递。
训练
Transformer模型通常使用反向传播算法和优化器(如Adam)进行监督学习。在训练过程中,模型通过最小化损失函数来调整权重,以使模型输出尽可能接近目标输出。这通常需要大规模的标记数据集。
自注意力机制
自注意力机制可以为输入序列中的每个元素分配权重,以便模型能够关注与当前任务相关的元素。在Transformer中,自注意力机制允许模型同时考虑输入序列中的所有位置,有助于捕捉长距离依赖关系。
核心思想是在处理序列数据时,网络应该更关注输入中的重要部分,而忽略不重要的部分,它通过学习不同部分的权重,将输入的序列中的重要部分显式地加权,从而使得模型可以更好地关注与输出有关的信息。
计算步骤
具体的计算步骤如下:
-
计算查询(Query):查询是当前时间步的输入,用于和序列中其他位置的信息进行比较。
-
计算键(Key)和值(Value):键表示序列中其他位置的信息,值是对应位置的表示。键和值用来和查询进行比较。
-
计算注意力权重:通过将查询和键进行内积运算,然后应用softmax函数,得到注意力权重。这些权重表示了在当前时间步,模型应该关注序列中其他位置的重要程度。
-
加权求和:根据注意力权重将值进行加权求和,得到当前时间步的输出。
在Transformer中,Self-Attention 被称为"Scaled Dot-Product Attention",其计算过程如下:
- 对于输入序列中的每个位置,通过计算其与所有其他位置之间的相似度得分(通常通过点积计算)。
- 对得分进行缩放处理,以防止梯度爆炸。
- 将得分用softmax函数转换为注意力权重,以便计算每个位置的加权和。
- 使用注意力权重对输入序列中的所有位置进行加权求和,得到每个位置的自注意输出。
attention和seq2seq的区别(也是RNN和Transform的区别)
传统的Seq2Seq模型只使用编码器来捕捉输入序列的信息,而解码器只从编码器的最后状态中获取信息,并将其用于生成输出序列。
而Attention机制则允许解码器在生成每个输出时,根据输入序列的不同部分给予不同的注意力,从而使得模型更好地关注到输入序列中的重要信息。
self-attention 和 target-attention的区别
自注意力主要关注序列内部的关系,而目标注意力则关注目标与其他对象之间的关系。
self-attention 在计算的过程中,如何对padding位做mask?
self-attention中,Q和K在点积之后,需要先经过mask再进行softmax,因此,对于要屏蔽的部分,mask之后的输出需要为负无穷,这样softmax之后输出才为0。
# Scaling by d_k so that the soft(arg)max doesn't explode
QK = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# Apply the mask
if mask is not None:
QK = QK.masked_fill(mask.to(QK.dtype) == 0, float('-inf'))
# Calculate the attention weights (softmax over the last dimension)
weights = F.softmax(QK, dim=-1)
多头注意力机制
注意力机制是用于根据输入数据的不同部分来分配不同的权重。
多头注意力允许模型在不同的表示子空间中学习关系,提高了模型的表达能力。它通过多个并行的注意力机制来处理输入,然后将它们组合在一起以获得更丰富的信息表示。
transformer中multi-head attention中每个head为什么要进行降维?
在Transformer的Multi-Head Attention中,对每个head进行降维是为了增加模型的表达能力和效率。
每个head是独立的注意力机制,它们可以学习不同类型的特征和关系。通过使用多个注意力头,Transformer可以并行地学习多种不同的特征表示,从而增强了模型的表示能力。
通过降低每个head的维度,Transformer可以在保持较高的表达能力的同时,大大减少计算复杂度。
为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根)
这取决于softmax函数的特性,如果softmax内计算的数数量级太大,会输出近似one-hot编码的形式,导致梯度消失的问题,所以需要scale
那么至于为什么需要用维度开根号,假设向量q,k满足各分量独立同分布,均值为0,方差为1,那么qk点积均值为0,方差为dk,从统计学计算,若果让qk点积的方差控制在1,需要将其除以dk的平方根,是的softmax更加平滑
代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
# Define the dimension of each head or subspace
self.d_k = d_model // self.num_heads
# These are still of dimension d_model. They will be split into number of heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
# Outputs of all sub-layers need to be of dimension d_model
self.W_o = nn.Linear(d_model, d_model)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
batch_size = Q.size(0)
K_length = K.size(-2)
# Scaling by d_k so that the soft(arg)max doesn't explode
QK = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# Apply the mask
if mask is not None:
QK = QK.masked_fill(mask.to(QK.dtype) == 0, float('-inf'))
# Calculate the attention weights (softmax over the last dimension)
weights = F.softmax(QK, dim=-1)
# Apply the self attention to the values
attention = torch.matmul(weights, V)
return attention, weights
def split_heads(self, x, batch_size):
"""
The original tensor with dimension batch_size * seq_length * d_model is split into num_heads
so we now have batch_size * num_heads * seq_length * d_k
"""
return x.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
# linear layers
q = self.W_q(q)
k = self.W_k(k)
v = self.W_v(v)
# split into multiple heads
q = self.split_heads(q, batch_size)
k = self.split_heads(k, batch_size)
v = self.split_heads(v, batch_size)
# self attention
scores, weights = self.scaled_dot_product_attention(q, k, v, mask)
# concatenate heads
concat = scores.transpose(1,2).contiguous().view(batch_size, -1, self.d_model)
# final linear layer
output = self.W_o(concat)
return output, weights
MQA
MQA的思想其实比较简单,MQA 与 MHA 不同的是,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头正常的只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
在 Multi-Query Attention 方法中只会保留一个单独的key-value头,这样虽然可以提升推理的速度,但是会带来精度上的损失。
GQA
在 MHA(Multi Head Attention)中,每个头有自己单独的 key-value 对;
在 MQA(Multi Query Attention)中只会有一组 key-value 对;
在 GQA(Grouped Query Attention)中,会对 attention 进行分组操作,query 被分为 N 组,每个组共享一个 Key 和 Value 矩阵。
GQA-N 是指具有 N 组的 Grouped Query Attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。
MHA,MQA,GQA之间的区别
MHA(Multi-head Attention)是标准的多头注意力机制,h个Query、Key 和 Value 矩阵。
MQA(Multi-Query Attention)是多查询注意力的一种变体,也是用于自回归解码的一种注意力机制。与MHA不同的是,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
GQA(Grouped-Query Attention)是分组查询注意力,GQA将查询头分成G组,每个组共享一个Key 和 Value 矩阵。GQA-G是指具有G组的grouped-query attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。
GQA介于MHA和MQA之间。GQA 综合 MHA 和 MQA ,既不损失太多性能,又能利用 MQA 的推理加速。不是所有 Q 头共享一组 KV,而是分组一定头数 Q 共享一组 KV,比如上图中就是两组 Q 共享一组 KV。
Tokenize
BPE
BPE是一种基于数据压缩算法的分词方法。它通过不断地合并出现频率最高的字符或者字符组合,来构建一个词表。具体来说,BPE的运算过程如下:
-
将所有单词按照字符分解为字母序列。例如:“hello”会被分解为[“h”,“e”,“l”,“l”,“o”]。
-
统计每个字母序列出现的频率,将频率最高的序列合并为一个新序列。
-
重复第二步,直到达到预定的词表大小或者无法再合并。
WordPiece
wordpiece算法可以看作是BPE的变种。不同的是,WordPiece基于概率生成新的subword而不是下一最高频字节对。WordPiece算法也是每次从词表中选出两个子词合并成新的子词。BPE选择频数最高的相邻子词合并,而WordPiece选择使得语言模型概率最大的相邻子词加入词表。
Unigram
与BPE或者WordPiece不同,Unigram的算法思想是从一个巨大的词汇表出发,再逐渐删除trim down其中的词汇,直到size满足预定义。
初始的词汇表可以采用所有预分词器分出来的词,再加上所有高频的子串。
每次从词汇表中删除词汇的原则是使预定义的损失最小。
Unigram算法每次会从词汇表中挑出使得loss增长最小的10%~20%的词汇来删除。
一般Unigram算法会与SentencePiece算法连用。
SentencePiece
它是把一个句子看作一个整体,再拆成片段,而没有保留天然的词语的概念。一般地,它把空格space也当作一种特殊字符来处理,再用BPE或者Unigram算法来构造词汇表。
预训练模型
T5, BERT, GPT区别
Encoder: 将文本映射到向量空间; Decoder: 将向量映射到文本空间。
BERT,是一个Transformer encoder结构(双向attention)
GPT,是一个Transformer decoder结构(单向attention,从左到右)
T5不仅仅是BERT+GPT模型,T5 encoder和decoder间的关联除了上面提到的hidden vector,还有cross attention。
T5淡化了中间的hidden vector(通过encoder得到),把encoder和decoder连为一体
bert
BERT通过使用掩码语言建模的自监督学习任务进行预训练,预测输入文本中的掩码标记。然后,模型的权重可以在下游任务中微调,通过将任务特定的标记数据与BERT的预训练参数结合,以提高性能。
BERT可以使用字粒度(character-level)和词粒度(word-level)两种方式来进行文本表示,它们各自有优缺点:
字粒度(Character-level):
- 优点:处理未登录词(Out-of-Vocabulary,OOV):字粒度可以处理任意字符串,包括未登录词,不需要像词粒度那样遇到未登录词就忽略或使用特殊标记。对于少见词和低频词,字粒度可以学习更丰富的字符级别表示,使得模型能够更好地捕捉词汇的细粒度信息。
- 缺点:计算复杂度高:使用字粒度会导致输入序列的长度大大增加,进而增加模型的计算复杂度和内存消耗。需要更多的训练数据:字粒度模型对于少见词和低频词需要更多的训练数据来学习有效的字符级别表示,否则可能会导致过拟合。
词粒度(Word-level):
- 优点:计算效率高:使用词粒度可以大大减少输入序列的长度,从而降低模型的计算复杂度和内存消耗。学习到更加稳定的词级别表示:词粒度模型可以学习到更加稳定的词级别表示,特别是对于高频词和常见词,有更好的表示能力。
- 缺点:处理未登录词(OOV):词粒度模型无法处理未登录词,遇到未登录词时需要采用特殊处理(如使用未登录词的特殊标记或直接忽略)。对于多音字等形态复杂的词汇,可能无法准确捕捉其细粒度的信息。
输入
BERT模型的输入主要包含三部分,分别是
① token embedding词向量
② segment embedding段落向量
③ position embedding位置向量。
BERT输入与Transformer的区别
Transformer的输入只包含两部分,token embedding词向量和position encoding位置向量,且position encoding用的是函数式(正余弦函数),BERT的position embedding位置向量是参数式(可学习的),且segment embedding段落向量用于区分两个句子(第一个句子为0,第二个句子为1)。
输出
BERT模型的输出为每个token对应的向量
两个预训练任务
BERT模型的预训练任务主要包含两个, 一个是MLM(Masked Language Model),一个是NSP(Next Sentence Prediction),BERT 预训练阶段实际上是将上述两个任务结合起来,同时进行,然后将所有的 Loss 相加。
Masked Language Model 可以理解为完形填空,随机mask每一个句子中15%的词,用其上下文来做预测。
而这样会导致预训练阶段与下游任务阶段之间的不一致性(下游任务中没有【MASK】),为了缓解这个问题,会按概率选择以下三种操作:
例如:my dog is hairy → my dog is [MASK]
80%的是采用[mask],my dog is hairy → my dog is [MASK]
10%的是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
10%的保持不变,my dog is hairy -> my dog is hairy
Next Sentence Prediction可以理解为预测两段文本的蕴含关系(分类任务),选择一些句子对A与B,其中50%的数据B是A的下一条句子(正样本),剩余50%的数据B是语料库中随机选择的(负样本),学习其中的相关性。
前面提到序列的头部会填充一个[CLS]标识符,该符号对应的bert输出值通常用来直接表示句向量。
下游任务
BERT模型在经过大规模数据的预训练后,可以将预训练模型应用在各种各样的下游任务中。使用方式主要有两种:一种是特征提取,一种是模型精调。
**特征提取:**仅使用BERT提取输入文本特征,生成对应上下文的语义表示,来进行下游任务的训练(BERT本身不参与训练);
**模型精调:**利用BERT作为下游任务模型基底,生成文本对应的上下文语义表示,并参与到下游任务的训练。
常见的下游任务有四种:单句文本分类、句子对文本分类、阅读理解和序列标注等。
BERT的Encoder与Decoder掩码有什么区别?
Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?
(为什么需要decoder自注意力需要进行 sequence mask)
Encoder主要使用自注意力掩码和填充掩码,而Decoder除了自注意力掩码外,还需要使用编码器-解码器注意力掩码来避免未来位置信息的泄露。这些掩码操作保证了Transformer在处理自然语言序列时能够准确、有效地进行计算,从而获得更好的表现。
让输入序列只看到过去的信息,不能让他看到未来的信息
BERT使用的是Transformer中的Encoder部分,而不是Decoder部分。
Transformer模型由Encoder和Decoder两个部分组成。Encoder用于将输入序列编码为一系列高级表示,而Decoder用于基于这些表示生成输出序列。
在BERT模型中,只使用了Transformer的Encoder部分,并且对其进行了一些修改和自定义的预训练任务,而没有使用Transformer的Decoder部分。
BERT非线性的来源在哪里?
主要来自两个地方:前馈层的gelu激活函数和self-attention。
- 前馈神经网络层:在BERT的Encoder中,每个自注意力层之后都跟着一个前馈神经网络层。前馈神经网络层是全连接的神经网络,通常包括一个线性变换和一个非线性的激活函数,如gelu。这样的非线性激活函数引入了非线性变换,使得模型能够学习更加复杂的特征表示。
- self-attention layer:在自注意力层中,查询(Query)、键(Key)、值(Value)之间的点积得分会经过softmax操作,形成注意力权重,然后将这些权重与值向量相乘得到每个位置的自注意输出。这个过程中涉及了softmax操作,使得模型的计算是非线性的。
gpt
GPT是一种基于Transformer的预训练模型,与BERT不同,它是一个自回归语言模型,可以生成连续文本。其独特之处在于使用单向上下文建模,适用于生成式任务,如文本生成和对话系统。
框架
pytorch
pytorch中train和eval有什么不同
(1). model.train()——训练时候启用
启用 BatchNormalization 和 Dropout,将BatchNormalization和Dropout置为True
(2). model.eval()——验证和测试时候启用
不启用 BatchNormalization 和 Dropout,将BatchNormalization和Dropout置为False
train模式会计算梯度,eval模式不会计算梯度。
pytorch如何微调fine tuning:在加载了预训练模型参数之后,需要finetuning模型,可以使用不同的方式finetune
局部微调:加载了模型参数后,只想调节最后几层,其它层不训练,也就是不进行梯度计算,pytorch提供的requires_grad使得对训练的控制变得非常简单
model = torchvision.models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
# 替换最后的全连接层, 改为训练100类
# 新构造的模块的参数默认requires_grad为True
model.fc = nn.Linear(512, 100)
# 只优化最后的分类层
optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)
全局微调:对全局微调时,只不过我们希望改换过的层和其他层的学习速率不一样,这时候把其它层和新层在optimizer中单独赋予不同的学习速率。
ignored_params = list(map(id, model.fc.parameters()))
base_params = filter(lambda p: id(p) not in ignored_params,
model.parameters())
optimizer = torch.optim.SGD([
{'params': base_params},
{'params': model.fc.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)
tensorflow
tensorflow中节点和边代表的什么
(1)节点代表着多种功能,比如说输入,变量初始化,运算,控制,输出等;
(2)边代表输入与输出之间的关系,即数据流动的方向。
大模型
embedding
m3e
微调
Adapter Tuning、Prompt Tuning、Prefix Tuning、P-Tuning、P-Tuning v2 和 AdaLoRA
bigfit
BitFit(论文:BitFit: Simple Parameter-efficient Fine-tuning or Transformer-based Masked Language-models)是一种稀疏的微调方法,它训练时只更新bias的参数或者部分bias参数。
RLHF
RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,这里我们按三个步骤分解:
- 预训练一个语言模型 (LM) ;由专门的研究人员去进行模型生成结果好坏的的评价。(耗费人力)
- 聚合问答数据并训练一个奖励模型 (Reward Model,RM) ;
- 用强化学习 (RL) 方式微调 LM。
RLHF 的局限性
虽然以ChatGPT为代表的RLHF技术非常有影响力,引发了巨大的关注,但仍然存在若干局限性:
- RLHF 范式训练出来的这些模型虽然效果更好,但仍然可能输出有害或事实上不准确的文本。这种不完美则是 RLHF 的长期挑战和优化目标。
- 在基于 RLHF 范式训练模型时,人工标注的成本是非常高昂的,而 RLHF 性能最终仅能达到标注人员的知识水平。此外,这里的人工标注主要是为RM模型标注输出文本的排序结果,而若想要用人工去撰写答案的方式来训练模型,那成本更是不可想象的。
- RLHF的流程还有很多值得改进的地方,其中,改进 RL 优化器显得尤为重要。PPO 是一种基于信赖域优化的相对较旧的RL算法,但没有其他更好的算法来优化 RLHF 了。
Instruction-tuning、Fine-tuning、Prompt-Tuning的区别在哪?
Fine-tuning:先在大规模语料上进行预训练,然后再在某个下游任务上进行微调,如BERT、T5;
Prompt-tuning:先选择某个通用的大规模预训练模型,然后为具体的任务生成一个prompt模板以适应大模型进行微调,如GPT-3;
Instruction-tuning:仍然在预训练语言模型的基础上,先在多个已知任务上进行微调(通过自然语言的形式),然后再推理某个新任务上进行zero-shot。
Adapter Tuning
在微调时,除了Adapter的部分,其余的参数都是被冻住的(freeze)
但这样的设计架构存在一个显著劣势:添加了Adapter后,模型整体的层数变深,会增加训练速度和推理速度,原因是:
- 需要耗费额外的运算量在Adapter上
- 当我们采用并行训练时(例如Transformer架构常用的张量模型并行),Adapter层会产生额外的通讯量,增加通讯时间
Prefix Tuning
作者通过对输入数据增加前缀(prefix)来做微调。当然,prefix也可以不止加载输入层,还可以加在Transformer Layer输出的中间层
对于GPT这样的生成式模型,在输入序列的最前面加入prefix token,图例中加入2个prefix token,在实际应用中,prefix token的个数是个超参,可以根据模型实际微调效果进行调整。对于BART这样的Encoder-Decoder架构模型,则在x和y的前面同时添加prefix token。在后续微调中,我们只需要冻住模型其余部分,单独训练prefix token相关的参数即可,每个下游任务都可以单独训练一套prefix token。
那么prefix的含义是什么呢?prefix的作用是引导模型提取x相关的信息,进而更好地生成y。例如,我们要做一个summarization的任务,那么经过微调后,prefix就能领悟到当前要做的是个“总结形式”的任务,然后引导模型去x中提炼关键信息;如果我们要做一个情感分类的任务,prefix就能引导模型去提炼出x中和情感相关的语义信息,以此类推。
Prefix Tuning虽然看起来方便,但也存在以下两个显著劣势;
- 较难训练,且模型的效果并不严格随prefix参数量的增加而上升,这点在原始论文中也有指出
- 会使得输入层有效信息长度减少。为了节省计算量和显存,我们一般会固定输入数据长度。增加了prefix之后,留给原始文字数据的空间就少了,因此可能会降低原始文字中prompt的表达能力。
lora
https://zhuanlan.zhihu.com/p/646831196
全参数微调太贵,Adapter Tuning存在训练和推理延迟,Prefix Tuning难训且会减少原始训练数据中的有效文字长度
全参数finetune可以理解成“冻住的预训练权重” + “微调过程中产生的权重更新量”。
lora就是在原始预训练矩阵的旁路上,用低秩矩阵A和B来近似替代增量更新
为什么LoRA又能从整体上降低显存使用呢,因为:
- LoRA并不是作用在模型的每一层,例如论文里的LoRA只作用在attention部分
- LoRA虽然会导致某一层的峰值显存高于全量微调,但计算完梯度后,这个中间结果就可以被清掉了,不会一致保存
- 当待训练权重从
d*d降为2*r*d时,需要保存的optimizer states也减少了(那可是fp32)。

P-Tuning v1
P-Tuning 方法的提出主要是为了解决这样一个问题:大模型的 Prompt 构造方式严重影响下游任务的效果。
P-Tuning 提出将 Prompt 转换为可以学习的 Embedding 层,只是考虑到直接对 Embedding 参数进行优化会存在这样两个挑战:
- Discretenes: 对输入正常语料的 Embedding 层已经经过预训练,而如果直接对输入的 prompt embedding进行随机初始化训练,容易陷入局部最优。
- Association:没法捕捉到 prompt embedding 之间的相关关系。
作者在这里提出用 MLP + LSTM 的方式来对 prompt embedding 进行一层处理
依然是固定 LLM 参数,利用多层感知机和 LSTM 对 Prompt 进行编码,编码之后与其他向量进行拼接之后正常输入 LLM。
P-Tuning 和 Prefix-Tuning 差不多同时提出,做法其实也有一些相似之处,主要区别在:
- Prefix Tuning 是将额外的 embedding 加在开头,看起来更像是模仿 Instruction 指令;而 P-Tuning 的位置则不固定。
- Prefix Tuning 通过在每个 Attention 层都加入 Prefix Embedding 来增加额外的参数,通过 MLP 来初始化;而 P-Tuning 只是在输入的时候加入 Embedding,并通过 LSTM+MLP 来初始化。
P-Tuning v2
P-Tuning v1 的问题是在小参数量模型上表现差
P-Tuning v2 的目标就是要让 Prompt Tuning 能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌 Fine-tuning 的结果。
那也就是说当前 Prompt Tuning 方法在这两个方面都存在局限性。
- 不同模型规模:Prompt Tuning 和 P-tuning 这两种方法都是在预训练模型参数规模够足够大时,才能达到和Fine-tuning 类似的效果,而参数规模较小时效果则很差。
- 不同任务类型:Prompt Tuning 和 P-tuning 这两种方法在 sequence tagging 任务上表现都很差。
prompt-tuning
简单总结就是说Prompt就是利用语言模型的生成能力帮我们完成任务。而Prompt-tuning的目的就是设计更加精巧的prompt,然后让模型输出我们想要的内容。
以句子的情感分类为例,基于prompt方式让模型做情感分类任务的做法通常是在句子前面加入前缀“该句子的情感是”即可。
本质上BERT这样的模型是一种生成模型,是无法完成特定任务的。它只是一个提取文本特征的通用模型。
当你在句子前加入“该句子的情感是”这样的前缀,你实际上是将情感分类任务转换为一个“填空”任务。这是因为,在训练过程中,BERT可以学习到这个前缀与句子情感之间的关联。例如,它可以学习到“该句子的情感是积极的”和“该句子的情感是消极的”之间的差异。
以bert作为举例,假设任务是文本分类。“今天天气很好。”我们想判断一下这句话的情感是正面还是负面
fine-tune的方法是在bert之后接一个head,然后调整整个模型。
prompt 的方法是把下游任务转化为预训练任务,我们知道bert的预训练任务是MLM,于是把
“今天天气很好。”转化为“今天天气很好。我很[mask][mask]”,我们希望bert预测出"开心"两个字。然后对“开心”映射到正面情感。
prompt-tuning:我们知道prompt的方法是把下游任务转化为预训练任务,但是怎么转化效果会好呢。比如如下几种prompt:
1.“今天天气很好。我很[mask][mask]”
2.“今天天气很好。我非常[mask][mask]”
3.“今天天气很好。我的心情是[mask][mask]”
我们并不知道哪种prompt是最好的,于是我们希望模型可以自己去学习,于是就提出了prompt-tuning(提示微调),该方法会固定预训练模型的参数(与fine-tune不同之处),增加额外的参数来训练,常见的方法有prompt-tuning, prefix-tuning, p-tuning,与fine-tune不同,可训练参数一般都是加载embbeding层,而不是加在最后
instruction-Tuning
与Prompt不同,Instruction通常是一种更详细的文本,用于指导模型执行特定操作或完成任务。Instruction可以是计算机程序或脚本,也可以是人类编写的指导性文本。Instruction的目的是告诉模型如何处理数据或执行某个操作,而不是简单地提供上下文或任务相关信息。
因此,Prompt和Instruction都是用于指导模型生成输出的文本,但它们的目的和使用方式是不同的。Prompt更多地用于帮助模型理解任务和上下文,而Instruction则更多地用于指导模型执行具体操作或完成任务。
Instruction可以提供更直接的任务指导,以帮助模型执行任务。对于问答任务,Instruction可以提供具体的指令,例如“请回答下列问题:谁是美国第一位总统?”,并将文本段落作为输入提供给模型。
以InstructGPT为例,其基本流程如下:
- 准备自然语言指令集:针对特定任务,准备一组自然语言指令,描述任务类型和任务目标,例如情感分类任务的指令可以是“该文本的情感是正面的还是负面的?”。
- 准备训练数据集:针对特定任务,准备一个标记化的数据集,其中每个数据样本都包含输入文本和标签,例如情感分类任务的标签可以是“正面”或“负面”。
- 将自然语言指令和数据集转换为模型输入:将自然语言指令和数据集转换为模型输入,例如对于情感分类任务,将自然语言指令和文本拼接作为输入,例如:“该文本的情感是正面的还是负面的?这家餐厅的食物很好吃。”
- 在指令上进行微调:在指令上进行微调,以适应特定任务的需求,提高模型在任务上的性能。
多轮对话
假设多轮为Q1A1/Q2A2/Q3A3,那么可以转化成 Q1—>A1, Q1A1Q2->A2, Q1A1Q2A2Q3->A3三条训练样本。
面试官:这样的话一个session变成了三条数据,并且上文有依次重复的情况,这样会不会有啥问题?
你:数据中大部分都是pad token,训练数据利用效率低下。另外会有数据重复膨胀的问题,训练数据重复膨胀为 session数量*平均轮次数,且上文有重复部分,训练效率也会低下。
面试官:你也意识到了,有什么改进的方法吗?
你:有没有办法能一次性构造一个session作为训练样本呢?(思索)
面试官:提示你下,限制在decoder-only系列的模型上,利用模型特性,改进样本组织形式。
prompt
cot
以下是一个简单的示例,说明语言模型如何解决一个数学问题:
问题:计算 3 * (4 + 5)
使用 chain-of-thought,我们可以将问题分解成以下步骤:
- 将问题输入模型:“计算 3 * (4 + 5)”
- 模型输出第一步的结果:“计算 4 + 5”
- 将上一步的结果作为输入,再次输入模型:“计算 3 * 9”
- 模型输出最终结果:“结果是 27”
在这个例子中,我们可以看到模型是如何通过一系列连贯的思考链(步骤)来逐步解决问题的。那么这样的能力是如何获得的?这就是chain-of-thought技术。通过思维链式方法训练大型语言模型需要将训练过程分解成较小、相互关联的任务,以帮助模型理解和生成连贯、上下文感知的响应。
强化学习
https://mp.weixin.qq.com/s/R6eFiv3Iczli2nNCfOt6gg
https://www.cnblogs.com/jiangxinyang/p/17553815.html
https://github.com/zixian2021/AI-interview-cards/blob/a75e06fdcdea97849d5a06d2d74d9bd435993ac2/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0%E9%9D%A2%E8%AF%95%E9%A2%98%2033a57369e58e46a9a6e4d073a2230a5e.md
LLM
RM(奖励模型)的数据格式?
在大语言模型训练中,RM(Reward Model,奖励模型)的数据格式可以采用以下方式:
输入数据:输入数据是一个文本序列,通常是一个句子或者一个段落。每个样本可以是一个字符串或者是一个tokenized的文本序列。
奖励数据:奖励数据是与输入数据对应的奖励或评分。奖励可以是一个实数值,表示对输入数据的评价。也可以是一个离散的标签,表示对输入数据的分类。奖励数据可以是人工标注的,也可以是通过其他方式(如人工评估、强化学习等)得到的。
数据集格式:数据集可以以文本文件(如CSV、JSON等)或数据库的形式存储。每个样本包含输入数据和对应的奖励数据。可以使用表格形式存储数据,每一列代表一个特征或标签。
下面是一个示例数据集的格式:
Input,Reward
“This is a sentence.”,0.8
“Another sentence.”,0.2
…
在这个示例中,输入数据是一个句子,奖励数据是一个实数值,表示对输入数据的评价。每一行代表一个样本,第一列是输入数据,第二列是对应的奖励数据。
需要注意的是,具体的数据集格式可能会因任务类型、数据来源和使用的深度学习框架而有所不同。因此,在使用RM进行大语言模型训练时,建议根据具体任务和框架的要求来定义和处理数据集格式。
PPO(强化学习)的数据格式?
在大语言模型训练中,PPO(Proximal Policy Optimization,近端策略优化)是一种常用的强化学习算法。PPO的数据格式可以采用以下方式:
输入数据:输入数据是一个文本序列,通常是一个句子或者一个段落。每个样本可以是一个字符串或者是一个tokenized的文本序列。
奖励数据:奖励数据是与输入数据对应的奖励或评分。奖励可以是一个实数值,表示对输入数据的评价。也可以是一个离散的标签,表示对输入数据的分类。奖励数据可以是人工标注的,也可以是通过其他方式(如人工评估、模型评估等)得到的。
动作数据:动作数据是模型在给定输入数据下的输出动作。对于语言模型,动作通常是生成的文本序列。动作数据可以是一个字符串或者是一个tokenized的文本序列。
状态数据:状态数据是模型在给定输入数据和动作数据下的状态信息。对于语言模型,状态数据可以是模型的隐藏状态或其他中间表示。状态数据的具体形式可以根据具体任务和模型结构进行定义。
数据集格式:数据集可以以文本文件(如CSV、JSON等)或数据库的形式存储。每个样本包含输入数据、奖励数据、动作数据和状态数据。可以使用表格形式存储数据,每一列代表一个特征或标签。
下面是一个示例数据集的格式:
Input,Reward,Action,State
“This is a sentence.”,0.8,“This is a generated sentence.”,[0.1, 0.2, 0.3, …]
“Another sentence.”,0.2,“Another generated sentence.”,[0.4, 0.5, 0.6, …]
…
在这个示例中,输入数据是一个句子,奖励数据是一个实数值,动作数据是生成的句子,状态数据是模型的隐藏状态。每一行代表一个样本,第一列是输入数据,第二列是对应的奖励数据,第三列是生成的动作数据,第四列是状态数据。
需要注意的是,具体的数据集格式可能会因任务类型、数据来源和使用的深度学习框架而有所不同。因此,在使用PPO进行大语言模型训练时,建议根据具体任务和框架的要求来定义和处理数据集格式。
开源模型
LLama
chatglm
chatglm跟gpt的区别:
chatglm是编码器加解码器架构,gpt是解码器架构
chatglm是sft训练的方法,gpt是rlhf训练的方法
ChatGLM
chatglm 首先要说起它的基座 GLM, GLM 既可以做 Encoder 也可以做 Decoder,主要通过两种mask方式来实现:
- [mask]:bert形式,随机 mask 文本中的 短span
- [gmask]:gpt 形式,mask 末尾的 长 span
在chatglm里面做生成任务时,是用 [gmask]。chaglm 2 中完全采用 gmask 来进行预训练。
在ChatGLM 的内部结构中的变换,从下到上依次是:
- 位置编码:从BERT的训练式位置编码转变为旋转位置编码
- 激活函数:从BERT中的 GeLU 转变为 GLU, 在ChatGLM 2 中又变成了 SwiGLU
- LayerNormalization:采用的是DeepNorm,是对post-Normalization 的改进,即在残差之后做 Normalization。在 ChatGLM中,把 layer-normalization 改为 RMSNormalization。
在ChatGLM 2.0 中还添加了一些其他变化:
- FlashAttenion:利用显存和内存来做加速
- Multi-Query Attention:多个头只采用一个 KV对,通过参数共享来降低显存占用。
baichuan
开源项目
autogpt
AutoGPT是一个程序,它基于GPT大模型对自然语言的理解能力,能基于用户下达的需求自动的拆解需求和制定计划,并利用AutoGPT程序里内置的一些基本能力(如文件的读写、数据库、逻辑运算、内存、其他小模型的能力)来执行计划并拿到中间数据,最终利用这些中间数据和多轮的自主迭代来完成用户的需求。
AutoGPT这个程序的一个核心部分,这里定义了AutoGPT内置的基础命令及命令所需的参数,比如使用google搜索关键字、使用浏览器抓取网页数据、使用语言模型进行文本数据分析、文件的读写等操作。AutoGPT就是通过这些内置的命令,给GPT插上了手脚,让它有了记忆,有了联网等能力。
langchain
autogen
AutoGen框架的核心是其代理协同工作的能力。每个代理都有其特定的能力和角色,你需要定义代理之间的互动行为,即当一个代理从另一个代理收到消息时该如何回复。这种方式不仅仅是在定义代理和角色,还在定义它们如何协同工作,从而实现更优的任务完成效果。
AutoGen提供了一个多agent系统的通用框架,满足各种实际需求,例如重用、定制和扩展现有agent,以及为它们之间的对话编程。每个agent都可以单独开发、测试和维护,这种方法简化了整体开发和代码管理。通过使用多个代理的交流合作,增强了解决问题的能力。
常规算法题
leetcode开根号
合并排序的数组 lc原题
螺旋数组
最长无重复子串
编辑距离
力扣上的区间合并
手撕两数之和
- [gmask]:gpt 形式,mask 末尾的 长 span
在chatglm里面做生成任务时,是用 [gmask]。chaglm 2 中完全采用 gmask 来进行预训练。
在ChatGLM 的内部结构中的变换,从下到上依次是:
- 位置编码:从BERT的训练式位置编码转变为旋转位置编码
- 激活函数:从BERT中的 GeLU 转变为 GLU, 在ChatGLM 2 中又变成了 SwiGLU
- LayerNormalization:采用的是DeepNorm,是对post-Normalization 的改进,即在残差之后做 Normalization。在 ChatGLM中,把 layer-normalization 改为 RMSNormalization。
在ChatGLM 2.0 中还添加了一些其他变化:
- FlashAttenion:利用显存和内存来做加速
- Multi-Query Attention:多个头只采用一个 KV对,通过参数共享来降低显存占用。
baichuan
开源项目
autogpt
AutoGPT是一个程序,它基于GPT大模型对自然语言的理解能力,能基于用户下达的需求自动的拆解需求和制定计划,并利用AutoGPT程序里内置的一些基本能力(如文件的读写、数据库、逻辑运算、内存、其他小模型的能力)来执行计划并拿到中间数据,最终利用这些中间数据和多轮的自主迭代来完成用户的需求。
AutoGPT这个程序的一个核心部分,这里定义了AutoGPT内置的基础命令及命令所需的参数,比如使用google搜索关键字、使用浏览器抓取网页数据、使用语言模型进行文本数据分析、文件的读写等操作。AutoGPT就是通过这些内置的命令,给GPT插上了手脚,让它有了记忆,有了联网等能力。
langchain
autogen
AutoGen框架的核心是其代理协同工作的能力。每个代理都有其特定的能力和角色,你需要定义代理之间的互动行为,即当一个代理从另一个代理收到消息时该如何回复。这种方式不仅仅是在定义代理和角色,还在定义它们如何协同工作,从而实现更优的任务完成效果。
AutoGen提供了一个多agent系统的通用框架,满足各种实际需求,例如重用、定制和扩展现有agent,以及为它们之间的对话编程。每个agent都可以单独开发、测试和维护,这种方法简化了整体开发和代码管理。通过使用多个代理的交流合作,增强了解决问题的能力。
常规算法题
leetcode开根号
合并排序的数组 lc原题
螺旋数组
最长无重复子串
编辑距离
力扣上的区间合并
手撕两数之和