什么是无头浏览器?
我们都知道,用户界面(UI)是任何软件中最重要的部分。因此,“无头浏览器”的“无头”部分意味着它们确实缺少一个关键元素,即图形用户界面(GUI)。
这意味着浏览器本身可以在后台正常运行(联系目标网站、上传/下载文档、呈现信息等),但你看不到任何东西。
相反,软件测试工程师更喜欢使用像“命令行”这样的界面,其中命令作为文本行处理。
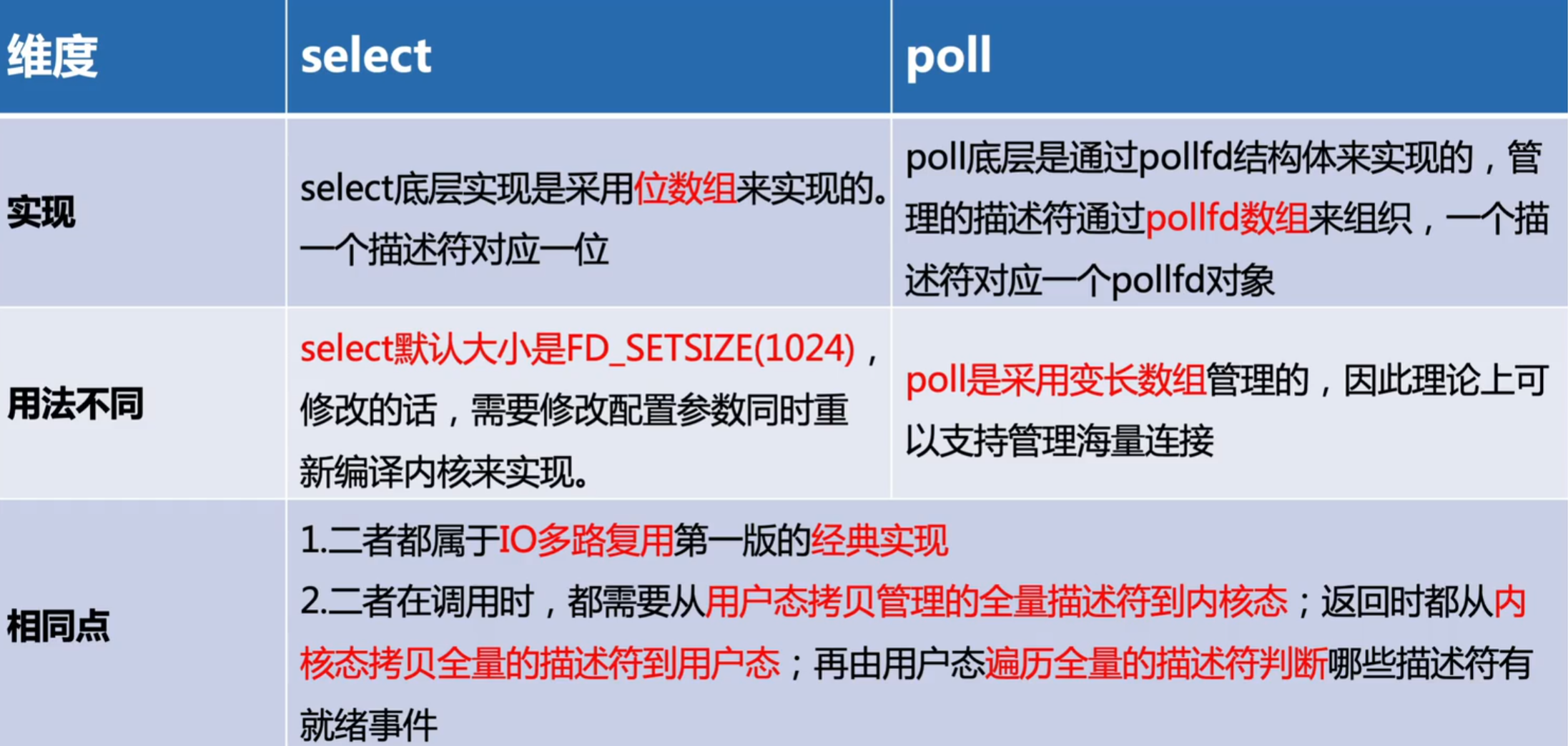
如何检测无头Chrome?
无头浏览器示例
- Headlesschrome
- Chromium
- Firefox Headless
- HTML Unit
- Apple Safari (Webkit)
- Zombie.JS
- PhantomJS
- Splash
为什么Puppeteer最适合网页抓取?
Puppeteer是Google开发的一个开源Node.js库,提供了控制无头Chrome或Chromium浏览器的高级API。以下7个优势说明了为什么开发人员更喜欢使用它进行网页抓取。
1. 无头Chrome自动化
Puppeteer操作无头版的Google Chrome,这意味着它可以在没有图形用户界面的情况下运行。这允许更快、更高效的抓取,因为它减少了与渲染完整浏览器窗口相关的开销。
2. JavaScript执行
许多现代网站严重依赖JavaScript动态加载内容。传统的抓取工具通常难以处理此类网站。然而,Puppeteer可以像真实浏览器一样执行JavaScript,确保所有动态内容完全加载并可供抓取。
3. 高质量API
Puppeteer提供了高质量的API,可以精确控制浏览器。这包括点击按钮、填写表单和在页面之间导航等操作,这些对于抓取复杂网站至关重要。
4. 自动截图
Puppeteer的一个功能是能够自动截图。这对于调试和验证内容是否正确加载非常有用,然后进行抓取。
5. 跨浏览器测试
Puppeteer支持跨浏览器测试,这意味着你可以在不同的浏览器(如Chrome和Firefox)上测试和抓取网站。这种灵活性确保你的抓取脚本稳健并能处理各种网络环境。
6. 社区和扩展
Puppeteer拥有强大的社区,并与TeamCity、Jenkins和TravisCI等其他工具有良好集成。这使得更容易找到支持和增强抓取任务的扩展。
7. 模拟真实用户交互
Puppeteer可以模拟真实用户交互,例如鼠标移动和键盘输入。这使得网站更难检测和阻止抓取活动,因为这些交互看起来更像是人类行为。
如何使用Puppeteer抓取网站?
现在,我将向你展示如何使用Nstbrowserles完成抓取!
让我们以抓取TikTok首页Explore页面上的视频链接地址为例具体说明:
你可能还喜欢: 如何使用Playwright抓取头像。
第一步 页面分析
我们需要:
- 进入TikTok首页。
- 打开控制台元素页面并定位Explore页面元素。此元素是具有
data-e2e="nav-explore"属性的a链接元素标签。

点击上面的元素进入预览页面以进行进一步分析。
我们可以发现我们想要的目标数据属于具有data-e2e="explore-item-list"属性的列表元素下的一个div元素项。
每个视频元素由data-e2e="explore-item"表示,我们想要的视频链接是其下的div a链接标签的href属性值。

成功定位到我们需要的元素后,我们可以进入抓取过程:
第二步 使用Nstbrowserless,你必须预先安装并运行Docker。
# 拉取镜像
docker pull nstbrowser/browserless:0.0.1-beta
# 运行nstbrowserless
docker run -it -e TOKEN=xxx -e SERVER_PORT=8848 -p 8848:8848 --name nstbrowserless nstbrowser/browserless:0.0.1-beta第三步 编码 (Python-Pyppeteer)
现在我们需要设置Nstbrowser为无头模式
import json
from urllib.parse import urlencode
from pyppeteer import launcher
async def main():
config = {
"once": True,
"headless": True, # 支持:true或false
"autoClose": True,
"args": ["--disable-gpu", "--no-sandbox"], # 浏览器参数应为列表
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # 支持:windows, mac, linux
"kernel": 'chromium', # 仅支持:chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # 支持:2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # 支持:2, 4, 8
},
}
query = {
'config': json.dumps(config)
}
browser = await launcher.connect(
browserWSEndpoint=f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
)
page = await browser.newPage()
await page.goto('chrome://version')
await page.screenshot({'path': 'chrome_version.png'})
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())运行上述代码后,你可以在chrome://version页面上看到以下信息:

在内核启动命令中添加--headless参数表示内核以无头模式运行。
整体代码展示:
import json
from urllib.parse import urlencode
from pyppeteer import launcher
async def main():
config = {
"once": True,
"headless": True, # 支持:true或false
"autoClose": True,
"args": ["--disable-gpu", "--no-sandbox"], # 浏览器参数应为列表
"fingerprint": {
"name": 'tiktok_scraper',
"platform": 'windows', # 支持:windows, mac, linux
"kernel": 'chromium', # 仅支持:chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8, # 支持:2, 4, 8, 10, 12, 14, 16
"deviceMemory": 8, # 支持:2, 4, 8
},
"proxy": "", # 如果你无法浏览TikTok网站,请设置适当的代理
}
query = {
'config': json.dumps(config)
}
browser = await launcher.connect(
browserWSEndpoint=f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
)
try:
# 创建新页面
page = await browser.newPage()
await page.goto("https://www.tiktok.com/")
await page.waitForSelector('[data-e2e="nav-explore"]', {'timeout': 30000})
explore_elem = await page.querySelector('[data-e2e="nav-explore"]')
if explore_elem:
await explore_elem.click()
await page.waitForSelector('[data-e2e="explore-item-list"]', {'timeout': 30000})
ul_element = await page.querySelector('[data-e2e="explore-item-list"]')
if ul_element:
li_elements = await ul_element.querySelectorAll('div')
href
s = []
for li in li_elements:
a_element = await li.querySelector('[data-e2e="explore-item"] div a')
if a_element:
href = await page.evaluate('(element) => element.getAttribute("href")', a_element)
if href:
print(href)
hrefs.append(href)
# TODO
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())抓取结果:

到目前为止,我们已经完成了使用Nstbrowserless抓取TikTok视频链接的操作。获得链接后,你可以进一步完成你想要的操作,例如存储、下载视频或重定向播放。
无头Chrome总是好吗?
虽然无头浏览器在网页抓取和自动化中非常重要,但实际上它并非全都是优点。在使用之前请仔细考虑以下优缺点:
优点:
- 无头Chrome在从目标网站提取特定数据点(例如竞争对手产品定价)时更高效。
- 无头浏览器比常规浏览器更快——它们加载CSS和JavaScript的速度更快,并且不需要打开和渲染HTML。
- 无头浏览器为开发人员节省时间,例如在执行单元测试代码更改(移动和桌面)时,可以使用命令行完成。
缺点:
- 无头浏览器操作仅限于后台任务,这意味着它无法解决前端问题(例如生成GUI截图)。
- 无头浏览器提高了速度,但有时会有代价,例如调试问题变得更加困难。
重点总结
无头Chrome为网页抓取过程提供了许多好处,只需几行代码即可实现抓取和自动化。它最小化内存使用,完美处理JavaScript,并在无GUI环境中运行。
在本指南中,你学习了:
- 什么是无头浏览器?
- Puppeteer用于网页抓取的优势
- Puppeteer网页抓取的详细步骤