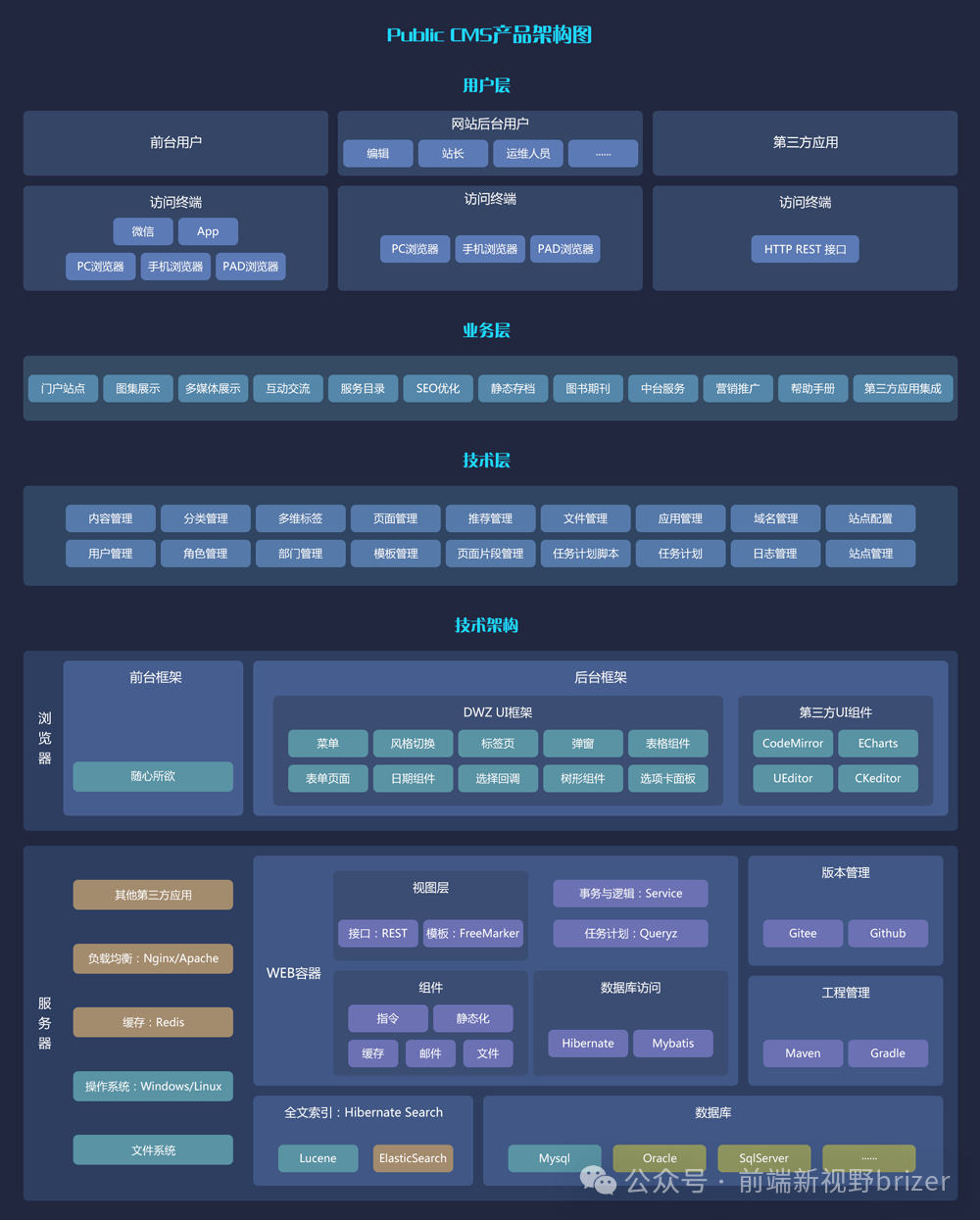
本次学习支持向量机部分数据如下所示
| ID | mass | width | height | color_score | fruit_name | kind |
其中ID:1-59是对应训练集和验证集的数据,60-67是对应测试集的数据,其中水果类别一共有四类包括apple、lemon、orange、mandarin。要求根据1-59的数据集的自变量(mass、width、height、color_score)和因变量(kind),去预测60-67的数据水果种类

一、导入支持向量机和其他的库
import numpy as np
from scipy import stats
from sklearn.model_selection import train_test_split
import pandas as pd
from sklearn import svm
from sklearn.metrics import accuracy_score二、读取数据
# 设置文件路径
file_path = 'E:\\Jupyter Workspace\\数学建模\\多分类水果数据.csv'
# 使用 pandas 的 read_csv 函数读取 CSV 文件,注意查看csv文件的编码,默认不填为utf-8编码
data = pd.read_csv(file_path,encoding='gbk')
# 显示数据的前几行来验证读取是否成功
print(data.head())
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
pd.set_option('display.width', 300) # 设置打印宽度(**重要**)
print(data.isnull().any())三、划分数据
# 选择第二列到最后一列,第一列相当于序号列可以忽略
X = data.iloc[0:59, 1:5] # [:)左闭右开
Y = data.iloc[0:59, 6]
# 划分数据集为训练集和验证集
X_train, X_valid, Y_train, Y_valid = train_test_split(X, Y, test_size=0.2, random_state=42)四、RBF核函数
# RBF 核函数
rbf_model = svm.SVC(kernel='rbf', gamma='auto')
rbf_model.fit(X_train, Y_train)
rbf_pred = rbf_model.predict(X_valid)
print("RBF Kernel Accuracy:", accuracy_score(Y_valid, rbf_pred))五、线性核函数
# 线性核函数
linear_model = svm.SVC(kernel='linear')
linear_model.fit(X_train, Y_train)
linear_pred = linear_model.predict(X_valid)
print("Linear Kernel Accuracy:", accuracy_score(Y_valid, linear_pred))六、多项式核函数
# 多项式核函数
poly_model = svm.SVC(kernel='poly', degree=3)
poly_model.fit(X_train, Y_train)
poly_pred = poly_model.predict(X_valid)
print("Polynomial Kernel Accuracy:", accuracy_score(Y_valid, poly_pred))七、Sigmoid核函数
# Sigmoid 核函数
sigmoid_model = svm.SVC(kernel='sigmoid')
sigmoid_model.fit(X_train, Y_train)
sigmoid_pred = sigmoid_model.predict(X_valid)
print("Sigmoid Kernel Accuracy:", accuracy_score(Y_valid, sigmoid_pred))其他
结合相关资料比较一下哪种核函数更适合该题数据,说明理由,同时给出测试集的对应预测结果
test_X = data.iloc[59:, 1:5]
# print(test_X)
test_Y = data.iloc[59:, 6]
# print(test_Y)
#举例:若为xxx核函数
#预测数据
xxx_pred_test = xxx_model.predict(test_X)
print(xxx_pred_test)拓展:尝试用以下指标衡量支持向量机(SVR)的预测效果
● MSE(均方误差): 预测值与实际值之差平方的期望值。取值越小,模型准确度越高。
● RMSE(均方根误差):为 MSE 的平方根,取值越小,模型准确度越高。
● MAE(平均绝对误差): 绝对误差的平均值,能反映预测值误差的实际情况。取值越小,模型准确度越高。
● MAPE(平均绝对百分比误差): 是 MAE 的变形,它是一个百分比值。取值越小,模型准确度越高。
● R²: 将预测值跟只使用均值的情况下相比,结果越靠近 1 模型准确度越高。