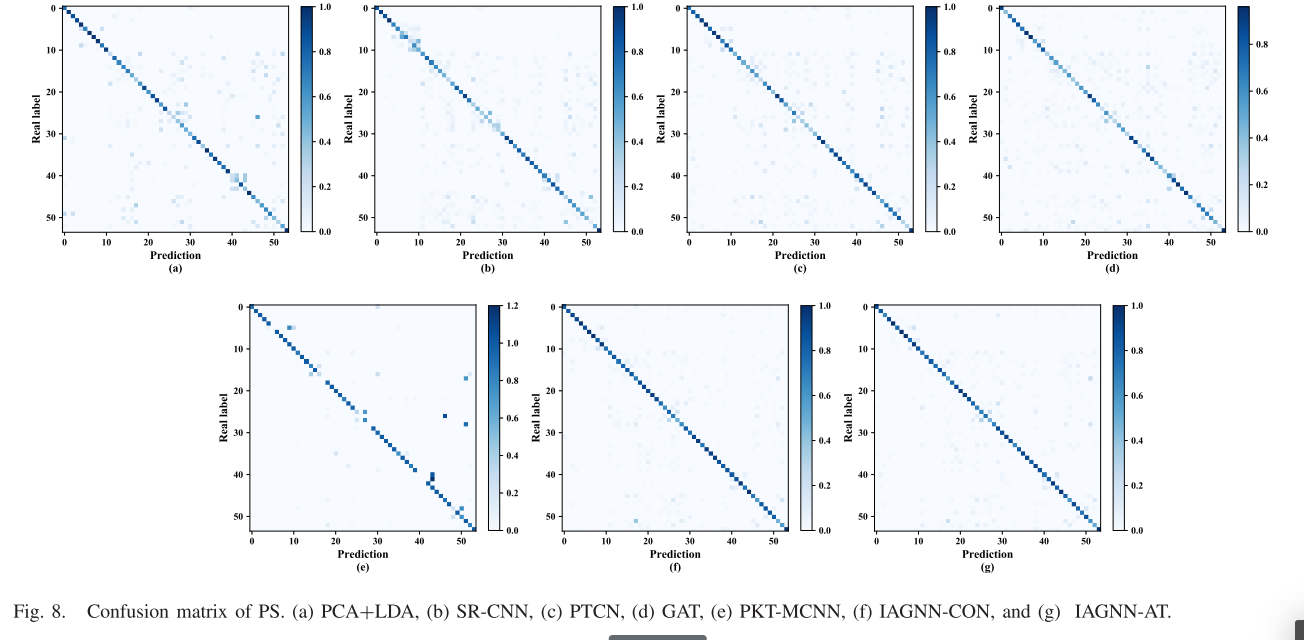
正则表达式
在Python中,正则表达式(Regular Expression,简称Regex)是一种强大的文本处理工具,它允许你使用一种特殊的语法来匹配、查找、替换字符串中的文本。
在这之前,还记得之前我们是通过什么方法分割字符串的嘛?
strs = "a,b;c@d"
print(strs.split(",")) #以“,”为分割点分割
------------------
['a', 'b;c@d']
字符串中的方法:split()方法:以括号内给入的东西为分割点分割,返回一个列表。
这是我们之前的方法,对于上述的字符串,如果要是想将a、b、c都分割出来还需要以";“、”@"为分隔带你再次分割,数据量大了之后就会变得很麻烦。于是,给我们带来新方法啦!
元字符
因为正则表达式也是用字符串表示的,所以首先了解如何用字符来描述字符如果直接给出字符,就是精确匹配,但有一些字符加上转义符后就具有特殊含义:
\d可以匹配一个数字
例如:'00\d'可以匹配'007',但无法匹配'00A'
'\d\d\d'可以匹配'010'
-------------------------
\w可以匹配一个字母或数字
例如:'\w\w\d'可以匹配'py3'
-------------------------
'.'可以匹配任意字符
例如:'py.'可以匹配'pyc'、'pyo'、'py!'等等
-------------------------------------------
\s可以匹配任何空白字符,包括空格、制表符、换页符等等
常见的元字符有:

正则进阶
要匹配变长的字符,在正则表达式中,用*表示任意个字符(包括0个),用+表示至少一个字符,用?表示0个或1个字符,用{n}表示n个字符,用{n,m}表示n~m个字符。来看一个复杂的例子:\d{3}\s+\d{3,8}
\d{3}表示匹配3个数字,例如'010'
\s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配 '空格','空格空格','空格空格空格'等;
\d{3,8}表示3-8个数字,例如'1234567','123','12345'
综上,该正则表达式可以匹配以任意个空格隔开的带三位区号的电话号码
要做更精确地匹配,则还需编写更复杂的正则表达式:
[0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线
[0-9a-zA-Z\_]+可以匹配至少由一个数字、字母或者下划线组成的字符串
比如'a100','0_Z','Py3000'等等
[a-zA-Z\_][0-9a-zA-Z\_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的命名规则
[a-zA-Z\_][0-9a-zA-Z\_]{0, 19}更精确地限制了长度是1-20个字符(前面1个字符,后面最多19个字符)
A|B可以匹配A或B,所以(P|p)ython可以匹配'Python'或者'python'
^表示行的开头,^\d表示必须以数字开头
$表示行的结束,\d$表示必须以数字结束
了解了这些新东西之后,我们来看看怎么使用到他们吧!
导入re模块
re模块使Python语言拥有全部的正则表达式功能!
# 正则表达式
import re
导入模块之后我们来看看怎么使用它:
正则方法
split()方法
开头说的字符串自带split方法可以指定分隔符进行字符串的切分,同样re模块也提供了split方法,可以按照指定的正则表达式进行字符串的切分:
import re
if __name__ == '__main__':
strs = "a,b;c@d"
print(re.split(r'[,;@]',strs))
----------------------
输出结果:
['a', 'b', 'c', 'd']
match()方法
re模块提供了一个match方法,可以判断正则表达式是否匹配,如果匹配成功,返回一个Match对象,否则返回None,比如:
phone = "1555-123456789"
print(re.match(r'\d{4}-\d{7}', phone)) #\d{7}中范围只到7,故此输出只能到第七个数
----------------
输出结果:
<re.Match object; span=(0, 12), match='1555-1234567'>
#匹配一个变量名称
print(re.match(r"[A-Za-z_]\w*", "AKBDkfnh983u"))
print(re.match(r"[p|P]ython","python"))
-------------------
输出结果:
<re.Match object; span=(0, 12), match='AKBDkfnh983u'>
<re.Match object; span=(0, 6), match='python'>
print("ABC\\001")
print(re.match(r"\w+\\\d+","ABC\\001")) #使用r标记字符串,那么就不再需要考虑转义的问题了
--------------
输出结果:
<re.Match object; span=(0, 7), match='ABC\\001'>
groups()分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(Group),比如:
匹配出时间:
t = "19:59:59"
# 匹配出时间
# 分组使用的是在正则内部使用 括号 第几个括号就是第几个组别
print(re.match(r"([0-1]\d|2[0-3]):([0-5]\d):([0-5]\d)", t).groups()) #小时、分钟、秒都用()分开了
[0-1]\d表示小时中的第一个数为0~1,第二个数\d即0~9都可以
print(re.match(r"([0-1]\d|2[0-3]):([0-5]\d):([0-5]\d)", t).group(1)) #group()括号内的参数表示组别
print(re.match(r"([0-1]\d|2[0-3]):([0-5]\d):([0-5]\d)", t).group(2))
print(re.match(r"([0-1]\d|2[0-3]):([0-5]\d):([0-5]\d)", t).group(3))
-----------------
输出结果:
('19', '59', '59')
19
59
59
贪婪匹配
正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。
例如,匹配出数字后面的0:
# 贪婪匹配
# 怎么结束贪婪匹配 ? 结束贪婪匹配
# ^表示以什么开头 $ 表示以什么结尾
num = "10233333000000"
print(re.match(r"^(\d+?)(0+)$", num).groups()) #^(\d+?)以数字开头;(0+)$以0结尾
-----------------
输出结果:
('10233333', '000000')
预编译
如果大家规则都类似,那可以提前将规则定义好,比如:
num1 = "102333000000"
num2 = "1023333000000"
num3 = "103333000000"
num4 = "133333000000"
怎么将它提前编译好呢?
使用compile方法预编译:
re_comp = re.compile(r"^(\d+?)(0+)$")
调用:
re_comp = re.compile(r"^(\d+?)(0+)$")
print(re_comp.match(num1))
print(re_comp.match(num2))
print(re_comp.match(num3))
print(re_comp.match(num4))
-------------------------------
输出结果:
<re.Match object; span=(0, 12), match='102333000000'>
<re.Match object; span=(0, 13), match='1023333000000'>
<re.Match object; span=(0, 12), match='103333000000'>
<re.Match object; span=(0, 12), match='133333000000'>
总结
本篇介绍了:
- 元字符:用字符来描述字符。
- 正则进阶:
- 用*表示任意个字符(包括0个),用+表示至少一个字符。
- 用?表示0个或1个字符,用{n}表示n个字符。
- 用{n,m}表示n~m个字符。
- 正则方法:
- split()方法:指定分隔符进行字符串的切分。
- match方法:可以判断正则表达式是否匹配,如果匹配成功,返回一个Match对象,否则返回None。
- groups()分组:提取子串的强大功能。用()表示的就是要提取的分组(Group)。
- 贪婪匹配:正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。
- “?” 结束贪婪匹配。
- "^"表示以什么开头 , “$” 表示以什么结尾。
- 预编译:如果大家规则都类似,可以使用compile方法提前将规则定义好。