目录
前言
准备
拉取服务和重平衡服务启动
初识PullRequest
重平衡服务
对重平衡资源进行排序
MessageQueue消息队列集合来源
Consumer消费者集合数据来源
确实分配资源策略
执行分配策略
初始化ProcessQueue
初始化PullRequest
内存队列填充PullRequest
消息拉取服务
调用消息核心处理方法
调用远程Broker服务拉取消息
提交消费消息请求
初始化ConsumeRequest
消息监听器消费消息
总结
前言
上一篇我们对Consumer的启动流程就进行了解析,有了消费者那么消费的Message从何而来呢,这就是本篇学习的重点。本篇会讲到MessageQueue的分配、Message的拉取以及消费等,让我们一起来学习吧!
准备
源码地址:https://github.com/apache/rocketmq
目前最新版本为:5.2.0
那么我们在idea上切换分支为 release-5.2.0
拉取服务和重平衡服务启动
//源码位置
//包名:org.apache.rocketmq.client.impl.factory
//文件名:MQClientInstance
//行数:315
// Start pull service
this.pullMessageService.start();
// Start rebalance service
this.rebalanceService.start();- 拉取服务和重平衡服务的启动其实就是在上一篇《从零开始读RocketMq源码(四)Consumer启动流程解析》中就已经执行了
- 这里就是触发Consumer从Broker获取Message的源头,进入启动源码会发现其实也就是分别开启了两个独立的线程来运行的。消息的获取也是需要这两个线程相互合作才能完成。
为什么我们消息选择的是Push推模式,但是这里服务启动的却是PullMessageService呢?
因为实际上,推模式下的实现还是基于消费者主动拉取的方式,推模式是通过一个长轮询的机制来实现的 , 消费者向 Broker 注册一个消息监听器,消费者内部维护一个线程,不断向 Broker 拉取消息,如果没有消息,则保持连接并等待消息到来。(下面会详细讲到)
初识PullRequest
我们按照启动顺序先对pullMessageService源码进行了解,进入线程的run()方法中
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:PullMessageService
//行数:131
MessageRequest messageRequest = this.messageRequestQueue.take();
if (messageRequest.getMessageRequestMode() == MessageRequestMode.POP) {
this.popMessage((PopRequest) messageRequest);
} else {
this.pullMessage((PullRequest) messageRequest);
}- 这里调用了内存队列的take()方法,这个方法看着是否眼熟,因为我们在《Broker存储Message流程解析》中也使用过
- take()方法的作用就是取出元素并从队列中删除,如果队列为空则会阻塞, 直到队列中有可用的消息请求为止。由此可见pullMessageService相当于内存队列中的消费者角色
- 但是这次的内存队列使用的是LinkedBlockingQueue类型,Broker存储Message中却使用的是PriorityBlockingQueue类型
- 内存队列获取出来的元素最终被转化为 PullRequest ,该对象在 RocketMQ 中用于封装消费者向 Broker 拉取消息时所需的所有信息。顾名思义这个对象就是向Broker发起拉取Message的请求对象。
扩展:LinkedBlockingQueue与PriorityBlockingQueue内存队列有什么区别吗?
LinkedBlockingQueue是一个 基于链表实现的阻塞队列,按 FIFO(先进先出)顺序存储元素。插入元素时,会添加到队列的尾部,移除元素时,会从队列的头部取出 。 如果队列满了,插入操作会阻塞;如果队列空了,移除操作会阻塞。
PriorityBlockingQueue 基于优先级堆实现的阻塞队列,元素按优先级顺序排列。默认情况下,使用元素的自然顺序(即元素需要实现
Comparable接口) , 插入元素时,会根据优先级排序,移除元素时,总是移除优先级最高的元素 ,由于是无界队列,所以插入操作不会阻塞;如果队列空了,移除操作会阻塞。
因为项目刚初始化,所以messageRequestQueue队列中一定是空的,那么调用task()方法后,pullMessageService线程一直会是阻塞状态不能向下执行,那么什么地方会新增内存队列元素呢,那就只有先把另一个主角rebalanceService服务请出场了。
重平衡服务
rebalanceService的核心作用就是 负责定期执行消费者的负载均衡操作 , 当消费者实例数量或者消息队列数量发送变更,确保消息队列均匀分布在多个消费者实例上,然后将 PullRequest 塞到messageRequestQueue内存队列中。
Producer生产者也使用到了该服务,作用则是将Message负载均衡到不同的MessageQueue中
进入run()方法
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:RebalanceService
//行数:51
boolean balanced = this.mqClientFactory.doRebalance();
realWaitInterval = balanced ? waitInterval : minInterval;- 结合源码上下文会发现这是包裹在一个while()循环中,相当于一个定时任务
- 当调用doRebalance()方法重平衡成功后,设置waitInterval= 20s后再次执行
- 如果调用doRebalance()方法重平衡执行失败,设置minInterval= 1s后再次重试
- 只要当前线程启动成功就会按照上面的逻辑周而复始
对重平衡资源进行排序
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:RebalanceImpl
//行数:342
Collections.sort(mqAll);
Collections.sort(cidAll);- mqAll为当前Topic中所有消息队列集合,然后进行排序
- cidAll为所有订阅了当前Topic的消费者实例id集合,然后进行排序
看到这里一头雾水,为什么要进行排序呢?
- 因为重平衡操作都是单独在每一个客户端进行的,而不是统一在Broker服务上进行分配的,那么为了保证消费者实例与消息队列能够合理的负载均衡,并且让每个消费者拿到互不相同的MessageQueue,那么就需要进行排序。
- 又因为订阅相同的topic,那么他们获取的总的消息队列和消费者实例都是完全相同的,然后每个客户端进行相同的排序,那么排序结果都是一样的,后续会使用到这些排序后的结果来对每个客户端进行分配MessageQueue,因为每个客户端id都不一样,从而经过后面的分配算法保证买个消费者分配的MessageQueue都不一样。后续分配算法会具体讲到。
MessageQueue消息队列集合来源
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:RebalanceImpl
//行数:325
Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);
//...
List<MessageQueue> mqAll = new ArrayList<>();
mqAll.addAll(mqSet);mqAll集合最终是从Map集合中通过Topic获取:ConcurrentMap<String/* topic */, Set<MessageQueue>> topicSubscribeInfoTable;
秉承着所以数据都有迹可循的原则,不禁要问topicSubscribeInfoTable中的数据从哪里来的呢?
其实就在上一篇讲到的Consumer启动流程中的填入的数据,就在下面方法中
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:DefaultMQPushConsumerImpl
//行数:1001
this.updateTopicSubscribeInfoWhenSubscriptionChanged();查看上方方法中的逻辑,会发现数据源又来自topic的订阅信息map:ConcurrentMap<String /* topic */, SubscriptionData> subscriptionInner;通过subscriptionInner的循环处理来分别填充topic对应的MessageQueue集合的
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:DefaultMQPushConsumerImpl
//行数:1235
Map<String, SubscriptionData> subTable = this.getSubscriptionInner();那么subscriptionInner中的数据又是什么时候填充的呢?
其实也是在最开始的Consumer启动的main方法设置订阅topic时中填充的。
//源码位置
//包名:org.apache.rocketmq.example.simple
//文件名:PushConsumer
//行数:39
consumer.subscribe(TOPIC, "*");深入subscribe()方法,你就会发现填充数据的源码
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:DefaultMQPushConsumerImpl
//行数:1250
SubscriptionData subscriptionData = FilterAPI.buildSubscriptionData(topic, subExpression);
this.rebalanceImpl.getSubscriptionInner().put(topic, subscriptionData);这样我们就理清楚了整个MessageQueue集合的来源和去向,有头也有尾,也不会再一知半解了
Consumer消费者集合数据来源
//源码位置
//包名:org.apache.rocketmq.client.impl
//文件名:MQClientAPIImpl
//行数:1349
RemotingCommand response = this.remotingClient.invokeSync(MixAll.brokerVIPChannel(this.clientConfig.isVipChannelEnabled(), addr),
request, timeoutMillis);由源码可知,消费者客户端集合cidAll是直接调用Broker服务来获取的
确实分配资源策略
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:RebalanceImpl
//行数:345
AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;
List<MessageQueue> allocateResult = null;
try {
allocateResult = strategy.allocate(
this.consumerGroup,
this.mQClientFactory.getClientId(),
mqAll,
cidAll);
} catch (Throwable e) {
log.error("allocate message queue exception. strategy name: {}, ex: {}", strategy.getName(), e);
return false;
}- 调用 strategy.allocate()方法对当前消费者实例分配消息队列,并返回一个集合allocateResult
进入分配方法中,会发现官方实现了多种分配策略
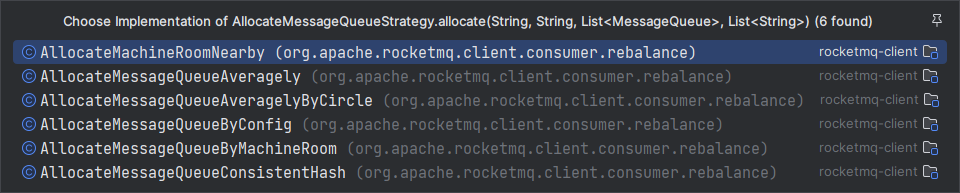
那么我们使用的是哪一种呢?其实在我们启动消费者服务实例化消费者对象时就已经设置了默认策略了
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:DefaultMQPushConsumer
//行数:308
public DefaultMQPushConsumer(final String consumerGroup) {
this(consumerGroup, null, new AllocateMessageQueueAveragely());
}new AllocateMessageQueueAveragely() 就是为我们默认指定的分配策略,即平均哈希队列算法
执行分配策略
//源码位置
//包名:org.apache.rocketmq.client.consumer.rebalance
//文件名:AllocateMessageQueueAveragely
//行数:32
List<MessageQueue> result = new ArrayList<>();
if (!check(consumerGroup, currentCID, mqAll, cidAll)) {
return result;
}
int index = cidAll.indexOf(currentCID);
int mod = mqAll.size() % cidAll.size();
int averageSize =
mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()
+ 1 : mqAll.size() / cidAll.size());
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
int range = Math.min(averageSize, mqAll.size() - startIndex);
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}这就是给当前消费者分配消息队列的算法逻辑
- index:表示当前消费者实例在所有排序后的消费者实例集合cidAll中的下标位置,每个currentCID都是唯一的。
- mod:表示mqAll集合中的MessageQueue能否被cidAll集合中的消费者实例均匀分配。
- averageSize:表示当前消费者平均能被分配到的MessageQueue数量。
- startIndex:表了当前这个 Consumer 从 MessageQueue 数组的哪个位置开始取。
- range: 代表当前这个 Consumer 获取到了多少个 MessageQueue
总结:最终分配逻辑可以理解为两步所有消费者客户端都会分配到相同数量的MessageQueue,对剩余无法平均分配的MessageQueue按照cidAll集合的顺序进行分配。但其实源码中是一次性算出分配结果的。
初始化ProcessQueue
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:RebalanceImpl
//行数:528
ProcessQueue pq = createProcessQueue(topic);
pq.setLocked(true);
long nextOffset = this.computePullFromWhere(mq);
if (nextOffset >= 0) {
ProcessQueue pre = this.processQueueTable.putIfAbsent(mq, pq);
//...
}- 第一步初始化创建ProcessQueue处理队列
- 最后将队列设置到processQueueTable的Map中,ConcurrentMap<MessageQueue, ProcessQueue> processQueueTable; 主要用于消费者负载均衡和消息消费管理,确保消息队列能够被正确地分配和处理
- 该Map在上一篇消费者启动中讲到过,数据用于处理定时任务清除过期的消息
- putIfAbsent()方法为如果存在相同的Key,就将原来的Value返回,不存在则返回null,同时put数据
初始化PullRequest
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:RebalanceImpl
//行数:532
if (pre != null) {
log.info("doRebalance, {}, mq already exists, {}", consumerGroup, mq);
} else {
log.info("doRebalance, {}, add a new mq, {}", consumerGroup, mq);
PullRequest pullRequest = new PullRequest();
pullRequest.setConsumerGroup(consumerGroup);
pullRequest.setNextOffset(nextOffset);
pullRequest.setMessageQueue(mq);
pullRequest.setProcessQueue(pq);
pullRequestList.add(pullRequest);
changed = true;
}- 到这里就正式封装PullRequest拉取请求对象了,紧接着上面初始化ProcessQueue代码可知,只有当该MessageQueue是一个全新并且之前不存在的消息队列时才会进行拉取请求。
- 初始化PullRequest从而和本篇前面讲到的pullMessageService有了关联
内存队列填充PullRequest
循环处理PullRequest对象
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:RebalancePushImpl
//行数:266
for (PullRequest pullRequest : pullRequestList) {
if (delay <= 0) {
this.defaultMQPushConsumerImpl.executePullRequestImmediately(pullRequest);
} else {
this.defaultMQPushConsumerImpl.executePullRequestLater(pullRequest, delay);
}
}循环逻辑处理中,对每次PullRequest对象的处理延迟5s,可以看到这里已经进入了PullMessageService服务中
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:PullMessageService
//行数:45
this.scheduledExecutorService.schedule(new Runnable() {
@Override
public void run() {
PullMessageService.this.executePullRequestImmediately(pullRequest);
}
}, timeDelay, TimeUnit.MILLISECONDS);最后就是将PullRequest对象put进内存队列LinkedBlockingQueue<MessageRequest> messageRequestQueue中,从而激活PullMessageService服务,结束阻塞状态开始执行拉取逻辑。
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:PullMessageService
//行数:58
this.messageRequestQueue.put(pullRequest);消息拉取服务
上面RebalanceService服务完成内存队列PullRequest入栈后,那么紧接着PullMessageService服务开始处理PullRequest。
调用消息核心处理方法
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:DefaultMQPushConsumerImpl
//行数:480
this.pullAPIWrapper.pullKernelImpl(
pullRequest.getMessageQueue(),
subExpression,
subscriptionData.getExpressionType(),
subscriptionData.getSubVersion(),
pullRequest.getNextOffset(),
this.defaultMQPushConsumer.getPullBatchSize(),
this.defaultMQPushConsumer.getPullBatchSizeInBytes(),
sysFlag,
commitOffsetValue,
BROKER_SUSPEND_MAX_TIME_MILLIS,
CONSUMER_TIMEOUT_MILLIS_WHEN_SUSPEND,
CommunicationMode.ASYNC,
pullCallback
);我们这里关注两个点:
- CommunicationMode.ASYNC:表示向Broker服务拉取消息是一个异步的操作
- pullCallback:异步回调后处理的逻辑就封装在该对象中
调用远程Broker服务拉取消息
//源码位置
//包名:org.apache.rocketmq.client.impl
//文件名:MQClientAPIImpl
//行数:1024
this.remotingClient.invokeAsync(addr, request, timeoutMillis, new InvokeCallback() {
//...
public void operationSucceed(RemotingCommand response) {
try {
PullResult pullResult = MQClientAPIImpl.this.processPullResponse(response, addr);
pullCallback.onSuccess(pullResult);
} catch (Exception e) {
pullCallback.onException(e);
}
}
//...
}由源码我们可知,pullCallback回调对象提供了
- pullCallback.onSuccess(pullResult):请求成功后处理逻辑方法
- pullCallback.onException(e):请求异常处理逻辑方法
提交消费消息请求
在调用this.pullAPIWrapper.pullKernelImpl核心方法之前,就已经重写了pullCallback的回调方法
并在onSuccess()实现中进行提交消费请求操作
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:DefaultMQPushConsumerImpl
//行数:370
DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(
pullResult.getMsgFoundList(),
processQueue,
pullRequest.getMessageQueue(),
dispatchToConsume);初始化ConsumeRequest
ConsumeRequest消费请求是PullRequest拉取请求之后的又一请求对象
顾名思义这也是消息最终被消费的请求了
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:ConsumeMessageConcurrentlyService
//行数:211
ConsumeRequest consumeRequest = new ConsumeRequest(msgThis, processQueue, messageQueue);
try {
this.consumeExecutor.submit(consumeRequest);
} catch (RejectedExecutionException e) {
for (; total < msgs.size(); total++) {
msgThis.add(msgs.get(total));
}
this.submitConsumeRequestLater(consumeRequest);
}- 将ConsumeRequest加入到线程池 ThreadPoolExecutor consumeExecutor;相当于就是为当前消费请求单独创建一个线程来异步处理
- 如果线程池加入异常,则会延迟5s后再次重试一次
消息监听器消费消息
直接进入ConsumeRequest线程的run()方法中
//源码位置
//包名:org.apache.rocketmq.client.impl.consumer
//文件名:ConsumeMessageConcurrentlyService
//行数:211
MessageListenerConcurrently listener = ConsumeMessageConcurrentlyService.this.messageListener;
ConsumeConcurrentlyContext context = new ConsumeConcurrentlyContext(messageQueue);
ConsumeConcurrentlyStatus status = null;
//...
status = listener.consumeMessage(Collections.unmodifiableList(msgs), context);- 这里就是消息消费的最后一步,将Message放入监听器MessageListenerConcurrently的consumeMessage()方法中。
Message最终在消费者启动中的main()方法的注册监听器的地方打印出来,最后返回消费成功状态ConsumeConcurrentlyStatus.CONSUME_SUCCESS
//源码位置
//包名:org.apache.rocketmq.example.simple
//文件名:PushConsumer
//行数:37
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
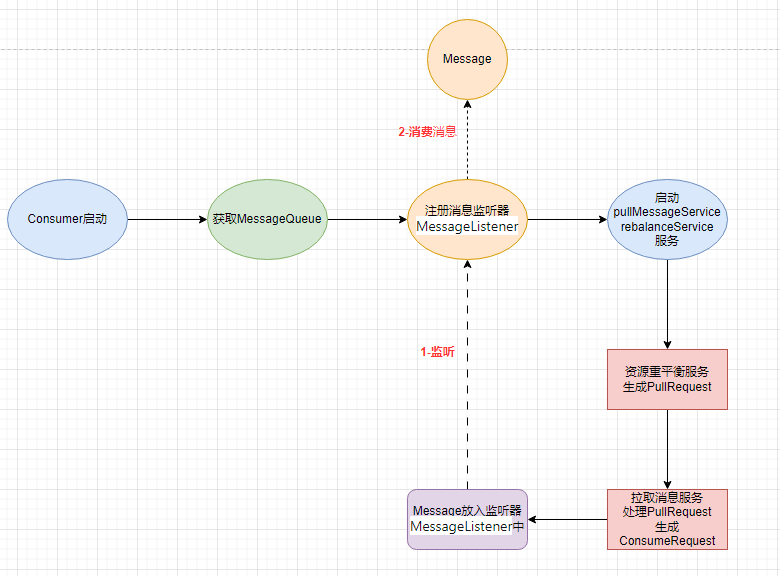
});Consumer端消费Message简易流程图如下
总结
根据上一篇消费者的启动到本篇消息的拉取与消费,完成了一个Message在消费者端的闭环。本篇我们也学到了一个新的内存队列LinkedBlockingQueue,也讲到了与PriorityBlockingQueue的区别,至此消费者端的源码基本学习完了,希望从源码中大家都有所收获!