文章目录
- 九、SwinTransformer
- 9.1 整体网络架构
- 9.2 Transformer Blocks
- 9.3 Patch Embedding(将图像切割成小块(Patch))
- 9.4 window_partition
- 9.5 W-MSA(Window Multi-head Self Attention)
- 9.6 window_reverse
- 9.7 SW-MSA(Shifted Window)
- 9.8 PatchMerging(下采样)
九、SwinTransformer
解决了哪些问题呢?
- 图像中像素点太多了,如果需要更多的特征就必须构建很长的序列
- 越长的序列算起注意力肯定越慢,这就导致了效率问题
- 能否用窗口和分层的形式来替代长序列的方法呢?这就是本质
- CNN中经常提到感受野,Transformer中该如何体现呢?(答案就是分层)
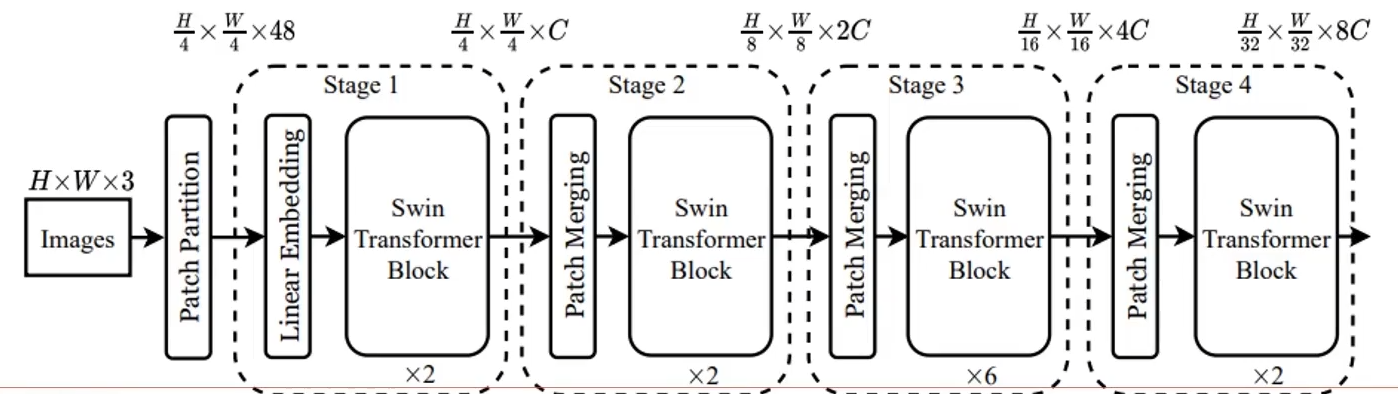
9.1 整体网络架构
- 得到个Pathch特征构建序列;
- 分层计算attention(逐步下采样过程)
- 其中Block是最核心的,对attention的计算方法进行了改进
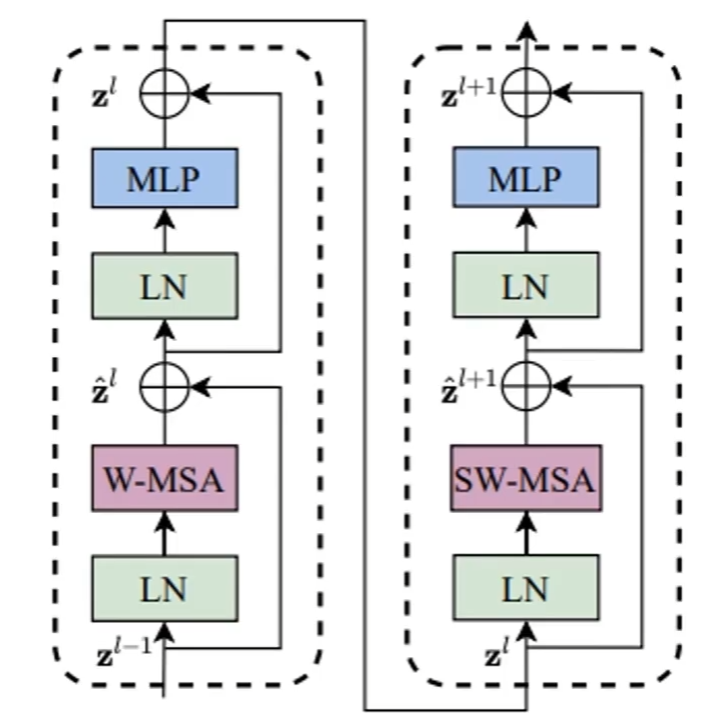
9.2 Transformer Blocks
- W-MSA:基于窗口的注意力机制
- SW-MSA:窗口滑动后重新计算注意力
- 上面两个串联在一起就是一个block
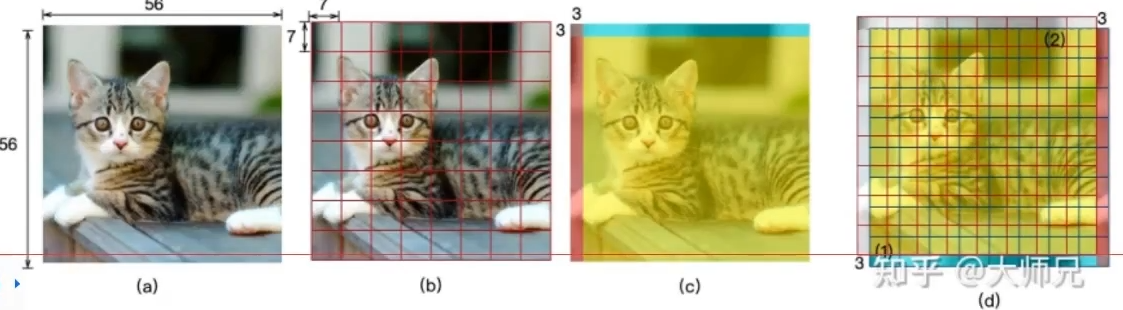
9.3 Patch Embedding(将图像切割成小块(Patch))
输入:图像数据(224,224,3)
输出:(3196,96)相当于序列长度是3136个,每个的向量是96维特征
3196也就是(224/4)*(224/4)得到的,也可以根据需求更改卷积参数
9.4 window_partition
输入:特征图(56,56,96)
默认窗口大小为7,所以总共可以分成8*8个窗口
输出:特征图(64,7,7,96)
之前的单位是序列,现在的单位是窗口(共64个窗口)
9.5 W-MSA(Window Multi-head Self Attention)
对得到的窗口,计算各个窗口自己的自注意力得分
qkv三个矩阵放在一起了:(3,64,3,49,32)
3个矩阵,64个窗口,heads为3,窗口大小7*7=49,每个head特征96/3=32
attention结果为:(64,3,49,49)每个头都会得出每个窗口内的自注意力
9.6 window_reverse
通过得到的attention计算得到新的特征(64,49,96)
总共64个窗口,每个窗口7*7的大小,每个点对应96维向量
window_reverse就是通过reshape操作还原回去(56,56,96)
这就得到了跟输入特征图一样的大小,但是其已经计算过了attention
9.7 SW-MSA(Shifted Window)
为什么要shift?原来的window都是算自己内部的
这样就会导致只有内部计算,没有它们之间的关系
容易让模型局限在自己的小领地,可以通过shift操作来改善
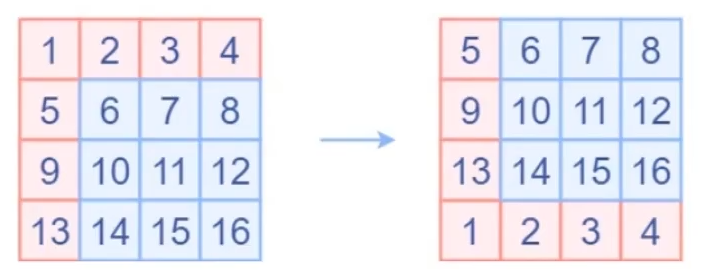
-
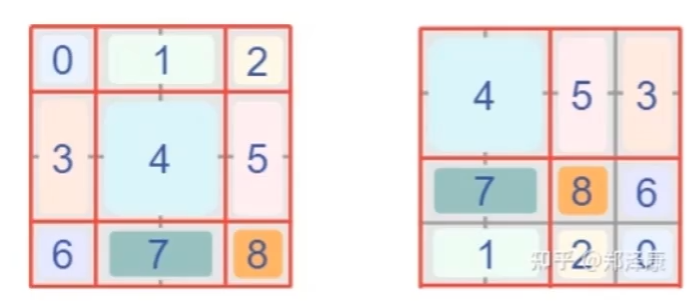
位移中的细节
- 位移就是像素点挪一下位置:
2. 窗口移动后,还有点小问题,例如原来4个,现在9个了,计算量怎么解决呢?
首先得到新窗口,并对其做位移操作
在计算时,只需要计算自己窗口的,其他的都是无关的
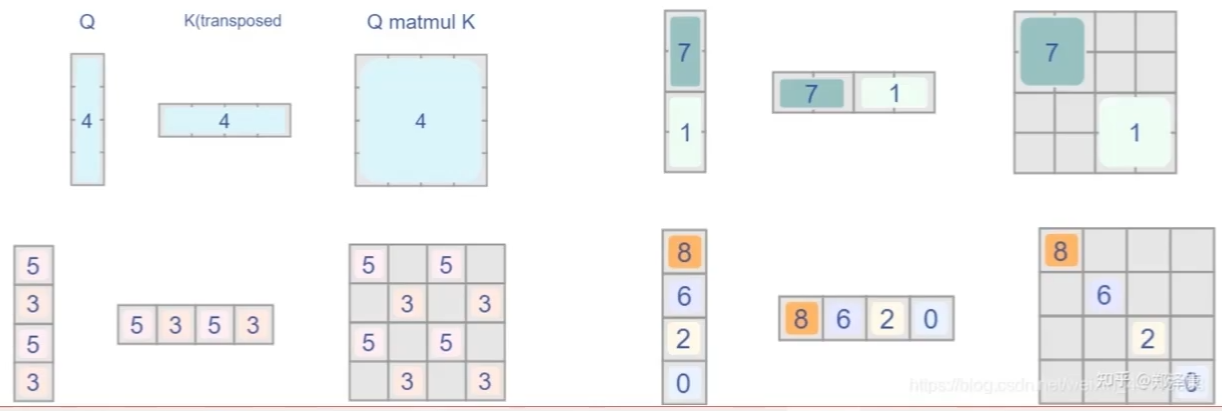
只需要设置好上面不需要的结果对应的位置的mask让其值为负无穷即可(softmax)
输出结果同样为(56,56,96)
不要忘记,计算完特征后需要对图像进行还原,也就是还原平移
这两组合就是SwinTransformer中的核心计算模块
9.8 PatchMerging(下采样)


分层计算:
一次下采样后(3176 -> 784也就是56*56 -> 28*28)
然后继续执行SwinTransformer Block
最后根据任务来选择合适的head层即可(分类,分割,检测等)



















