The Annotated Transformer注释加量版:复现Transformer,训练翻译模型
The Annotated GPT2注释加量版:GPT2预训练
The Annotated BERT注释加量版:BERT预训练
从零实现大模型-GPT2指令微调:GPT2指令微调
按照顺序,轮也该轮到BERT指令微调了吧!
是微调,但不是指令微调!
我们在之前的文章介绍过大模型的多种微调方法,指令微调只是其中一种,就像训犬一样,让它坐就坐,让它卧就卧,同理,你让LLM翻译,它不是去总结,你让它总结,它不是去情感分析。
大语言模型白皮书,让你彻底搞懂训练,微调和提示工程
指令微调在像GPT这种自回归的模型中应用多一些。我们在前一篇文章中基于GPT-2预训练模型进行了指令微调。
除了指令微调,还有一种比较常用的是任务微调,预训练模型虽然具备一定的知识,但尚不能直接用于某些具体任务。
例如,虽然在BERT的预训练过程中,通过Masked Language Model (MLM)和Next Sentence Prediction (NSP)使其学习了语言的基本特征。
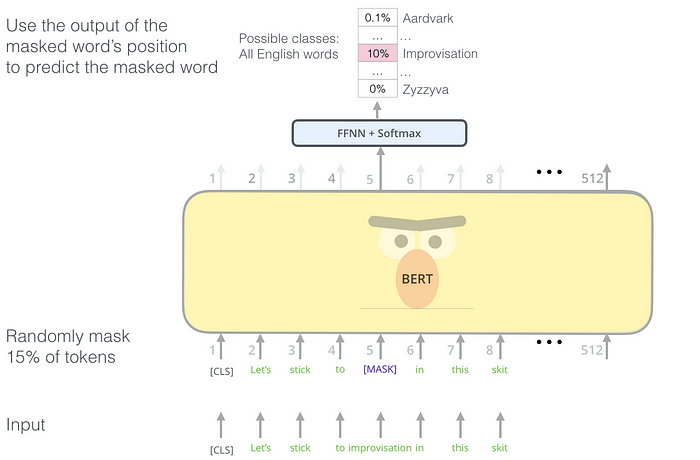
Masked Language Model (MLM)

Next Sentence Prediction (NSP)
但它仍不能直接用于自然语言推理(NLI)和问答(QA)等具体任务。因此,今天我们将对之前的BERT预训练模型进行进一步微调,使其能够更好地适应这些具体任务。
但完整代码如下,请结合代码阅读本文。
https://github.com/AIDajiangtang/LLM-from-scratch/blob/main/Bert_fine_tune_from_scratch.ipynb
在正式开始之前,有几点需要注意:
1.**在微调阶段,模型架构与预训练要一致,2.使用预训练模型的权重进行初始化而非随机初始化,3.使用预训练相同的分词方法和词表,4.**输入数据的格式与预训练阶段一致。例如,BERT模型通常要求输入序列包含[CLS]和[SEP]标记。
所以在下载预训练模型时,除了下载模型参数,通常还要下载配套的词表和模型超参数。
['bert_config.json',` `'bert_model.ckpt.data-00000-of-00001',` `'bert_model.ckpt.index',` `'vocab.txt']
如果要扩充词表来支持多语言,那模型结构中的嵌入层和输出层也需要更改,所以往往需要重新预训练。
有了前面四篇文章的烘托,本篇文章会忽略重复内容。
/ 01 /
微调任务1:自然语言推理
自然语言推理任务通常是判断两个句子之间的逻辑关系(如蕴涵、矛盾或中立)。

Next Sentence Prediction (NSP)可以看作是一种特殊的自然语言推理任务。
1.训练数据
本次微调用的数据来自GLUE MRPC,数据由成对的句子构成,并且还有一个人工标注的标签,表示两个句子是否语义相似。
`FeaturesDict({` `'idx': int32,` `'label': ClassLabel(shape=(), dtype=int64, num_classes=2),` `'sentence1': Text(shape=(), dtype=string),` `'sentence2': Text(shape=(), dtype=string),``})`
下面打印一条数据。
idx : 1680``label : 0``sentence1: b'The identical rovers will act as robotic geologists , searching for evidence of past water .'``sentence2: b'The rovers act as robotic geologists , moving on six wheels .'
-
对于每个样本中的句子对,拼接成一个输入序列,格式为:[CLS] 句子A [SEP] 句子B [SEP]。
-
使用BERT的分词器将输入序列分词,并将其转换为输入ID、注意力掩码和类型ID。
词表参数:``{'vocab_size': 30522,` `'start_of_sequence_id': 101,` `'end_of_segment_id': 102,` `'padding_id': 0,` `'mask_id': 103}
设置batch_size=32,max_seq_length = 128。
则输入ID:
模型的输入X。
'input_word_ids': <tf.Tensor: shape=(32, 128), dtype=int32, numpy=` `array([[ 101, 1996, 7235, ..., 0, 0, 0],` `[ 101, 2625, 2084, ..., 0, 0, 0],` `[ 101, 6804, 1011, ..., 0, 0, 0],` `...,` `[ 101, 2021, 2049, ..., 0, 0, 0],` `[ 101, 2274, 2062, ..., 0, 0, 0],` `[ 101, 2043, 1037, ..., 0, 0, 0]], dtype=int32)>
注意力掩码:
注意力掩码用于区分实际的 token 和填充的 token,1表示实际的 token,0表示填充的 token。
在多头注意力计算时,注意力掩码会将填充位置对应的注意力权重设置为负无穷(通常是一个非常大的负数,如 -10^9),这样在通过 softmax 计算时,这些位置的权重就会接近于零,从而使这些填充位置不会对注意力分数产生影响。
在计算损失时,通常会忽略填充位置对应的 token。
'input_mask': <tf.Tensor: shape=(32, 128), dtype=int32, numpy=` `array([[1, 1, 1, ..., 0, 0, 0],` `[1, 1, 1, ..., 0, 0, 0],` `[1, 1, 1, ..., 0, 0, 0],` `...,` `[1, 1, 1, ..., 0, 0, 0],` `[1, 1, 1, ..., 0, 0, 0],` `[1, 1, 1, ..., 0, 0, 0]], dtype=int32)>,
类型ID:
表示token属于哪个句子,0表示属于句子A,1表示数据句子B。
'input_type_ids': <tf.Tensor: shape=(32, 128), dtype=int32, numpy=` `array([[0, 0, 0, ..., 0, 0, 0],` `[0, 0, 0, ..., 0, 0, 0],` `[0, 0, 0, ..., 0, 0, 0],` `...,` `[0, 0, 0, ..., 0, 0, 0],` `[0, 0, 0, ..., 0, 0, 0],` `[0, 0, 0, ..., 0, 0, 0]], dtype=int32)>
在将token id转换成词嵌入向量时,会将类型id视为segment Embedding。
标签:
[‘not_equivalent’, ‘equivalent’]->[0,1]
0:表示两个句子语义不相似。
1:表示两个句子语义相似。
<tf.Tensor: shape=(32,), dtype=int64, numpy=``array([0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1,` `1, 1, 1, 1, 1, 0, 0, 1, 0, 1])>
到此,我们就构造了模型输入和标签。
input_word_ids shape: (32, 128)``input_mask shape: (32, 128)``input_type_ids shape: (32, 128)``labels shape: (32,)
2.模型
在模型架构上,相对于BERT预训练,在微调过程中,会在模型的输出层添加一个分类层。这个分类层的输入是[CLS]标记对应的隐藏状态,其输出是表示类别概率的logits。
因为EMB_SIZE = 768,所以分类层的输入(32, 768),输出(32, 768,2)。
3.微调
超参数``EMB_SIZE = 768//词嵌入维度``HIDDEN_SIZE = 768` `BATCH_SIZE = 32 #batch size``NUM_HEADS = 4 //头的个数
3.1.词嵌入
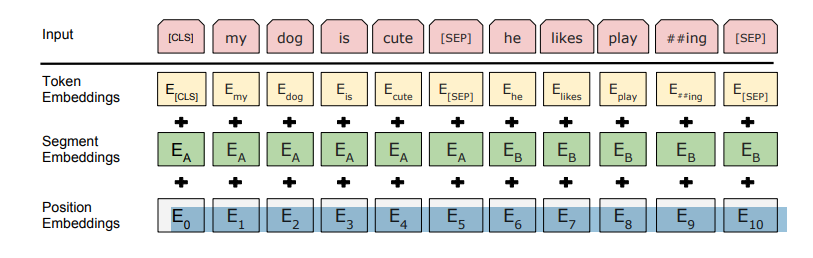
接下来将token ids转换成embedding,在Bert中,每个token都涉及到三种嵌入,第一种是Token embedding,token id转换成词嵌入向量,第二种是位置编码。还有一种是Segment embedding。用于表示哪个句子,0表示第一个句子,1表示第二个句子。
根据超参数EMB_SIZE = 768,所以词嵌入维度768,Token embedding通过一个嵌入层[30522,768]将输入[32,128]映射成[32,128,768]。
30522是词表的大小,[30522,768]的嵌入层可以看作是有30522个位置索引的查找表,每个位置存储768维向量。
位置编码可以通过学习的方式获得,也可以通过固定计算方式获得,本次采用固定计算方式。
Segment embedding和输入X大小一致,第一个句子对应为0,第二个位置为1。
最后将三个embedding相加,然后将输出的embedding[32,128,768]输入到编码器中。
****3.2.多头注意力
编码器的第一个操作是多头注意力,与Transformer和GPT中不同的是,不计算[PAD]的注意力,会将[PAD]对应位置的注意力分数设置为一个非常小的值,使之经过softmax后为0。
多头注意力的输出维度[32,128,768]。
****3.3.MLP
与Transformer和GPT中的一致,MLP的输出维度[32,128,768]。
****3.4.输出
编码器的输出[32,128,768],但我们只需要[CLS]对应的输出[32,768]。
二分类损失
通过另一个线性层[768,2]将开头的[CLS]的输出[32,768]映射成[32,2],表示属于正负类的概率,然后与标签[32,]计算交叉熵损失。
/ 02 /
微调任务2:问答
问答任务通常是给定一个段落和一个问题,模型需要从段落中找出答案的起始位置和结束位置。
示例
假设我们有一个段落和一个问题:
段落:“BERT is a model developed by Google for natural language processing tasks. It stands for Bidirectional Encoder Representations from Transformers.”
问题:“Who developed BERT?”
我们需要从段落中找出答案的起始位置和结束位置。在这个例子中,答案是 “Google”,它在段落中的位置如下:
-
起始位置:6 (第7个词,“Google”)
-
结束位置:6 (第7个词,“Google”)
超参数``max_seq_length = 128``EMB_SIZE = 768//词嵌入维度``HIDDEN_SIZE = 768` `BATCH_SIZE = 32 #batch size``NUM_HEADS = 4 //头的个数
1.训练数据
- 输入预处理:
将段落和问题转换为BERT的输入格式:[CLS] 问题 [SEP] 段落 [SEP]。
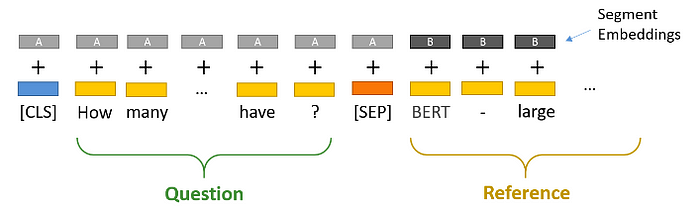
例如:[CLS] Who developed BERT? [SEP] BERT is a model developed by Google for natural language processing tasks. It stands for Bidirectional Encoder Representations from Transformers. [SEP]
- 分词和ID转换:
使用BERT的分词器将输入序列分词,并将其转换为输入ID、注意力掩码和类型ID。
input_word_ids shape: (32, 128)``input_mask shape: (32, 128)``input_type_ids shape: (32, 128)``labels shape: (32, 128, 2)#标记起始位置和结束位置
2.模型
-
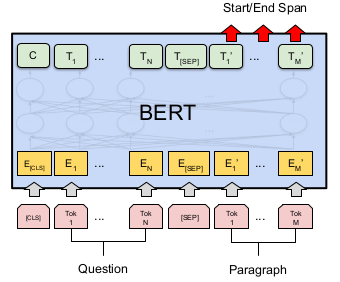
经过BERT模型的编码器处理后,每个标记都会有一个对应的隐藏状态向量。
-
假设输入序列长度为L,那么输出将是一个形状为 (L, H) 的矩阵,其中L是序列长度,H是隐藏状态的维度(通常为768)。
-
我们在BERT模型的输出层添加两个分类层(全连接层),分别用于预测答案的起始位置和结束位置。
-
这些分类层的输入是每个标记对应的隐藏状态向量,其输出是表示起始和结束位置的logits。
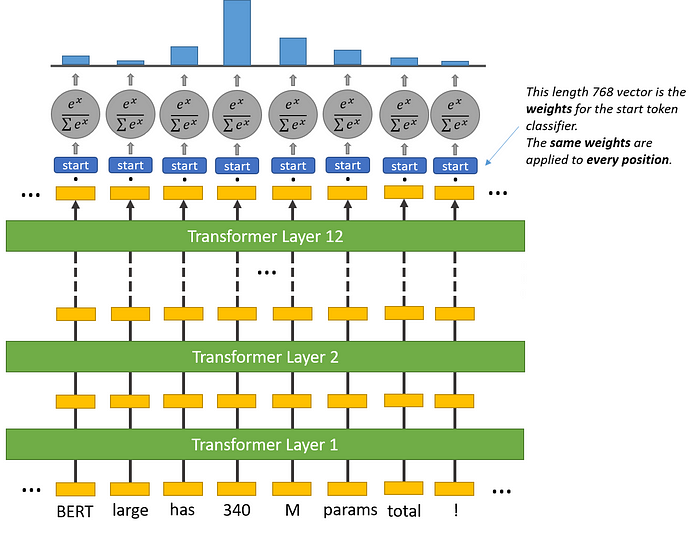
上图中的start就是用于预测答案起始位置的全连接层。
3.微调
3.1.词嵌入
接下来将token ids转换成embedding,在Bert中,每个token都涉及到三种嵌入,第一种是Token embedding,token id转换成词嵌入向量,第二种是位置编码。还有一种是Segment embedding。用于表示哪个句子,0表示第一个句子,1表示第二个句子。

根据超参数EMB_SIZE = 768,所以词嵌入维度768,Token embedding通过一个嵌入层[30522,768]将输入[32,128]映射成[32,128,768]。
30522是词表的大小,[30522,768]的嵌入层可以看作是有30522个位置索引的查找表,每个位置存储768维向量。
位置编码可以通过学习的方式获得,也可以通过固定计算方式获得,本次采用固定计算方式。
Segment embedding和输入X大小一致,第一个句子对应为0,第二个位置为1。
最后将三个embedding相加,然后将输出的embedding[32,128,768]输入到编码器中。
****3.2.多头注意力
编码器的第一个操作是多头注意力,与Transformer和GPT中不同的是,不计算[PAD]的注意力,会将[PAD]对应位置的注意力分数设置为一个非常小的值,使之经过softmax后为0。
多头注意力的输出维度[32,128,768]。
****3.3.MLP
与Transformer和GPT中的一致,MLP的输出维度[32,128,768]。
****3.4.输出
编码器的输出[32,128,768],但我们只需要属于段落对应的输出[32,N]。
二分类损失
通过预测起始位置的全连接层[768,2]将段落对应的输出[32,N,768]映射成[32,N,2],表示属于起始位置的概率,通过掩码根据原始标签(32, 128, 2)获取起始位置的标签[32,N],然后与起始位置的标签[32,N]计算交叉熵损失。
同样,通过预测结束位置的全连接层[768,2]将段落对应的输出[32,N,768]映射成[32,N,2],表示属于起始位置的概率,然后与结束位置的标签[32,N]计算交叉熵损失。