什么是Diffusion Model? 什么是Diffusion Model? ¶
如果将Diffusion与其他生成模型(如Normalizing Flows、GAN或VAE)进行比较,它并没有那么复杂,它们都将噪声从一些简单分布转换为数据样本,Diffusion也是从纯噪声开始通过一个神经网络学习逐步去噪,最终得到一个实际图像。 Diffusion对于图像的处理包括以下两个过程:
-
我们选择的固定(或预定义)正向扩散过程 𝑞𝑞 :它逐渐将高斯噪声添加到图像中,直到最终得到纯噪声
-
一个学习的反向去噪的扩散过程 𝑝𝜃𝑝𝜃 :通过训练神经网络从纯噪声开始逐渐对图像去噪,直到最终得到一个实际的图像
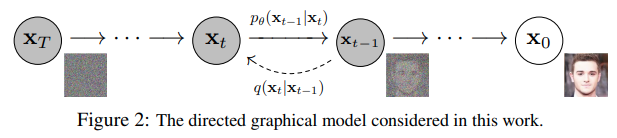
由 𝑡𝑡 索引的正向和反向过程都发生在某些有限时间步长 𝑇𝑇(DDPM作者使用 𝑇=1000𝑇=1000)内。从𝑡=0𝑡=0开始,在数据分布中采样真实图像 𝐱0𝑥0(本文使用一张来自ImageNet的猫图像形象的展示了diffusion正向添加噪声的过程),正向过程在每个时间步长 𝑡𝑡 都从高斯分布中采样一些噪声,再添加到上一个时刻的图像中。假定给定一个足够大的 𝑇𝑇 和一个在每个时间步长添加噪声的良好时间表,您最终会在 𝑡=𝑇𝑡=𝑇 通过渐进的过程得到所谓的各向同性的高斯分布。
Diffusion 前向过程
-
这个过程逐步将数据添加噪声,直到最终数据变成纯噪声。具体地,给定一个初始数据分布 q(x0)q(\mathbf{x}_0)q(x0),我们通过一系列马尔可夫链来生成一个噪声序列 x1,x2,…,xT\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_Tx1,x2,…,xT,使得每一步 xt+1\mathbf{x}_{t+1}xt+1 都是在 xt\mathbf{x}_txt 的基础上添加了一定的噪声。
-
这个过程的转移概率可以表示为:
q(xt+1∣xt)=N(xt+1;1−βtxt,βtI)q(\mathbf{x}_{t+1} | \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t+1}; \sqrt{1-\beta_t}\mathbf{x}_t, \beta_t\mathbf{I})q(xt+1∣xt)=N(xt+1;1−βtxt,βtI)其中, βt\beta_tβt 是一个逐渐增加的噪声系数。
具体过程如下:
-
初始化数据:
- 给定一组数据样本 x0\mathbf{x}_0x0(例如,图像)。
-
逐步添加噪声:
- 对于每一步 t=1,2,…,Tt = 1, 2, \ldots, Tt=1,2,…,T,按照以下方式添加噪声: q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(\mathbf{x}_t | \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1-\beta_t}\mathbf{x}_{t-1}, \beta_t\mathbf{I})q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
- 这里, βt\beta_tβt 是噪声的方差,通常设置为一组递增的值,如线性递增或余弦递增。
-
从初始数据到纯噪声:
- 经过多次添加噪声(例如,经过 T 步),最终数据 xT\mathbf{x}_TxT 将接近于纯噪声分布。
Diffusion 逆向过程
-
这个过程从纯噪声数据开始,逐步去噪声以生成新的数据样本。我们希望学习一个模型 pθ(xt−1∣xt)p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)pθ(xt−1∣xt) 来近似逆转正向过程,即从 xT\mathbf{x}_TxT 开始逐步去噪,得到 x0\mathbf{x}_0x0。
-
反向过程的转移概率为:
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \mu_\theta(\mathbf{x}_t, t), \Sigma_\theta(\mathbf{x}_t, t))pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))其中, μθ\mu_\thetaμθ 和 Σθ\Sigma_\thetaΣθ 是需要通过模型训练得到的参数。
-
初始化噪声:
- 从一个标准正态分布中采样初始噪声 xT\mathbf{x}_TxT(例如,图像中的每个像素都是从 N(0,1)\mathcal{N}(0, 1)N(0,1) 中采样的值)。
-
逐步去噪声:
- 对于每一步 t=T,T−1,…,1t = T, T-1, \ldots, 1t=T,T−1,…,1,根据以下公式去噪声: pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \mu_\theta(\mathbf{x}_t, t), \Sigma_\theta(\mathbf{x}_t, t))pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
- 其中, μθ(xt,t)\mu_\theta(\mathbf{x}_t, t)μθ(xt,t) 和 Σθ(xt,t)\Sigma_\theta(\mathbf{x}_t, t)Σθ(xt,t) 是模型参数,需通过训练来学习。
-
生成新数据:
- 最终得到 x0\mathbf{x}_0x0,即生成的新数据样本。
U-Net神经网络预测噪声
神经网络需要在特定时间步长接收带噪声的图像,并返回预测的噪声。请注意,预测噪声是与输入图像具有相同大小/分辨率的张量。因此,从技术上讲,网络接受并输出相同形状的张量。那么我们可以用什么类型的神经网络来实现呢?
这里通常使用的是非常相似的自动编码器,您可能还记得典型的"深度学习入门"教程。自动编码器在编码器和解码器之间有一个所谓的"bottleneck"层。编码器首先将图像编码为一个称为"bottleneck"的较小的隐藏表示,然后解码器将该隐藏表示解码回实际图像。这迫使网络只保留bottleneck层中最重要的信息。
在模型结构方面,DDPM的作者选择了U-Net,出自(Ronneberger et al.,2015)(当时,它在医学图像分割方面取得了最先进的结果)。这个网络就像任何自动编码器一样,在中间由一个bottleneck组成,确保网络只学习最重要的信息。重要的是,它在编码器和解码器之间引入了残差连接,极大地改善了梯度流(灵感来自于(He et al., 2015))。
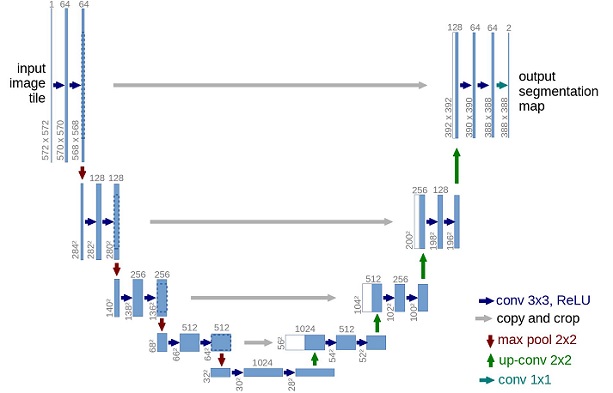
可以看出,U-Net模型首先对输入进行下采样(即,在空间分辨率方面使输入更小),之后执行上采样。
训练过程
训练扩散模型的目标是学习到反向扩散过程的参数,使其能够准确地将噪声转化为数据。具体步骤包括:
-
变分推断(Variational Inference):
- 通过变分推断最小化正向过程和反向过程之间的差异。定义损失函数为: L(θ)=Eq(x0:T)[∑t=1TDKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))]L(\theta) = \mathbb{E}_{q(\mathbf{x}_{0:T})} \left[ \sum_{t=1}^T D_{KL}(q(\mathbf{x}_{t-1}|\mathbf{x}_t, \mathbf{x}_0) || p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)) \right]L(θ)=Eq(x0:T)[t=1∑TDKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))]
其中, DKLD_{KL}DKL 表示 Kullback-Leibler 散度,用于衡量两个概率分布之间的差异。
- 通过变分推断最小化正向过程和反向过程之间的差异。定义损失函数为: L(θ)=Eq(x0:T)[∑t=1TDKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))]L(\theta) = \mathbb{E}_{q(\mathbf{x}_{0:T})} \left[ \sum_{t=1}^T D_{KL}(q(\mathbf{x}_{t-1}|\mathbf{x}_t, \mathbf{x}_0) || p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)) \right]L(θ)=Eq(x0:T)[t=1∑TDKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))]
-
参数优化:
- 使用梯度下降法更新模型参数 θ\thetaθ,使其能够更好地近似逆向过程。

- 使用梯度下降法更新模型参数 θ\thetaθ,使其能够更好地近似逆向过程。










![[C++]——同步异步日志系统(7)](https://i-blog.csdnimg.cn/direct/2089cf1cb08c477da3e3cb95915796c2.png)








