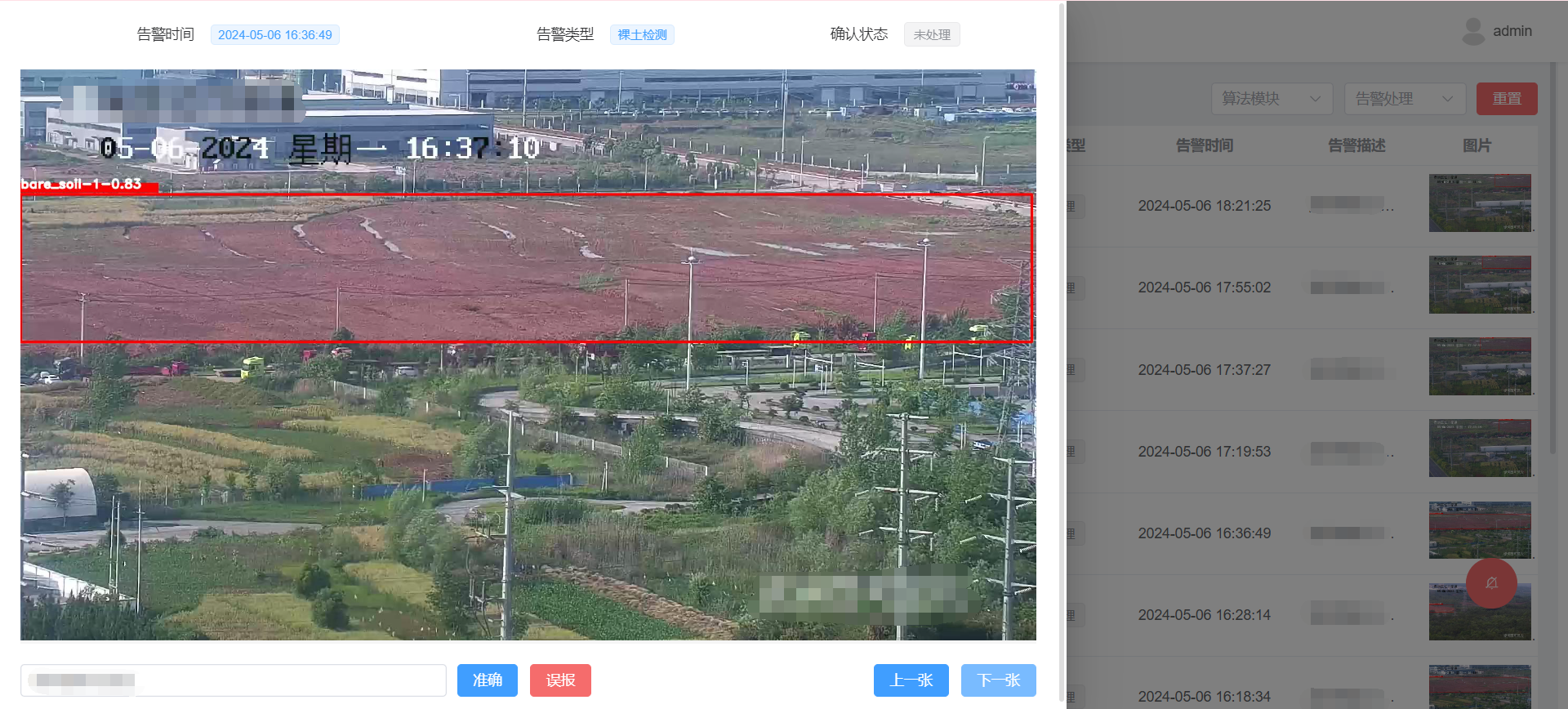
文章目录
- 一、语义特征空间
- 二、引入新维度:皇室
- 三、语义特征向量的用途
- 四、向量运算类比
- 五、词嵌入的维度和应用
- 词嵌入的应用
- 六、测量欧几里得距离
- 向量
- 计算向量和欧几里得距离
- 七、使用点积测量相似度
- 八、创建词嵌入
一、语义特征空间
考虑“男人”、“女人”、“男孩”和“女孩”这几个词。其中两个表示男性,两个表示女性。另外,两个表示成年人,两个表示儿童。我们可以将这些词绘制为图形上的点,其中 x x x轴表示性别, y y y轴表示年龄:

性别和年龄被称为语义特征:它们代表每个单词的部分含义。如果我们将每个特征与数值尺度相关联,那么我们可以为每个单词分配坐标:
单词
性别
年龄
男人
1
7
女人
9
7
男孩
1
2
女孩
9
2
\begin{array}{ccc} \text{单词} & \text{性别} & \text{年龄} \\ \hline \text{男人} & 1 & 7 \\ \text{女人} & 9 & 7 \\ \text{男孩} & 1 & 2 \\ \text{女孩} & 9 & 2 \\ \end{array}
单词男人女人男孩女孩性别1919年龄7722
我们可以根据新词的含义将其添加到情节中。例如,“成人”和“儿童”应该放在哪里?“婴儿”呢?或者“祖父”?

单词 性别 年龄 祖父 1 9 男人 1 7 成人 5 7 女人 9 7 男孩 1 2 儿童 5 2 女孩 9 2 婴儿 5 1 \begin{array}{ccc} \text{单词} & \text{性别} & \text{年龄} \\ \hline \text{祖父} & 1 & 9 \\ \text{男人} & 1 & 7 \\ \text{成人} & 5 & 7 \\ \text{女人} & 9 & 7 \\ \text{男孩} & 1 & 2 \\ \text{儿童} & 5 & 2 \\ \text{女孩} & 9 & 2 \\ \text{婴儿} & 5 & 1 \\ \end{array} 单词祖父男人成人女人男孩儿童女孩婴儿性别11591595年龄97772221
练习:如何表示“祖母”、“祖父母”、“青少年”和“八十多岁”这几个词?
答案:性别坐标很明显。我们可以根据已经定义的单词的值推断出年龄坐标:

单词 性别 年龄 祖母 9 9 祖父母 5 9 青少年 5 4 八十多岁 5 10 \begin{array}{ccc} \text{单词} & \text{性别} & \text{年龄} \\ \hline \text{祖母} & 9 & 9 \\ \text{祖父母} & 5 & 9 \\ \text{青少年} & 5 & 4 \\ \text{八十多岁} & 5 & 10 \\ \end{array} 单词祖母祖父母青少年八十多岁性别9555年龄99410
二、引入新维度:皇室
现在让我们考虑“国王”、“王后”、“王子”和“公主”这几个词。它们具有与“男人”、“女人”、“男孩”和“女孩”相同的性别和年龄属性,但它们的意思并不相同。为了区分“男人”和“国王”、“女人”和“王后”等,我们需要引入一个使它们不同的新语义特征。我们称之为“皇室”。现在我们必须在三维空间中绘制这些点:

单词 性别 年龄 皇室 男人 1 7 1 女人 9 7 1 男孩 1 2 1 女孩 9 2 1 国王 1 8 8 王后 9 7 8 王子 1 2 8 公主 9 2 8 \begin{array}{cccc} \text{单词} & \text{性别} & \text{年龄} & \text{皇室} \\ \hline \text{男人} & 1 & 7 & 1 \\ \text{女人} & 9 & 7 & 1 \\ \text{男孩} & 1 & 2 & 1 \\ \text{女孩} & 9 & 2 & 1 \\ \text{国王} & 1 & 8 & 8 \\ \text{王后} & 9 & 7 & 8 \\ \text{王子} & 1 & 2 & 8 \\ \text{公主} & 9 & 2 & 8 \\ \end{array} 单词男人女人男孩女孩国王王后王子公主性别19191919年龄77228722皇室11118888
每个单词都有三个坐标值:性别、年龄和皇室。我们将这些数字列表称为向量。由于它们表示语义特征的值,我们也可以将它们称为特征向量。
三、语义特征向量的用途
通过计算词嵌入向量之间的距离,可以判断单词之间的相似性。例如,“男孩”与“女孩”的相似度要高于“王后”,因为“男孩”到“女孩”的距离小于“男孩”到“王后”的距离。测量距离的方法有几种:
- 特征数量法:计算单词不同的特征数量。“男孩”和“女孩”仅在一个特征(性别)上不同,而“男孩”和“王后”在所有三个特征(性别、年龄和皇室)上都不同。这是一种粗略的测量相似性的方法。
- 欧几里得距离:由于每个单词都由坐标值表示,因此更好的方法是计算这些点之间的欧几里得距离,这可以使用勾股定理来完成。例如:
- “男孩”和“女孩”之间的距离为 8.0 8.0 8.0
- “男孩”和“王后”之间的距离为 11.75 11.75 11.75
语义距离:语义距离是衡量词语相关性的一种方法。通过计算词嵌入向量之间的语义距离,可以更准确地评估单词之间的关系。
解决词语类比问题:词嵌入还可以用于解决词语类比问题。通过向量运算,可以发现类似的关系。例如,通过计算“男孩”与“女孩”的关系,可以推测“国王”与“王后”的关系。
四、向量运算类比
类比表达了概念之间的关系。例如,“男人之于国王,相当于女人之于_____”。要得出答案,我们首先要找到男人和国王之间的关系。我们可以通过计算“国王” - “男人”来以数字方式做到这一点。我们分别减去每个坐标,得到
(
1
−
1
)
\mathbf{(1 - 1)}
(1−1) 、
(
8
−
7
)
\mathbf{(8 - 7)}
(8−7) 和
(
8
−
1
)
\mathbf{(8 - 1)}
(8−1) 或
[
0
,
1
,
7
]
\mathbf{[0, 1, 7]}
[0,1,7]。然后我们将其添加到“女人”,再次分别处理每个坐标,即
(
0
+
9
)
\mathbf{(0 + 9)}
(0+9)、
(
1
+
7
)
\mathbf{(1 + 7)}
(1+7)、
(
7
+
1
)
\mathbf{(7 + 1)}
(7+1) 或
[
9
,
8
,
8
]
\mathbf{[9, 8, 8]}
[9,8,8]。最后,我们找到最接近结果的单词,即“女王”,或
[
9
,
7
,
8
]
\mathbf{[9, 7, 8]}
[9,7,8]。
单词
性别
年龄
皇室
国王
1
8
8
男人
1
7
1
王者
0
1
7
女人
9
7
1
国王 - 男人 + 女人
9
8
8
女王
9
7
8
\begin{array}{cccc} \text{单词} & \text{性别} & \text{年龄} & \text{皇室} \\ \hline \text{国王} & 1 & 8 & 8 \\ \text{男人} & 1 & 7 & 1 \\ \text{王者} & 0 & 1 & 7 \\ \text{女人} & 9 & 7 & 1 \\ \text{国王 - 男人 + 女人} & 9 & 8 & 8 \\ \text{女王} & 9 & 7 & 8 \\ \end{array}
单词国王男人王者女人国王 - 男人 + 女人女王性别110999年龄871787皇室817188
我们还可以用图形表示词语类比。对于“男人”和“国王”的关系,我们从“男人”画一个箭头指向“国王”。接下来,我们复制这个箭头,保持相同的方向和长度,但现在从“女人”开始。然后我们看看箭头指向哪里,并寻找最接近的单词:

这种方法不仅直观地显示了单词之间的关系,还展示了如何使用向量运算来解答词语类比问题。通过这种方式,我们可以在向量空间中发现单词的语义关系,并且这种方法在自然语言处理中的应用非常广泛。
五、词嵌入的维度和应用
随着词嵌入向量的维度增加,我们能够表示更多的语义特征。虽然两个或三个语义特征可以表示一些单词,但它们往往不足以捕捉复杂的语义关系。例如,“黄瓜”、“微笑”或“诚实”等单词的表示需要更高维度的空间。
高维特征空间
要表示典型的 50,000 个单词的英语词汇的复杂性,通常需要数百个特征。手动设计所有这些特征并为每个单词分配准确的坐标是非常繁琐的工作。因此,我们使用词嵌入技术来自动创建这些特征空间。
自动生成特征空间
我们可以通过将大量文本(例如整个维基百科或大量新闻文章)提供给机器学习算法来让计算机自动创建特征空间。算法通过分析单词与其他单词的共现关系来发现单词之间的统计关系,并在自己设计的语义特征空间中为单词生成表示。这些表示称为词嵌入,典型的嵌入可能使用 300 维空间,每个单词由 300 个数字表示。
词嵌入的应用
- 类比推理:词嵌入可以支持各种类比推理,例如:
- 复数形式:例如,“hand”与“hands”的类比可以推导出“foot”与“feet”。
- 过去时态:例如,“sing”与“sang”的类比可以推导出“eat”与“ate”。
- 比较:例如,“big”与“small”的类比可以推导出“fast”与“slow”。
- 国家与首都:例如,“France”与“Paris”的类比可以推导出“England”与“London”。
- 神经网络输入:词嵌入是神经网络的关键输入,尤其是用于理解整个句子甚至段落含义的复杂神经网络。这种类型的网络称为 Transformer 神经网络。两个著名的 Transformer 网络是 Google 的 BERT 和 OpenAI 的 GPT-3。BERT 现在用于处理许多 Google 搜索任务。
通过这些高维的词嵌入,计算机能够更准确地理解和处理自然语言,从而提高各种语言处理任务的效果。
六、测量欧几里得距离
前面研究了测量两个单词之间距离的方法。计算它们之间不同的特征数量是一种过于粗略的测量方法,因为它无法区分小值差异和大值差异。我们考虑的替代方法是欧几里得距离。要解释计算该距离的公式,首先需要了解向量的知识。
向量
我们一直将单词绘制为语义空间中的点,我们也将这些点称为向量。在数学中,向量被绘制为箭头,它由长度和方向组成。单词可以绘制为从原点开始到点结束的箭头。因此,单词“child”可以绘制为从原点 [ 0 , 0 ] \mathbf{[0, 0]} [0,0] 到点 [ 5 , 2 ] \mathbf{[5, 2]} [5,2] 的箭头。以下是我们二维语义空间中绘制为向量的所有单词:

计算向量和欧几里得距离
我们可以通过绘制一个向量来比较两个单词,然后测量其长度。从“boy”到“infant”的向量可以通过从“infant” [ 5 , 1 ] \mathbf{[5,1]} [5,1] 开始并减去“boy” [ 1 , 2 ] \mathbf{[1,2]} [1,2] 来计算,得到向量 [ 4 , − 1 ] \mathbf{[4, -1]} [4,−1]。向量 [ x , y ] \mathbf{[x, y]} [x,y] 的长度由公式 x 2 + y 2 \sqrt{\mathbf{x}^2 + \mathbf{y}^2} x2+y2 给出,其中 \sqrt{} 是平方根函数。因此,从“boy”到“infant”的向量长度为 17 \sqrt{17} 17,或大约 4.12。这是两个单词之间的欧几里得距离。以下是从“boy”到所有其他单词的向量及其长度:

与“男孩”的距离 向量 长度 祖父 [ 0 , 7 ] 7 男人 [ 0 , 5 ] 5 成人 [ 4 , 5 ] 6.4031 女士 [ 8 , 5 ] 9.4340 男生 [ 0 , 0 ] 0 孩子 [ 4 , 0 ] 4 女孩 [ 8 , 0 ] 8 婴儿 [ 4 , − 1 ] 4.1231 \begin{array}{ccc} \text{与“男孩”的距离} & \text{向量} & \text{长度} \\ \text{祖父} & \mathbf{[0, 7]} & 7 \\ \text{男人} & \mathbf{[0, 5]} & 5 \\ \text{成人} & \mathbf{[4, 5]} & 6.4031 \\ \text{女士} & \mathbf{[8, 5]} & 9.4340 \\ \text{男生} & \mathbf{[0, 0]} & 0 \\ \text{孩子} & \mathbf{[4, 0]} & 4 \\ \text{女孩} & \mathbf{[8, 0]} & 8 \\ \text{婴儿} & \mathbf{[4, -1]} & 4.1231 \\ \end{array} 与“男孩”的距离祖父男人成人女士男生孩子女孩婴儿向量[0,7][0,5][4,5][8,5][0,0][4,0][8,0][4,−1]长度756.40319.43400484.1231
可以看到,与“boy”最接近的词是“child”,但是“infant”也只是稍微远一点。
相同的欧几里得距离公式也适用于高维空间。三维向量 [ x , y , z ] \mathbf{[x, y, z]} [x,y,z] 的长度为 x 2 + y 2 + z 2 \sqrt{\mathbf{x}^2 + \mathbf{y}^2 + \mathbf{z}^2} x2+y2+z2。
欧几里德距离是一种非常合理的距离测量方法,但它并不是词向量的首选距离测量方法。相反,使用点积进行计算,这是一种相似性测量方法,而不是距离测量方法。值越大表示单词越相似。
七、使用点积测量相似度
给定两个向量 [ x 1 , y 1 ] \mathbf{[x_1, y_1]} [x1,y1] 和 [ x 2 , y 2 ] \mathbf{[x_2, y_2]} [x2,y2],它们之间的欧几里得距离为 ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 \sqrt{(\mathbf{x_1 - x_2})^2 + (\mathbf{y_1 - y_2})^2} (x1−x2)2+(y1−y2)2。点积更简单,即 x 1 ⋅ x 2 + y 1 ⋅ y 2 \mathbf{x_1 \cdot x_2 + y_1 \cdot y_2} x1⋅x2+y1⋅y2。点积与两个向量之间角度的余弦成正比,公式: u ⋅ v = ∥ u ∥ ∥ v ∥ cos ( θ ) \mathbf{u} \cdot \mathbf{v} = \|\mathbf{u}\| \|\mathbf{v}\| \cos(\theta) u⋅v=∥u∥∥v∥cos(θ)。但为了使其成为一个合理的相似度度量,我们必须首先对向量进行轻微调整。考虑原始向量之间的角度:
原始词向量

单词
向量
祖父
[
1
,
9
]
男人
[
1
,
7
]
成人
[
5
,
7
]
女士
[
9
,
7
]
男生
[
1
,
2
]
孩子
[
5
,
2
]
女孩
[
9
,
2
]
婴儿
[
5
,
1
]
\begin{array}{ccc} \text{单词} & \text{向量} \\ \text{祖父} & \mathbf{[1, 9]} \\ \text{男人} & \mathbf{[1, 7]} \\ \text{成人} & \mathbf{[5, 7]} \\ \text{女士} & \mathbf{[9, 7]} \\ \text{男生} & \mathbf{[1, 2]} \\ \text{孩子} & \mathbf{[5, 2]} \\ \text{女孩} & \mathbf{[9, 2]} \\ \text{婴儿} & \mathbf{[5, 1]} \\ \end{array}
单词祖父男人成人女士男生孩子女孩婴儿向量[1,9][1,7][5,7][9,7][1,2][5,2][9,2][5,1]
在上图中,“男孩”(栗色向量)和“成人”(黄色向量)之间的角度较小,而“男孩”和“儿童”(蓝色向量)之间的角度较大。然而,“男孩”与“儿童”在语义上的相似度显然更高,因为“男孩”与“儿童”在性别坐标上的差异微小,而与“成人”在性别和年龄坐标上都有显著的差异。
所有的向量最初都是从原点出发的。为了使角度成为更有用的相似度度量,我们需要将这些向量的起点移动到所有点的中心。我们可以通过以下步骤实现这一点:
- 计算所有点的平均值。
- 从每个点中减去该平均值,使得这些点的中心位于原点。
通过这种方式,某些词的特征值将变为负数,其他词的特征值则变为正数,使得所有点的平均值为零。虽然这种调整不会改变欧几里得距离的测量结果(因为所有点都移动了相同的量),但它会显著影响点积的计算。
这种调整后,词向量的位置和角度将更准确地反映单词之间的相似度。
零均值二维向量

单词
向量
祖父
[
−
3.500
,
4.375
]
男人
[
−
3.500
,
2.375
]
成人
[
0.500
,
2.375
]
女士
[
4.500
,
2.375
]
男生
[
−
3.500
,
−
2.625
]
孩子
[
0.500
,
−
2.625
]
女孩
[
4.500
,
−
2.625
]
婴儿
[
0.500
,
−
3.625
]
\begin{array}{ccc} \text{单词} & \text{向量} \\ \text{祖父} & \mathbf{[-3.500, 4.375]} \\ \text{男人} & \mathbf{[-3.500, 2.375]} \\ \text{成人} & \mathbf{[0.500, 2.375]} \\ \text{女士} & \mathbf{[4.500, 2.375]} \\ \text{男生} & \mathbf{[-3.500, -2.625]} \\ \text{孩子} & \mathbf{[0.500, -2.625]} \\ \text{女孩} & \mathbf{[4.500, -2.625]} \\ \text{婴儿} & \mathbf{[0.500, -3.625]} \\ \end{array}
单词祖父男人成人女士男生孩子女孩婴儿向量[−3.500,4.375][−3.500,2.375][0.500,2.375][4.500,2.375][−3.500,−2.625][0.500,−2.625][4.500,−2.625][0.500,−3.625]
现在,“男孩”和“儿童”向量之间的角度比“男孩”和“成人”之间的角度小得多,这符合预期,因为“男孩”和“儿童”在性别坐标上只相差 4,而“男孩”和“成人”在性别坐标上相差 4,在年龄坐标上相差 5。但仍然存在一个问题。两个向量的点积并不完全是它们之间角度
θ
\mathbf{\theta}
θ 的余弦;它与余弦成比例。给定两个向量
u
\mathbf{u}
u 和
v
\mathbf{v}
v,
u
⋅
v
\mathbf{u \cdot v}
u⋅v 的确切值是:
cos
(
θ
)
⋅
∣
∣
u
∣
∣
⋅
∣
∣
v
∣
∣
\cos(\mathbf{\theta}) \cdot ||\mathbf{u}|| \cdot ||\mathbf{v}||
cos(θ)⋅∣∣u∣∣⋅∣∣v∣∣
其中
∣
∣
u
∣
∣
||\mathbf{u}||
∣∣u∣∣ 是向量
u
\mathbf{u}
u 的长度,即它与原点的欧几里得距离。如果我们希望点积恰好等于余弦,我们需要对向量进行归一化,使它们的长度为 1。我们通过将每个向量的坐标除以向量的长度来实现这一点,即,给定一个向量
u
=
[
x
,
y
]
\mathbf{u = [x, y]}
u=[x,y],其长度
∣
∣
u
∣
∣
=
x
2
+
y
2
||\mathbf{u}|| = \sqrt{\mathbf{x^2 + y^2}}
∣∣u∣∣=x2+y2,我们可以构造一个指向同一方向但长度为 1 的单位向量,即
u
/
∣
∣
u
∣
∣
\mathbf{u}/||\mathbf{u}||
u/∣∣u∣∣ 或
[
x
/
∣
∣
u
∣
∣
,
y
/
∣
∣
u
∣
∣
]
\mathbf{[x/||u||, y/||u||]}
[x/∣∣u∣∣,y/∣∣u∣∣]。
当我们将这些点转换为单位向量时,它们看起来如下,因此它们都位于半径为 1 的圆上:
零均值二维单位向量

单词
向量
祖父
[
−
0.6247
,
0.7809
]
男人
[
−
0.8275
,
0.5615
]
成人
[
0.2060
,
0.9785
]
女士
[
0.8844
,
0.4668
]
男生
[
−
0.8000
,
−
0.6000
]
孩子
[
0.1871
,
−
0.9823
]
女孩
[
0.8638
,
−
0.5039
]
婴儿
[
0.1366
,
−
0.9906
]
\begin{array}{ccc} \text{单词} & \text{向量} \\ \text{祖父} & \mathbf{[-0.6247, 0.7809]} \\ \text{男人} & \mathbf{[-0.8275, 0.5615]} \\ \text{成人} & \mathbf{[0.2060, 0.9785]} \\ \text{女士} & \mathbf{[0.8844, 0.4668]} \\ \text{男生} & \mathbf{[-0.8000, -0.6000]} \\ \text{孩子} & \mathbf{[0.1871, -0.9823]} \\ \text{女孩} & \mathbf{[0.8638, -0.5039]} \\ \text{婴儿} & \mathbf{[0.1366, -0.9906]} \\ \end{array}
单词祖父男人成人女士男生孩子女孩婴儿向量[−0.6247,0.7809][−0.8275,0.5615][0.2060,0.9785][0.8844,0.4668][−0.8000,−0.6000][0.1871,−0.9823][0.8638,−0.5039][0.1366,−0.9906]
点积和欧几里得距离度量产生的结果相似但不完全相同。例如,基于欧几里得距离,“男孩”与“儿童”的距离比与“婴儿”的距离略近,但查看上图中的单位向量,“男孩”和“婴儿”之间的角度略小于“男孩”和“儿童”之间的角度。
本演示中使用的词向量以及真实 AI 系统使用的词向量都是具有零均值的单位向量,就像上面的点一样。同样的规范化技术适用于更高维度的向量,例如,对于三维语义向量,这些点位于单位球面(半径为 1 的球面)的表面上,如下所示:
零均值三维单位向量

单词 向量 祖父 [ − 0.5426 , 0.6412 , − 0.5426 ] 男人 [ − 0.7191 , 0.4576 , − 0.5230 ] 女士 [ 0.7741 , 0.4168 , − 0.4764 ] 男生 [ − 0.6971 , − 0.5070 , − 0.5070 ] 女孩 [ 0.7543 , − 0.4642 , − 0.4642 ] 国王 [ − 0.5570 , 0.5064 , 0.6583 ] 君主 [ 0.0676 , 0.4730 , 0.8785 ] 女王 [ 0.6608 , 0.3558 , 0.6608 ] 王子 [ − 0.5846 , − 0.4252 , 0.6909 ] 公主 [ 0.6484 , − 0.3990 , 0.6484 ] 孩子 [ 0.0733 , − 0.5866 , − 0.8066 ] 婴儿 [ 0.0642 , − 0.7057 , − 0.7057 ] \begin{array}{ccc} \text{单词} & \text{向量} \\ \text{祖父} & \mathbf{[-0.5426, 0.6412, -0.5426]} \\ \text{男人} & \mathbf{[-0.7191, 0.4576, -0.5230]} \\ \text{女士} & \mathbf{[0.7741, 0.4168, -0.4764]} \\ \text{男生} & \mathbf{[-0.6971, -0.5070, -0.5070]} \\ \text{女孩} & \mathbf{[0.7543, -0.4642, -0.4642]} \\ \text{国王} & \mathbf{[-0.5570, 0.5064, 0.6583]} \\ \text{君主} & \mathbf{[0.0676, 0.4730, 0.8785]} \\ \text{女王} & \mathbf{[0.6608, 0.3558, 0.6608]} \\ \text{王子} & \mathbf{[-0.5846, -0.4252, 0.6909]} \\ \text{公主} & \mathbf{[0.6484, -0.3990, 0.6484]} \\ \text{孩子} & \mathbf{[0.0733, -0.5866, -0.8066]} \\ \text{婴儿} & \mathbf{[0.0642, -0.7057, -0.7057]} \\ \end{array} 单词祖父男人女士男生女孩国王君主女王王子公主孩子婴儿向量[−0.5426,0.6412,−0.5426][−0.7191,0.4576,−0.5230][0.7741,0.4168,−0.4764][−0.6971,−0.5070,−0.5070][0.7543,−0.4642,−0.4642][−0.5570,0.5064,0.6583][0.0676,0.4730,0.8785][0.6608,0.3558,0.6608][−0.5846,−0.4252,0.6909][0.6484,−0.3990,0.6484][0.0733,−0.5866,−0.8066][0.0642,−0.7057,−0.7057]
点积比欧几里得距离更受欢迎,主要有两个原因。首先,点积需要更少的算术运算。对于 300 维向量,点积需要 599 次运算(300 次乘法加上 299 次加法),而欧几里得距离需要 899 次运算,因为它包括 300 次减法。其次,点积正是神经网络中的神经元所计算的:它将其权重向量与输入向量进行点积。
八、创建词嵌入
构建词向量的算法有很多种。这里我们介绍第一种算法,称为带负采样的 Skip-gram (SGNS)。
步骤 1:组建文本语料库
我们可能会选择维基百科文章、新闻报道集或莎士比亚全集。语料库决定了我们要使用的词汇量和单词的共现统计,因为不同的写作风格会以不同的方式使用单词。
步骤 2:选择词汇量 M \mathbf{M} M
如果我们包括人名和地名,大型语料库可以包含一百万个不同的单词。其中许多单词很少出现。为了使嵌入任务易于管理,我们可能决定只保留频率最高的单词,例如,我们可能会选择语料库中最常出现的 50,000 个单词。过滤掉频率最低的单词还可以消除拼写错误,例如,“graet”应该是“great”、“grate”或“greet”。在此阶段,我们还需要决定如何处理标点符号、缩写、下标和上标、特殊字符(如希腊字母或商标符号)以及其他大写字母。
步骤 3:选择上下文窗口大小 C \mathbf{C} C
如果我们使用大小为 C = 2 \mathbf{C=2} C=2 的上下文窗口,我们将查看五个单词块。也就是说,对于语料库中的每个单词,我们将把它左边的 2 个单词和右边的 2 个单词视为其上下文。
步骤 4:汇编共现词典
通过逐个单词地浏览语料库,并向前和向后查看 C \mathbf{C} C 个单词,我们可以确定每个目标单词在其上下文中出现的单词。例如,当 C = 2 \mathbf{C=2} C=2 时,给定文本“Thou shalt not make a machine in the likeness of a human mind”,共现词典将如下所示:
thou -> shalt, not
shalt -> thou, not, make
not -> thou, shalt, make, a
make -> shalt, not, a, machine
a -> not, make, machine, in, image, of, human, mind
machine -> make, a, in, the
in -> a, machine, the, image
the -> machine, in, image, of
image -> in, the, of, a
of -> the, image, a, human
human -> of, a, mind
mind -> a, human
请注意,单词“a”在语料库中出现了两次。它的上下文在词典中组合在一起。实际上,语料库会比这大得多,每个单词都会出现多次,从而形成更丰富的上下文。
步骤 5:选择嵌入大小 N \mathbf{N} N
以便每个单词由 N \mathbf{N} N 个数字的列表表示。 N \mathbf{N} N 的典型值为 300,尽管小嵌入可能每个单词仅使用 100 个数字,而大嵌入可能使用 700 个或更多。较大的 N \mathbf{N} N 值可以编码更多信息,但嵌入需要更长的计算时间和更多的内存来存储。
步骤 6:制作两个表格
每个表格包含 M \mathbf{M} M 行和 N \mathbf{N} N 列。每行代表一个单词。例如,如果我们有 50,000 个单词的词汇表并正在构建 300 个元素的嵌入,则表格的大小将为 50 , 000 × 300 \mathbf{50,000 \times 300} 50,000×300。一个表格 E \mathbf{E} E 用于我们尝试嵌入的目标单词。第二个表格 U \mathbf{U} U 用于用作上下文单词的单词。使用较小的随机数初始化两个表格。
步骤 7:训练过程
在整个训练语料库上滑动一个大小为 2 C + 1 \mathbf{2C+1} 2C+1 的窗口,每次移动一个词。对于窗口中间位置的每个目标词 t \mathbf{t} t,在嵌入表 E \mathbf{E} E 中查找其向量 e \mathbf{e} e。对于出现在窗口其他位置的每个上下文词 u \mathbf{u} u,在上下文表 U \mathbf{U} U 中查找其向量 u \mathbf{u} u。计算点积 e ⋅ u \mathbf{e \cdot u} e⋅u 并将结果通过非线性压缩函数(称为“S 型”或“逻辑”函数)运行,该函数产生 0 到 1 之间的输出值。如果输出小于 1,则使用称为梯度下降学习的技术对向量 e \mathbf{e} e 和 u \mathbf{u} u 进行微小调整;该技术也用于训练神经网络。对所有上下文词重复该过程。这些是正面例子。我们还需要一些负面例子。随机选择 5 到 10 个词汇单词,我们的上下文词典表明这些单词从未出现在目标词的上下文中。应用与上述相同的过程,但现在我们希望压缩后的点积值为 0 而不是 1。相应地对嵌入和上下文向量进行细微调整。我们重复此过程,遍历整个语料库,重复 3 到 50 次。
步骤 8:嵌入表 E \mathbf{E} E 现在包含所需的嵌入
上下文表 U \mathbf{U} U 可以丢弃。
参考:Word Embedding Demo: Tutorial
推荐:
- python 错误记录
- python 笔记
- 数据结构