随着数据量的爆炸性增长和云计算的普及,数据中心内存的多比特错误及由无法纠正错误(UE)导致的停机问题日益凸显,这些故障不仅影响服务质量,还会带来高昂的修复或更换成本。随着工作负载、硬件密度以及对高性能要求的增加,数据中心的规模呈指数级增长。这一趋势直接导致了因设备故障引起的停机成为保持稳定运行的最大挑战之一。
为了应对这一挑战,产业界和学术界均致力于开发与停机相关的解决方案,这些方案主要围绕可靠性(Reliability)、可用性(Availability)和可维护性(Serviceability),即RAS三个核心方面展开。
-
可靠性:指设备防止或纠正错误的能力,通常通过平均无故障时间(MTBF)来量化。高可靠性意味着设备在两次故障之间的平均时间较长,且在错误发生时,系统具备自我修复或隔离错误的功能,从而减少对系统运行的影响。MTBF与恢复时间的关系决定了可靠性水平,即恢复时间越短,MTBF越长,系统的可靠性越高。
-
可用性:关注的是系统正常运行的概率,即用户能否持续获得服务。它通过计算系统停机时间的百分比来量化,目标是确保服务不间断。可用性不仅要求系统能够持续运作,还强调在遇到问题时快速恢复的能力。可用性通常依据每年的“9”数量来量化停机时间,例如,“五个9”(99.999%)的可用性意味着系统每年的停机时间不超过5.26分钟。因此,99.9%和99.99%的可用性分别对应每年526分钟和53分钟的不可用时间。
-
服务性:则涉及系统维护和修理的便捷性,包括如何快速识别和解决故障,以及最小化维护活动对系统运行的影响。系统无需人工干预即可维持运行和自我修复的能力,早期发现并响应潜在问题是提高服务性的关键。
从20世纪40年代贝尔实验室对计算机错误数据的研究,到1951年磁带存储中使用奇偶校验。随着IBM在1968年获得第一项DRAM专利,硬件故障导致的停机和维护问题成为关注焦点,并在1970年代开始在设计中融入RAS理念。此外,早期计算机科学中,如在贝尔实验室对错误数据的研究,已探索了数据冗余作为错误纠正的方法,例如通过存储三份数据来实现错误恢复,尽管这种方式带来了66%的存储冗余。随后,随着Hamming码的引入,仅需少量奇偶校验位即可检测和纠正多位错误,标志着在减少冗余的同时提升错误校正能力的重要进步。
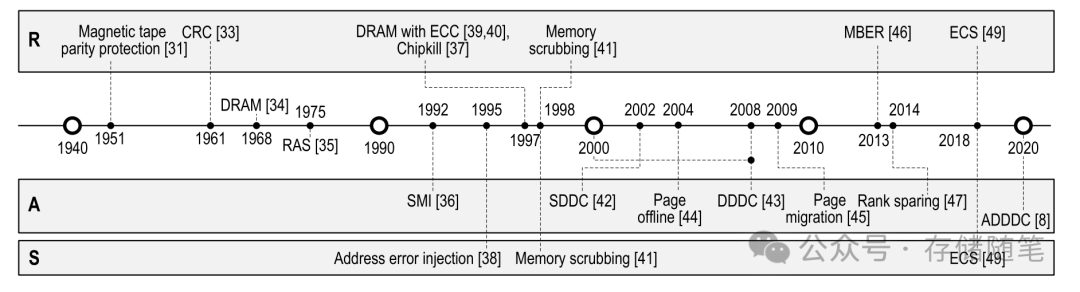
自2000年代初以来,RAS技术已被开发出来,以减少由系统故障或数据丢失导致的服务器停机时间。数据中心的停机成本稳步上升,到2016年,基于99.9%可用性的单个数据中心的停机成本已达到740,000美元。对于拥有多个数据中心的大公司来说,这一成本更为显著。而将可用性提高到99.99%,则可以将成本降至十分之一或更低,凸显了RAS特性对于数据中心的重要性。
更多信息解读:论文解读|数据中心内存RAS技术全景剖析