故障预测是内存可靠性、可用性和服务性(RAS)领域中的一个重要方面,旨在提前识别潜在的不可纠正错误(UE),以防止系统崩溃或数据丢失。
4.1 错误日志记录与预测基础
错误一般通过Linux内核模块Mcelog记录到文件中,包括时间戳、物理地址、服务器名称、物理地址所在的插槽、通道和bank信息,以及错误发生时的内存访问类型(读或写)。由于UE(不可纠正错误)通常导致较高的系统崩溃率,2010年代起,基于历史CE(可纠正错误)统计的UE预测方法被广泛采用。该方法基于一定的历史数据,当某段时间内CE超过一定阈值时,预判可能即将发生UE,并提前更换相关内存部件。
4.2 预测后的预防措施
为阻止预测到的UE发生,采取了诸如控制缓存行隔离错误区域(如牺牲8KB或更小的系统开销)、页面离线(Page Offline)等策略。页面离线通过隔离4KB或更大容量的错误区域,无需额外硬件成本,能有效移除超过94%的UE,且作为系统可控制的最小内存单位,有助于最小化内存容量浪费。
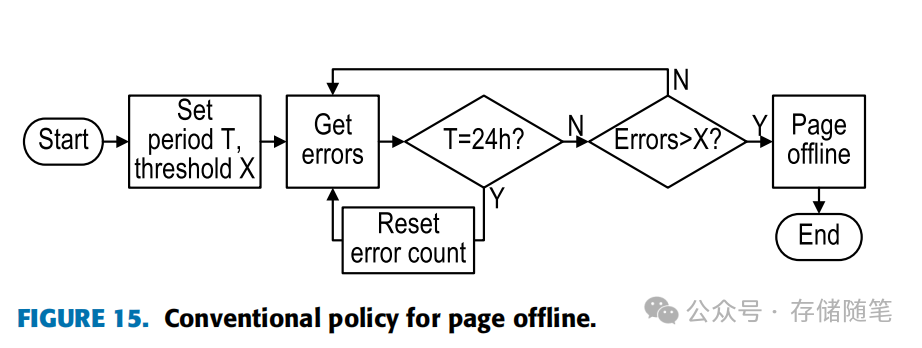
图15描述了传统的页面离线政策,通过设置一个时间窗口T内允许的最大CE次数X来监控错误。当错误计数在指定时间内超过X,触发页面隔离。X的设定依据设备特性调整,考虑了不同DIMM的使用状况和可靠性随时间递增的故障概率,需动态调整以达到最优解决方案。
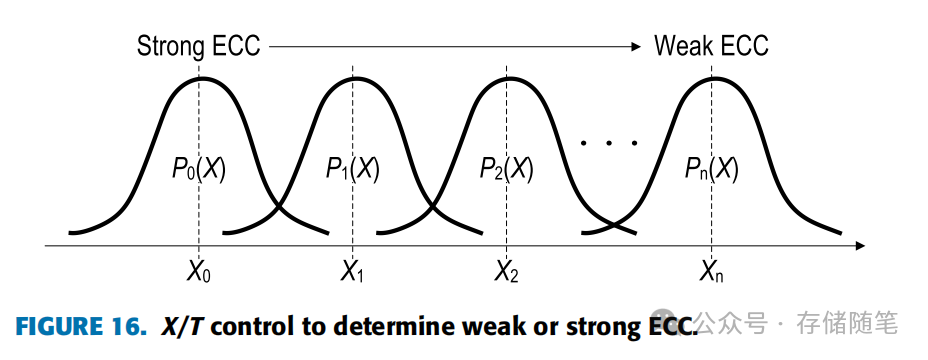
图16展示了通过调整X来控制强弱ECC策略,Pn(X)代表与X相关的纠错能力概率密度函数。
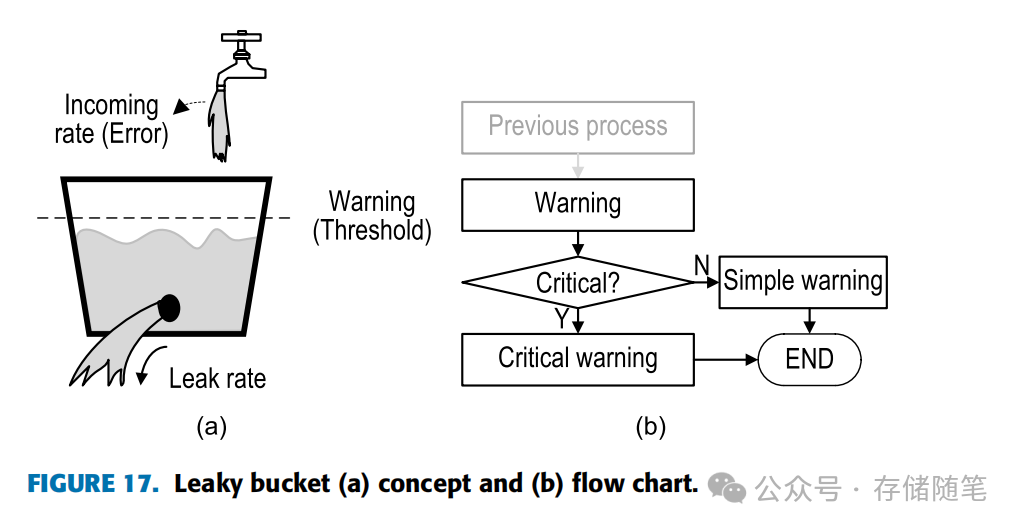
确定X的其中一个方法是漏桶算法,如图17所示。该算法通过设置阈值X,监控UE、DIMM、Socket、页面和CE等部分的错误情况,当累积错误超过阈值时发出警告。漏桶概念中,水流入速率代表错误发生频率,漏水速率(即错误计数衰减速度)根据压力(即系统对错误的容忍度)变化。
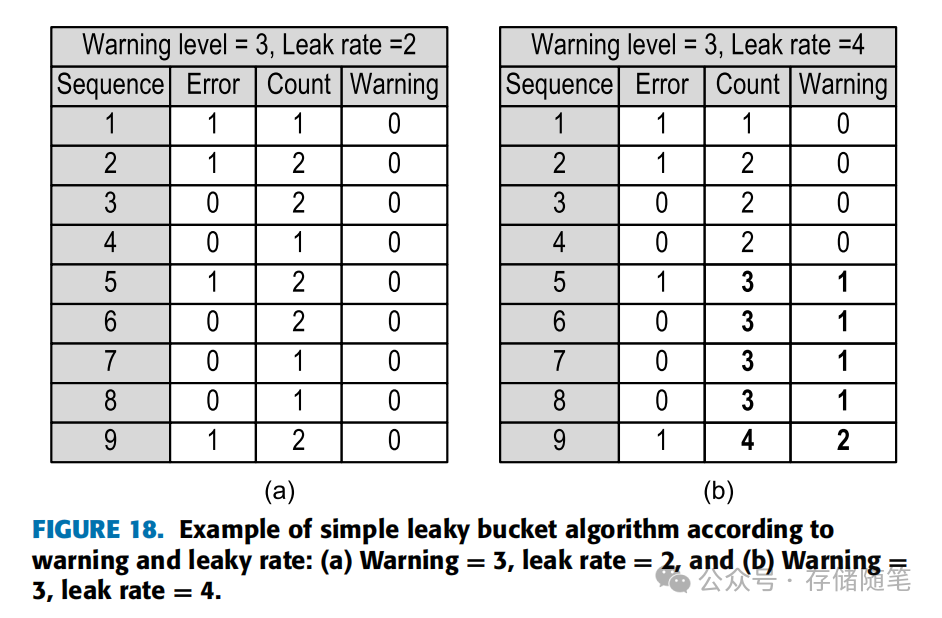
图18展示了基于警告等级和泄漏速率的简单漏桶算法示例,根据不同的配置,决定离线页面的大小和预警级别。
4.3 CE与UE的关联
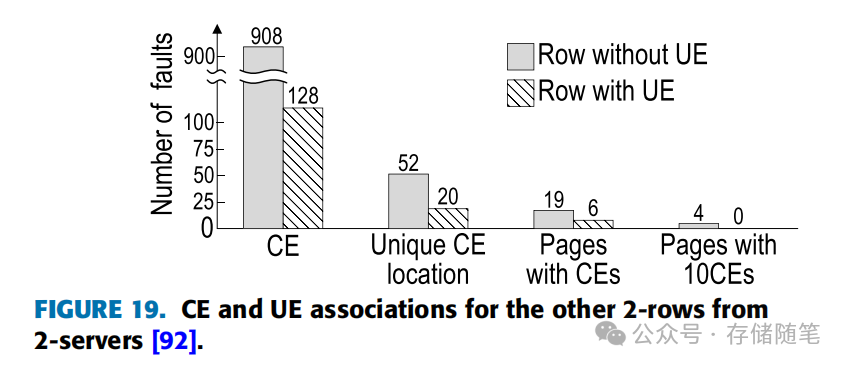
尽管CE计数在预测UE方面至关重要,但跨页错误关联性使得基于单页CE计数的预测面临挑战。图19显示了来自两台服务器的两个不同行的CE与UE关联性,表明拥有更高CE率的行并不一定伴随UE。这促使研究转向基于特定CE模式的UE预测方法。
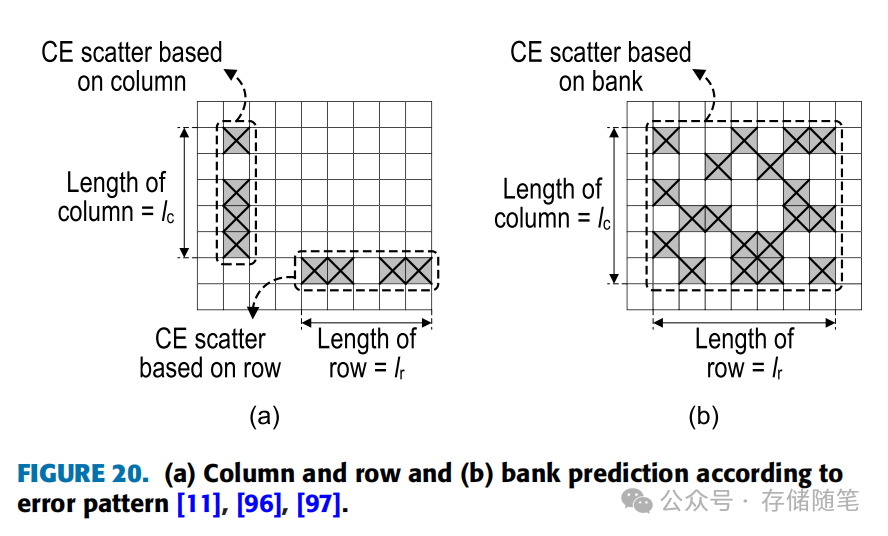
如图20所示,通过分析列、行或bank的错误模式长度,来预测UE的可能性。
4.3.1 基于列Column预测UE
基于列模式的不可纠正错误(UE)预测主要利用了这样一个现象:UE通常在内存列中更频繁地发生且分布分散。这是因为在内存操作中,信号通过晶体管栅极传输时影响较小,但数据沿位线(bit lines)移动,连接到源或漏极时,由于位线的电阻或电容效应,电荷流动可能会受到干扰,导致较高的错误率。在高密度内存中,由于位线细薄且周围信号线众多,这一问题尤为突出。
传统的基于列故障的预测方法通过精确度(Precision)和召回率(Recall)两个指标来评估其性能。精确度衡量当预测发生UE时预测的准确程度,而召回率则表示预测出的UE占实际发生UE总数的比例。公式定义如下:
-
精确度(Precision)= TP / (TP + FP)
-
召回率(Recall)= TP / (TP + FN)
其中,TP(True Positive)是指正确预测出的UE次数,FP(False Positive)是指错误预测出UE但实际上未发生的次数,FN(False Negative)是指实际发生了UE但未预测出的次数。
图21展示了针对CE率(Correctable Error Rate)和列故障的精确度、召回率以及修复次数(维修次数通常指需要隔离或更换的内存模块数量)。横轴上的X值代表重复次数的阈值,即错误发生次数达到多少时触发预测或响应。
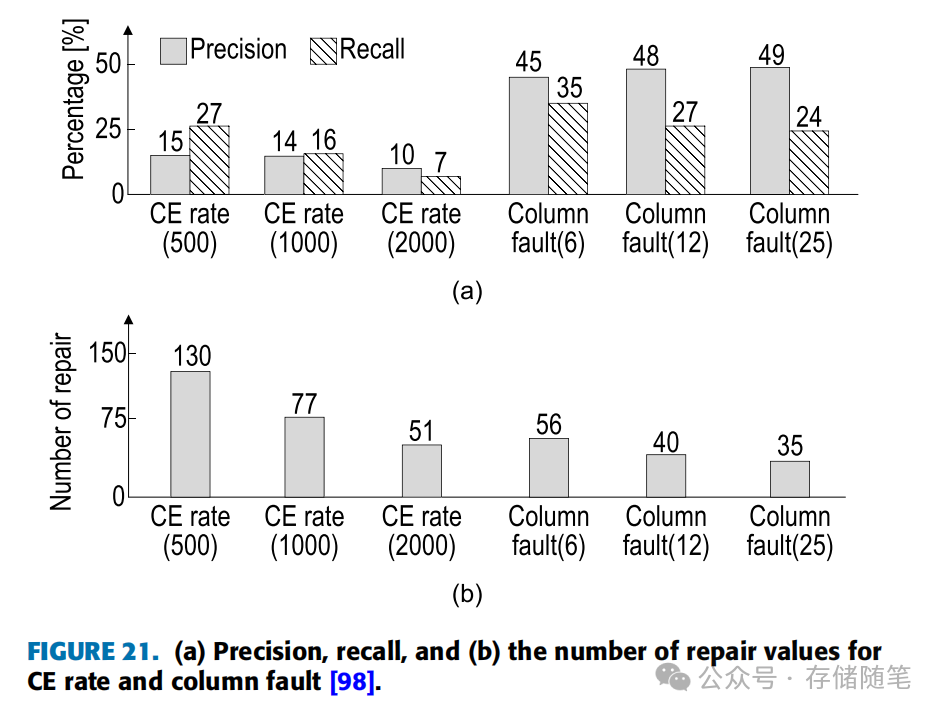
分析结果显示,基于CE率的页面离线策略中,当阈值设为500时,精确度和召回率表现最佳。然而,当阈值提高到2000时,精确度和召回率分别降到了10%和7%,这意味着许多不必要的内存隔离,导致内存资源浪费。相比之下,基于列故障的预测策略在多数情况下提供了更好的性能。即使在较低的阈值(X=6)下,精确度和召回率也能达到45%和35%,尽管此时需要修复的次数较多,意味着维护成本或内存模块替换成本较高。但即便如此,相比于CE率导致的高维修成本,列故障引起的维修成本在较低阈值时仍然较低。当阈值设为最高(X=25)时,基于列故障的预测在精确度、召回率和维修次数上均优于基于CE率的方法。
总结来说,基于列故障的UE预测方法相比基于CE率的方法,能够提供更优的预测效果,减少误报和漏报,同时在一定程度上降低了因过度维修而导致的成本开销。
4.3.2 基于行Row预测UE
图22介绍了一种基于行Row预测模型的应用,它专门分析特定长度lr的行中CE(Correctable Errors,可纠正错误)的扩散情况,用于辅助页面离线方法。类似于之前提到的列预测器,当某个特定模式X的错误重复次数超过预设的行故障阈值(Row Fault, X)时,就认为该错误可能会演变为不可纠正错误(UE)。
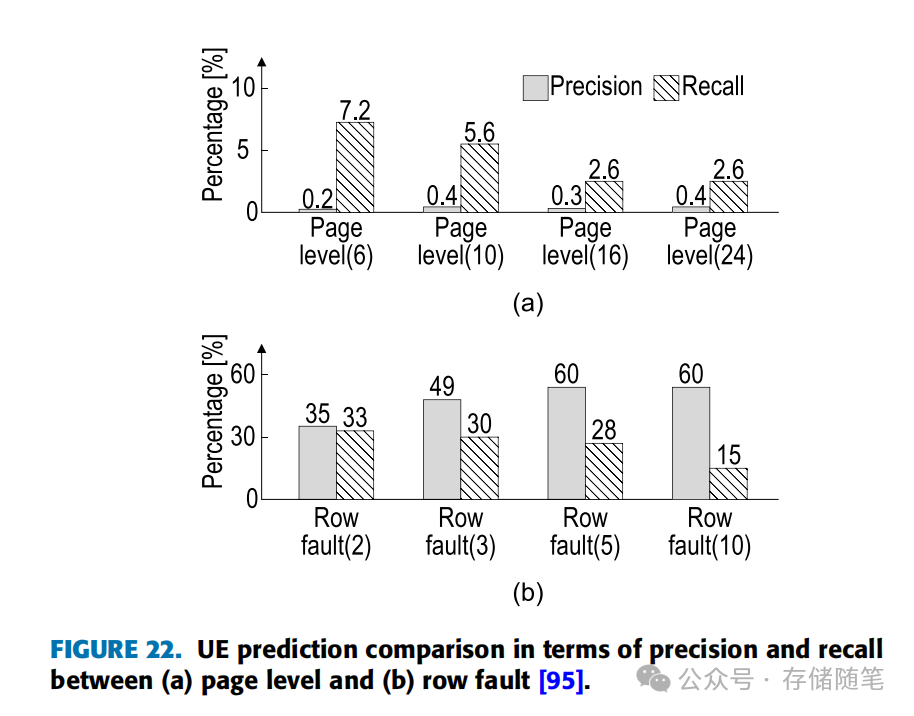
图22(a)展示了当X设置为6、10、16、和24时,相应页面会被标记为离线。在这种情况下,预测的最高精确度(Precision)和召回率(Recall)分别为7.2%和0.4%。然而,当采用行故障预测方法,如图22(b)所示,最高精确度和召回率分别达到了60%和33%。这表明,通过特定行和列的错误模式来进行预测,在精确度和召回率上都优于直接使用CE率进行UE预测。
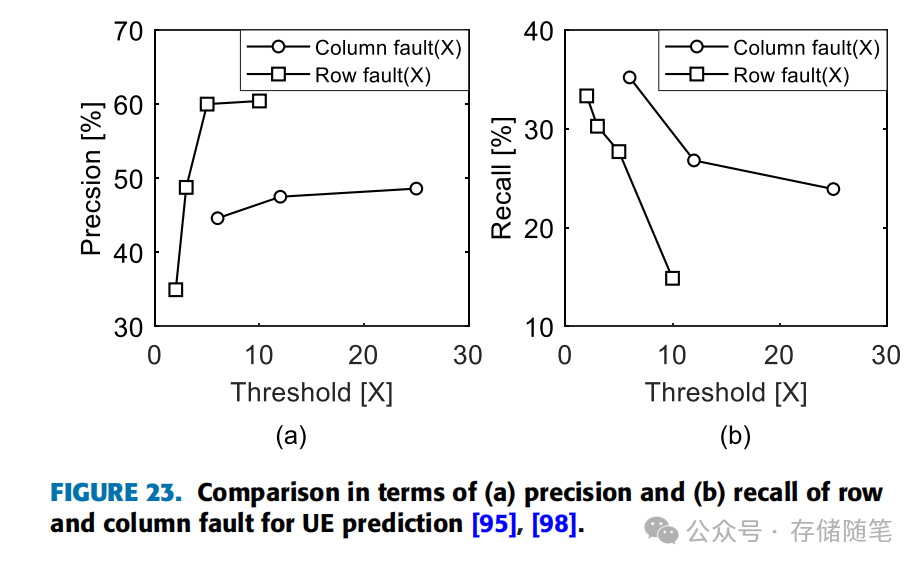
图23进一步对比了基于行故障和列故障的UE预测在精确度和召回率上的表现。在这两种方法中,随着阈值的提高,精确度往往增加而召回率下降。行故障预测在精确度上表现更优,有利于提高UE预测的准确性;相反,列故障预测在召回率方面更有优势,能更好地覆盖实际发生的UE事件。这些结果的差异可能源于多种因素,包括DIMM的工作环境、状态、以及所承受的工作负载等。
综上所述,行和列故障预测各有千秋,行预测在精确度上更胜一筹,适合追求预测准确性的场景,而列预测则在召回率上表现更好,适用于需要广泛捕获潜在UE情况的场合。选择合适的预测策略应基于对系统具体需求和工作条件的综合考量。
4.3.3 混合UE预测
Hybrid UE Prediction方法旨在克服单一预测器在随机出现的DRAM错误面前难以保证高精确度的问题。由于错误的发生受工作负载或数据类型的影响,单纯依靠行或列的错误模式进行UE预测可能不够全面。实际上,有研究表明大约15%-30%的错误发生在列或行中,并且其中约40%的错误是重复出现的。
混合预测方法利用了时间局部性和空间局部性两种特征。时间局部性意味着最近访问过的数据再次被访问的可能性较高。当首次发现符号错误后,若紧接着出现附加的符号错误,那么在1分钟内触发chipkill(一种强大的ECC纠错机制)的概率超过90%。通过关联这种时间特征与UE的发生,可以预测UE的时间点。空间局部性则是指临近的数据点被访问的可能性较大,一旦某单元或特定区域出现错误,周围的单元也应被检查。结合这两种特性,预测覆盖率可提升至80%,重复错误能减少76%,意味着大约63%的故障得以预防,但采用chipkill的开销比SECDED高出38%。
为了解决单预测模型的局限性,可以结合多种类型的预测器形成混合模型。例如,通过深度学习技术,可以整合逻辑回归(LR)、支持向量机(SVM)、分类与回归树(CART)、反向传播(BP)、梯度提升决策树(GBDT)、随机森林(RF)以及极端梯度提升(XGBoost)等多种模型。近期,基于提升法的深度学习技术在UE预测中得到了广泛应用。
在特定研究中,采用了混合预测器策略,结合了列、行和bank预测器,按照0.474、0.246、0.219的比例进行加权,以优化预测效果。这意味着通过智能地组合不同维度的预测模型,可以更全面地覆盖错误模式,提高预测准确性和效率,进而有效减少内存系统中的不可纠正错误,提升系统的稳定性和可靠性。通过这种多维度、多层次的分析与预测,混合UE预测方法为数据中心内存的高效管理与维护提供了一种先进策略。
4.3.4 离线策略性能分析
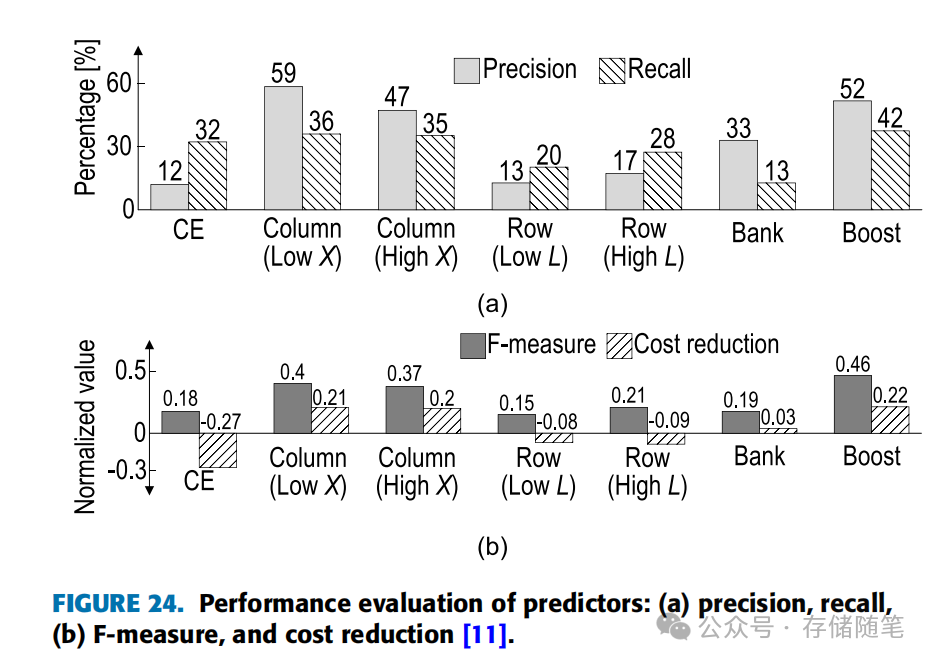
图24展示了对不同预测模型在页面离线策略中的性能分析,该分析基于来自四台不同服务器的数据。评价指标包括精确度(Precision)、召回率(Recall)、F-measure(F-分数)以及成本节省。结果显示,混合方法(特别是采用提升法的Boost)通常比单一模式的预测模型表现更优。当设置的阈值X较低,或者错误模式长度L较长时,预测性能更佳。
F-measure是精确度和召回率的一种调和平均值,旨在平衡两者之间的关系,公式为:
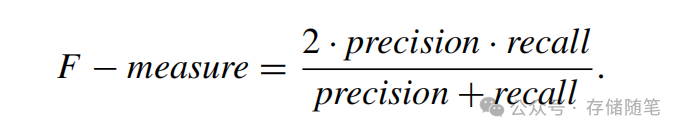
高的F-measure意味着既有较高的精确度也有较高的召回率。例如,尽管CE(Correctable Errors)的召回率相对较高,但由于精确度低,其F-measure可能较低。而对于具有较长模式长度L的行模式预测,由于精确度和召回率较为均衡,F-measure通常会高于CE。
成本节省是通过正确预测UE而减少的维护或替换成本。公式表达如下:
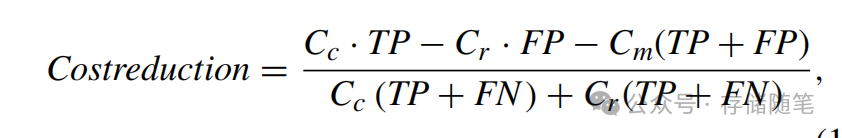
这里,Cc是由于UE发生的单位成本,Cr是DIMM替换的单位成本,Cm是由于数据迁移而产生的单位成本。该公式用于判断基于成本节省的UE预测是否有利。在图24(b)中,CE的情况显示,由于频繁的替换或迁移导致的成本高于因正确预测UE带来的好处,成本节省呈现负值,意味着预测策略在经济上是不利的。
4.3.5 故障检测与刷新
故障检测与刷新(Error Check and Scrub)是提高内存系统可靠性的关键技术之一,尤其是对于早期诊断和识别内存故障,以减少不可纠正错误(UE)带来的成本。这一领域内的研究分为两大类:企业界倾向于研究不增加硬件面积负担的方法,而学术界则更关注即使消耗一定的硬件面积和功耗,也要准确预测UE的技术。
(1)OBET(On-Byte-Error Tracking)技术
图25展示的OBET硬件模块图例中,该技术通过在特定数据单元间增设错误标志来追踪字节错误,这一设计虽然带来了1.6%的面积开销和3%的功率消耗,但提供了有效的错误监测机制。错误标志具有三种状态:0表示无错误,0x00FF表示存在多个错误,0xFFFF表示奇偶校验错误,其余情况则可能为单比特错误或其他类型错误。
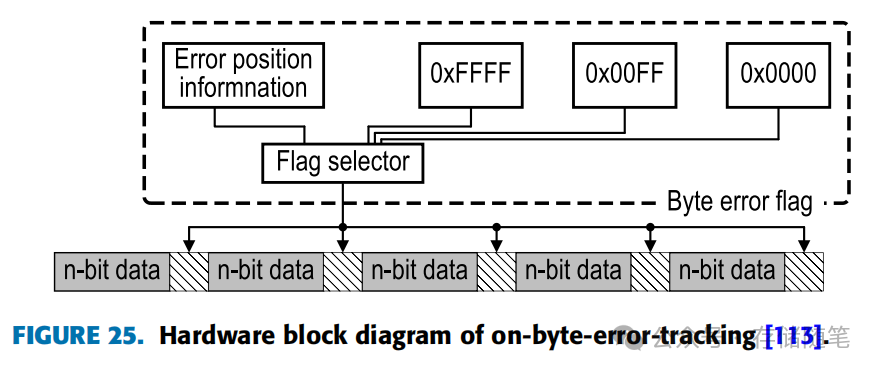
OBET技术的最大优点在于,通过在数据间添加标志并利用这些信息进行选择性刷新(Selective Scrubbing),相比传统的ECS(Error Checking and Scrubbing)方法,它能以更低的开销和功耗运作。传统ECS方法通常需要对特定数据进行全面刷新来检测内存中的CE或UE,这会导致较大的功率消耗或较长的提取错误延迟。因此,OBET特别适用于检测多比特错误或UE,而不是单一错误。
(2)类似技术:DUO和XED
-
DUO:这是一种利用RS码进行小规模冗余设计的方法,尽管它能够提供较强的错误纠正能力,但伴随着较长的延迟。与OBET相似,DUO也是通过牺牲一定的硬件资源来实现更强大的错误处理能力。
-
XED(eXtra Error Detection):XED技术通过在存储奇偶校验信息的第9个芯片中存储带有错误信息的catchwords(捕捉词,或称为错误指示信息),擅长处理多比特错误而非简单的单比特纠正。与OBET类似,XED也因使用寄存器而需要占用一小部分硬件面积,但它在处理复杂错误模式方面表现出色。
综上所述,OBET、DUO和XED等技术均通过创新的错误检测与刷新机制,以不同程度的硬件开销和功耗为代价,实现了对内存错误的高效管理。它们在提高系统可靠性和数据完整性方面发挥着重要作用,特别是对于那些对错误容忍度要求严格的高性能计算和数据中心应用。
完整分析解读参考:数据中心内存RAS技术全景剖析