简介
近年来,人工智能(AI)技术的进步极大地改变了人类与机器的互动方式,特别是在语音处理领域。阿里巴巴通义实验室最近开源了一个名为FunAudioLLM的语音大模型项目,旨在促进人类与大型语言模型(LLMs)之间的自然语音交互。FunAudioLLM包含两个核心模型:SenseVoice和CosyVoice,分别负责语音理解和语音生成。
SenseVoice:语音理解模型
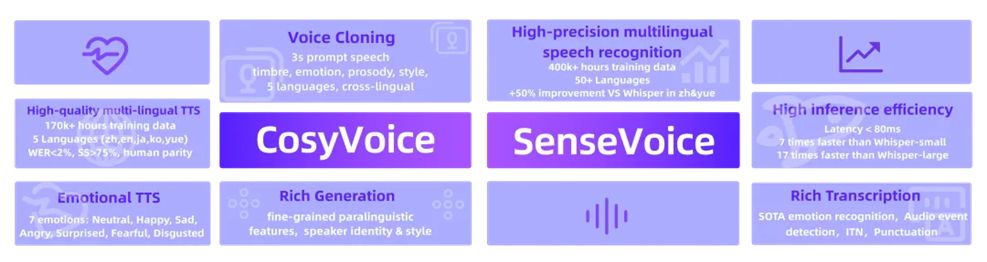
SenseVoice是一个功能强大的语音理解模型,支持多种语音处理任务,包括自动语音识别(ASR)、语言识别(LID)、语音情绪识别(SER)和音频事件检测(AED)。其主要特点包括:
- 多语言支持:SenseVoice支持超过50种语言的语音识别。
- 低延迟:SenseVoice-Small模型具有极低的推理延迟,比Whisper-small快5倍以上,比Whisper-large快15倍以上,适用于实时语音交互应用。
- 高精度:SenseVoice-Large模型在高精度语音识别方面表现出色,适用于需要高精度识别的应用。
- 丰富的语音理解功能:包括情绪识别和音频事件检测,为复杂的语音交互应用提供支持。
CosyVoice:语音生成模型
CosyVoice是一个功能强大的语音生成模型,可以生成自然流畅的语音,并支持多种语言、音色、说话风格和说话人身份的控制。其主要特点包括:
- 多语言语音生成:支持中文、英文、日语、粤语和韩语等多种语言的语音生成。
- 零样本学习:可以通过少量参考语音进行语音克隆。
- 跨语言语音克隆:可以将语音克隆到不同的语言中。
- 情感语音生成:可以生成情感丰富的语音,如快乐、悲伤、愤怒等。
- 指令遵循:可以通过指令文本控制语音输出的各个方面,如说话人身份、说话风格和副语言特征。
训练数据
- SenseVoice:使用了约40万小时的多语言语音数据,并通过开源的音频事件检测(AED)和语音情绪识别(SER)模型生成伪标签,构建了一个包含大量丰富语音识别标签的数据集。
- CosyVoice:使用了多种语言的语音数据集,并通过专门的工具进行语音检测、信噪比(SNR)估计、说话人分割和分离等操作,以提高数据质量。
实验结果
FunAudioLLM在多个语音理解和生成任务上取得了优异的性能:
- 多语言语音识别:SenseVoice在大多数测试集上优于Whisper模型,特别是在低资源语言上表现更佳。
- 语音情绪识别:在7个流行的情绪识别数据集上表现出色,无需微调即可获得高准确率。
- 音频事件检测:能够识别语音中的音频事件,如音乐、掌声和笑声。
- 语音生成质量:CosyVoice在内容一致性和说话人相似度方面表现出色,生成的语音与原始语音高度一致。
应用场景
FunAudioLLM的SenseVoice和CosyVoice模型可以应用于多个场景,包括:
- 语音翻译:将输入语音翻译成目标语言,并生成目标语言的语音。
- 情感语音聊天:识别输入语音的情绪和音频事件,并生成与情绪相符的语音。
- 交互式播客:根据实时世界知识和内容生成播客脚本,并使用CosyVoice合成语音。
- 有声读物:分析文本中的情感和角色,并使用CosyVoice合成具有丰富情感的有声读物。
局限性
尽管FunAudioLLM在多个方面表现出色,但仍存在一些局限性:
- 低资源语言:SenseVoice在低资源语言上的语音识别准确率较低。
- 流式识别:SenseVoice不支持流式语音识别。
- 语言支持:CosyVoice支持的语言数量有限。
- 情感和风格推断:CosyVoice需要明确的指令才能生成特定情绪和风格的语音。
- 唱歌:CosyVoice在唱歌方面表现不佳。
- 端到端训练:FunAudioLLM的模型不是与LLMs端到端训练的,这可能会引入误差传播。
总的来说,FunAudioLLM在语音理解和生成方面展现了强大的能力,为语音交互应用提供了新的可能性。通过开源,阿里巴巴希望能够促进社区的参与和进一步发展。
高性价比GPU算力:https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_0712_shemei