1. 背景
视频中物体分割是视频理解的基础算法,也是对淘宝商品视频分析和加工所依赖的重要能力。传统的视频分割任务一般分为两种类型:一种是VOS(Video Object Segmentation),该任务需要在第一帧给出物体的初始分割标注,并在此基础上对视频后续帧中的标定物体进行跟踪和分割;另一种是VIS(Video Instance Segmentation),这个任务目标是在预定的物体类别范围内,实现物体的检测、分类、跟踪和分割。
VOS需要给定第一帧标注,在实际应用中可行性低,因为视频的第一帧可能不包含需要分割的商品,另外在批量处理场景也难以通过交互给出物体的分割区域;VIS方案需要预先定义物体的类别范围,但对于淘宝平台而言,商品种类和样式繁多,且新品增速快,无法预先确定需要分割的物体类别集合。
为了实现从视频中分割任意物体,我们提出了一个新任务:视频感兴趣物体实例分割(VOIS,Video Object of Interest Segmentation),给定视频和目标物体图像,从视频中检测、跟踪并分割出目标物体。同时我们设计了一种基于双路Transformer融合图像和视频特征的方案,实现给定任意视频和感兴趣图像对,从视频中跟踪并分割出给定的物体。基于该工作论文已发表在AAAI 2023,欢迎阅读交流。
论 文: Video Object of Interest Segmentation
下 载(点击↓阅读原文)::https://arxiv.org/abs/2212.02871
2. 任务介绍&数据集
2.1 VOIS任务介绍
任务定义:给定一个视频和感兴趣物体的图像,从视频中分割出与感兴趣物体相关的实例。
相关物体(实例):是指视频中的物体在样式、类别和颜色等方面都与图片中的物体一致。物体存在一定的形变、角度变化等情况,仍被认为是相关物体。
分割目标:需对所有的相关物体实例实现跟踪和分割,如果存在多个相关物体,需要能够单独区分实例。

2.2 数据集
数据集构建
对于VOIS任务,目前没有与之匹配的数据集,因此我们重新构建了一个视频图像对组成的视频实例分割数据集。数据集中的视频来源于淘宝直播场景,图片来源于淘宝商品白底图,标注方式为人工标注。数据集中共包含2418个视频片段和商品图像样本对。其中,视频2003个,目标商品图像2418个,共包含3341个目标物体,11.4万个掩码图(视频和图的掩码数量总和)。每个视频长度在5秒~7.2秒之间,同时在数据构建时保证视频中有目标物体出现。由于视频的来源为淘宝直播,我们将数据集命名为LiveVideos,LiveVideos与常用视频分割数据集对比的情况见下表:
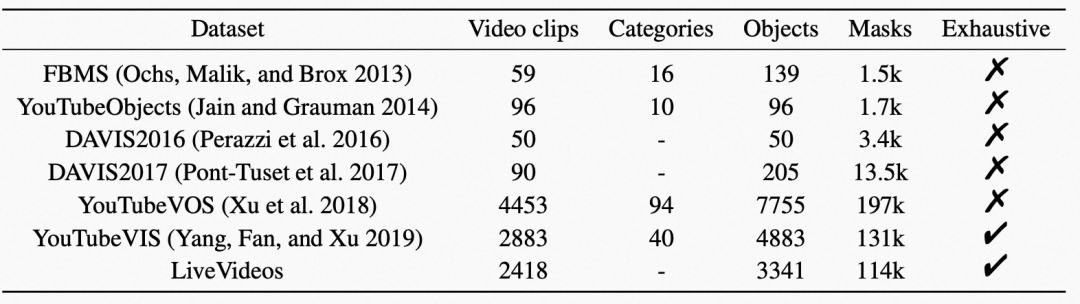
另外,这个数据集也可以作为基础数据集支持其他视频分析相关任务使用,比如视频检索(Video Retrieval),视频精彩片段判断(Video Highlight)等。
评价指标
VOIS的目标与VIS任务类似,均需从视频中检测、跟踪并分割目标物体,因此,我们应用VIS任务中使用的平均准确率(AP, Average Precision )和平均召回率(AR,Average Recall)指标来对VOIS任务的效果进行评估。
3. 方案介绍
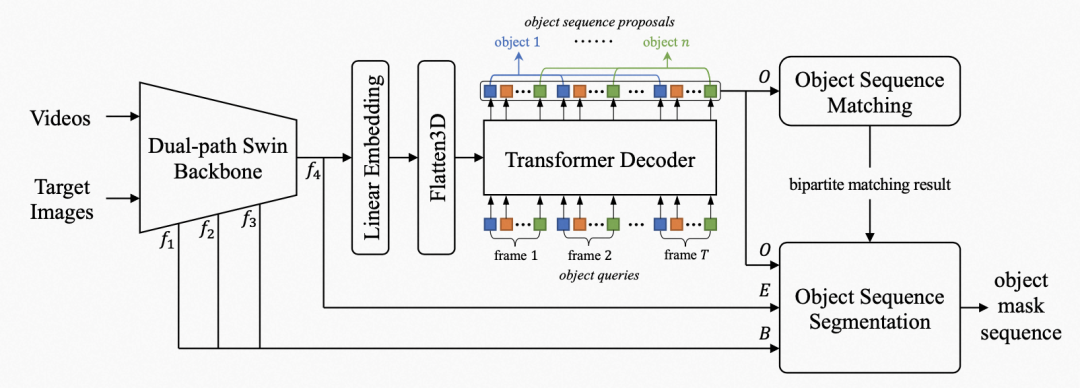
为了实现感兴趣物体实例分割,我们提出了一种Encoder-Decoder结构,包括对图片和视频编码、特征解码和目标物体检测、掩码分割几个部分,主要流程如下:
3.1 特征提取
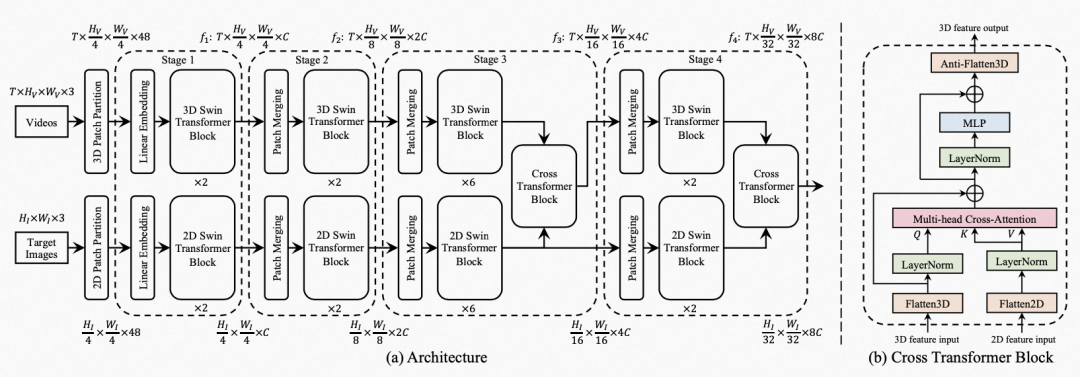
由于VOIS任务需要同时处理一个视频和一个图像,我们使用一个双路Transformer结构来提取视频和图像特征。考虑到效果和时效性,我们采用了Swin Transformer作为特征提取结构,Swin Transformer的特征提取包括4个阶段(Stage),每个阶段对空间维度进行下采样,实现特征提取。
3.2 特征融合
为了将图片和视频的特征结合在一起,我们同时将两个特征输入到Cross Transformer模块,生成融合特征。Swin Transformer的特征提取模块包含4个阶段,我们将Cross Transformer模块添加到第3和第4阶段,以融合更高阶的模型特征,Cross Transformer采用常用的Multi-head Cross-Attention结构。
3.3 实例生成
受到DETR的启发,我们使用一个Transformer Decoder从融合特征中生成物体的候选集合。在融合特征进入到Transformer Decoder之前,我们利用Embedding层实现对特征维度的匹配。经Decoder之后,我们从视频中的每一帧中解码出n个物体,n为预定义的超参数。
3.4 物体匹配
在物体匹配过程,我们利用二部图匹配损失(Bipartite Matching Loss)训练匹配模块,将预测实例和标注(Ground Truth)匹配。在进行了二部图匹配之后,候选物体与目标物体之间将具有最优的匹配方案,也就是最短距离。根据匹配结果,即可找到视频中的感兴趣物体的相关实例。
3.5 视频分割
视频分割环节,使用视频序列分割模块为每个候选物体生成分割结果。我们利用匈牙利损失(Hungarian Loss)实现分割模块的训练,匈牙利损失主要包括:分类、包围框回归和分割三个模块,其中分类模块输出代表候选物体的置信度,包围框回归和分割模块的输出分别代表物体的包围框和分割结果。
4. 实验
4.1 Baseline搭建
由于现有的视频分割方案(如VOS和VIS任务的解决方案)跟VOIS设定存在差异,我们在任务定义的时候额外给定了一张输入图片,因此现有的视频分割方法无法直接与之对比。为了实现合理的方案对照,我们在现有视频分割方案的基础上,增加新的图像编码分支,复现不同方案在VOIS数据上的效果。我们基于MaskTrack R-CNN 和 VisTR两个实例分割方案实现对比Baseline。
MaskTrack R-CNN模型
我们额外增加一条ResNet分支作为图像特征提取Backbone,然后使用Cross Transformer融合图像和视频两种特征,使用双路输入的特征提取和特征融合模块替代原始Backbone。
VisTR模型
VisTR采用了ResNet作为特征提取Backbone,我们采取跟改造MaskTrack R-CNN类似的方式提取图像特征,用融合特征替换原始Backbone。由于VisTR包含Transformer特征处理模块,我们将VisTR模型里的Transformer层改为Cross Transformer,作为视频、图像特征的融合,最后将融合特征输出给Decoder模块。
4.2 对比实验
实验数据
在完成Baseline模型的适配后,我们实验对比了MaskTrack R-CNN 、VisTR和我们提出方案的视频分割效果。实验结果可以看出,我们的双路Swin Transformer方案在平均准确率(AP)和平均召回率(AR)指标上均优于两个Baseline。

不同方案效果对比示例
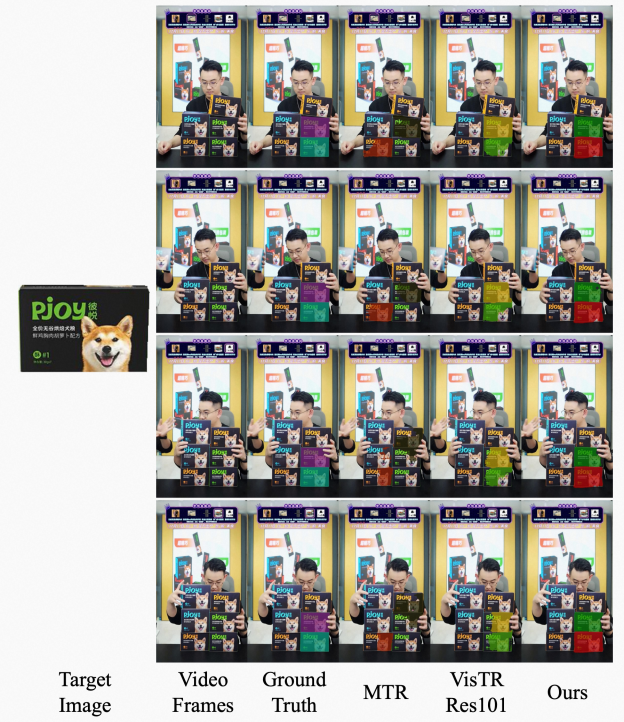
在上图中,左侧给定的是目标物体的图像,右侧的第一列为原始视频帧,右侧第二列为标注结果,右侧的后三列是不同方法的分割结果。在分割结果中,不同颜色代表不同的实例。由于给定的商品(物体)可能包含不同的包装样式,视频中包含很多相似的物品,准确地找出给定物体存在一定难度。从分割结果上可以看出,我们提出的方案在物体识别能力和目标分割准确度上均优于其他方法。
4.3 消融实验
验证目标图像的作用
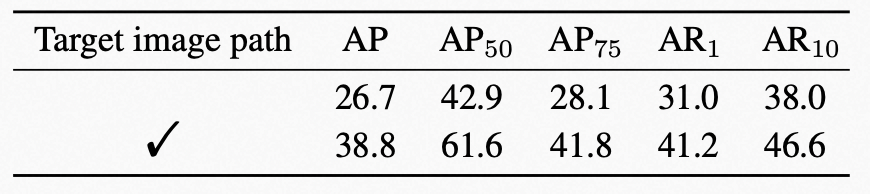
在VOIS任务定义和模型构建过程时,我们在数据集中提供并在模型中使用了感兴趣的目标图像,我们期望提供的感兴趣图像能够引导模型从视频中找到正确的物体,在此我们验证了给定图像对分割效果的影响。具体来讲,我们在模型中删除图像特征提取分支,只保留视频特征提取分支,与双路输入的模型对比效果。我们发现在去除目标图像分支后,模型的AP和AR1分别下跌了12.1和10.2。由此验证在VOIS任务中,给定图像特征直接影响视频分割的效果,且图像在模型推理过程中可以正确地引导视频分割目标物体。
选择最优模型结构
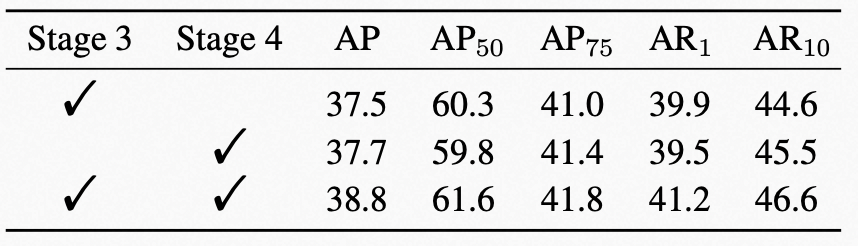
在特征融合时, 我们在Swin Transformer的第3、4层添加了Cross Transformer结构,原因为网络初始层只包含低层模型特征,同时前两层的特征图较大,使得Cross Transformer的计算占用过多显存空间难以计算。因此我们主要关注在第3、4阶段(Stage)验证添加Cross Transformer的效果。只在第3阶段或第4阶段添加Cross Transformer,与两层均添加相比 AP 分别降低1.1和1.3,AR1分别降低0.7和0.3。由此可见,两次特征融合可以更好地匹配视频和图像特征。
5. 总结和展望
为了突破传统视频分割算法的局限性,我们提出了一种应用场景更加广泛的视频分割范式VOIS:根据提供的视频和目标物体图像,对视频中的目标物体进行实例分割。同时,我们提出了一种有效解决VOIS任务的模型,该模型可以学习到一种通用的、对视频和图像特征进行提取和匹配的能力,从而能够有效处理任意给定的视频和图像对,满足我们面临的商品样式多、新品增速快的海量视频分析场景。然而,目前方案仍有一定的扩展空间,比如:给定的图像中包含多个物体时,如何在视频中对不同的物体实现多类别的实例分割等,未来我们也将持续在相关方向上探索。
6. 关于我们
我们是阿里妈妈创意&内容算法团队,致力于推动广告创意和内容投放产业的AI升级,努力推动创意制作、理解、模型预估和广告投放的全栈智能化。得益于阿里巴巴庞大而真实的营销场景,团队在图像技术、视频技术、文案生成、广告投放等领域持续发力和创新,现已构建出图片与短视频创意自动生成,创意个性化投放,智能文案写作,全自动与交互式抠图等特色产品,论文发表于CVPR、ICCV、AAAI、ACMMM、WWW、EMNLP、CIKM、ICASSP 等领域知名会议。用AI赋能现代营销,驱动产业升级。真诚欢迎CV、NLP和推荐系统相关领域的同学加入!
投递简历邮箱:
alimama_chuangyi@service.alibaba.com
7. 参考文献
[1] Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; and Guo, B. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV.
[2] Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; and Hu, H. 2022. Video swin transformer. In CVPR.
[3] Wang, Y.; Xu, Z.; Wang, X.; Shen, C.; Cheng, B.; Shen, H.; and Xia, H. 2021. End-to-end video instance segmentation with transformers. In CVPR.
[4] Ge, W.; Lu, X.; and Shen, J. 2021. Video object segmentation using global and instance embedding learning. In CVPR.
[5] Voigtlaender, P.; Chai, Y.; Schroff, F.; Adam, H.; Leibe, B.; and Chen, L.C. 2019. Feelvos: Fast end-to-end embedding learning for video object segmentation. In CVPR.
[6] Yang, L.; Fan, Y.; and Xu, N. 2019. Video instance segmentation. In ICCV.
END

也许你还想看
丨营销文案的“瑞士军刀”:阿里妈妈智能文案多模态、多场景探索
丨实现"模板自由"?阿里妈妈全自动无模板图文创意生成
丨告别拼接模板 —— 阿里妈妈动态描述广告创意
丨如何快速选对创意 —— 阿里妈妈广告创意优选

喜欢要“分享”,好看要“点赞”哦ღ~
↓欢迎留言参与讨论↓