今天是参加昇思25天学习打卡营的第21天,今天打卡的课程是“CycleGAN 图像风格迁移互换”,这里做一个简单的分享。
1.简介
从今天开始到第25天的学习内容都是生成式网络的内容。今天要学习的第一个生成式网络是CycleGAN,目标是实现图像风格迁移互换。
CycleGAN(Cycle Generative Adversarial Network) 即循环对抗生成网络,来自论文 Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks 。该模型实现了一种在没有配对示例的情况下学习将图像从源域 X 转换到目标域 Y 的方法。
该模型一个重要应用领域是域迁移(Domain Adaptation),可以通俗地理解为图像风格迁移。其实在 CycleGAN 之前,就已经有了域迁移模型,比如 Pix2Pix ,但是 Pix2Pix 要求训练数据必须是成对的,而现实生活中,要找到两个域(画风)中成对出现的图片是相当困难的,因此 CycleGAN 诞生了,它只需要两种域的数据,而不需要他们有严格对应关系,是一种新的无监督的图像迁移网络。
2.模型架构
- 模型结构
CycleGAN 网络本质上是由两个镜像对称的 GAN 网络组成,其结构如下图所示(图片来源于原论文):
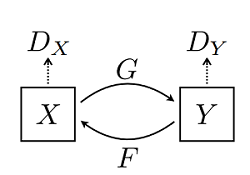
为了方便理解,这里以苹果和橘子为例介绍。上图中 𝑋𝑋 可以理解为苹果,𝑌𝑌 为橘子;𝐺𝐺 为将苹果生成橘子风格的生成器,𝐹𝐹 为将橘子生成的苹果风格的生成器,𝐷𝑋𝐷𝑋 和 𝐷𝑌𝐷𝑌 为其相应判别器,具体生成器和判别器的结构可见下文代码。模型最终能够输出两个模型的权重,分别将两种图像的风格进行彼此迁移,生成新的图像。
该模型一个很重要的部分就是损失函数,在所有损失里面循环一致损失(Cycle Consistency Loss)是最重要的。循环损失的计算过程如下图所示(图片来源于原论文):
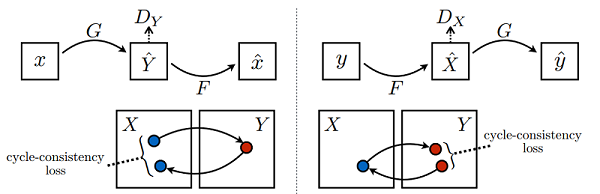
图中苹果图片 𝑥𝑥 经过生成器 𝐺𝐺 得到伪橘子 𝑌̂ 𝑌^,然后将伪橘子 𝑌̂ 𝑌^ 结果送进生成器 𝐹𝐹 又产生苹果风格的结果 𝑥̂ 𝑥^,最后将生成的苹果风格结果 𝑥̂ 𝑥^ 与原苹果图片 𝑥𝑥 一起计算出循环一致损失,反之亦然。循环损失捕捉了这样的直觉,即如果我们从一个域转换到另一个域,然后再转换回来,我们应该到达我们开始的地方。
- 生成器构建
本案例生成器的模型结构参考的 ResNet 模型的结构,参考原论文,对于128×128大小的输入图片采用6个残差块相连,图片大小为256×256以上的需要采用9个残差块相连,所以本文网络有9个残差块相连,超参数 n_layers 参数控制残差块数。
生成器的结构如下所示:

具体的模型结构请参照下文代码:
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore.common.initializer import Normal
weight_init = Normal(sigma=0.02)
class ConvNormReLU(nn.Cell):
def __init__(self, input_channel, out_planes, kernel_size=4, stride=2, alpha=0.2, norm_mode='instance',
pad_mode='CONSTANT', use_relu=True, padding=None, transpose=False):
super(ConvNormReLU, self).__init__()
norm = nn.BatchNorm2d(out_planes)
if norm_mode == 'instance':
norm = nn.BatchNorm2d(out_planes, affine=False)
has_bias = (norm_mode == 'instance')
if padding is None:
padding = (kernel_size - 1) // 2
if pad_mode == 'CONSTANT':
if transpose:
conv = nn.Conv2dTranspose(input_channel, out_planes, kernel_size, stride, pad_mode='same',
has_bias=has_bias, weight_init=weight_init)
else:
conv = nn.Conv2d(input_channel, out_planes, kernel_size, stride, pad_mode='pad',
has_bias=has_bias, padding=padding, weight_init=weight_init)
layers = [conv, norm]
else:
paddings = ((0, 0), (0, 0), (padding, padding), (padding, padding))
pad = nn.Pad(paddings=paddings, mode=pad_mode)
if transpose:
conv = nn.Conv2dTranspose(input_channel, out_planes, kernel_size, stride, pad_mode='pad',
has_bias=has_bias, weight_init=weight_init)
else:
conv = nn.Conv2d(input_channel, out_planes, kernel_size, stride, pad_mode='pad',
has_bias=has_bias, weight_init=weight_init)
layers = [pad, conv, norm]
if use_relu:
relu = nn.ReLU()
if alpha > 0:
relu = nn.LeakyReLU(alpha)
layers.append(relu)
self.features = nn.SequentialCell(layers)
def construct(self, x):
output = self.features(x)
return output
class ResidualBlock(nn.Cell):
def __init__(self, dim, norm_mode='instance', dropout=False, pad_mode="CONSTANT"):
super(ResidualBlock, self).__init__()
self.conv1 = ConvNormReLU(dim, dim, 3, 1, 0, norm_mode, pad_mode)
self.conv2 = ConvNormReLU(dim, dim, 3, 1, 0, norm_mode, pad_mode, use_relu=False)
self.dropout = dropout
if dropout:
self.dropout = nn.Dropout(p=0.5)
def construct(self, x):
out = self.conv1(x)
if self.dropout:
out = self.dropout(out)
out = self.conv2(out)
return x + out
class ResNetGenerator(nn.Cell):
def __init__(self, input_channel=3, output_channel=64, n_layers=9, alpha=0.2, norm_mode='instance', dropout=False,
pad_mode="CONSTANT"):
super(ResNetGenerator, self).__init__()
self.conv_in = ConvNormReLU(input_channel, output_channel, 7, 1, alpha, norm_mode, pad_mode=pad_mode)
self.down_1 = ConvNormReLU(output_channel, output_channel * 2, 3, 2, alpha, norm_mode)
self.down_2 = ConvNormReLU(output_channel * 2, output_channel * 4, 3, 2, alpha, norm_mode)
layers = [ResidualBlock(output_channel * 4, norm_mode, dropout=dropout, pad_mode=pad_mode)] * n_layers
self.residuals = nn.SequentialCell(layers)
self.up_2 = ConvNormReLU(output_channel * 4, output_channel * 2, 3, 2, alpha, norm_mode, transpose=True)
self.up_1 = ConvNormReLU(output_channel * 2, output_channel, 3, 2, alpha, norm_mode, transpose=True)
if pad_mode == "CONSTANT":
self.conv_out = nn.Conv2d(output_channel, 3, kernel_size=7, stride=1, pad_mode='pad',
padding=3, weight_init=weight_init)
else:
pad = nn.Pad(paddings=((0, 0), (0, 0), (3, 3), (3, 3)), mode=pad_mode)
conv = nn.Conv2d(output_channel, 3, kernel_size=7, stride=1, pad_mode='pad', weight_init=weight_init)
self.conv_out = nn.SequentialCell([pad, conv])
def construct(self, x):
x = self.conv_in(x)
x = self.down_1(x)
x = self.down_2(x)
x = self.residuals(x)
x = self.up_2(x)
x = self.up_1(x)
output = self.conv_out(x)
return ops.tanh(output)
# 实例化生成器
net_rg_a = ResNetGenerator()
net_rg_a.update_parameters_name('net_rg_a.')
net_rg_b = ResNetGenerator()
net_rg_b.update_parameters_name('net_rg_b.')
- 优化器和损失函数

# 构建生成器,判别器优化器
optimizer_rg_a = nn.Adam(net_rg_a.trainable_params(), learning_rate=0.0002, beta1=0.5)
optimizer_rg_b = nn.Adam(net_rg_b.trainable_params(), learning_rate=0.0002, beta1=0.5)
optimizer_d_a = nn.Adam(net_d_a.trainable_params(), learning_rate=0.0002, beta1=0.5)
optimizer_d_b = nn.Adam(net_d_b.trainable_params(), learning_rate=0.0002, beta1=0.5)
# GAN网络损失函数,这里最后一层不使用sigmoid函数
loss_fn = nn.MSELoss(reduction='mean')
l1_loss = nn.L1Loss("mean")
def gan_loss(predict, target):
target = ops.ones_like(predict) * target
loss = loss_fn(predict, target)
return loss
- 前向计算
为了减少模型振荡[1],这里遵循 Shrivastava 等人的策略[2],使用生成器生成图像的历史数据而不是生成器生成的最新图像数据来更新鉴别器。这里创建 image_pool 函数,保留了一个图像缓冲区,用于存储生成器生成前的50个图像。
import mindspore as ms
# 前向计算
def generator(img_a, img_b):
fake_a = net_rg_b(img_b)
fake_b = net_rg_a(img_a)
rec_a = net_rg_b(fake_b)
rec_b = net_rg_a(fake_a)
identity_a = net_rg_b(img_a)
identity_b = net_rg_a(img_b)
return fake_a, fake_b, rec_a, rec_b, identity_a, identity_b
lambda_a = 10.0
lambda_b = 10.0
lambda_idt = 0.5
def generator_forward(img_a, img_b):
true = Tensor(True, dtype.bool_)
fake_a, fake_b, rec_a, rec_b, identity_a, identity_b = generator(img_a, img_b)
loss_g_a = gan_loss(net_d_b(fake_b), true)
loss_g_b = gan_loss(net_d_a(fake_a), true)
loss_c_a = l1_loss(rec_a, img_a) * lambda_a
loss_c_b = l1_loss(rec_b, img_b) * lambda_b
loss_idt_a = l1_loss(identity_a, img_a) * lambda_a * lambda_idt
loss_idt_b = l1_loss(identity_b, img_b) * lambda_b * lambda_idt
loss_g = loss_g_a + loss_g_b + loss_c_a + loss_c_b + loss_idt_a + loss_idt_b
return fake_a, fake_b, loss_g, loss_g_a, loss_g_b, loss_c_a, loss_c_b, loss_idt_a, loss_idt_b
def generator_forward_grad(img_a, img_b):
_, _, loss_g, _, _, _, _, _, _ = generator_forward(img_a, img_b)
return loss_g
def discriminator_forward(img_a, img_b, fake_a, fake_b):
false = Tensor(False, dtype.bool_)
true = Tensor(True, dtype.bool_)
d_fake_a = net_d_a(fake_a)
d_img_a = net_d_a(img_a)
d_fake_b = net_d_b(fake_b)
d_img_b = net_d_b(img_b)
loss_d_a = gan_loss(d_fake_a, false) + gan_loss(d_img_a, true)
loss_d_b = gan_loss(d_fake_b, false) + gan_loss(d_img_b, true)
loss_d = (loss_d_a + loss_d_b) * 0.5
return loss_d
def discriminator_forward_a(img_a, fake_a):
false = Tensor(False, dtype.bool_)
true = Tensor(True, dtype.bool_)
d_fake_a = net_d_a(fake_a)
d_img_a = net_d_a(img_a)
loss_d_a = gan_loss(d_fake_a, false) + gan_loss(d_img_a, true)
return loss_d_a
def discriminator_forward_b(img_b, fake_b):
false = Tensor(False, dtype.bool_)
true = Tensor(True, dtype.bool_)
d_fake_b = net_d_b(fake_b)
d_img_b = net_d_b(img_b)
loss_d_b = gan_loss(d_fake_b, false) + gan_loss(d_img_b, true)
return loss_d_b
# 保留了一个图像缓冲区,用来存储之前创建的50个图像
pool_size = 50
def image_pool(images):
num_imgs = 0
image1 = []
if isinstance(images, Tensor):
images = images.asnumpy()
return_images = []
for image in images:
if num_imgs < pool_size:
num_imgs = num_imgs + 1
image1.append(image)
return_images.append(image)
else:
if random.uniform(0, 1) > 0.5:
random_id = random.randint(0, pool_size - 1)
tmp = image1[random_id].copy()
image1[random_id] = image
return_images.append(tmp)
else:
return_images.append(image)
output = Tensor(return_images, ms.float32)
if output.ndim != 4:
raise ValueError("img should be 4d, but get shape {}".format(output.shape))
return output
- 计算梯度和反向传播
其中梯度计算也是分开不同的模型来进行的:
from mindspore import value_and_grad
# 实例化求梯度的方法
grad_g_a = value_and_grad(generator_forward_grad, None, net_rg_a.trainable_params())
grad_g_b = value_and_grad(generator_forward_grad, None, net_rg_b.trainable_params())
grad_d_a = value_and_grad(discriminator_forward_a, None, net_d_a.trainable_params())
grad_d_b = value_and_grad(discriminator_forward_b, None, net_d_b.trainable_params())
# 计算生成器的梯度,反向传播更新参数
def train_step_g(img_a, img_b):
net_d_a.set_grad(False)
net_d_b.set_grad(False)
fake_a, fake_b, lg, lga, lgb, lca, lcb, lia, lib = generator_forward(img_a, img_b)
_, grads_g_a = grad_g_a(img_a, img_b)
_, grads_g_b = grad_g_b(img_a, img_b)
optimizer_rg_a(grads_g_a)
optimizer_rg_b(grads_g_b)
return fake_a, fake_b, lg, lga, lgb, lca, lcb, lia, lib
# 计算判别器的梯度,反向传播更新参数
def train_step_d(img_a, img_b, fake_a, fake_b):
net_d_a.set_grad(True)
net_d_b.set_grad(True)
loss_d_a, grads_d_a = grad_d_a(img_a, fake_a)
loss_d_b, grads_d_b = grad_d_b(img_b, fake_b)
loss_d = (loss_d_a + loss_d_b) * 0.5
optimizer_d_a(grads_d_a)
optimizer_d_b(grads_d_b)
return loss_d
3.小结
CycleGAN是两个镜像对称的GAN网络组成,属于无监督学习类型的模型,不需要准备完全匹配的成对样本,这大大降低了数据准备的难度,也使得模型可以应用的范围更加广泛。通俗的理解,在这个模型中,先通过构建生成网络模型,提取图像的内容和风格特征,并尝试进行风格迁移图像生成,通过定义损失函数来衡量生成图像与内容图像和风格图像的相似度。然后一个的镜像的结构,进行逆向的风格迁移,通过循环一致损失函数来评估一次循环的损失来纠正模型学习的方向。
以上是第21天的学习内容,附上今日打卡记录: