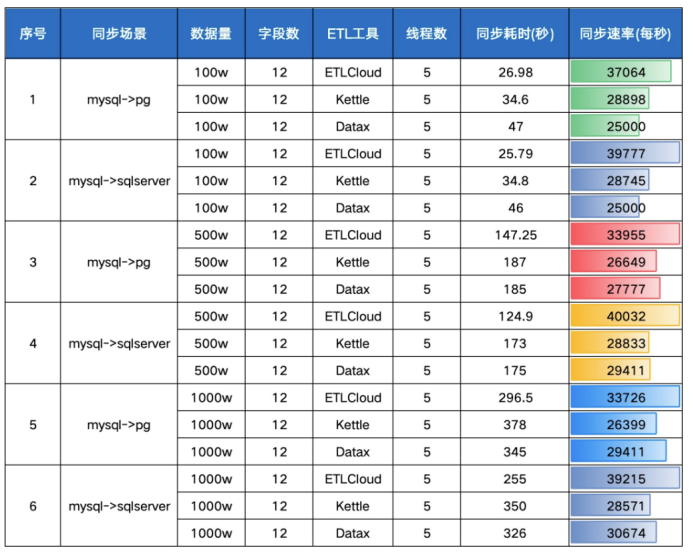
代码原理
基于GRU(Gated Recurrent Unit)的数据回归预测通常涉及多输入单输出的情况。以下是简单的原理及流程:
数据准备:
- 准备多个时间序列作为输入特征,每个时间序列可以表示不同的变量或特征。
- 准备一个目标变量作为单一的输出,通常是要预测的主要变量或结果。
模型构建:
- 使用GRU作为循环神经网络(RNN)的一种变体,用于处理时间序列数据。GRU相比传统的RNN有较好的记忆能力和防止梯度消失的特性。
- 输入层将多个时间序列数据输入到GRU模型中。
- 输出层通常是一个全连接层,将GRU的输出映射到预测的单一输出变量。
训练模型:
- 将准备好的数据集分为训练集和验证集。
- 将数据输入到GRU模型中,通过反向传播算法优化模型参数,以最小化预测输出与实际输出之间的差距(损失函数)。
- 通过调整超参数(如学习率、迭代次数等)来优化模型的训练效果。
预测:
- 使用训练好的模型对新的输入数据进行预测。新数据需要具有相同的特征维度和时间步长作为模型训练时的数据。
- GRU模型通过历史输入的信息来预测未来的单一输出变量值。
评估:
- 使用评估指标(如均方误差、平均绝对误差等)来评估模型预测的准确性和效果。
- 根据评估结果可以调整模型的结构或超参数,进一步优化预测性能。
总结来说,基于GRU的多输入单输出的数据回归预测通过处理多个时间序列输入,利用GRU模型的记忆能力和非线性特性,结合深度学习的训练和优化方法,实现对单一输出变量的预测。
部分代码
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc
%% 导入数据
data = readmatrix('回归数据集.xlsx');
data = data(:,1:14);
res=data(randperm(size(data,1)),:); %此行代码用于打乱原始样本,使训练集测试集随机被抽取,有助于更新预测结果。
num_samples = size(res,1); %样本个数
% 训练集和测试集划分
outdim = 1; % 最后一列为输出
num_size = 0.7; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
% 格式转换
for i = 1 : M
vp_train{i, 1} = p_train(:, i);
vt_train{i, 1} = t_train(:, i);
end
for i = 1 : N
vp_test{i, 1} = p_test(:, i);
vt_test{i, 1} = t_test(:, i);
end
% 创建GRU网络,
layers = [ ...
sequenceInputLayer(f_) % 输入层
gruLayer(20)
reluLayer
fullyConnectedLayer(outdim) % 回归层
regressionLayer];代码效果图
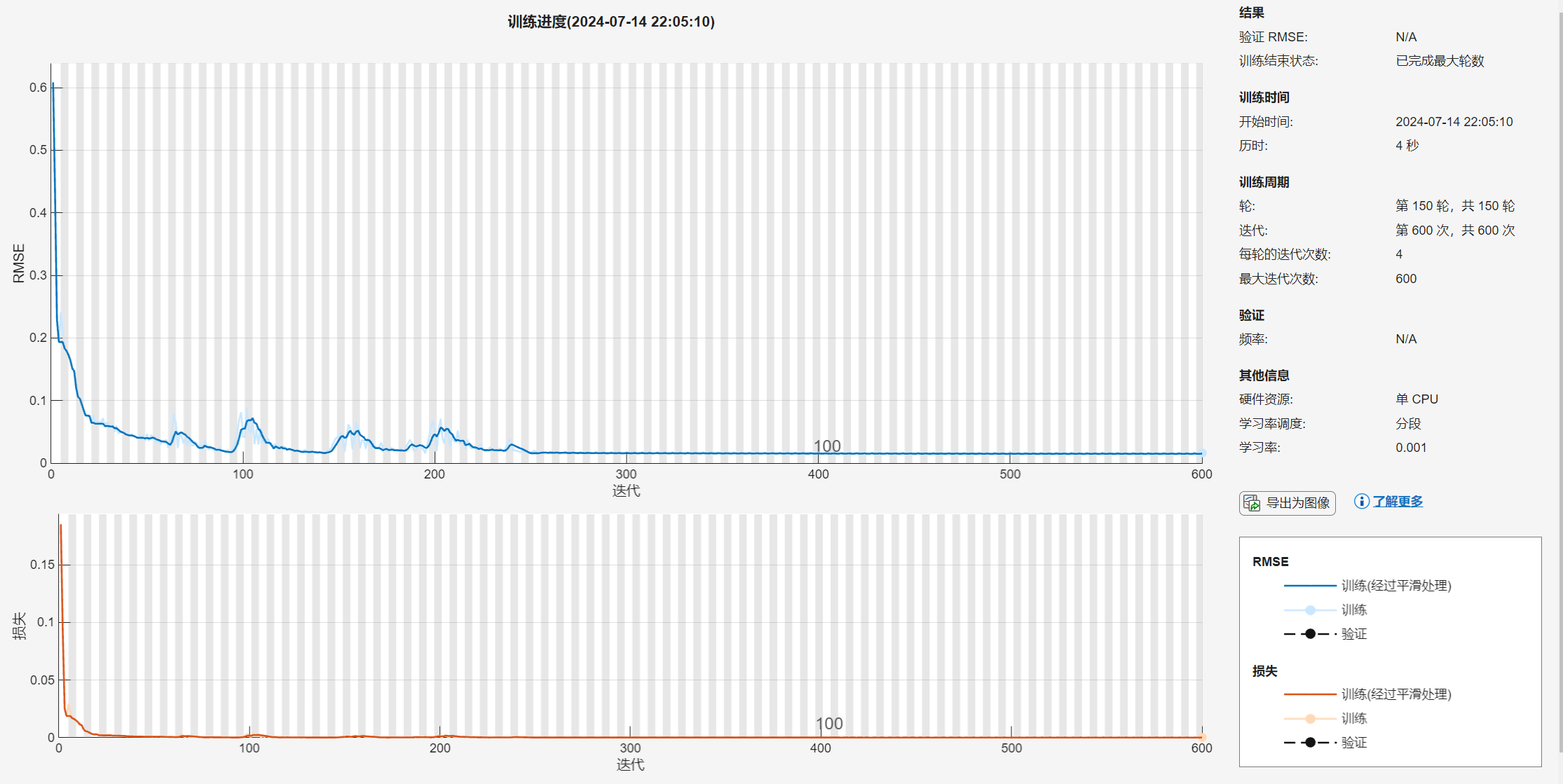
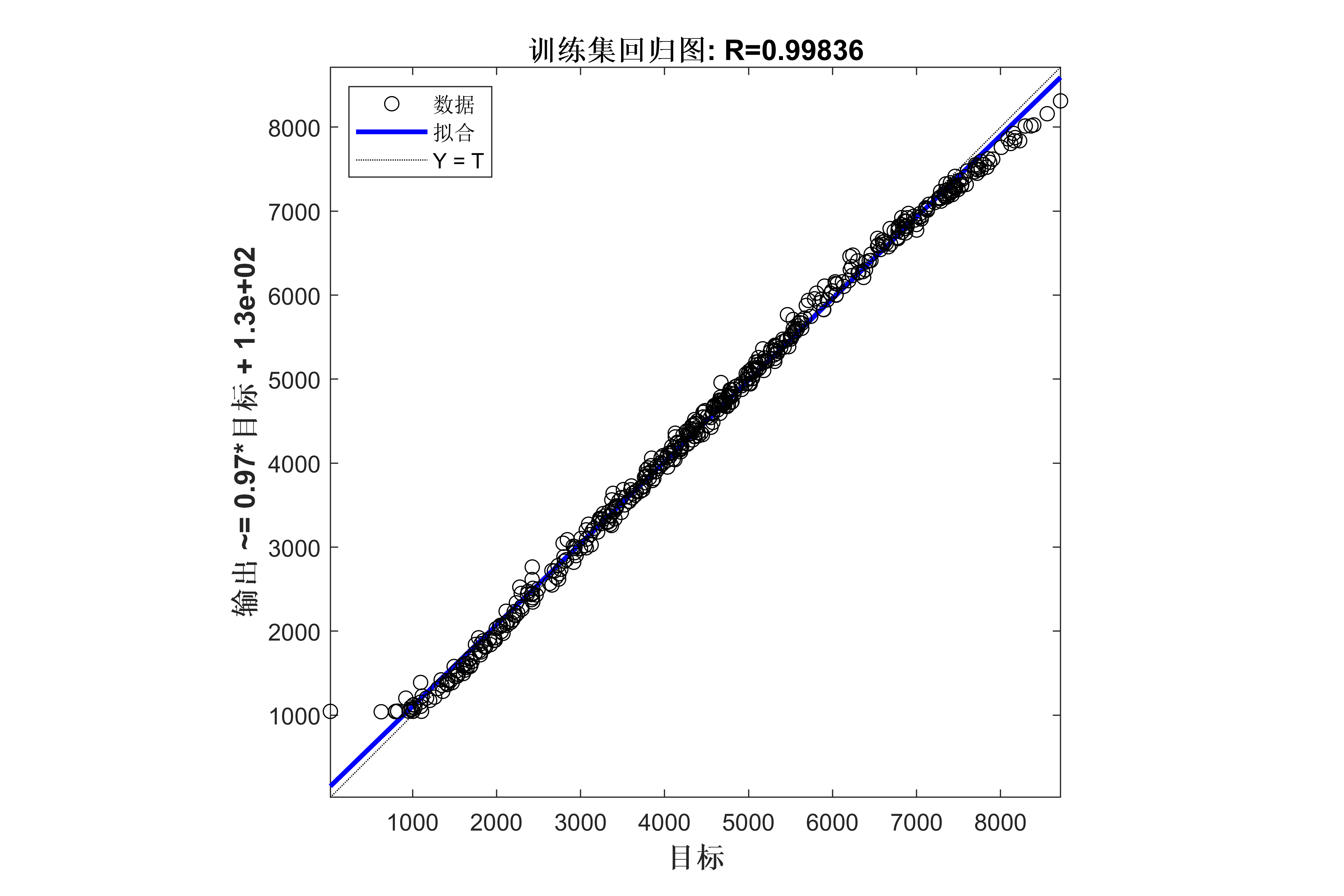
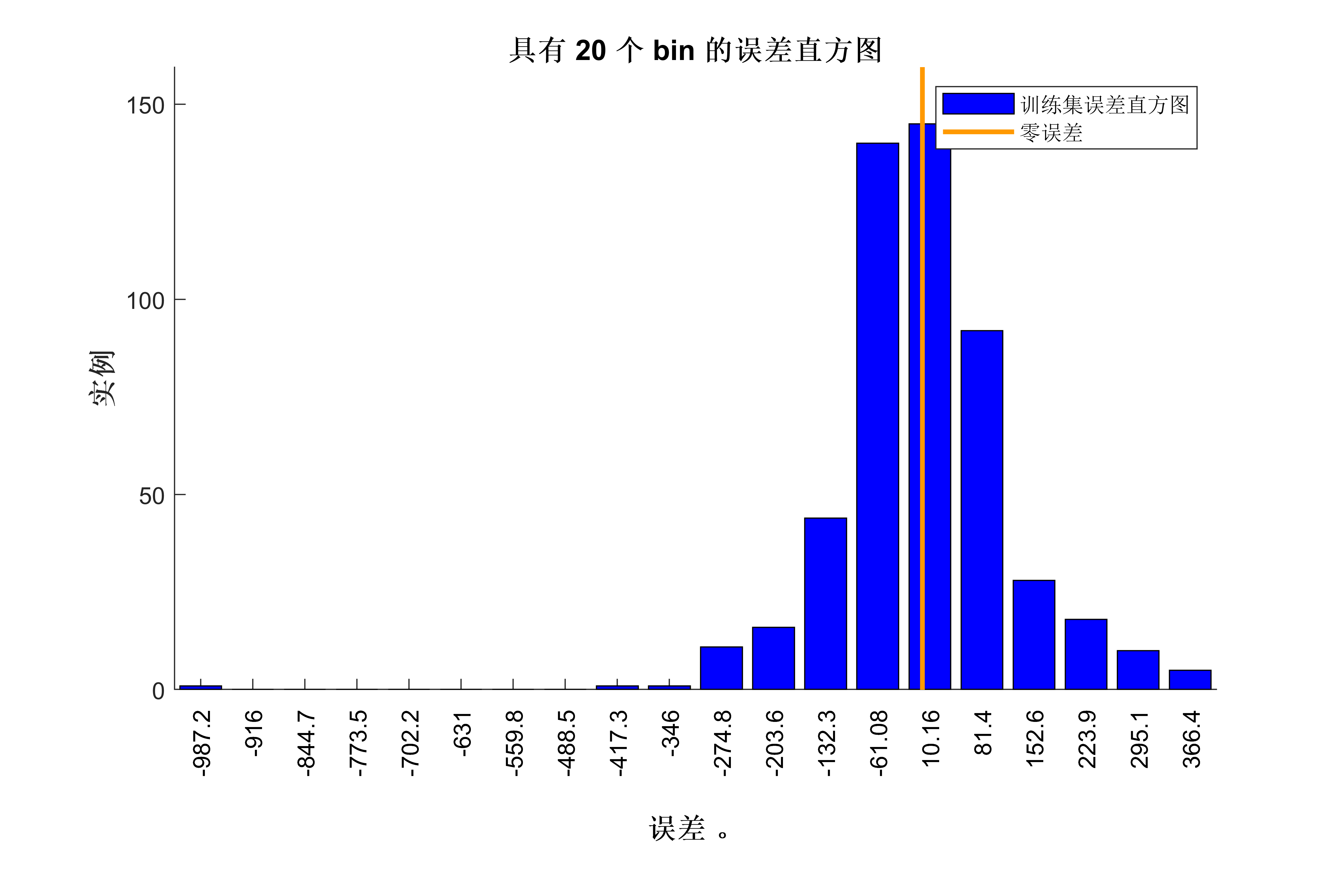
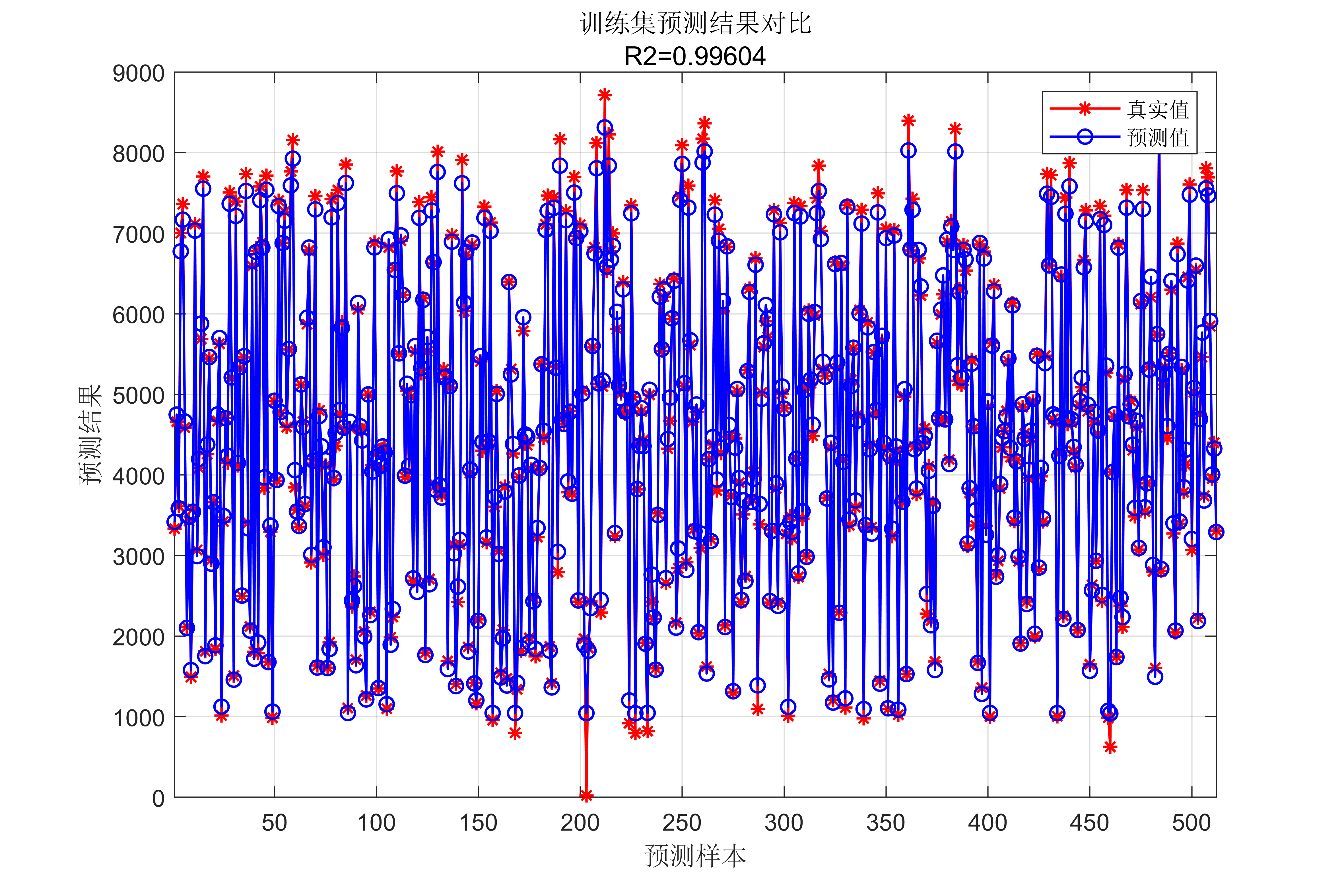
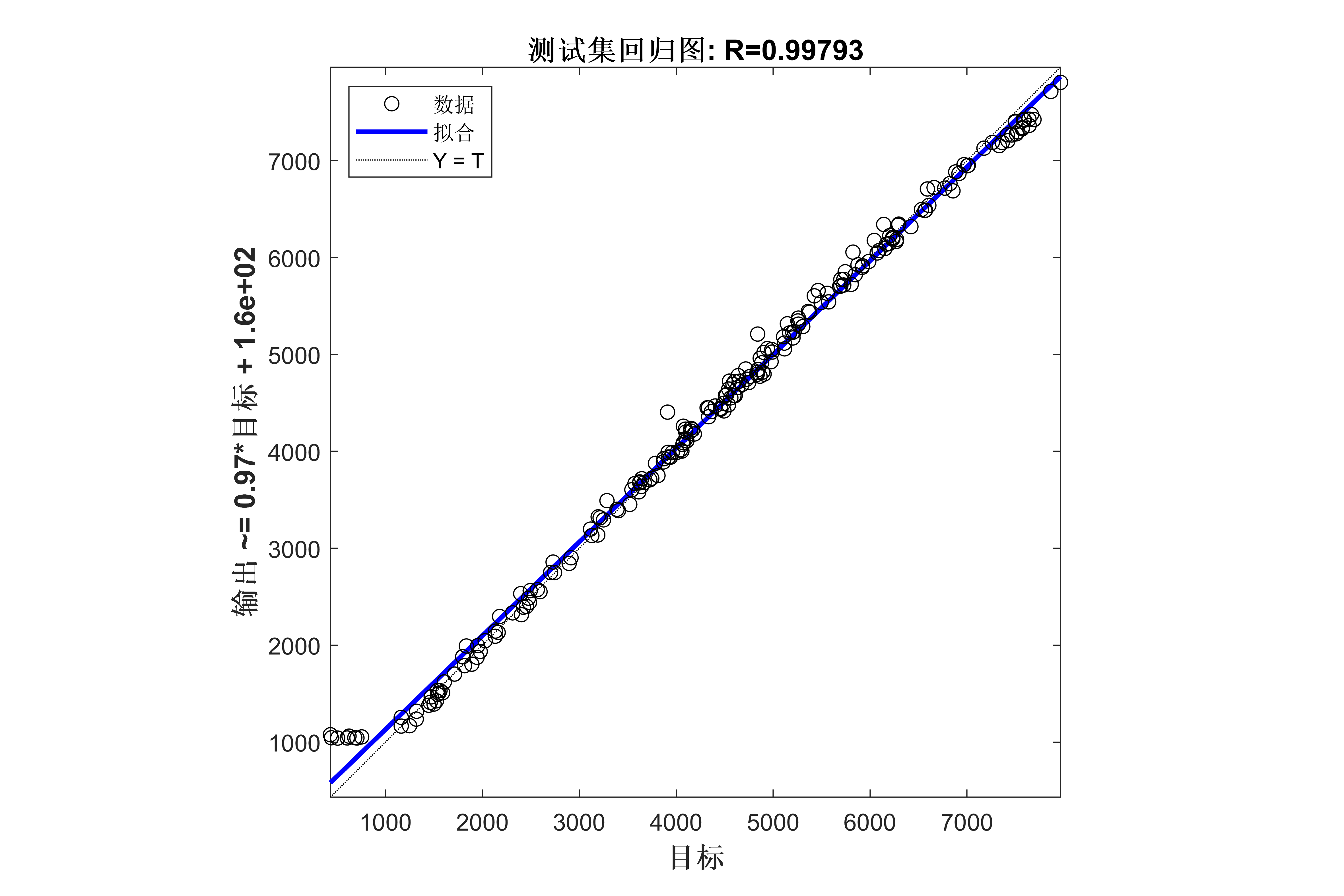
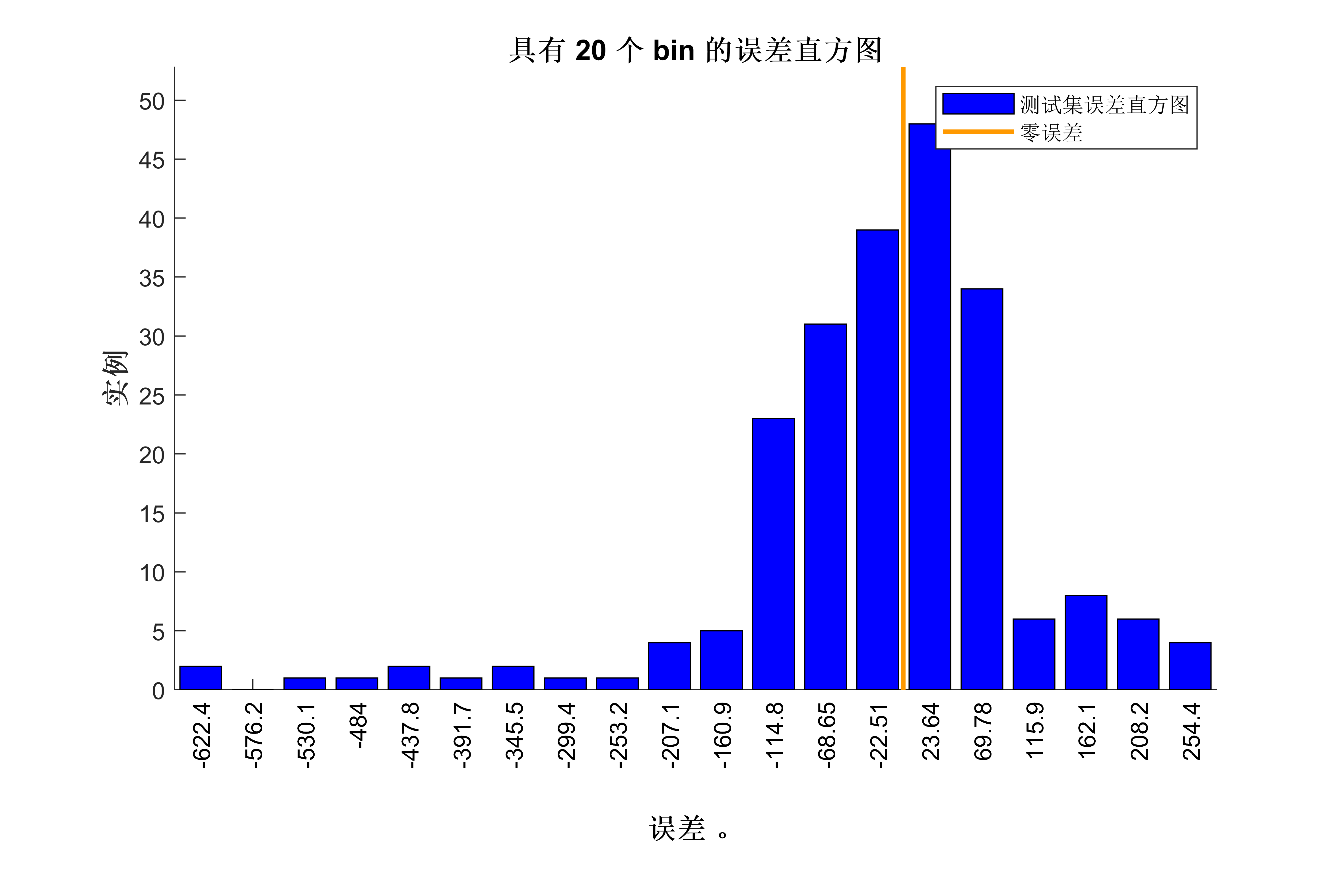
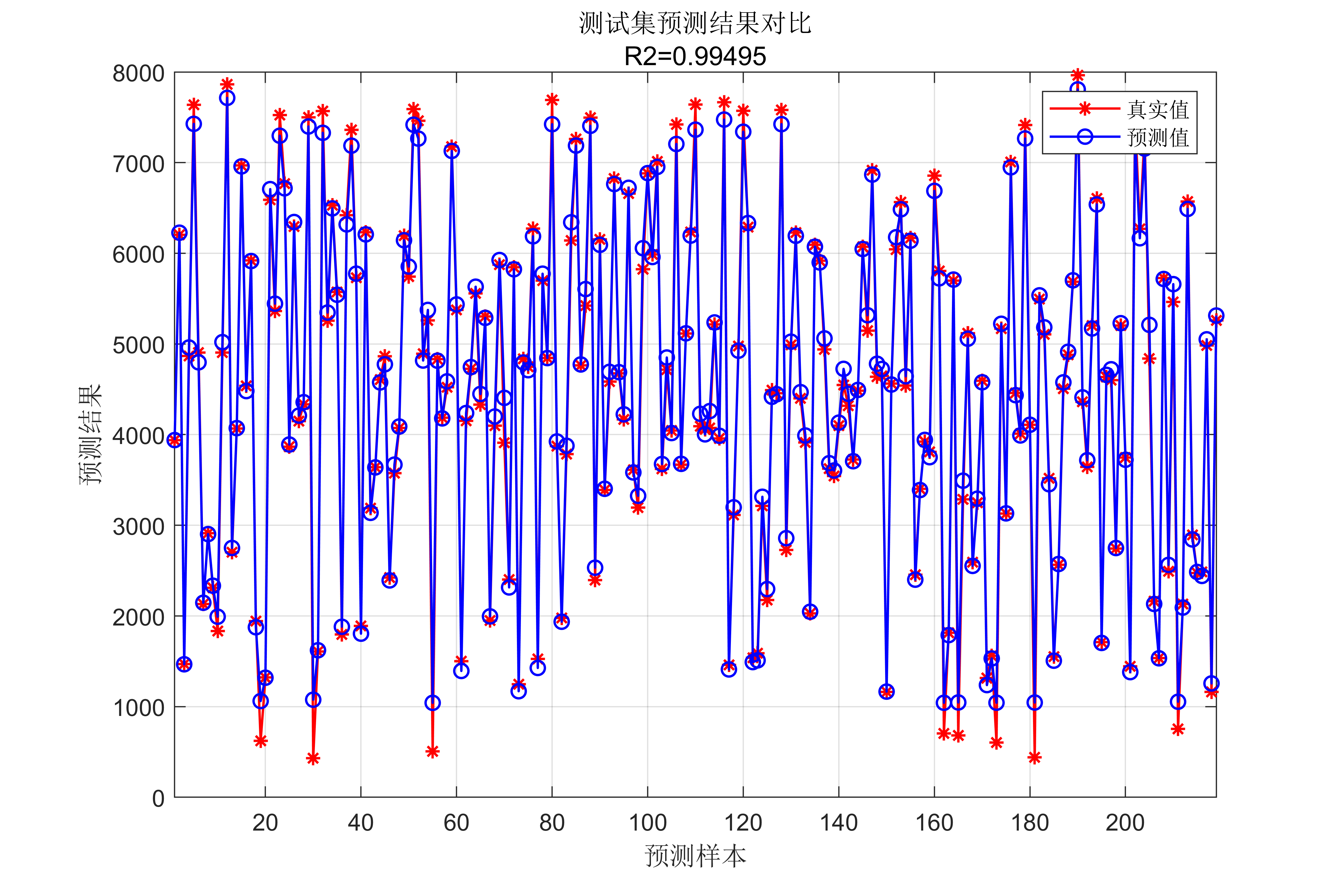
获取代码请关注MATLAB科研小白的个人公众号(即文章下方二维码),并回复回归预测本公众号致力于解决找代码难,写代码怵。各位有什么急需的代码,欢迎后台留言~不定时更新科研技巧类推文,可以一起探讨科研,写作,文献,代码等诸多学术问题,我们一起进步。





![[UTCTF2020]babymips](https://i-blog.csdnimg.cn/direct/5d2b0613fa324cde9be35190fd846330.png)