目录
PEP8 代码风格指南
知识点
介绍
愚蠢的一致性就像没脑子的妖怪
代码排版
缩进
制表符还是空格
每行最大长度
空行
源文件编码
导入包
字符串引号
表达式和语句中的空格
不能忍受的情况
其他建议
注释
块注释
行内注释
文档字符串
版本注记
命名约定
覆盖原则
规定:命名约定
规定:命名约定
公共和内部接口
程序编写建议
总结
参考文献
版权说明
迭代器、生成器、装饰器
知识点
迭代器
生成器
生成器表达式
闭包
装饰器
总结
Virtualenv
一、实验介绍
实验知识点
二、安装 virtualenv
三、用法
四、总结
测试
一、实验介绍
知识点
二、测试范围
三、单元测试
单元测试模块
阶乘计算程序
3.1 第一个测试用例
测试哪个函数
3.2 各类 assert 语句
3.3 异常测试
3.4 mounttab.py
3.5 测试覆盖率
覆盖率示例
四、总结
项目结构
一、实验介绍
知识点
二、创建 Python 项目
2.1 MANIFEST.in
2.2 安装 python-setuptools 包
2.3 setup.py
2.3.1. setup.py 用例
2.4 Python Package Index (PyPI)
三、总结
Flask 介绍
一、实验介绍
知识点
二、基本概念
什么是 Flask?
什么是模板引擎?
三、"Hello World" 应用
四、Flask 中使用参数
五、额外工作
六、总结
PEP8 代码风格指南
编程语言不是艺术,而是工作或者说是工具,所以整理并遵循一套编码规范是十分必要的。 这篇文章原文实际上来自于这里:pep-0008
知识点
- 代码排版
- 字符串引号
- 表达式和语句中的空格
- 注释
- 版本注记
- 命名约定
- 公共和内部接口
- 程序编写建议
建议在实验楼中打开 Python 解释器或者 vim 自己照着做一下,或者看看以前自己写的代码
介绍
这份文档给出的代码约定适用于主要的 Python 发行版所有标准库中的 Python 代码。请参阅相似的 PEP 信息,其用于描述实现 Python 的 C 代码规范[1]。
这份文档和 PEP 257(文档字符串约定) 改编自 Guido 的 Python 风格指南原文,从 Barry 的风格指南里添加了一些东西[2]。
随着时间的推移,这份额外约定的风格指南已经被认可了,过去的约定由于语言自身的发展被淘汰了。
许多项目有它们自己的编码风格指南。如果有冲突,优先考虑项目规定的编码指南。
愚蠢的一致性就像没脑子的妖怪
Guido 的一个主要见解是读代码多过写代码。这里提供指南的意图是强调代码可读性的重要性,并且使大多数 Python 代码保持一致性。如 PEP 20 所述,“Readability counts”。
风格指南是关于一致性的。风格一致对于本指南来说是重要的,对一个项目来说是更重要的,对于一个模块或者方法来说是最重要的。
但是最最重要的是:知道什么时候应该破例–有时候这份风格指南就是不适用。有疑问时,用你最好的判断力,对比其它的例子来确定这是不是最好的情况,并且不耻下问。
特别说明:不要为了遵守这份风格指南而破坏代码的向后兼容性。
这里有一些好的理由去忽略某个风格指南:
- 当应用风格指南的时候使代码更难读了,对于严格依循风格指南的约定去读代码的人也是不应该的。
- 为了保持和风格指南的一致性同时也打破了现有代码的一致性(可能是历史原因)–虽然这也是一个整理混乱代码的机会(现实中的 XP 风格)。
- 因为问题代码的历史比较久远,修改代码就没有必要性了。
- 当代码需要与旧版本的 Python 保持兼容,而旧版 Python 又不支持风格指南中提到的特性的时候。
代码排版
缩进
每层缩进使用 4 个空格。
续行要么与圆括号、中括号、花括号这样的被包裹元素保持垂直对齐,要么放在 Python 的隐线(注:应该是相对于 def 的内部块)内部,或者使用悬挂缩进。使用悬挂缩进的注意事项:第一行不能有参数,用进一步的缩进来把其他行区分开。
好的示例:
# Aligned with opening delimiter.
foo = long_function_name(var_one, var_two,
var_three, var_four)
# More indentation included to distinguish this from the rest.
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
# Hanging indents should add a level.
foo = long_function_name(
var_one, var_two,
var_three, var_four)
不好的示例:
# Arguments on first line forbidden when not using vertical alignment.
foo = long_function_name(var_one, var_two,
var_three, var_four)
# Further indentation required as indentation is not distinguishable.
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
空格规则是可选的:
# Hanging indents *may* be indented to other than 4 spaces.
foo = long_function_name(
var_one, var_two,
var_three, var_four)
当 if 语句的条件部分足够长,需要将它写入到多个行,值得注意的是两个连在一起的关键字(i.e. if),添加一个空格,给后续的多行条件添加一个左括号形成自然地 4 空格缩进。如果和嵌套在 if 语句内的缩进代码块产生了视觉冲突,也应该被自然缩进 4 个空格。这份增强建议书对于怎样(或是否)把条件行和 if 语句的缩进块在视觉上区分开来是没有明确规定的。可接受的情况包括,但不限于:
# No extra indentation.
if (this_is_one_thing and
that_is_another_thing):
do_something()
# Add a comment, which will provide some distinction in editors
# supporting syntax highlighting.
if (this_is_one_thing and
that_is_another_thing):
# Since both conditions are true, we can frobnicate.
do_something()
# Add some extra indentation on the conditional continuation line.
if (this_is_one_thing
and that_is_another_thing):
do_something()
在多行结构中的右圆括号、右中括号、右大括号应该放在最后一行的第一个非空白字符的正下方,如下所示:
my_list = [
1, 2, 3,
4, 5, 6,
]
result = some_function_that_takes_arguments(
'a', 'b', 'c',
'd', 'e', 'f',
)
或者放在多行结构的起始行的第一个字符正下方,如下:
my_list = [
1, 2, 3,
4, 5, 6,
]
result = some_function_that_takes_arguments(
'a', 'b', 'c',
'd', 'e', 'f',
)
制表符还是空格
空格是首选的缩进方法。
制表符(Tab)应该被用在那些以前就使用了制表符缩进的地方。
Python 3 不允许混合使用制表符和空格来缩进代码。
混合使用制表符和空格缩进的 Python 2 代码应该改为只使用空格。
当使用-t选项来调用 Python 2 的命令行解释器的时候,会对混合使用制表符和空格的代码发出警告。当使用-tt选项的时候,这些警告会变成错误。这些选项是强烈推荐的!
每行最大长度
限制每行的最大长度为 79 个字符。
对于那些约束很少的文本结构(文档字符串或注释)的长块,应该限制每行长度为 72 个字符。
限制编辑窗口的宽度使并排打开两个窗口成为可能,使用通过代码审查工具时,也能很好的通过相邻列展现不同代码版本。
一些工具的默认换行设置打乱了代码的可视结构,使其更难理解。限制编辑器窗口宽为 80 来避免自动换行,即使有些编辑工具在换行的时候会在最后一列放一个标识符。一些基于 Web 的工具可能根本就不提供动态换行。
一些团队更倾向于长的代码行。对于达成了一致意见来统一代码的团队而言,把行提升到 80~100 的长度是可接受的(实际最大长度为 99 个字符),注释和文档字符串的长度还是建议在 72 个字符内。
Python 标准库是非常专业的,限制最大代码长度为 79 个字符(注释和文档字符串最大长度为 72 个字符)。
首选的换行方式是在括号(小中大)内隐式换行(非续行符 \)。长行应该在括号表达式的包裹下换行。这比反斜杠作为续行符更好。
反斜杠有时仍然适用。例如,多个很长的 with 语句不能使用隐式续行,因此反斜杠是可接受的。
with open('/path/to/some/file/you/want/to/read') as file_1, \
open('/path/to/some/file/being/written', 'w') as file_2:
file_2.write(file_1.read())
(见前面关于 多行 if 语句 的讨论来进一步思考这种多行 with 语句该如何缩进。)
另一种使用反斜杠续行的案例是 assert 语句。
确保续行的缩进是恰到好处的。遇到二元操作符,首选的断行位置是操作符的后面而不是前面。这有一些例子:
class Rectangle(Blob):
def __init__(self, width, height,
color='black', emphasis=None, highlight=0):
if (width == 0 and height == 0 and
color == 'red' and emphasis == 'strong' or
highlight > 100):
raise ValueError("sorry, you lose")
if width == 0 and height == 0 and (color == 'red' or
emphasis is None):
raise ValueError("I don't think so -- values are %s, %s" %
(width, height))
Blob.__init__(self, width, height,
color, emphasis, highlight)
空行
顶级函数和类定义上下使用两个空行分隔。
类内的方法定义使用一个空行分隔。
可以使用额外的空行(有节制的)来分隔相关联的函数组。在一系列相关联的单行代码中空行可以省略(e.g. 一组虚拟的实现)。
在函数中使用空白行(有节制的)来表明逻辑部分。
Python 接受使用换页符(i.e. Ctrl+L)作为空格;许多工具都把 Ctrl+L 作为分页符,因此你可以用它们把你的文件中相似的章节分页。注意,一些编辑器和基于 Web 的代码查看工具可能不把 Ctrl+L 看做分页符,而是在这个位置放一个其它的符号。
源文件编码
在核心 Python 发布版中的代码应该总是使用UTF-8编码(或者在 Python 2 中使用 ASCII)。
使用 ASCII(Python 2)或 UTF-8(Python 3)的文件不需要有编码声明(注:它们是默认的)。
在标准库中,非缺省的编码应该仅仅用于测试目的,或者注释或文档字符串中的作者名包含非 ASCII 码字符;否则,优先使用 \x、\u、\U 或者 \N 来转义字符串中的非 ASCII 数据。
对于 Python 3.0 和之后的版本,以下是有关标准库的政策(见PEP 3131):所有 Python 标准库中的标识符必须使用只含 ASCII 的标识,并且只要可行,应该使用英语单词(在多数情况下,缩略语和技术术语哪个不是英语)。此外,字符串和注释也必须是 ASCII。仅有的例外是:(a)测试用例测试非 ASCII 特性时,(b)作者名。作者的名字不是基于拉丁字母的必须提供他们名字的拉丁字母音译。
面向全球用户的开源项目,鼓励采取相似的政策。
导入包
-
import不同的模块应该独立一行,如:好的:
import os
import sys
不好的:
import sys, os
这样也是可行的:
from subprocess import Popen, PIPE
-
import语句应该总是放在文件的顶部,在模块注释和文档字符串之下,在模块全局变量和常量之前。import语句分组顺序如下:- 导入标准库模块
- 导入相关第三方库模块
- 导入当前应用程序 / 库模块
每组之间应该用空行分开。
然后用
__all__声明本文件内的模块。 -
绝对导入是推荐的,它们通常是更可读的,并且在错误的包系统配置(如一个目录包含一个以
os.path结尾的包)下有良好的行为倾向(至少有更清晰的错误消息):
import mypkg.sibling
from mypkg import sibling
from mypkg.sibling import example
当然,相对于绝对导入,相对导入是个可选替代,特别是处理复杂的包结构时,绝对导入会有不必要的冗余:
from . import sibling
from .sibling import example
标准库代码应该避免复杂的包结构,并且永远使用绝对导入。
应该从不使用隐式的相对导入,而且在 Python 3 中已经被移除。
- 从一个包含类的模块导入类时,这样写通常是可行的:
from myclass import MyClass
from foo.bar.yourclass import YourClass
如果上面的方式会本地导致命名冲突,则这样写:
import myclass
import foo.bar.yourclass
以 myclass.MyClass和foo.bar.yourclass.YourClass 这样的方式使用。
-
应该避免通配符导入(
from import *),这会使名称空间里存在的名称变得不清晰,迷惑读者和自动化工具。这里有一个可辩护的通配符导入用例,,重新发布一个内部接口作为公共 API 的一部分(例如,使用纯 Python 实现一个可选的加速器模块的接口,但并不能预知这些定义会被覆盖)。当以这种方式重新发布名称时,下面关于公共和内部接口的指南仍然适用。
字符串引号
在 Python 里面,单引号字符串和双引号字符串是相同的。这份指南对这个不会有所建议。选择一种方式并坚持使用。一个字符串同时包含单引号和双引号字符时,用另外一种来包裹字符串,而不是使用反斜杠来转义,以提高可读性。
对于三引号字符串,总是使用双引号字符来保持与文档字符串约定的一致性(PEP 257)。
表达式和语句中的空格
不能忍受的情况
避免在下列情况中使用多余的空格:
- 与括号保持紧凑(小括号、中括号、大括号):
# Yes
spam(ham[1], {eggs: 2})
# No
spam( ham[ 1 ], { eggs: 2 } )
- 与后面的逗号、分号或冒号保持紧凑:
# Yes
if x == 4: print x, y; x, y = y, x
# No
if x == 4 : print x , y ; x , y = y , x
- 切片内的冒号就像二元操作符一样,任意一侧应该被等同对待(把它当做一个极低优先级的操作)。在一个可扩展的切片中,冒号两侧必须有相同的空格数量。例外:切片参数省略时,空格也省略。
好的:
ham[1:9], ham[1:9:3], ham[:9:3], ham[1::3], ham[1:9:]
ham[lower:upper], ham[lower:upper:], ham[lower::step]
ham[lower+offset : upper+offset]
ham[: upper_fn(x) : step_fn(x)], ham[:: step_fn(x)]
ham[lower + offset : upper + offset]
不好的:
ham[lower + offset:upper + offset]
ham[1: 9], ham[1 :9], ham[1:9 :3]
ham[lower : : upper]
ham[ : upper]
- 函数名与其后参数列表的左括号应该保持紧凑:
# Yes
spam(1)
#No
spam (1)
- 与切片或索引的左括号保持紧凑:
# Yes
dct['key'] = lst[index]
# No
dct ['key'] = lst [index]
-
在赋值操作符(或其它)的两侧保持多余一个的空格:
好的:
x = 1
y = 2
long_variable = 3
不好的:
x = 1
y = 2
long_variable = 3
其他建议
-
总是在这些二元操作符的两侧加入一个空格:赋值(
=),增量赋值(+=,-=,...),比较(==,<,>,!=,<>,<=,>=,in,not in,is,is not),布尔运算(and,or,not)。 -
在不同优先级之间,考虑在更低优先级的操作符两侧插入空格。用你自己的判断力;但不要使用超过一个空格,并且在二元操作符的两侧有相同的空格数。
好的:
i = i + 1
submitted += 1
x = x*2 - 1
hypot2 = x*x + y*y
c = (a+b) * (a-b)
不好的:
i=i+1
submitted +=1
x = x * 2 - 1
hypot2 = x * x + y * y
c = (a + b) * (a - b)
-
不要在关键值参数或默认值参数的等号两边加入空格。
好的:
def complex(real, imag=0.0):
return magic(r=real, i=imag)
不好的:
def complex(real, imag = 0.0):
return magic(r = real, i = imag)
-
Python 3 带注释的函数定义中的等号两侧要各插入空格。此外,在冒号后用一个单独的空格,也要在表明函数返回值类型的
->左右各插入一个空格。
好的:
def munge(input: AnyStr):
def munge(sep: AnyStr = None):
def munge() -> AnyStr:
def munge(input: AnyStr, sep: AnyStr = None, limit=1000):
不好的:
def munge(input: AnyStr=None):
def munge(input:AnyStr):
def munge(input: AnyStr)->PosInt:
- 打消使用复合语句(多条语句在同一行)的念头。
好的:
if foo == 'blah':
do_blah_thing()
do_one()
do_two()
do_three()
宁可不:
if foo == 'blah': do_blah_thing()
do_one(); do_two(); do_three()
- 有时候把
if/for/while和一个小的主体放在同一行也是可行的,千万不要在有多条语句的情况下这样做。此外,还要避免折叠,例如长行。
宁可不:
if foo == 'blah': do_blah_thing()
for x in lst: total += x
while t < 10: t = delay()
绝对不:
if foo == 'blah': do_blah_thing()
else: do_non_blah_thing()
try: something()
finally: cleanup()
do_one(); do_two(); do_three(long, argument,
list, like, this)
if foo == 'blah': one(); two(); three()注释
与代码相矛盾的注释不如没有。注释总是随着代码的变更而更新。
注释应该是完整的句子。如果注释是一个短语或语句,第一个单词应该大写,除非是一个开头是小写的标识符(从不改变标识符的大小写)。
如果注释很短,末尾的句点可以省略。块注释通常由一个或多个有完整句子的段落组成,并且每个句子应该由句点结束。
你应该在一个句子的句点后面用两个空格。
写英语时,遵循《Strunk and White》(注:《英文写作指南》,参考维基百科)。
来自非英语国家的程序员:请用英语写注释,除非你 120% 确定你的代码永远不会被那些不说你的语言的人阅读。
块注释
块注释通常用来说明跟随在其后的代码,应该与那些代码有相同的缩进层次。块注释每一行以#起头,并且#后要跟一个空格(除非是注释内的缩进文本)。
行内注释
有节制的使用行内注释。
一个行内注释与语句在同一行。行内注释应该至少与语句相隔两个空格。以#打头,#后接一个空格。
无谓的行内注释如果状态明显,会转移注意力。不要这样做:
x = x + 1 # Increment x
但有的时候,这样是有用的:
x = x + 1 # Compensate for border
文档字符串
编写良好的文档字符串(a.k.a “docstring”)的约定常驻在 PEP 257
- 为所有的公共模块、函数、类和方法编写文档字符串。对于非公共的方法,文档字符串是不必要的,但是也应该有注释来说明代码是干什么的。这个注释应该放在方法声明的下面。
- PEP 257 描述了良好的文档字符串的约定。注意,文档字符串的结尾
"""应该放在单独的一行,例如:
"""Return a foobang
Optional plotz says to frobnicate the bizbaz first.
"""
- 对于单行的文档字符串,把结尾
"""放在同一行。
版本注记
如果必须要 Subversion,CVS 或 RCS 标记在你的源文件里,像这样做:
__version__ = "$Revision$"
# $Source$
这几行应该在模块的文档字符串后面,其它代码的前面,上下由一个空行分隔。
命名约定
Python 库的命名规则有点混乱,因此我们永远也不会使其完全一致的 – 不过,这里有一些当前推荐的命名标准。新的模块和包(包括第三方框架)应该按照这些标准来命名,但是已存在库有不同的风格,内部一致性是首选。
覆盖原则
API 里对用户可见的公共部分应该遵循约定,反映的是使用而不是实现。
规定:命名约定
有许多不同的命名风格。这有助于识别正在使用的命名风格,独立于它们的用途。
下面的命名风格通常是有区别的:
- b (一个小写字母)
- B (一个大写字母)
- lowercase
- lower_case_with_underscores
- UPPERCASE
- UPPER_CASE_WITH_UNDERSCORES
- CapitalizedWords (又叫 CapWords,或者 CamelCase(骆驼命名法) – 如此命名因为字母看起来崎岖不平[3]。有时候也叫 StudlyCaps。
注意:在 CapWords 使用缩略语时,所有缩略语的首字母都要大写。因此HTTPServerError比HttpServerError要好。
- mixedCase (和上面不同的是首字母小写)
- Capitalized_Words_With_Underscores (丑陋无比!)
也有种风格用独一无二的短前缀来将相似的命名分组。在 Python 里用的不是很多,但是为了完整性被提及。例如,os.stat()函数返回一个元组,通常有像st_mode,st_size,st_mtime等名字。(强调与 POSIX 系统调用的字段结构一致,有助于程序员对此更熟悉)
X11 库的所有公共函数都用 X 打头。在 Python 中这种风格被认为是不重要的,因为属性和方法名的前缀是一个对象,函数名的前缀为一个模块名。
此外,下面的特许形式用一个前导或尾随的下划线进行识别(这些通常可以和任何形式的命名约定组合):
- _single_leading_underscore :仅内部使用的标识,如
from M import *不会导入像这样一下划线开头的对象。 - singletrailing_underscore : 通常是为了避免与 Python 规定的关键字冲突,如
Tkinter.Toplevel(master, class_='ClassName')。 - **double_leading_underscore : 命名一个类属性,调用的时候名字会改变(在类
FooBar中,**boo变成了\_FooBar\_\_boo;见下)。 - double_leading_and_trailing_underscore :”魔术”对象或属性,活在用户控制的命名空间里。例如,
__init__,__import__和__file__。永远不要像这种方式命名;只把它们作为记录。
规定:命名约定
- 应该避免的名字
永远不要使用单个字符l(小写字母 el),O(大写字母 oh),或I(大写字母 eye)作为变量名。
在一些字体中,这些字符是无法和数字1和0区分开的。试图使用l时用L代替。
- 包和模块名
模块名应该短,且全小写。如果能改善可读性,可以使用下划线。Python 的包名也应该短,全部小写,但是不推荐使用下划线。
因为模块名就是文件名,而一些文件系统是大小写不敏感的,并且自动截断长文件名,所以给模块名取一个短小的名字是非常重要的 – 在 Unix 上这不是问题,但是把代码放到老版本的 Mac, Windows,或者 DOS 上就可能变成一个问题了。
用 C/C++ 给 Python 写一个高性能的扩展(e.g. more object oriented)接口的时候,C/C++ 模块名应该有一个前导下划线。
- 类名
类名通常使用 CapWords 约定。
The naming convention for functions may be used instead in cases where the interface is documented and used primarily as a callable.
注意和内建名称的区分开:大多数内建名称是一个单独的单词(或两个单词一起),CapWords 约定只被用在异常名和内建常量上。
- 异常名
因为异常应该是类,所以类名约定在这里适用。但是,你应该用Error作为你的异常名的后缀(异常实际上是一个错误)。
- 全局变量名
(我们希望这些变量仅仅在一个模块内部使用)这个约定有关诸如此类的变量。
若被设计的模块可以通过from M import *来使用,它应该使用__all__机制来表明那些可以可导出的全局变量,或者使用下划线前缀的全局变量表明其是模块私有的。
- 函数名
函数名应该是小写的,有必要的话用下划线来分隔单词提高可读性。
混合大小写仅仅在上下文都是这种风格的情况下允许存在(如 thread.py),这是为了维持向后兼容性。
- 函数和方法参数
总是使用 self 作为实例方法的第一个参数。
总是使用 cls 作为类方法的第一个参数。
如果函数参数与保留关键字冲突,通常最好在参数后面添加一个尾随的下划线,而不是使用缩写或胡乱拆减。因此 class_ 比 clss 要好。(或许避免冲突更好的方式是使用近义词)
- 方法名和实例变量
用函数名的命名规则:全部小写,用下划线分隔单词提高可读性。
用一个且有一个前导的下划线来表明非公有的方法和实例变量。
为了避免与子类变量或方法的命名冲突,用两个前导下划线来调用 Python 的命名改编规则。
Python 命名改编通过添加一个类名:如果类 Foo 有一个属性叫 __a,它不能被这样 Foo.__a 访问(执着的人可以通过这样 Foo._Foo__a 来访问)通常,双前导的下划线应该仅仅用来避免与其子类属性的命名冲突。
注意:这里有一些争议有关 __names 的使用(见下文)。
- 常量
常量通常是模块级的定义,全部大写,单词之间以下划线分隔。例如MAX_OVERFLOW和TOTAL。
- 继承的设计
总是决定一个类的方法和变量(属性)是应该公有还是非公有。如果有疑问,选择非公有;相比把共有属性变非公有,非公有属性变公有会容易得多。
公有属性是你期望给那些与你的类无关的客户端使用的,你应该保证不会出现不向后兼容的改变。非公有的属性是你不打算给其它第三方使用的;你不需要保证非公有的属性不会改变甚至被移除也是可以的。
我们这里不适用“私有”这个术语,因为在 Python 里没有真正的私有属性(一般没有不必要的工作量)。
另一种属性的分类是“子类 API”的一部分(通常在其它语言里叫做“Protected”)。一些类被设计成被继承的,要么扩展要么修改类的某方面行为。设计这样一个类的时候,务必做出明确的决定,哪些是公有的,其将会成为子类 API 的一部分,哪些仅仅是用于你的基类的。
处于这种考虑,给出 Pythonic 的指南:
- 共有属性不应该有前导下划线。
- 如果你的公有属性与保留关键字发生冲突,在你的属性名后面添加一个尾随的下划线。这比使用缩写或胡乱拆减要好。(尽管这条规则,已知某个变量或参数可能是一个类情况下,
cls是首选的命名,特别是作为类方法的第一个参数)
注意一:见上面推荐的类方法参数命名方式。
- 对于简单的公有数据属性,最好的方式是暴露属性名,不要使用复杂的访问属性/修改属性的方法。记住,Python 提供了捷径去提升特性,如果你发现简单的数据属性需要增加功能行为。在这种情况下,使用
properties把功能实现隐藏在简单的数据属性访问语法下面。
注意一:properties仅仅在新式类下工作。 注意二:尽量保持功能行为无边际效应,然而如缓存有边际效应也是好的。 注意三:避免为计算开销大的操作使用properties;属性标记使调用者相信这样来访问(相对来说)是开销很低的。
- 如果你的类是为了被继承,你有不想让子类使用的属性,给属性命名时考虑给它们加上双前导下划线,不要加尾随下划线。这会调用 Python 的名称重整算法,把类名加在属性名前面。避免了命名冲突,当子类不小心命名了和父类属性相同名称的时候。
注意一:注意只是用了简单的类名来重整名字,因此如果子类和父类同名的时候,你仍然有能力避免冲突。
注意二:命名重整有确定的用途,例如调试和__getattr__(),就不太方便。命名重整算法是有据可查的,易于手动执行。
注意三:不是每个人都喜欢命名重整。尽量平衡名称的命名冲突与面向高级调用者的潜在用途
公共和内部接口
保证所有公有接口的向后兼容性。用户能清晰的区分公有和内部接口是重要的。
文档化的接口考虑公有,除非文档明确的说明它们是暂时的,或者内部接口不保证其的向后兼容性。所有的非文档化的应该被假设为非公开的。
为了更好的支持内省,模块应该用 __all__ 属性来明确规定公有 API 的名字。设置 __all__ 为空 list 表明模块没有公有 API。
甚至与 __all__ 设置相当,内部接口(包、模块、类、函数、属性或者其它的名字)应该有一个前导的下划线前缀。
被认为是内部的接口,其包含的任何名称空间(包、模块或类)也被认为是内部的。
导入的名称应始终视作一个实现细节。其它模块不能依赖间接访问这些导入的名字,除非它们是包含模块的 API 明确记载的一部分,例如 os.path 或一个包的 __init__ 模块暴露了来自子模块的功能。
程序编写建议
-
代码的编写方式不能对其它 Python 的实现(PyPy、Jython、IronPython、Cython、Psyco,诸如此类的)不利。
例如,不要依赖于 CPython 在字符串拼接时的优化实现,像这种语句形式
a += b和a = a + b。即使是 CPython(仅对某些类型起作用) 这种优化也是脆弱的,不是在所有的实现中都不使用引用计数。在库中性能敏感的部分,用''.join形式来代替。这会确保在所有不同的实现中字符串拼接是线性时间的。 -
比较单例,像
None应该用is或is not,从不使用==操作符。当你的真正用意是
if x is not None的时候,当心if x这样的写法 – 例如,测试一个默认值为None的变量或参数是否设置成了其它值,其它值可能是那些布尔值为 false 的类型(如空容器)。 -
用
is not操作符而不是not ... is。虽然这两个表达式是功能相同的,前一个是更可读的,是首选。好的:
if foo is not None:
不好的:
if not foo is None:
-
用富比较实现排序操作的时候,实现所有六个比较操作符(
__eq__,__ne__,__lt__,__le__,__gt__,__ge__)是更好的,而不是依赖其它仅仅运用一个特定比较的代码为了最大限度的减少工作量,
functools.total_ordering()装饰器提供了一个工具去生成缺少的比较方法。PEP 207 说明了 Python 假定的所有反射规则。因此,解释器可能交换
y > x与x < y,y >= x与x <= y,也可能交换x == y和x != y。sort()和min()操作肯定会使用<操作符,max()函数肯定会使用>操作符。当然,最好是六个操作符都实现,以便不会在其它上下文中有疑惑。 -
始终使用
def语句来代替直接绑定了一个lambda表达式的赋值语句。好的:
def f(x): return 2*x
不好的:
f = lambda x: 2*x
第一种形式意味着函数对象的 __name__ 属性值是 'f' 而不是 '<lambda>' 。通常这对异常追踪和字符串表述是更有用的。使用赋值语句消除的唯一好处,lambda 表达式可以提供一个显示的def语句不能提供的,如,lambda 能镶嵌在一个很长的表达式里。
-
异常类应派生自
Exception而不是BaseException。直接继承自BaseException是为Exception保留的,如果从BaseException继承,捕获到的错误总是错的。设计异常结构层次,应基于那些可能出现异常的代码,而不是在出现异常后的。编码的时候,以回答“出了什么问题?”为目标,而不是仅仅指出“这里出现了问题”(见 PEP 3151 一个内建异常结构层次的例子)。
类的命名约定适用于异常,如果异常类是一个错误,你应该给异常类加一个后缀
Error。用于非本地流程控制或者其他形式的信号的非错误异常不需要一个特殊的后缀。 -
适当的使用异常链。在 Python 3 里,
raise X from Y用于表明明确的替代者,不丢失原有的回溯信息。有意替换一个内部的异常时(在 Python 2 用
raise X,Python 3.3+ 用raise X from None),确保相关的细节全部转移给了新异常(例如,把KeyError变成AttributeError时保留属性名,或者把原始异常的错误信息嵌在新异常里)。 -
在 Python 2 里抛出异常时,用
raise ValueError('message')代替旧式的raise ValueError, 'message'。在 Python 3 之后的语法里,旧式的异常抛出方式是非法的。
使用括号形式的异常意味着,当你传给异常的参数过长或者包含字符串格式化时,你就不需要使用续行符了,这要感谢括号!
-
捕获异常时,尽可能使用明确的异常,而不是用一个空的
except:语句。例如,用:
try:
import platform_specific_module
except ImportError:
platform_specific_module = None
一个空的except:语句将会捕获到SystemExit和KeyboardInterrupt异常,很难区分程序的中断到底是Ctrl+C还是其他问题引起的。如果你想捕获程序的所有错误,使用except Exception:(空except:等同于except BaseException)。
一个好的经验是限制使用空except语句,除了这两种情况:
- 如果异常处理程序会打印出或者记录回溯信息;至少用户意识到错误的存在。
- 如果代码需要做一些清理工作,但后面用
raise向上抛出异常。try .. finally是处理这种情况更好的方式。
- 绑定异常给一个名字时,最好使用 Python 2.6 里添加的明确的名字绑定语法:
try:
process_data()
except Exception as exc:
raise DataProcessingFailedError(str(exc))
Python 3 只支持这种语法,避免与基于逗号的旧式语法产生二义性。
-
捕获操作系统错误时,最好使用 Python 3.3 里引进的明确的异常结构层次,而不是自省的
errno值。 -
此外,对于所有的
try/except语句来说,限制try里面有且仅有绝对必要的代码。在强调一次,这能避免屏蔽错误。
好的:
try:
value = collection[key]
except KeyError:
return key_not_found(key)
else:
return handle_value(value)
不好的:
try:
# Too broad!
return handle_value(collection[key])
except KeyError:
# Will also catch KeyError raised by handle_value()
return key_not_found(key)
-
当资源是本地的特定代码段,用
with语句确保其在使用后被立即干净的清除了,try/finally也是也接受的。 -
当它们做一些除了获取和释放资源之外的事的时候,上下文管理器应该通过单独的函数或方法调用。例如:
好的:
with conn.begin_transaction():
do_stuff_in_transaction(conn)
不好的:
with conn:
do_stuff_in_transaction(conn)
第二个例子没有提供任何信息来表明__enter__和__exit__方法在完成一个事务后做了一些除了关闭连接以外的其它事。在这种情况下明确是很重要的。
-
坚持使用
return语句。函数内的return语句都应该返回一个表达式,或者None。如果一个return语句返回一个表达式,另一个没有返回值的应该用return None清晰的说明,并且在一个函数的结尾应该明确使用一个return语句(如果有返回值的话)。好的:
def foo(x):
if x >= 0:
return math.sqrt(x)
else:
return None
def bar(x):
if x < 0:
return None
return math.sqrt(x)
不好的:
def foo(x):
if x >= 0:
return math.sqrt(x)
def bar(x):
if x < 0:
return
return math.sqrt(x)
-
用字符串方法代替字符串模块。
字符串方法总是更快,与 unicode 字符串共享 API。如果需要向后兼容性覆盖这个规则,需要 Python 2.0 以上的版本。
-
用
''.startswith()和''.endswith()代替字符串切片来检查前缀和后缀。startswith()和endswith()是更简洁的,不容易出错的。例如:
Yes: if foo.startswith('bar'):
No: if foo[:3] == 'bar':
- 对象类型的比较应该始终使用
isinstance()而不是直接比较。
Yes: if isinstance(obj, int):
No: if type(obj) is type(1):
当比较一个对象是不是字符串时,记住它有可能也是一个 unicode 字符串!在 Python 2 里面,str和unicode有一个公共的基类叫basestring,因此你可以这样做:
if isinstance(obj, basestring):
注意,在 Python 3 里面,unicode和basestring已经不存在了(只有str),byte对象不再是字符串的一种(被一个整数序列替代)。
-
对于序列(字符串、列表、元组)来说,空的序列为
False:
好的:
if not seq:
if seq:
不好的:
if len(seq):
if not len(seq):
- 不要让字符串对尾随的空格有依赖。这样的尾随空格是视觉上无法区分的,一些编辑器(or more recently, reindent.py)会将其裁剪掉。
- 不要用
==比较True和False。
Yes: if greeting:
No: if greeting == True:
Worse: if greeting is True:
-
Python 标准库将不再使用函数标注,以至于给特殊的标注风格给一个过早的承若。代替的,这些标注是留给用户去发现和体验的有用的标注风格。
建议第三方实验的标注用相关的修饰符指示标注应该如何被解释。
早期的核心开发者尝试用函数标注显示不一致、特别的标注风格。例如:
[str]是很含糊的,它可能代表一个包含字符串的列表,也可能代表一个为字符串或为空的值。open(file:(str,bytes))可能用来表示file的值可以是一个str或者bytes,也可能用来表示file的值是一个包含str和bytes的二元组。- 标注
seek(whence:int)体现了一个过于明确又不够明确的混合体:int太严格了(有__index__的应该被允许),又不够严格(只有 0,1,2 是被允许的)。同样的,标注write(b: byte)太严格了(任何支持缓存协议的都应该被允许)。 - 像
read1(n: int=None)这样的标注自我矛盾,因为None不是int。像source_path(self, fullname:str) -> object标注是迷惑人的,返回值到底是应该什么类型? - 除了上面之外,在具体类型和抽象类型的使用上是不一致的:
int对integral(整数),set/fronzenset对MutableSet/Set。 - 不正确的抽象基类标注规格。例如,集合之间的操作需要另一个对象是集合的实例,而不只是一个可迭代序列。
- 另一个问题是,标注成为了规范的一部分,但却没有经受过考验。
- 在大多数情况下,文档字符串已经包括了类型规范,比函数标注更清晰。在其余的情况下,一旦标注被移除,文档字符串应该被完善。
- 观察到的函数标注太标新立异了,相关的系统不能一致的处理自动类型检查和参数验证。离开这些标注的代码以后很难做出更改,使自动化工具可以支持。
总结
即使内容有点多,但每一个 Python 开发者都应该尽量遵守 PEP8 规范。
参考文献
[1]:PEP 7, Style Guide for C Code, van Rossum
[2]:Barry's GNU Mailman style guide http://barry.warsaw.us/software/STYLEGUIDE.txt
[3]:http://www.wikipedia.com/wiki/CamelCase
版权说明
This document has been placed in the public domain.
Source: peps: 65c5d45eab5f pep-0008.txt
迭代器、生成器、装饰器
在这个实验里我们学习迭代器、生成器、装饰器有关知识。
这几个概念是 Python 中不容易理解透彻的概念,务必把所有的实验代码都完整的输入并理解清楚其中每一行的意思。
知识点
- 迭代器
- 生成器
- 生成器表达式
- 闭包
- 装饰器
迭代器
Python 迭代器(_Iterators_)对象在遵守迭代器协议时需要支持如下两种方法。
__iter__(),返回迭代器对象自身。这用在for和in语句中。__next__(),返回迭代器的下一个值。如果没有下一个值可以返回,那么应该抛出StopIteration异常。
class Counter(object):
def __init__(self, low, high):
self.current = low
self.high = high
def __iter__(self):
return self
def __next__(self):
#返回下一个值直到当前值大于 high
if self.current > self.high:
raise StopIteration
else:
self.current += 1
return self.current - 1
现在我们能把这个迭代器用在我们的代码里。
>>> c = Counter(5,10)
>>> for i in c:
... print(i, end=' ')
...
5 6 7 8 9 10
请记住迭代器只能被使用一次。这意味着迭代器一旦抛出 StopIteration,它会持续抛出相同的异常。
>>> c = Counter(5,6)
>>> next(c)
5
>>> next(c)
6
>>> next(c)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 11, in next
StopIteration
>>> next(c)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 11, in next
StopIteration
我们已经看过在 for 循环中使用迭代器的例子了,下面的例子试图展示迭代器被隐藏的细节:
>>> iterator = iter(c)
>>> while True:
... try:
... x = iterator.__next__()
... print(x, end=' ')
... except StopIteration as e:
... break
...
5 6 7 8 9 10生成器
在这一节我们学习有关 Python 生成器(_Generators_)的知识。生成器是更简单的创建迭代器的方法,这通过在函数中使用 yield 关键字完成:
>>> def my_generator():
... print("Inside my generator")
... yield 'a'
... yield 'b'
... yield 'c'
...
>>> my_generator()
<generator object my_generator at 0x7fbcfa0a6aa0>
在上面的例子中我们使用 yield 语句创建了一个简单的生成器。我们能在 for 循环中使用它,就像我们使用任何其它迭代器一样。
>>> for char in my_generator():
... print(char)
...
Inside my generator
a
b
c
在下一个例子里,我们会使用一个生成器函数完成与 Counter 类相同的功能,并且把它用在 for 循环中。
>>> def counter_generator(low, high):
... while low <= high:
... yield low
... low += 1
...
>>> for i in counter_generator(5,10):
... print(i, end=' ')
...
5 6 7 8 9 10
在 While 循环中,每当执行到 yield 语句时,返回变量 low 的值并且生成器状态转为挂起。在下一次调用生成器时,生成器从之前冻结的地方恢复执行然后变量 low 的值增一。生成器继续 while 循环并且再次来到 yield 语句...
当你调用生成器函数时它返回一个生成器对象。如果你把这个对象传入 dir() 函数,你会在返回的结果中找到 __iter__ 和 __next__ 两个方法名。

我们通常使用生成器进行惰性求值。这样使用生成器是处理大数据的好方法。如果你不想在内存中加载所有数据,你可以使用生成器,一次只传递给你一部分数据。
os.path.walk() 函数是最典型的这样的例子,它使用一个回调函数和当前的 os.walk 生成器。使用生成器实现节约内存。
我们可以使用生成器产生无限多的值。以下是一个这样的例子。
>>> def infinite_generator(start=0):
... while True:
... yield start
... start += 1
...
>>> for num in infinite_generator(4):
... print(num, end=' ')
... if num > 20:
... break
...
4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
如果我们回到 my_generator() 这个例子,我们会发现生成器的一个特点:它们是不可重复使用的。
>>> g = my_generator()
>>> for c in g:
... print(c)
...
Inside my generator
a
b
c
>>> for c in g:
... print(c)
...
我们无法创建一个可重复使用的生成器,但可以创建一个对象,将它的 __iter__ 方法调用得到一个生成器,举例如下:
>>> class Counter(object):
... def __init__(self, low, high):
... self.low = low
... self.high = high
... def __iter__(self):
... counter = self.low
... while self.high >= counter:
... yield counter
... counter += 1
...
>>> gobj = Counter(5, 10)
>>> for num in gobj:
... print(num, end=' ')
...
5 6 7 8 9 10
>>> for num in gobj:
... print(num, end=' ')
...
5 6 7 8 9 10
上面的 gobj 并不是生成器或迭代器,因为它不具有 __next__ 方法,只是一个可迭代对象,生成器是一定不能重复循环的。而 gobj.__iter__() 是一个生成器,因为它是一个带有 yield 关键字的函数。
如果想要使类的实例变成迭代器,可以用 __iter__ + __next__ 方法实现:
>>> from collections import Iterator
>>> class Test():
...: def __init__(self, a, b):
...: self.a = a
...: self.b = b
...: def __iter__(self):
...: return self
...: def __next__(self):
...: self.a += 1
...: if self.a > self.b:
...: raise StopIteration()
...: return self.a
...:
>>> test = Test(5, 10)
>>> isinstance(test, Iterator)
True生成器表达式
在这一节我们学习生成器表达式(_Generator expressions_),生成器表达式是列表推导式和生成器的一个高性能,内存使用效率高的推广。
举个例子,我们尝试对 1 到 9 的所有数字进行平方求和。
>>> sum([x*x for x in range(1,10)])
这个例子实际上首先在内存中创建了一个平方数值的列表,然后遍历这个列表,最终求和后释放内存。你能理解一个大列表的内存占用情况是怎样的。
我们可以通过使用生成器表达式来节省内存使用。
>>> sum(x*x for x in range(1,10))
生成器表达式的语法要求其总是直接在在一对括号内,并且不能在两边有逗号。这基本上意味着下面这些例子都是有效的生成器表达式用法示例:
>>> sum(x*x for x in range(1,10))
285
>>> g = (x*x for x in range(1,10))
>>> g
<generator object <genexpr> at 0x7fc559516b90>
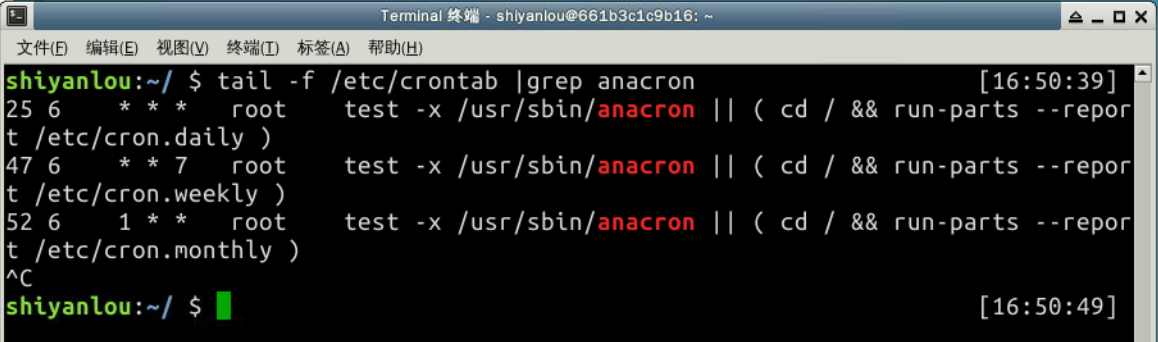
我们可以把生成器和生成器表达式联系起来,在下面的例子中我们会读取文件 '/var/log/cron' 并且查看任意指定任务(例中我们搜索 'anacron' )是否成功运行。
我们可以用 shell 命令 tail -f /etc/crontab |grep anacron 完成同样的事(按 Ctrl + C 终止命令执行)。
>>> jobtext = 'anacron'
>>> all = (line for line in open('/etc/crontab', 'r') )
>>> job = ( line for line in all if line.find(jobtext) != -1)
>>> text = next(job)
>>> text
'25 6\t* * *\troot\ttest -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )\n'
>>> text = next(job)
>>> text
'47 6\t* * 7\troot\ttest -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly )\n'
>>> text = next(job)
>>> text
'52 6\t1 * *\troot\ttest -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly )\n'
你可以写一个 for 循环遍历所有行。
闭包
闭包(_Closures_)是由另外一个函数返回的函数。我们使用闭包去除重复代码。在下面的例子中我们创建了一个简单的闭包来对数字求和。
>>> def add_number(num):
... def adder(number):
... #adder 是一个闭包
... return num + number
... return adder
...
>>> a_10 = add_number(10)
>>> a_10(21)
31
>>> a_10(34)
44
>>> a_5 = add_number(5)
>>> a_5(3)
8
adder 是一个闭包,把一个给定的数字与预定义的一个数字相加。
装饰器
装饰器(_Decorators_)用来给一些对象动态的添加一些新的行为,我们使用过的闭包也是这样的。
我们会创建一个简单的示例,将在函数执行前后打印一些语句。
>>> def my_decorator(func):
... def wrapper(*args, **kwargs):
... print("Before call")
... result = func(*args, **kwargs)
... print("After call")
... return result
... return wrapper
...
>>> @my_decorator
... def add(a, b):
... #我们的求和函数
... return a + b
...
>>> add(1, 3)
Before call
After call
4总结
知识点回顾:
- 迭代器
- 生成器
- 生成器表达式
- 闭包
- 装饰器
本实验我们学习了迭代器和生成器以及装饰器这几个高级特性的定义方法和用法,也了解了怎样使用生成器表达式和怎样定义闭包。
Virtualenv
一、实验介绍
Virtualenv 是一个创建隔离 Python 环境的工具,可以帮助你在本地目录安装不同版本 Python 模块的 Python 环境,你可以不再需要在你系统中安装所有东西就能开发并测试你的代码。
实验知识点
- virtualenv 的安装
- 创建虚拟环境
- 激活虚拟环境
- 使用多个虚拟环境
- 关闭虚拟环境
二、安装 virtualenv
首先安装 pip3,打开 xfce 终端输入下面的命令:
sudo apt-get update
sudo apt-get install python3-pip
用如下命令安装 virtualenv:
sudo pip3 install virtualenv
三、用法
我们会创建一个叫做 virtual 的目录,在里面我们会创建两个不同的虚拟环境。
cd /home/shiyanlou
mkdir virtual
下面的命令创建一个叫做 virt1 的环境。
cd virtual
virtualenv virt1

现在我们激活这个 virt1 环境。
source virt1/bin/activate

提示符的第一部分是当前虚拟环境的名字,当你有多个环境的时候它会帮助你识别你在哪个环境里面。
现在我们将安装 redis 这个 Python 模块。
pip install redis
使用 deactivate 命令关闭虚拟环境。
deactivate

现在我们将创建另一个虚拟环境 virt2,我们会在里面同样安装 redis 模块,但版本是 2.8 的旧版本。
virtualenv virt2
source virt2/bin/activate
pip install redis==2.8
这样可以为你的所有开发需求拥有许多不同的环境。
四、总结
本节知识点回顾:
- virtualenv 的安装
- 创建虚拟环境
- 激活虚拟环境
- 使用多个虚拟环境
- 关闭虚拟环境
永远记住当开发新应用时创建虚拟环境,这会帮助你的系统模块保持干净。
测试
一、实验介绍
编写测试检验应用程序所有不同的功能。每一个测试集中在一个关注点上验证结果是不是期望的。定期执行测试确保应用程序按预期的工作。当测试覆盖很大的时候,通过运行测试你就有自信确保修改点和新增点不会影响应用程序。
知识点
- 单元测试概念
- 使用 unittest 模块
- 测试用例的编写
- 异常测试
- 测试覆盖率概念
- 使用 coverage 模块
二、测试范围
如果可能的话,代码库中的所有代码都要测试。但这取决于开发者,如果写一个健壮性测试是不切实际的,你可以跳过它。就像 _Nick Coghlan_(Python 核心开发成员) 在访谈里面说的:有一个坚实可靠的测试套件,你可以做出大的改动,并确信外部可见行为保持不变。
三、单元测试
这里引用维基百科的介绍:
在计算机编程中,单元测试(英语:Unit Testing)又称为模块测试, 是针对程序模块(软件设计的最小单位)来进行正确性检验的测试工作。程序单元是应用的最小可测试部件。在过程化编程中,一个单元就是单个程序、函数、过程等;对于面向对象编程,最小单元就是方法,包括基类(超类)、抽象类、或者派生类(子类)中的方法。
单元测试模块
在 Python 里我们有 unittest 这个模块来帮助我们进行单元测试。
阶乘计算程序
在这个例子中我们将写一个计算阶乘的程序 /home/shiyanlou/factorial.py:
import sys
def fact(n):
"""
阶乘函数
:arg n: 数字
:returns: n 的阶乘
"""
if n == 0:
return 1
return n * fact(n -1)
def div(n):
"""
只是做除法
"""
res = 10 / n
return res
def main(n):
res = fact(n)
print(res)
if __name__ == '__main__':
if len(sys.argv) > 1:
main(int(sys.argv[1]))
运行程序:
$ python3 factorial.py 53.1 第一个测试用例
测试哪个函数
正如你所看到的, fact(n) 这个函数执行所有的计算,所以我们至少应该测试这个函数。
编辑 /home/shiyanlou/factorial_test.py 文件,代码如下:
import unittest
from factorial import fact
class TestFactorial(unittest.TestCase):
"""
我们的基本测试类
"""
def test_fact(self):
"""
实际测试
任何以 `test_` 开头的方法都被视作测试用例
"""
res = fact(5)
self.assertEqual(res, 120)
if __name__ == '__main__':
unittest.main()
运行测试:
$ python3 factorial_test.py
.
----------------------------------------------------------------------
Ran 1 test in 0.000s
OK
说明
我们首先导入了 unittest 模块,然后测试我们需要测试的函数。
测试用例是通过子类化 unittest.TestCase 创建的。
现在我们打开测试文件并且把 120 更改为 121,然后看看会发生什么?
3.2 各类 assert 语句
| Method | Checks that | New in |
|---|---|---|
| assertEqual(a, b) | a == b | |
| assertNotEqual(a, b) | a != b | |
| assertTrue(x) | bool(x) is True | |
| assertFalse(x) | bool(x) is False | |
| assertIs(a, b) | a is b | 2.7 |
| assertIsNot(a, b) | a is not b | 2.7 |
| assertIsNone(x) | x is None | 2.7 |
| assertIsNotNone(x) | x is not None | 2.7 |
| assertIn(a, b) | a in b | 2.7 |
| assertNotIn(a, b) | a not in b | 2.7 |
| assertIsInstance(a, b) | isinstance(a, b) | 2.7 |
| assertNotIsInstance(a, b) | not isinstance(a, b) | 2.7 |
3.3 异常测试
如果我们在 factorial.py 中调用 div(0),我们能看到异常被抛出。
我们也能测试这些异常,就像这样:
self.assertRaises(ZeroDivisionError, div, 0)
完整代码:
import unittest
from factorial import fact, div
class TestFactorial(unittest.TestCase):
"""
我们的基本测试类
"""
def test_fact(self):
"""
实际测试
任何以 `test_` 开头的方法都被视作测试用例
"""
res = fact(5)
self.assertEqual(res, 120)
def test_error(self):
"""
测试由运行时错误引发的异常
"""
self.assertRaises(ZeroDivisionError, div, 0)
if __name__ == '__main__':
unittest.main()3.4 mounttab.py
mounttab.py 中只有一个 mount_details() 函数,函数分析并打印挂载详细信息。
import os
def mount_details():
"""
打印挂载详细信息
"""
if os.path.exists('/proc/mounts'):
fd = open('/proc/mounts')
for line in fd:
line = line.strip()
words = line.split()
print('{} on {} type {}'.format(words[0],words[1],words[2]), end=' ')
if len(words) > 5:
print('({})'.format(' '.join(words[3:-2])))
else:
print()
fd.close()
if __name__ == '__main__':
mount_details()
重构 mounttab.py
现在我们在 mounttab2.py 中重构了上面的代码并且有一个我们能容易的测试的新函数 parse_mounts()。
import os
def parse_mounts():
"""
分析 /proc/mounts 并返回元组的列表
"""
result = []
if os.path.exists('/proc/mounts'):
fd = open('/proc/mounts')
for line in fd:
line = line.strip()
words = line.split()
if len(words) > 5:
res = (words[0],words[1],words[2],'({})'.format(' '.join(words[3:-2])))
else:
res = (words[0],words[1],words[2])
result.append(res)
fd.close()
return result
def mount_details():
"""
打印挂载详细信息
"""
result = parse_mounts()
for line in result:
if len(line) == 4:
print('{} on {} type {} {}'.format(*line))
else:
print('{} on {} type {}'.format(*line))
if __name__ == '__main__':
mount_details()
同样我们测试代码,编写 mounttest.py 文件:
#!/usr/bin/env python
import unittest
from mounttab2 import parse_mounts
class TestMount(unittest.TestCase):
"""
我们的基本测试类
"""
def test_parsemount(self):
"""
实际测试
任何以 `test_` 开头的方法都被视作测试用例
"""
result = parse_mounts()
self.assertIsInstance(result, list)
self.assertIsInstance(result[0], tuple)
def test_rootext4(self):
"""
测试找出根文件系统
"""
result = parse_mounts()
for line in result:
if line[1] == '/' and line[2] != 'rootfs':
self.assertEqual(line[2], 'ext4')
if __name__ == '__main__':
unittest.main()
运行程序
$ python3 mounttest.py
..
----------------------------------------------------------------------
Ran 2 tests in 0.001s
OK3.5 测试覆盖率
测试覆盖率是找到代码库未经测试的部分的简单方法。它并不会告诉你的测试好不好。
在 Python 中我们已经有了一个不错的覆盖率工具来帮助我们。你可以在实验楼环境中安装它:
$ sudo pip3 install coverage
覆盖率示例
$ coverage3 run mounttest.py
..
----------------------------------------------------------------------
Ran 2 tests in 0.013s
OK
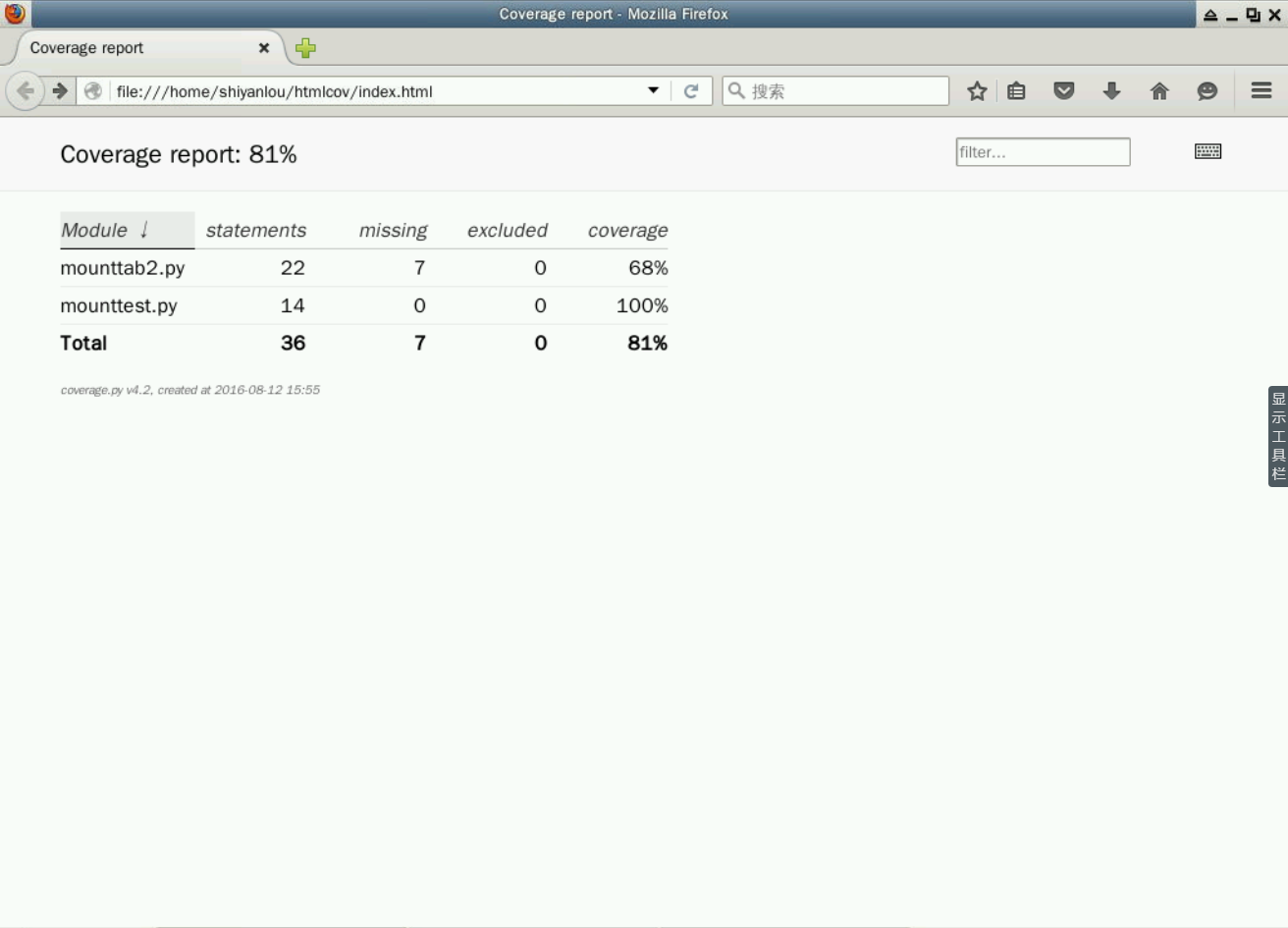
$ coverage3 report -m
Name Stmts Miss Cover Missing
--------------------------------------------
mounttab2.py 22 7 68% 16, 25-30, 34
mounttest.py 14 0 100%
--------------------------------------------
TOTAL 36 7 81%
我们还可以使用下面的命令以 HTML 文件的形式输出覆盖率结果,然后在浏览器中查看它。
$ coverage3 html
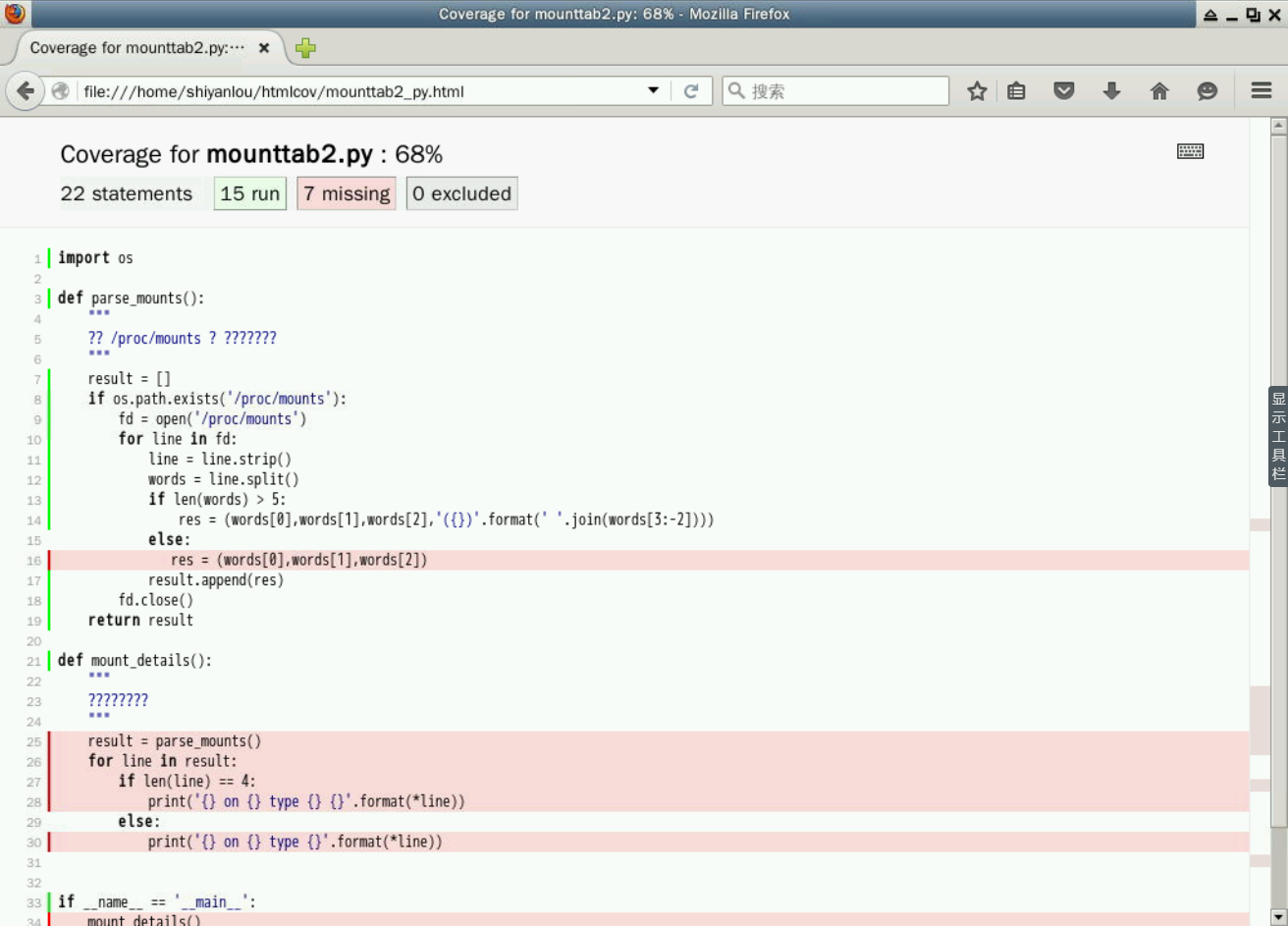
四、总结
知识点回顾:
- 单元测试概念
- 使用 unittest 模块
- 测试用例的编写
- 异常测试
- 测试覆盖率概念
- 使用 coverage 模块
本实验了解了什么是单元测试,unittest 模块怎么用,测试用例怎么写。以及最后我们使用第三方模块 coverage 进行了覆盖率测试。
在实际生产环境中,测试环节是非常重要的的一环,即便志不在测试工程师,但以后的趋势就是 DevOps,所以掌握良好的测试技能也是很有用的。
项目结构
一、实验介绍
本实验阐述了一个完整的 Python 项目结构,你可以使用什么样的目录布局以及怎样发布软件到网络上。
知识点
- 创建项目,编写
__init__文件 - 使用 setuptools 模块,编写 setup.py 和 MANIFEST.in 文件
- 创建源文件的发布版本
- 项目注册&上传到 PyPI
二、创建 Python 项目
我们的实验项目名为 _factorial_,放到 /home/shiyanlou/factorial 目录:
$ cd /home/shiyanlou
$ mkdir factorial
$ cd factorial/
我们给将要创建的 Python 模块取名为 myfact_,因此我们下一步创建 _myfact 目录。
$ mkdir myfact
$ cd myfact/
主代码将在 fact.py 文件里面。
"myfact module"
def factorial(num):
"""
返回给定数字的阶乘值
:arg num: 我们将计算其阶乘的整数值
:return: 阶乘值,若传递的参数为负数,则为 -1
"""
if num >= 0:
if num == 0:
return 1
return num * factorial(num -1)
else:
return -1
我们还有模块的 __init__.py 文件,内容如下:
from fact import factorial
__all__ = [factorial, ]
我们还在 factorial 目录下添加了一个 README.rst 文件。因此,目录结构看起来像下面这样:
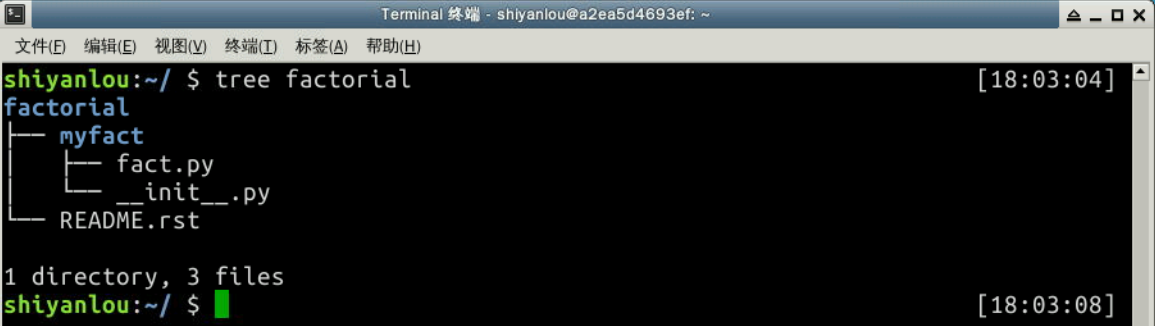
2.1 MANIFEST.in
现在我们要写一个 /home/shiyanlou/factorial/MANIFEST.in 文件,它用来在使用 sdist 命令的时候找出将成为项目源代码压缩包一部分的所有文件。
include *.py
include README.rst
如果你想要排除某些文件,你可以在这个文件中使用 exclude 语句。
2.2 安装 python-setuptools 包
我们使用 _virtualenv_(这里不示范步骤)。
$ sudo pip3 install setuptools2.3 setup.py
最终我们需要写一个 /home/shiyanlou/factorial/setup.py,用来创建源代码压缩包或安装软件。
#!/usr/bin/env python3
"""Factorial project"""
from setuptools import find_packages, setup
setup(name = 'factorial', # 注意这里的name不要使用factorial相关的名字,因为会重复,需要另外取一个不会与其他人重复的名字
version = '0.1',
description = "Factorial module.",
long_description = "A test module for our book.",
platforms = ["Linux"],
author="ShiYanLou",
author_email="support@shiyanlou.com",
url="/courses/596",
license = "MIT",
packages=find_packages()
)
name 是项目名称,version 是发布版本,description 和 long_description_ 分别是项目介绍,项目长描述。platforms 是此模块的支持平台列表。_find_packages() 是一个能在你源目录下找到所有模块的特殊函数,packaging docs。
2.3.1. setup.py 用例
要创建一个源文件发布版本,执行以下命令。
$ python3 setup.py sdist
执行完毕会返回类似下面的信息:
running sdist
running egg_info
creating factorial.egg-info
writing factorial.egg-info/PKG-INFO
writing top-level names to factorial.egg-info/top_level.txt
writing dependency_links to factorial.egg-info/dependency_links.txt
writing manifest file 'factorial.egg-info/SOURCES.txt'
reading manifest file 'factorial.egg-info/SOURCES.txt'
reading manifest template 'MANIFEST.in'
writing manifest file 'factorial.egg-info/SOURCES.txt'
running check
creating factorial-0.1
creating factorial-0.1/factorial.egg-info
creating factorial-0.1/myfact
making hard links in factorial-0.1...
hard linking MANIFEST.in -> factorial-0.1
hard linking README.rst -> factorial-0.1
hard linking setup.py -> factorial-0.1
hard linking factorial.egg-info/PKG-INFO -> factorial-0.1/factorial.egg-info
hard linking factorial.egg-info/SOURCES.txt -> factorial-0.1/factorial.egg-info
hard linking factorial.egg-info/dependency_links.txt -> factorial-0.1/factorial.egg-info
hard linking factorial.egg-info/top_level.txt -> factorial-0.1/factorial.egg-info
hard linking myfact/__init__.py -> factorial-0.1/myfact
hard linking myfact/fact.py -> factorial-0.1/myfact
Writing factorial-0.1/setup.cfg
creating dist
Creating tar archive
removing 'factorial-0.1' (and everything under it)
我们能在 dist 目录下看到一个 tar 压缩包。
$ ls dist/
factorial-0.1.tar.gz
记住尝试安装代码时使用 virtualenv。
执行下面的命令从源代码安装。
$ sudo python3 setup.py install
学习更多可前往 packaging.python.org。
2.4 Python Package Index (PyPI)
你还记得我们经常使用的 pip 命令吗?有没有想过这些包是从哪里来的?答案是 _PyPI_。这是 Python 的软件包管理系统。
为了实验,我们会使用 PyPI 的测试服务器 https://testpypi.python.org/pypi。
2.4.1 创建账号
首先在这个链接注册账号。你会收到带有链接的邮件,点击这个链接确认你的注册。
创建 ~/.pypirc 文件,存放你的账号详细信息,其内容格式如下:
[distutils]
index-servers = pypi
testpypi
[pypi]
repository: https://upload.pypi.org/legacy/
username: <username>
password: <password>
[testpypi]
repository:https://test.pypi.org/legacy/
username: <username>
password: <password>
替换 <username> 和 <password> 为您新创建的帐户的详细信息。在这里,由于我们是到 testpypi的网页上去注册账号,即将相应的服务上传到 testpypi,所以在这里,你只需修改[testpypi]的用户名和密码
记得在 setup.py 中更改项目的名称为其它的名字来测试下面的指令,在接下来的命令中我将项目名称修改为 factorial2,为了不重复,大家需要自行修改至其它名称(不要使用 factorial 和 factorial2,因为已经被使用了)。
2.4.2 上传到 TestPyPI 服务
下一步我们会将我们的项目到 TestPyPI 服务。这通过 twine 命令完成。
我们也会使用 -r 把它指向测试服务器。
$ sudo pip3 install twine
$ twine upload dist/* -r testpypi
执行完毕会返回类似下面的信息:
Uploading distributions to https://test.pypi.org/legacy/
Uploading factorial2-0.1.tar.gz
现在如果你浏览这个页面,你会发现你的项目已经准备好被别人使用了。
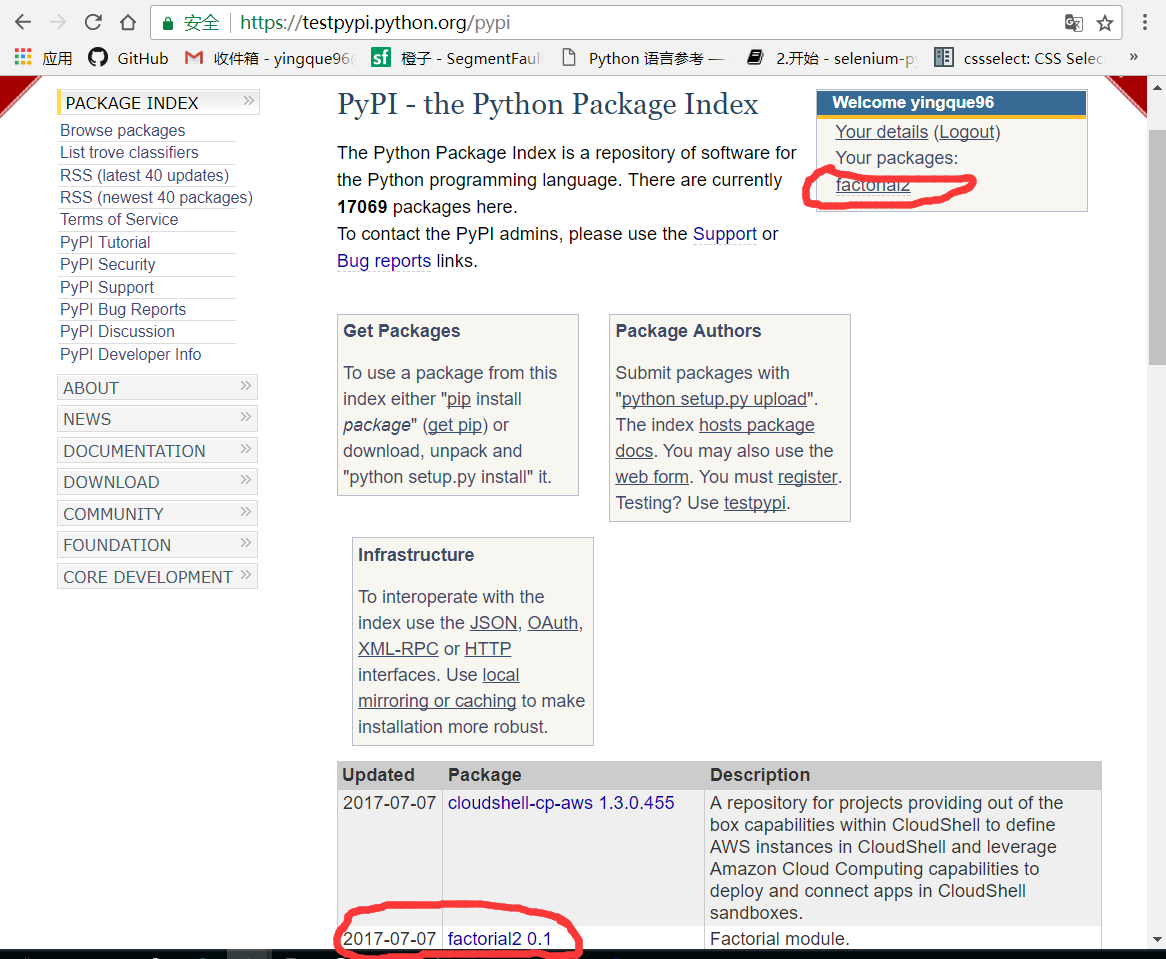
在这里你也可以使用下面的命令上传到 PyPI 服务上,但这里需要注意,在 ~/.pypirc 里面,你需要到 https://pypi.python.org页面,按照上面的步骤去注册一个账号,然后到~/.pypirc 的 [pypi] 下填写相应的用户名和密码。testpypi 和 pypi 的账号密码并不通用。
$ twine upload dist/* -r pypi三、总结
实验知识点回顾:
- 创建项目,编写
__init__文件 - 使用 setuptools 模块,编写 setup.py 和 MANIFEST.in 文件
- 创建源文件的发布版本
- 项目注册&上传到 PyPI
本实验使用了 setuptools 包,并完成了较为完整的项目创建&发布流程,最后还将项目发布到了网络 (PyPI)上。
Flask 介绍
一、实验介绍
本节实验通过一些简单的示例,学习 Flask 框架的基本使用。
知识点
- 微框架、WSGI、模板引擎概念
- 使用 Flask 做 web 应用
- 模板的使用
- 根据 URL 返回特定网页
二、基本概念
什么是 Flask?
Flask 是一个 web 框架。也就是说 Flask 为你提供工具,库和技术来允许你构建一个 web 应用程序。这个 web 应用程序可以是一些 web 页面、博客、wiki、基于 web 的日历应用或商业网站。
Flask 属于微框架(_micro-framework_)这一类别,微架构通常是很小的不依赖于外部库的框架。这既有优点也有缺点,优点是框架很轻量,更新时依赖少,并且专注安全方面的 bug,缺点是,你不得不自己做更多的工作,或通过添加插件增加自己的依赖列表。Flask 的依赖如下:
- Werkzeug 一个 WSGI 工具包
- jinja2 模板引擎
维基百科 WSGI 的介绍:
Web 服务器网关接口(Python Web Server Gateway Interface,缩写为 WSGI)是为Python语言定义的Web 服务器和Web 应用程序或框架之间的一种简单而通用的接口。自从 WSGI 被开发出来以后,许多其它语言中也出现了类似接口。
什么是模板引擎?
你搭建过一个网站吗?你面对过保持网站风格一致的问题吗,你不得不写多次相同的文本吗?你有没有试图改变这种网站的风格?
如果你的网站只包含几个网页,改变网站风格会花费你一些时间,这确实可行。尽管如此,如果你有许多页面(比如在你商店里的售卖物品列表),这个任务便很艰巨。
使用模板你可以设置你的页面的基本布局,并提及哪个元素将发生变化。这种方式可以定义您的网页头部并在您的网站的所有页面使它保持一致,如果你需要改变网页头部,你只需要更新一个地方。
使用模板引擎创建/更新/维护你的应用会节约你很多时间。
三、"Hello World" 应用
我们将使用 flask 完成一个非常基础的应用。
- 安装 flask
$ sudo pip3 install flask
- 创建项目结构
$ cd /home/shiyanlou
$ mkdir -p hello_flask/{templates,static}
这是你的 web 应用的基本结构:
$ tree hello_flask/
hello_flask
|-- static
`-- templates
2 directories, 0 files
templates 文件夹是存放模板的地方,static 文件夹存放 web 应用所需的静态文件(images, css, javascript)。
- 创建应用文件
$ cd hello_flask
$ vim hello_flask.py
hello_flask.py 文件里编写如下代码:
#!/usr/bin/env python3
import flask
# Create the application.
APP = flask.Flask(__name__)
@APP.route('/')
def index():
""" 显示可在 '/' 访问的 index 页面
"""
return flask.render_template('index.html')
if __name__ == '__main__':
APP.debug=True
APP.run()
- 创建模板文件
index.html
$ vim templates/index.html
index.html 文件内容如下:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Hello world!</title>
<link
type="text/css"
rel="stylesheet"
href="{{ url_for('static',
filename='hello.css')}}"
/>
</head>
<body>
It works!
</body>
</html>
- 运行 flask 应用程序
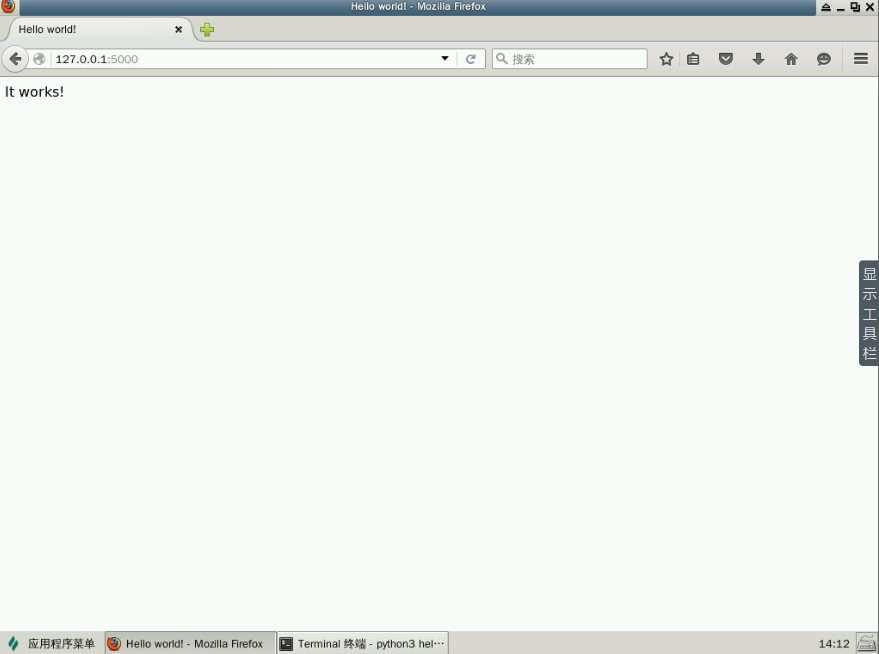
$ python3 hello_flask.py
访问 http://127.0.0.1:5000/,这应该只是显示黑字白底的 "It works!" 文本,如下图:
四、Flask 中使用参数
在本节中我们将要看到如何根据用户使用的 URL 返回网页。
为此我们更新 hello_flask.py 文件。
- 在 hello_flask.py 文件中添加以下条目
@APP.route('/hello/<name>/')
def hello(name):
""" Displays the page greats who ever comes to visit it.
"""
return flask.render_template('hello.html', name=name)
- 创建下面这个模板 hello.html
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Hello</title>
<link
type="text/css"
rel="stylesheet"
href="{{ url_for('static',
filename='hello.css')}}"
/>
</head>
<body>
Hello {{name}}
</body>
</html>
- 运行 flask 应用
$ python3 hello_flask.py
访问 http://127.0.0.1:5000/ ,这应该只是显示黑字白底的 "It works!" 文本。
访问http://127.0.0.1:5000/hello/you,这应该返回文本 "Hello you",见下图:
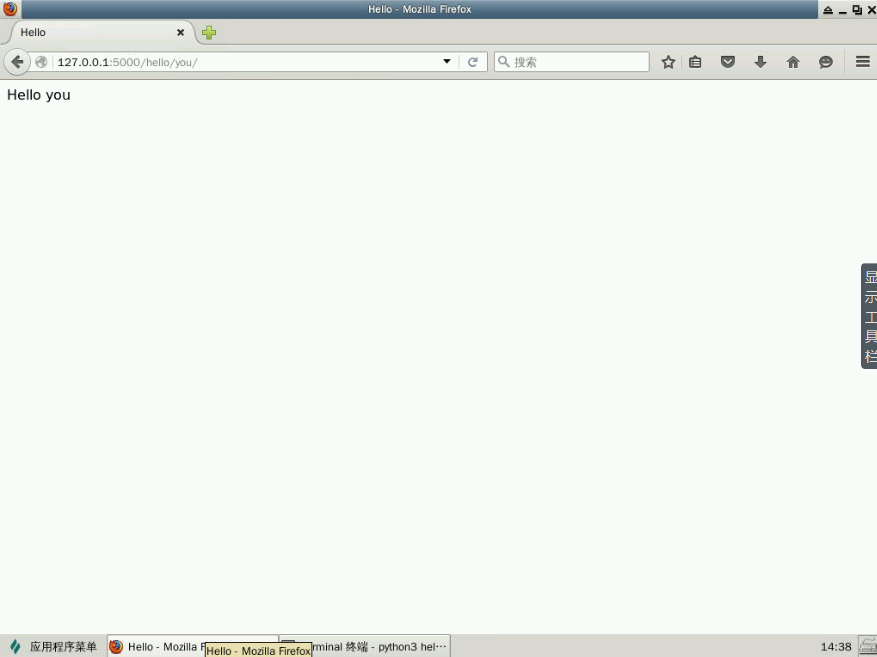
无论你在 URL 中 /hello/ 后填写的什么,都会出现在返回的网页中。
这是你第一次使用模板,我们在 hello_flask.py 中建立了 name 变量(参见 hello 函数的 return 行)。通过语法 {{name}},name 变量之后在页面中显示其自身。
五、额外工作
目前,对于每一个页面我们都创建了一个模板,其实这是不好的做法,我们应该做的是创建一个主模板并且在每个页面使用它。
- 创建模板文件 master.html。
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>{% block title %}{% endblock %} - Hello Flask!</title>
<link
type="text/css"
rel="stylesheet"
href="{{ url_for('static',
filename='hello.css')}}"
/>
</head>
<body>
{% block body %}{% endblock %}
</body>
</html>
- 调整模板 index.html。
{% extends "master.html" %} {% block title %}Home{% endblock %} {% block body %}
It works! {% endblock %}
正如你所看到的,在 master.html 模板中我们定义了两部分,名为 title 和 body 的 blocks。
在模板 index.html 中,我们声明这个模板扩展自 master.html 模板,然后我们定义了内容来放在这两个部分中(blocks)。在第一个 block title 中,我们放置了 Home 单词,在第二个 block body 中我们定义了我们想要在页面的 body 中有的东西。
- 作为练习,更改其他模板 hello.html,同样要使用 master.html。
- 在 hello 页面添加首页链接。
调整模板 hello.html,添加到首页的链接。
<a href="{{ url_for('index') }}"><button>Home</button></a>
- 作为你的任务,在首页添加到 hello 页面的链接。
六、总结
实验知识点回顾:
- 微框架、WSGI、模板引擎概念
- 使用 Flask 做 web 应用
- 模板的使用
- 根据 URL 返回特定网页
本实验中我们了解了微框架、WSGI、模板引擎等概念,学习使用 Flask 做一个 web 应用,在这个 web 应用中,我们使用了模板。而用户以正确的不同 URL 访问服务器时,服务器返回不同的网页。最后还给大家留了一个小任务,希望大家能完成。
当然,在学习过程中有任何不懂的地方或者对 Flsak 非常感兴趣,推荐学习 Flask官方文档。