目录
介绍一下mysql 的日志
redo log 和binlog 的区别及应用场景
redo log 和 binlog 在恢复数据库有什么区别?
redo log 是怎么实现持久化的?
redo log除了崩溃恢复还有什么其他作用? (顺序写)
redo log 怎么刷入磁盘的知道吗?
两阶段提交的过程
为什么需要两阶段提交?(两个状态保证逻辑上的一致) 先备份 再恢复(老数据) 先恢复再备份(备份数据不是最新)
SQL 优化
怎样查看一条语句是否走了索引?
explain的结果有哪些?有哪些信息去告诉你怎么优化?
慢 SQL
如何定位呢?
慢sql日志怎么开启?
有哪些方式优化 SQL?
如何优化慢 SQL? (优化数据查询、拆分查询、联合索引进行覆盖查询、避免索引失效、对排序进行优化(相应字段建立索引))
深分页场景如何优化?
如果 SQL 和索引都没问题,查询还是很慢怎么办?
介绍一下mysql 的日志
- undo log(回滚日志):是 Innodb 存储引擎层生成的日志,实现了事务中的原子性,主要用于事务回滚和 MVCC。
- redo log(重做日志):是 Innodb 存储引擎层生成的日志,实现了事务中的持久性,主要用于掉电等故障恢复;
- binlog (归档日志):是 Server 层生成的日志,主要用于数据备份和主从复制;
- 慢查询日志(Slow Query Log):记录执行时间超过 long_query_time 值的所有 SQL 语句。这个时间值是可配置的,默认情况下,慢查询日志功能是关闭的。可以用来识别和优化慢 SQL。
----------------------------------------------------------------------------------------
错误日志(Error Log):记录 MySQL 服务器启动、运行或停止时出现的问题。
一般查询日志(General Query Log):记录所有 MySQL 服务器的连接信息及所有的 SQL 语句,不论这些语句是否修改了数据。
redo log 和binlog 的区别及应用场景
- redo log 是 InnoDB 引擎实现的日志,属于物理日志,记录了 Innodb 引擎对数据页所做的修改操作,主要用于崩溃恢复,比如某个事务提交了,脏页数据还没有刷盘,如果 MySQL机器断电了,脏页的数据就丢失了,MySQL重启后可以通过重做日志,可以将已提交事务的数据恢复回来
- binlog 是 server 层实现的日志,对所有存储引擎都可用,保存了所有对数据库的增删改操作,以及每个语句的执行时间,主要用于数据库备份和归档,也用于主从复制。
binlog 有三种日志格式,日志的内容可能是 SQL 语句、数据本身或两者的混合+
redo log 和 binlog 在恢复数据库有什么区别?
redo log 是固定大小的,通常配置为一组文件,使用环形方式写入,旧的日志会在空间需要时被覆盖。
binlog 是追加写入的,新的事件总是被添加到当前日志文件的末尾,当文件达到一定大小后,会创建新的 binlog 文件继续记录。
redo log 是怎么实现持久化的?
Redolog是MySQL中用于保证持久性的重要机制之一。它通过以下方式来保证持久性:
- Write-ahead logging(WAL):在事务提交之前,将事务所做的修改操作记录到redo log中,然后再将脏页中数据写入磁盘。这样即使在数据写入磁盘之前发生了宕机,系统可以通过redo log中的记录来恢复数据。
- Redo log的顺序写入:redo log采用追加写入的方式,将redo日志记录追加到文件末尾,而不是随机写入。这样可以减少磁盘的随机I/O操作,提高写入性能。
- Checkpoint机制:MySQL会定期将内存中的数据刷新到磁盘,同时将最新的LSN(Log Sequence Number)记录到磁盘中,这个LSN可以确保redo log中的操作是按顺序执行的。在恢复数据时,系统会根据LSN来确定从哪个位置开始应用redo log。(环形写入)
redo log除了崩溃恢复还有什么其他作用? (顺序写)
Redolog 日志是追加的形式,所以redolog 写磁盘是一个顺序写的过程,而数据页写磁盘是一个随机写的过程,顺序写的性能是比随机写性能高的,事务在提交的时候,是先写日志再写数据的机制,相当于把 MySQL写入磁盘的操作从磁盘随机写成了顺序写,所以 redo Log 还可以起到提升 MySQL写入磁盘性能的作用。
redo log 怎么刷入磁盘的知道吗?
redo log 的写入不是直接落到磁盘,而是在内存中设置了一片称之为redo log buffer的连续内存空间,也就是redo 日志缓冲区。 16mb
- log buffer 空间不足时
如果当前写入 log buffer 的 redo 日志量已经占满了 log buffer 总容量的大约一半左右,就需要把这些日志刷新到磁盘
- 事务提交时
在事务提交时,为了保证持久性,会把 log buffer 中的日志全部刷到磁盘。注意,这时候,除了本事务的,可能还会刷入其它事务的日志。
- 后台线程输入
有一个后台线程,大约每秒都会刷新一次log buffer中的redo log到磁盘。
- 正常关闭服务器时
- 触发 checkpoint 规则 :环形写入 写入方式是从头到尾开始写,写到末尾又回到开头循环写

其中有两个标记位置:
write pos是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到磁盘。

当write_pos追上checkpoint时,表示 redo log 日志已经写满。这时候就不能接着往里写数据了,需要执行checkpoint规则腾出可写空间。
所谓的checkpoint 规则,就是 checkpoint 触发后,将 buffer 中日志页都刷到磁盘。
两阶段提交的过程
两阶段提交把事务的提交拆分成了 2 个阶段,分别是准备阶段和提交阶段
- 准备阶段会将 redo log 状态设置为 prepare 状态,然后将 redo log 刷入磁盘;
- 提交阶段会将 binlog 刷入磁盘,然后设置 redo log 设置为 commit 状态,
到这里两阶段就已经完成了
在两阶段提交中,是以 binlog 刷入磁盘时机作为事务提交成功的标志的:
- 如果 binlog 还没刷入磁盘的时候,MySQL就发生了崩溃,MySQL重启的时候就需要回滚事务;
- 如果 binlog 刷入磁盘,即使 redo log 没有设置 commit 状态,MySQL就发生了崩溃,MySqL重启的时候就会提交事务。
为什么需要两阶段提交?(两个状态保证逻辑上的一致) 先备份 再恢复(老数据) 先恢复再备份(备份数据不是最新)
两阶段提交是为了保证 redo log 和 binlog 逻辑一致,从而保证主从复制的时候不会出现数据不一致的问题。
事务提交后,redo log 和 binlog 都要持久化到磁盘,但是这两个是独立的逻辑,可能出现半成功的状态,比如在主从复制的场景下,如果在将 redo log 刷入到磁盘之后,MySQL突然宕机了,而 binlog 还没有来得及写入磁盘,这时候主库是最新的数据,而从库是旧数据,这样就造成两份日志之间的逻辑不一致。
SQL 优化
怎样查看一条语句是否走了索引?
可以通过 explain 查看 SQL 的执行计划,关注 type 字段,这个字段表明 SQL 扫描的方式
如果 type字段不是 all 或者 index(全索引扫描) 就代表是索引扫描的方式,这种情况就代表 SQL 走了索引,并且我们还可以通过 key 字段,看这条查询用了哪个索引字段来走索引,如果 key 为 null,也代表没有走索引。
explain的结果有哪些?有哪些信息去告诉你怎么优化?
explain 是 MySQL 提供的一个用于查看查询执行计划的工具,可以帮助我们分析查询语句的性能瓶颈,找出慢 SQL 的原因。


对于执行计划,参数有:
- possible_keys 字段表示可能用到的索引;
- key 字段表示实际用的索引,如果这一项为 NULL,说明没有使用索引;
- key_len 表示索引的长度;
- rows 表示扫描的数据行数。
- type 表示数据扫描类型,表示 MySQL 在表中找到所需行的方式,性能从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL。
type 字段就是描述了找到所需数据时使用的扫描方式是什么,常见扫描类型的执行效率从低到高的顺序为:
- All(全表扫描);all 是最坏的情况,因为采用了全表扫描的方式。
- index(全索引扫描);index 和 all 差不多,只不过 index 对索引表进行全扫描,这样做的好处是不再需要对数据进行排序,但是开销依然很大。所以,要尽量避免全表扫描和全索引扫描。
- range(索引范围扫描):range 表示采用了索引范围扫描,一般在 where 子句中使用 < 、>、in、between 等关键词,只检索给定范围的行,属于范围查找。
从这一级别开始,索引的作用会越来越明显,因此我们需要尽量让 SQL 查询可以使用到 range 这一级别及以上的 type 访问方式。
- ref(非唯一索引扫描):ref 类型表示采用了非唯一索引,或者是唯一索引的非唯一性前缀,返回数据返回可能是多条。因为虽然使用了索引,但该索引列的值并不唯一,有重复。这样即使使用索引快速查找到了第一条数据,仍然不能停止,要进行目标值附近的小范围扫描。但它的好处是它并不需要扫全表,因为索引是有序的,即便有重复值,也是在一个非常小的范围内扫描。
- eq_ref(唯一索引扫描):eq_ref 类型是使用主键或唯一索引时产生的访问方式,通常使用在多表联查中。比如,对两张表进行联查,关联条件是两张表的 user_id 相等,且 user_id 是唯一索引,那么使用 EXPLAIN 进行执行计划查看的时候,type 就会显示 eq_ref。
- const(结果只有一条的主键或唯一索引扫描):const 类型表示使用了主键或者唯一索引与常量值进行比较,比如 select name from product where id=1。
除了关注 type,我们也要关注 extra 显示的结果。
这里说几个重要的参考指标:
- Using filesort :当查询语句中包含 group by 操作,而且无法利用索引完成排序操作的时候, 这时不得不选择相应的排序算法进行,甚至可能会通过文件排序,效率是很低的,所以要避免这种问题的出现。
- Using temporary:使用临时表保存中间结果,MySQL 在对查询结果排序时使用临时表,常见于排序 order by 和分组查询 group by。效率低,要避免这种问题的出现。
- Using index:所需数据只需在索引即可全部获得,不须要再到表中取数据,也就是使用了覆盖索引,避免了回表操作,效率不错。
- using where 表示MySQL的存储引擎返回给 server 层的数据并不一定满足 where 子句的条件,所以MySQL从存储引擎拿到的数据,还得在 server 层进行了where 子句的条件判断,来过滤出最终 sql 所需要查询的数据
慢 SQL
如何定位呢?
定位慢 SQL 主要通过两种手段:
- 慢查询日志:开启 MySQL 慢查询日志,再通过一些工具比如 mysqldumpslow 去分析对应的慢查询日志,找出问题的根源。
- 服务监控:可以在业务的基建中加入对慢 SQL 的监控,常见的方案有字节码插桩、连接池扩展、ORM 框架过程,对服务运行中的慢 SQL 进行监控和告警。
show variables like '%slow_query_log';
show variables like 'long_query_time' 默认是10s
show processlist;
查看当前正在执行的 SQL 语句,找出执行时间较长的 SQL。可以开启慢查询日志,MySQL就会自动将执行比较慢的 SQL 语句记录在慢查询日志中(默认是10s),具体多慢我们可以自己设置的,比如设置 3 秒,那么 MySQL就会将执行超过 3 秒的 SQL 语句记录在慢查询日志中。
SQL 执行过程中,优化器通过成本计算预估出执行效率最高的方式,基本的预估维度为:
- IO 成本:从磁盘读取数据到内存的开销。
- CPU 成本:CPU 处理内存中数据的开销。
基于这两个维度,可以得出影响 SQL 执行效率的因素有:
①、IO 成本
- 数据量:数据量越大,IO 成本越高。所以要避免 select *;尽量分页查询。
- 数据从哪读取:尽量通过索引加快查询。
②、CPU 成本
- 尽量避免复杂的查询条件,如有必要,考虑对子查询结果进行过滤。
- 尽量缩减计算成本,比如说为排序字段加上索引,提高排序效率;比如说使用 union all 替代 union,减少去重处理。
慢sql日志怎么开启?
慢 SQL 日志的开启方式有多种,
- 直接编辑 MySQL 的配置文件 my.cnf 或 my.ini,设置 slow_query_log 参数为 1,设置 slow_query_log_file 参数为慢查询日志的路径,设置 long_query_time 参数为慢查询的时间阈值。然后重启 MySQL 服务就好了

- 通过 set global 命令动态设置。

有哪些方式优化 SQL?

- 通过 explain 查看查询执行计划,查看执行结果,查看 sql 是否走索引,如果不走索引,考虑增加索引。
- 可以通过建立联合索引,实现覆盖索引优化,减少回表
- 联合索引符合最左匹配原则,不然会索引失效
- 避免索引失效,比如不要用左模糊匹配、函数计算、表达式计算、避免使用 != 或者 <> 操作符 等等。
- 联表查询最好要以小表驱动大表,并且被驱动表的字段要有索引,当然最好通过冗余字段的设计,避免联表查询。
- 针对 limit n,y 深分页的查询优化,可以把Limit查询转换成某个位置的查询:select * from tb_sku where id>20000 limit 10;,该方案适用于主键自增的表, 数据库需要扫描OFFSET + LIMIT数量的行。
- 深分页优化可以使用子查询, 从多个表中获取数据且主表行数较多的情况。它首先从索引表中检索出需要的行 ID,然后再根据这些 ID 去关联其他的表获取详细信息。
- 将字段多的表分解成多个表,有些字段使用频率高,有些低,数据量大时,会由于使用频率低的存在而变慢,可以考虑分开
如何优化慢 SQL? (优化数据查询、拆分查询、联合索引进行覆盖查询、避免索引失效、对排序进行优化(相应字段建立索引))
常见 SQL 优化的方法:
- 优化数据访问: limit 子句缩减数据行数、避免 select *
- 拆分查询:分而治之的思想,将一个大查询拆分多个小查询,每个小查询只返回一部分查询结果。
- 覆盖索引: 当索引中的列包含所有查询中需要使用的列的时候,可以避免回表
- 避免索引失效: 检查 Sql 是否因为写的不合理,导致索引失效
- 分解联表查询: 让业务层分多个查询来聚合,或者增加冗余字段减少联表查询
- 排序优化:对于有排序场景,如果 extra 显示 filesort,这时候就需要考虑对排序的字段建立索引,避免文件排序
回答
- 优化数据访问: 要先确认这条查询语句是否查询了不必要的数据行,可以通过 limit 子句来缩减查询返回的数据行数,如果查询语句用了 select *,需要改进 SQL 语句,只返回需要查询的列。
- 切分查询:针对一个大查询可以拆分多个小查询,每个小查询只返回一部分查询数据。比如删除一千万行数据可以改进成分批删除,每一次只删除一批数据,然后睡眠一下,再删除下一批,这样可以将一次性的压力分散到个很长的时间段中,不仅可以降低对服务器的性能影响,还可以大大减少删除时锁的持续时间。
- 覆盖索引:如果没有索引字段的话,就需要考虑建立索引,或者建立联合索引,通过覆盖索引的查询,这样就避免回表查询,可以提高查询性能。
- 避免索引失效:检查 SQL 语句有没有问题,比如对索引进行了计算和函数操作、联合索引没有遵循最左匹配原则等,这些场景都会导致索引失效,这时候就需要修改 SQL 避免索引失效的发生。
- 分解联表查询:针对联表查询的 SQL 语句,可以将联表查询分解成多个单表查询的语句,然后在业务层来聚合数据,或者增加冗余字段减少联表查询。
- 排序优化: 针对 order by 排序操作,如果执行计划的 extra 显示了文件排序,这时候我们可以对排序字段和其他字段建立联合索引,因为索引数据是天然有序的,这样对索引字段进行排序操作的时候,就不需要文件排序了,提高了查询性能。
深分页场景如何优化?
①、延迟关联
延迟关联适用于需要从多个表中获取数据且主表行数较多的情况。它首先从索引表中检索出需要的行 ID,然后再根据这些 ID 去关联其他的表获取详细信息。

首先对employees表进行分页查询,仅获取需要的行的 ID,然后再根据这些 ID 关联获取其他信息,减少了不必要的 JOIN 操作。
②、书签(Seek Method)
书签方法通过记住上一次查询返回的最后一行的某个值,然后下一次查询从这个值开始,避免了扫描大量不需要的行。
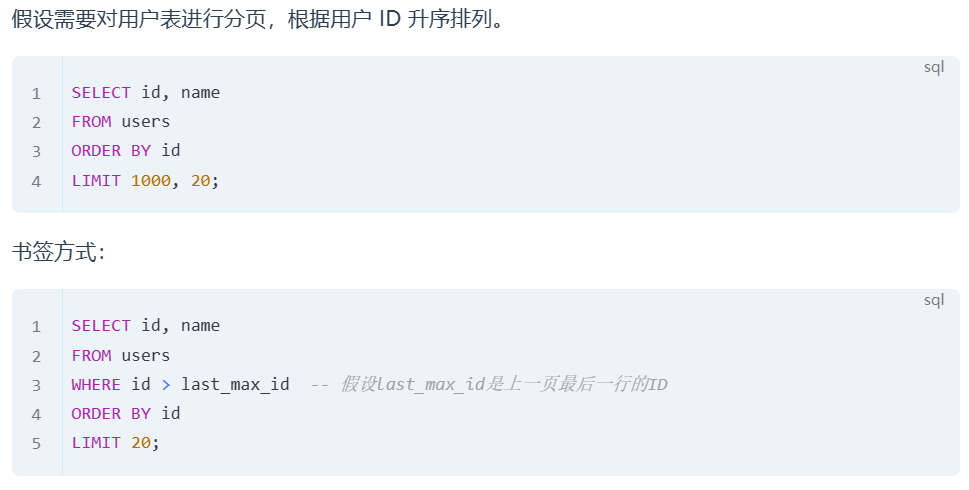
优化之后不再使用OFFSET,而是直接从上一页最后一个用户的 ID 开始查询。这里的last_max_id是上一次查询返回的最后一行的用户 ID。这种方法有效避免了不必要的数据扫描,提高了分页查询的效率。
原因:limit限制条数是在select投影之后才执行的,所以前面的记录也需要获取 (数据库需要扫描OFFSET + LIMIT数量的行。)
如果 SQL 和索引都没问题,查询还是很慢怎么办?
- 分批查询: 针对一个大查询可以拆分多个小查询,每个小查询只返回一部分查询数据.
- 增加缓存: 针对频繁读取的热点数据,我们可以放到 Redis 缓存,避免每次都要请求 MySQL.
- 分表:如果表的数据量很大,比如表数据千万级别了,这时候可以考虑分表了,通过减少每次查询数据总量来解决数据查询缓慢的问题。
- 主从复制: 针对读多写少的场景,我们可以搭建 MySQL主从模式来分摊读请求的流量
- 分库: 针对写多读少的场景,单库的性能无法抗住高并发流量,就需要进行分库,把并发请求分散到多个实例中去。
自己整理,借鉴很多博主,感谢他们







![【web]-sql注入-bestdb](https://i-blog.csdnimg.cn/direct/97a8f63843074333ae0e3488126f4cd6.png)




![[吃瓜教程]南瓜书第6章软间隔与支持向量回归](https://i-blog.csdnimg.cn/direct/712fcaf4b77543099818e621d99b69e7.png)




