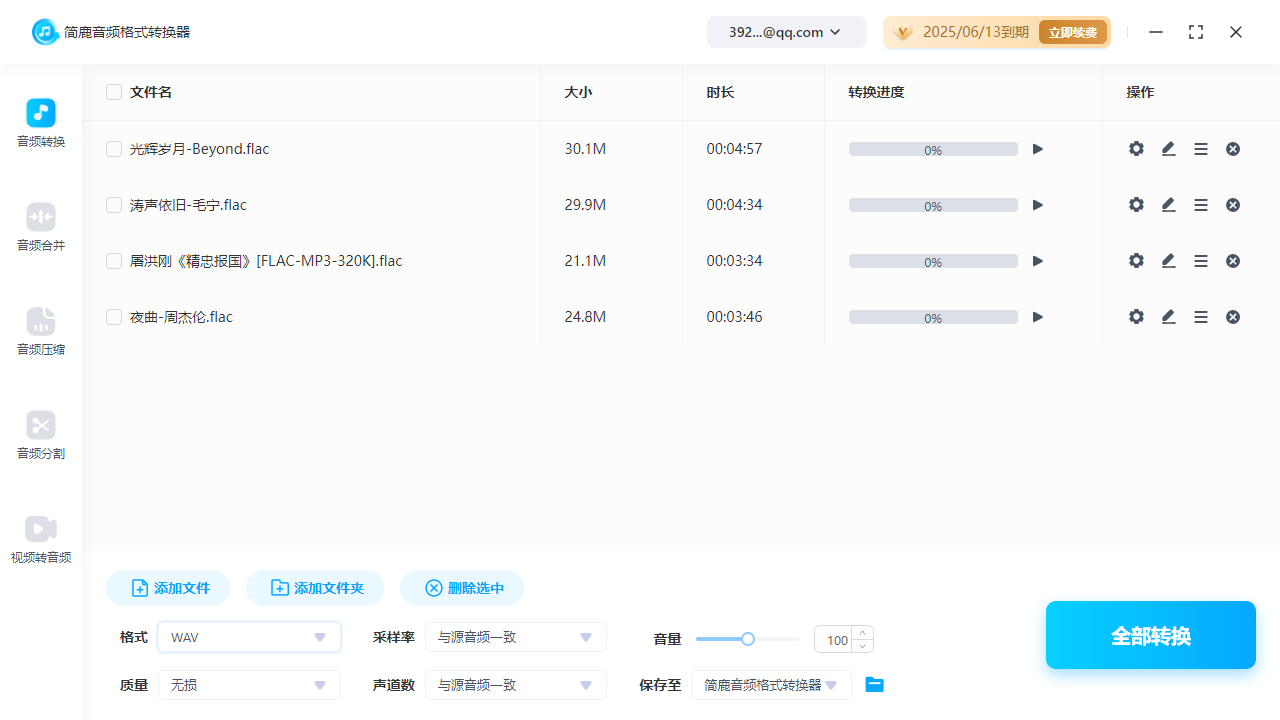
目录
1、基于表征学习的ReID方法
2、基于度量学习的ReID方法
(1)对比损失(Contrastive loss)
(2)三元组损失(Triplet loss)
(3) 四元组损失(Quadruplet loss)
(4)难样本采样三元组损失(Triplet loss with batch hard mining, TriHard loss)
(5)边界挖掘损失(Margin sample mining loss, MSML)
(6)各种loss的性能对比
3、基于局部特征的ReID方法
1、基于表征学习的ReID方法
基于表征学习(Representation learning)的方法是一类非常常用的行人重识别方法[1-4]。这主要得益于深度学习,尤其是卷积神经网络(Convolutional neural network, CNN)的快速发展。由于CNN可以自动从原始的图像数据中根据任务需求自动提取出表征特征(Representation),所以有些研究者把行人重识别问题看做分类(Classification/Identification)问题或者验证(Verification)问题:(1)分类问题是指利用行人的ID或者属性等作为训练标签来训练模型;
(2)验证问题是指输入一对(两张)行人图片,让网络来学习这两张图片是否属于同一个行人。
论文[1]利用Classification/Identification loss和verification loss来训练网络,其网络示意图如下图所示。网络输入为若干对行人图片,包括分类子网络(Classification Subnet)和验证子网络(Verification Subnet)。分类子网络对图片进行ID预测,根据预测的ID来计算分类误差损失。验证子网络融合两张图片的特征,判断这两张图片是否属于同一个行人,该子网络实质上等于一个二分类网络。经过足够数据的训练,再次输入一张测试图片,网络将自动提取出一个特征,这个特征用于行人重识别任务。
 但是也有论文认为光靠行人的ID信息不足以学习出一个泛化能力足够强的模型。在这些工作中,它们额外标注了行人图片的属性特征,例如性别、头发、衣着等属性。通过引入行人属性标签,模型不但要准确地预测出行人ID,还要预测出各项正确的行人属性,这大大增加了模型的泛化能力,多数论文也显示这种方法是有效的。下图是其中一个示例[2],从图中可以看出,网络输出的特征不仅用于预测行人的ID信息,还用于预测各项行人属性。通过结合ID损失和属性损失能够提高网络的泛化能力。
但是也有论文认为光靠行人的ID信息不足以学习出一个泛化能力足够强的模型。在这些工作中,它们额外标注了行人图片的属性特征,例如性别、头发、衣着等属性。通过引入行人属性标签,模型不但要准确地预测出行人ID,还要预测出各项正确的行人属性,这大大增加了模型的泛化能力,多数论文也显示这种方法是有效的。下图是其中一个示例[2],从图中可以看出,网络输出的特征不仅用于预测行人的ID信息,还用于预测各项行人属性。通过结合ID损失和属性损失能够提高网络的泛化能力。

如今依然有大量工作是基于表征学习,表征学习也成为了ReID领域的一个非常重要的baseline,并且表征学习的方法比较鲁棒,训练比较稳定,结果也比较容易复现。但是个人的实际经验感觉表征学习容易在数据集的domain上过拟合,并且当训练ID增加到一定程度的时候会显得比较乏力。
2、基于度量学习的ReID方法
度量学习(Metric learning)是广泛用于图像检索领域的一种方法。不同于表征学习,度量学习旨在通过网络学习出两张图片的相似度。在行人重识别问题上,具体为同一行人的不同图片相似度大于不同行人的不同图片。最后网络的损失函数使得相同行人图片(正样本对)的距离尽可能小,不同行人图片(负样本对)的距离尽可能大。常用的度量学习损失方法有对比损失(Contrastive loss)[5]、三元组损失(Triplet loss)[6-8]、 四元组损失(Quadruplet loss)[9]、难样本采样三元组损失(Triplet hard loss with batch hard mining, TriHard loss)[10]、边界挖掘损失(Margin sample mining loss, MSML)[11]。首先,假如有两张输入图片 𝐼1 和 𝐼2 ,通过网络的前馈我们可以得到它们归一化后的特征向量 𝑓𝐼1 和 𝑓𝐼2 。我们定义这两张图片特征向量的欧式距离为:
𝑑𝐼1,𝐼2=||𝑓𝐼1−𝑓𝐼2||2
(1)对比损失(Contrastive loss)

对比损失用于训练孪生网络(Siamese network),其结构图如上图所示。孪生网络的输入为一对(两张)图片 𝐼𝑎 和 𝐼𝑏 ,这两张图片可以为同一行人,也可以为不同行人。每一对训练图片都有一个标签 𝑦 ,其中 𝑦=1 表示两张图片属于同一个行人(正样本对),反之 𝑦=0 表示它们属于不同行人(负样本对)。之后,对比损失函数写作:
𝐿𝑐=𝑦𝑑𝐼𝑎,𝐼𝑏2+(1−𝑦)(𝛼−𝑑𝐼𝑎,𝐼𝑏)+2
(2)三元组损失(Triplet loss)
三元组损失是一种被广泛应用的度量学习损失,之后的大量度量学习方法也是基于三元组损失演变而来。顾名思义,三元组损失需要三张输入图片。和对比损失不同,一个输入的三元组(Triplet)包括一对正样本对和一对负样本对。三张图片分别命名为固定图片(Anchor) 𝑎 ,正样本图片(Positive) 𝑝 和负样本图片(Negative) 𝑛 。图片 𝑎 和图片 𝑝 为一对正样本对,图片 𝑎 和图片 𝑛 为一对负样本对。则三元组损失表示为:
𝐿𝑡=(𝑑𝑎,𝑝−𝑑𝑎,𝑛+𝛼)+
如下图所示,三元组可以拉近正样本对之间的距离,推开负样本对之间的距离,最后使得相同ID的行人图片在特征空间里形成聚类,达到行人重识别的目的。
其中 (𝑧)+ 表示 𝑚𝑎𝑥(𝑧,0) , 𝛼 是根据实际需求设计的阈值参数。为了最小化损失函数,当网络输入一对正样本对, 𝑑(𝐼𝑎,𝐼𝑏) 会逐渐变小,即相同ID的行人图片会逐渐在特征空间形成聚类。反之,当网络输入一对负样本对时, 𝑑(𝐼𝑎,𝐼𝑏) 会逐渐变大直到超过设定的 𝛼 。通过最小化 𝐿𝑐 ,最后可以使得正样本对之间的距离逐渐变小,负样本对之间的距离逐渐变大,从而满足行人重识别任务的需要。

论文[8]认为原版的Triplet loss只考虑正负样本对之间的相对距离,而并没有考虑正样本对之间的绝对距离,为此提出改进三元组损失(Improved triplet loss):
𝐿𝑖𝑡=𝑑𝑎,𝑝+(𝑑𝑎,𝑝−𝑑𝑎,𝑛+𝛼)+
公式添加 𝑑𝑎,𝑝 项,保证网络不仅能够在特征空间把正负样本推开,也能保证正样本对之间的距离很近。
(3) 四元组损失(Quadruplet loss)

四元组损失是三元组损失的另一个改进版本。顾名思义,四元组(Quadruplet)需要四张输入图片,和三元组不同的是多了一张负样本图片。即四张图片为固定图片(Anchor) 𝑎 ,正样本图片(Positive) 𝑝 ,负样本图片1(Negative1) 𝑛1 和负样本图片2(Negative2) 𝑛2 。其中 𝑛1 和 𝑛2 是两张不同行人ID的图片,其结构如上图所示。则四元组损失表示为:
𝑞=(𝑑𝑎,𝑝−𝑑𝑎,𝑛1+𝛼)++(𝑑𝑎,𝑝−𝑑𝑛1,𝑛2+𝛽)+
其中 𝛼 和 𝛽 是手动设置的正常数,通常设置 𝛽 小于 𝛼 ,前一项称为强推动,后一项称为弱推动。相比于三元组损失只考虑正负样本间的相对距离,四元组添加的第二项不共享ID,所以考虑的是正负样本间的绝对距离。因此,四元组损失通常能让模型学习到更好的表征。
(4)难样本采样三元组损失(Triplet loss with batch hard mining, TriHard loss)
难样采样三元组损失(本文之后用TriHard损失表示)是三元组损失的改进版。传统的三元组随机从训练数据中抽样三张图片,这样的做法虽然比较简单,但是抽样出来的大部分都是简单易区分的样本对。如果大量训练的样本对都是简单的样本对,那么这是不利于网络学习到更好的表征。大量论文发现用更难的样本去训练网络能够提高网络的泛化能力,而采样难样本对的方法很多。论文[10]提出了一种基于训练批量(Batch)的在线难样本采样方法——TriHard Loss。
TriHard损失的核心思想是:对于每一个训练batch,随机挑选 𝑃 个ID的行人,每个行人随机挑选 𝐾 张不同的图片,即一个batch含有 𝑃×𝐾 张图片。之后对于batch中的每一张图片 𝑎 ,我们可以挑选一个最难的正样本和一个最难的负样本和 𝑎 组成一个三元组。
首先我们定义和 𝑎 为相同ID的图片集为 𝐴 ,剩下不同ID的图片图片集为 𝐵 ,则TriHard损失表示为:
𝐿𝑡ℎ=1𝑃×𝐾∑𝑎∈𝑏𝑎𝑡𝑐ℎ(max𝑝∈𝐴𝑑𝑎,𝑝−min𝑛∈𝐵𝑑𝑎,𝑛+𝛼)+
其中 𝛼 是人为设定的阈值参数。TriHard损失会计算 𝑎 和batch中的每一张图片在特征空间的欧式距离,然后选出与 𝑎 距离最远(最不像)的正样本 𝑝 和距离最近(最像)的负样本 𝑛 来计算三元组损失。通常TriHard损失效果比传统的三元组损失要好。
(5)边界挖掘损失(Margin sample mining loss, MSML)
边界样本挖掘损失(MSML)是一种引入难样本采样思想的度量学习方法。三元组损失只考虑了正负样本对之间的相对距离。为了引入正负样本对之间的绝对距离,四元组损失加入一张负样本组成了四元组{𝑎,𝑝,𝑛1,𝑛2}。四元组损失也定义为:
𝐿𝑞=(𝑑𝑎,𝑝−𝑑𝑎,𝑛1+𝛼)++(𝑑𝑎,𝑝−𝑑𝑛1,𝑛2+𝛽)+
假如我们忽视参数 𝛼 和 𝛽 的影响,我们可以用一种更加通用的形式表示四元组损失:
𝐿𝑞′=(𝑑𝑎,𝑝−𝑑𝑚,𝑛+𝛼)+
其中 𝑚 和 𝑛 是一对负样本对, 𝑚 和 𝑎 既可以是一对正样本对也可以是一对负样本对。之后把TriHard loss的难样本挖掘思想引入进来,便可以得到:
𝐿𝑚𝑠𝑚𝑙=(max𝑎,𝑝𝑑𝑎,𝑝−min𝑚,𝑛𝑑𝑚,𝑛+𝛼)+
其中 𝑎,𝑝,𝑚,𝑛 均是batch中的图片, 𝑎,𝑝 是batch中最不像的正样本对, 𝑚,𝑛 是batch 中最像的负样本对, 𝑎,𝑚 皆可以是正样本对也可以是负样本对。概括而言TriHard损失是针对batch中的每一张图片都挑选了一个三元组,而MSML损失只挑选出最难的一个正样本对和最难的一个负样本对计算损失。所以MSML是比TriHard更难的一种难样本采样,此外 max𝑎,𝑝𝑑𝑎,𝑝 可以看作是正样本对距离的上界, min𝑚,𝑛𝑑𝑚,𝑛 可以看作是负样本对的下界。MSML是为了把正负样本对的边界给推开,因此命名为边界样本挖掘损失。总的概括,MSML是同时兼顾相对距离和绝对距离并引入了难样本采样思想的度量学习方法。其演变思想如下图:

(6)各种loss的性能对比
在论文[11]之中,对上面提到的主要损失函数在尽可能公平的实验的条件下进行性能对比,实验结果如下表所示。作为一个参考

3、基于局部特征的ReID方法
早期的ReID研究大家还主要关注点在全局的global feature上,就是用整图得到一个特征向量进行图像检索。但是后来大家逐渐发现全局特征遇到了瓶颈,于是开始渐渐研究起局部的local feature。常用的提取局部特征的思路主要有图像切块、利用骨架关键点定位以及姿态矫正等等。
(1)图片切块是一种很常见的提取局部特征方式[12]。如下图所示,图片被垂直等分为若干份,因为垂直切割更符合我们对人体识别的直观感受,所以行人重识别领域很少用到水平切割。

之后,被分割好的若干块图像块按照顺序送到一个长短时记忆网络(Long short term memory network, LSTM),最后的特征融合了所有图像块的局部特征。但是这种缺点在于对图像对齐的要求比较高,如果两幅图像没有上下对齐,那么很可能出现头和上身对比的现象,反而使得模型判断错误。
(2)为了解决图像不对齐情况下手动图像切片失效的问题,一些论文利用一些先验知识先将行人进行对齐,这些先验知识主要是预训练的人体姿态(Pose)和骨架关键点(Skeleton) 模型。论文[13]先用姿态估计的模型估计出行人的关键点,然后用仿射变换使得相同的关键点对齐。如下图所示,一个行人通常被分为14个关键点,这14个关键点把人体结果分为若干个区域。为了提取不同尺度上的局部特征,作者设定了三个不同的PoseBox组合。之后这三个PoseBox矫正后的图片和原始为矫正的图片一起送到网络里去提取特征,这个特征包含了全局信息和局部信息。特别提出,这个仿射变换可以在进入网络之前的预处理中进行,也可以在输入到网络后进行。如果是后者的话需要需要对仿射变换做一个改进,因为传统的仿射变化是不可导的。为了使得网络可以训练,需要引入可导的近似放射变化,在本文中不赘述相关知识。

(3)CVPR2017的工作Spindle Net[14]也利用了14个人体关键点来提取局部特征。和论文[12]不同的是,Spindle Net并没有用仿射变换来对齐局部图像区域,而是直接利用这些关键点来抠出感兴趣区域(Region of interest, ROI)。Spindle Net网络如下图所示,首先通过骨架关键点提取的网络提取14个人体关键点,之后利用这些关键点提取7个人体结构ROI。网络中所有提取特征的CNN(橙色表示)参数都是共享的,这个CNN分成了线性的三个子网络FEN-C1、FEN-C2、FEN-C3。对于输入的一张行人图片,有一个预训练好的骨架关键点提取CNN(蓝色表示)来获得14个人体关键点,从而得到7个ROI区域,其中包括三个大区域(头、上身、下身)和四个四肢小区域。这7个ROI区域和原始图片进入同一个CNN网络提取特征。原始图片经过完整的CNN得到一个全局特征。三个大区域经过FEN-C2和FEN-C3子网络得到三个局部特征。四个四肢区域经过FEN-C3子网络得到四个局部特征。之后这8个特征按照图示的方式在不同的尺度进行联结,最终得到一个融合全局特征和多个尺度局部特征的行人重识别特征。

(4)论文[15]提出了一种全局-局部对齐特征描述子(Global-Local-Alignment Descriptor, GLAD),来解决行人姿态变化的问题。与Spindle Net类似,GLAD利用提取的人体关键点把图片分为头部、上身和下身三个部分。之后将整图和三个局部图片一起输入到一个参数共享CNN网络中,最后提取的特征融合了全局和局部的特征。为了适应不同分辨率大小的图片输入,网络利用全局平均池化(Global average pooling, GAP)来提取各自的特征。和Spindle Net略微不同的是四个输入图片各自计算对应的损失,而不是融合为一个特征计算一个总的损失。
 (5)以上所有的局部特征对齐方法都需要一个额外的骨架关键点或者姿态估计的模型。而训练一个可以达到实用程度的模型需要收集足够多的训练数据,这个代价是非常大的。为了解决以上问题,AlignedReID[16]提出基于SP距离的自动对齐模型,在不需要额外信息的情况下来自动对齐局部特征。而采用的方法就是动态对齐算法,或者也叫最短路径距离。这个最短距离就是自动计算出的local distance。
(5)以上所有的局部特征对齐方法都需要一个额外的骨架关键点或者姿态估计的模型。而训练一个可以达到实用程度的模型需要收集足够多的训练数据,这个代价是非常大的。为了解决以上问题,AlignedReID[16]提出基于SP距离的自动对齐模型,在不需要额外信息的情况下来自动对齐局部特征。而采用的方法就是动态对齐算法,或者也叫最短路径距离。这个最短距离就是自动计算出的local distance。

这个local distance可以和任何global distance的方法结合起来,论文[15]选择以TriHard loss作为baseline实验,最后整个网络的结构如下图所示,具体细节可以去看原论文。