训练代码:
train.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import torch.nn.functional as F
# 假设我们有一个简单的文本数据集
class TextDataset(Dataset):
def __init__(self, texts, labels, vocab):
self.texts = texts
self.labels = labels
self.vocab = vocab
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
# 将文本转换为索引
text_indices = [self.vocab.get(word, self.vocab['<UNK>']) for word in text.split()]
return torch.tensor(text_indices, dtype=torch.long), torch.tensor(label, dtype=torch.long)
# 定义一个简单的LSTM分类器
class LSTMClassifier(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim):
super(LSTMClassifier, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
embedded = self.embedding(x)
_, (hidden, _) = self.lstm(embedded)
output = self.fc(hidden[-1])
return output
# 构建词汇表
vocab = {'<PAD>': 0, '<UNK>': 1, 'I': 2, 'love': 3, 'this': 4, 'movie': 5, 'is': 6, 'terrible': 7}
vocab_size = len(vocab)
# 示例数据
texts = ["I love this movie", "This movie is terrible"]
labels = [1, 0] # 1表示正面情感,0表示负面情感
# 创建数据集和数据加载器
dataset = TextDataset(texts, labels, vocab)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True, collate_fn=lambda x: (torch.nn.utils.rnn.pad_sequence([item[0] for item in x], batch_first=True), torch.stack([item[1] for item in x])))
# 实例化模型
embedding_dim = 50
hidden_dim = 50
output_dim = 2
model = LSTMClassifier(vocab_size, embedding_dim, hidden_dim, output_dim)
# 使用DataParallel包装模型
model = nn.DataParallel(model)
# 将模型移动到GPU
model = model.cuda()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练步骤
model.train()
for epoch in range(10): # 训练10个epoch
for inputs, labels in dataloader:
inputs, labels = inputs.cuda(), labels.cuda()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item()}")
print("训练完成")
# 测试模型
model.eval()
test_texts = ["I love this movie", "This movie is terrible"]
test_dataset = TextDataset(test_texts, [1, 0], vocab)
test_dataloader = DataLoader(test_dataset, batch_size=2, shuffle=False, collate_fn=lambda x: (torch.nn.utils.rnn.pad_sequence([item[0] for item in x], batch_first=True), torch.stack([item[1] for item in x])))
with torch.no_grad():
for inputs, labels in test_dataloader:
inputs, labels = inputs.cuda(), labels.cuda()
outputs = model(inputs)
predictions = torch.argmax(F.softmax(outputs, dim=1), dim=1)
print(f"Predictions: {predictions.cpu().numpy()}, Labels: {labels.cpu().numpy()}")
执行命令:
- export CUDA_VISIBLE_DEVICES=0,2
- python train.py
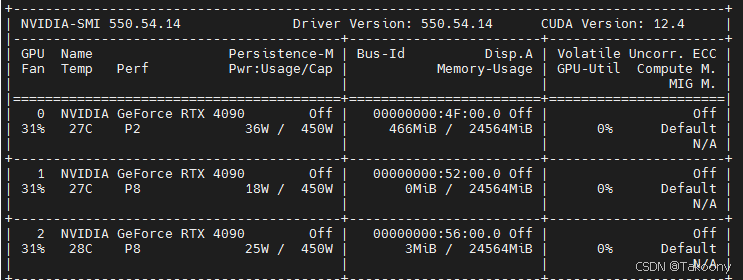
GPU监控
训练前

训练中
Epoch 1, Loss: 0.7198400497436523
Epoch 2, Loss: 0.6889444589614868
Epoch 3, Loss: 0.6591541767120361
Epoch 4, Loss: 0.630306601524353
Epoch 5, Loss: 0.6022476553916931
Epoch 6, Loss: 0.5748419761657715
Epoch 7, Loss: 0.5479871034622192
Epoch 8, Loss: 0.5216072201728821
Epoch 9, Loss: 0.4956483840942383
Epoch 10, Loss: 0.47007784247398376
训练完成
Predictions: [1 0], Labels: [1 0]
结论
export CUDA_VISIBLE_DEVICES=0,2与nn.DataParallel(model)结合的方法是正确的
为什么需要指定 CUDA_VISIBLE_DEVICES
- 在多GPU系统中,默认情况下,PyTorch 会尝试使用所有可用的GPU进行训练。
- 通过设置 CUDA_VISIBLE_DEVICES 环境变量,用于控制哪些GPU对当前进程可见,PyTorch 只会使用这些可见的GPU进行训练。
- 通过设置环境变量,你可以在不修改代码的情况下控制使用的GPU。这使得代码更加简洁和通用,不需要在代码中硬编码GPU的选择逻辑。
总的来说:通过设置 CUDA_VISIBLE_DEVICES 环境变量,你可以灵活地控制哪些GPU对当前进程可见,从而避免资源冲突、简化代码并更好地管理多GPU资源。这是使用 torch.nn.DataParallel 进行多GPU训练时的一种常见做法。
nn.DataParallel原理是什么
nn.DataParallel 是 PyTorch 中用于多 GPU 并行计算的一个模块。它的主要原理是将输入数据分割成多个子集,并将这些子集分配到不同的 GPU 上进行并行计算。具体来说,nn.DataParallel 的工作流程如下:
- 模型复制:首先,nn.DataParallel 会将模型复制到每个 GPU 上。这意味着每个 GPU 都会有一份完整的模型副本。
- 数据分割:输入数据会被分割成多个子集,每个子集会被分配到一个 GPU 上。通常,这个分割是按批次(batch)维度进行的。
- 并行计算:每个 GPU 使用其本地的模型副本对分配到的子集进行前向传播和后向传播计算。
- 梯度汇总:在所有 GPU 上完成计算后,nn.DataParallel 会将每个 GPU 计算得到的梯度汇总到主 GPU 上(通常是 GPU 0)。
- 参数更新:主 GPU 汇总梯度后,使用这些梯度更新模型参数。更新后的参数会同步到所有 GPU 上的模型副本。