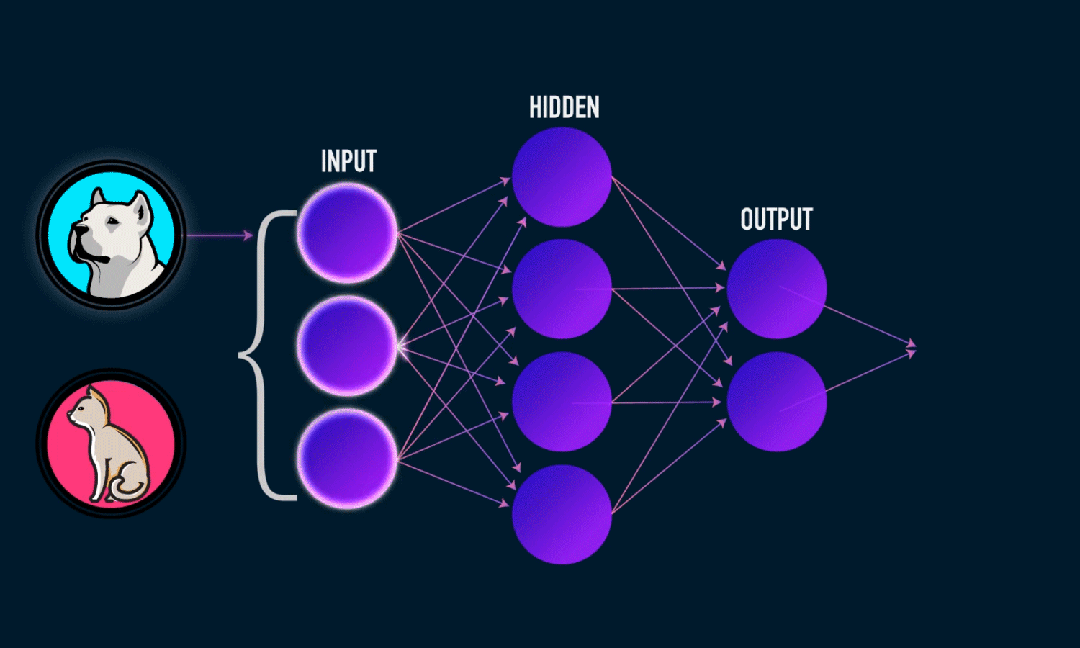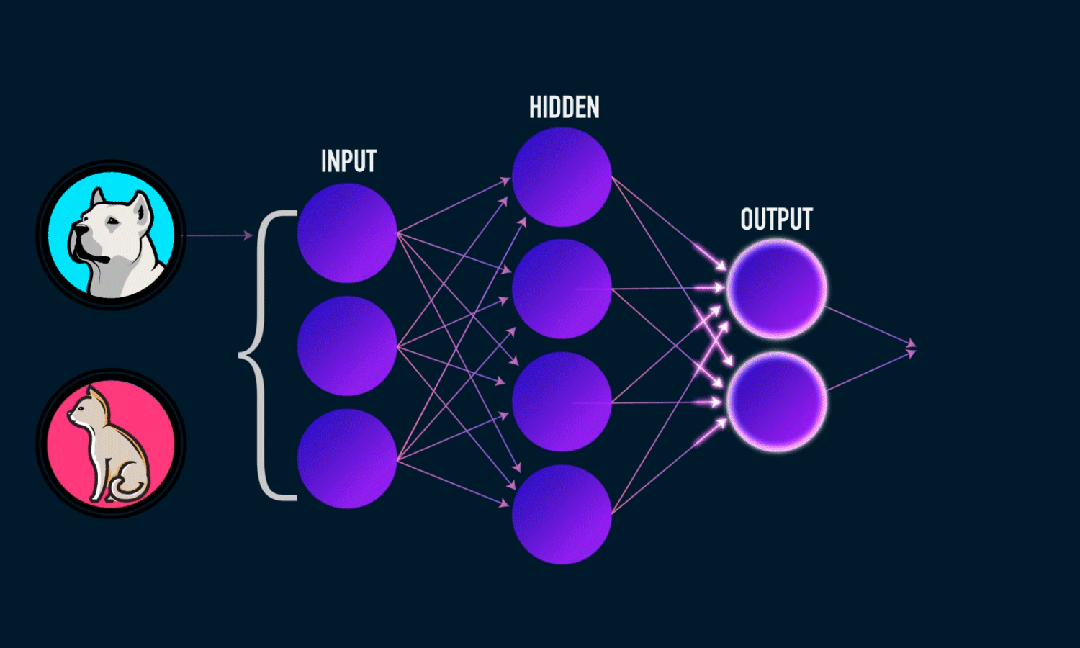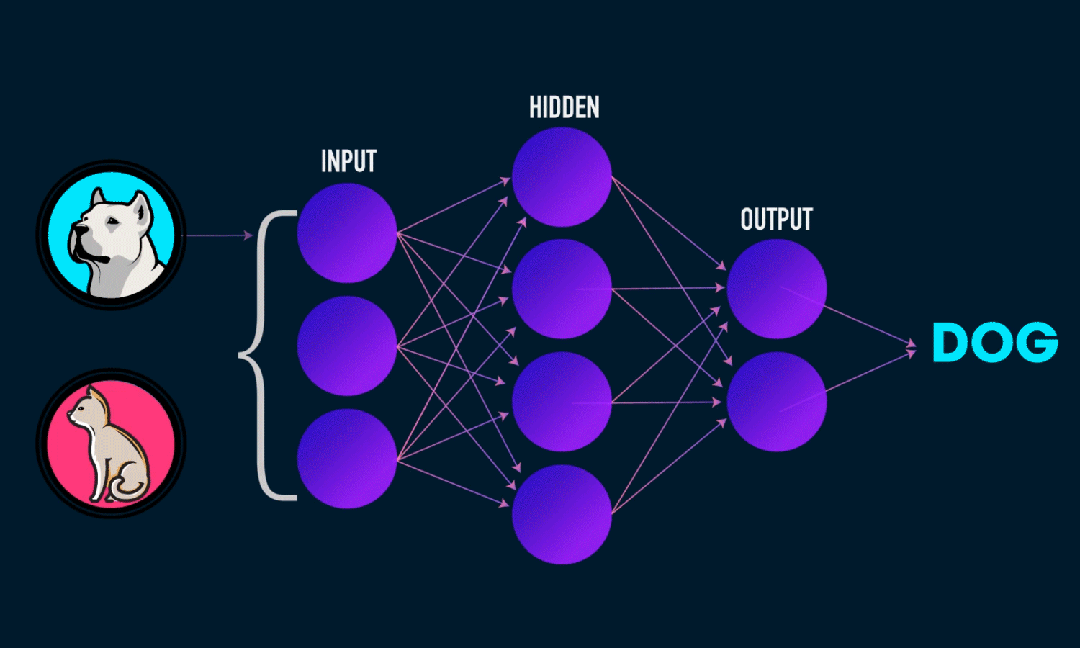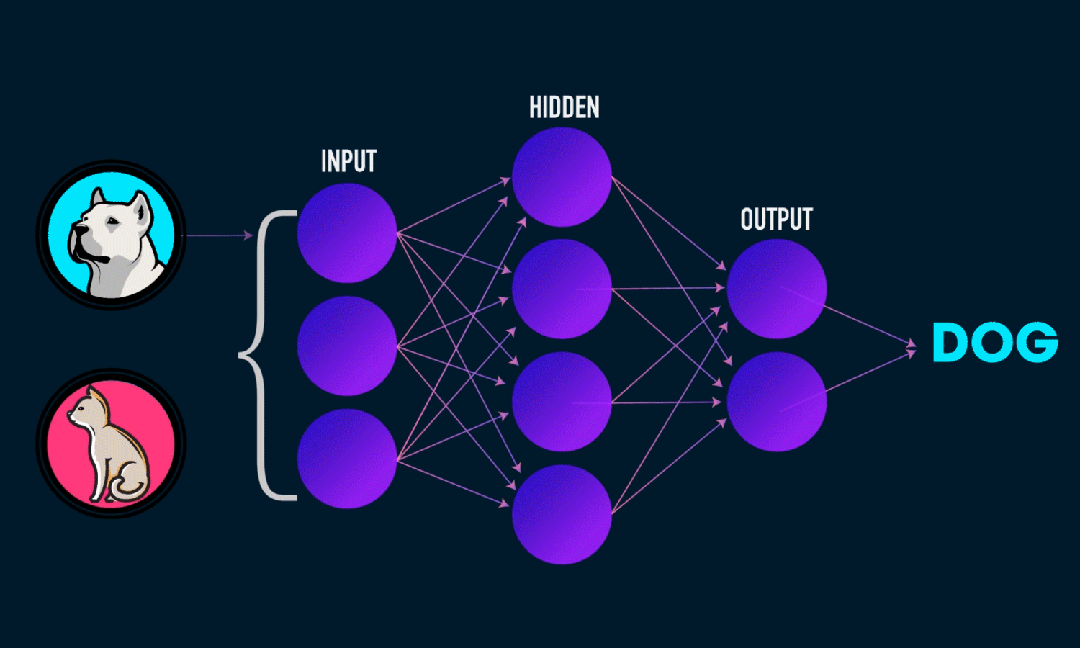
极限学习机(ELM)是一种简单的单层前馈神经网络(SLFN)学习算法。理论上,极限学习机算法(ELM)往往以极快的学习速度提供良好的性能(属于机器学习算法),由Huang等人提出。ELM的主要特点是它的学习速度非常快,相比传统的梯度下降方法(如BP神经网络),ELM不需要迭代过程。其基本原理是随机选择隐藏层的权重和偏置,然后通过最小化输出层的误差来学习输出权重。
img
ELM算法的主要步骤
-
随机初始化输入到隐藏层的权重和偏置:
-
隐藏层的权重和偏置是随机生成的,并且在训练过程中保持不变。
-
-
计算隐藏层的输出矩阵(即激活函数的输出):
-
使用激活函数(如sigmoid、ReLU等)计算隐藏层的输出。
-
-
计算输出权重:
-
通过最小二乘法计算隐藏层到输出层的权重。
-
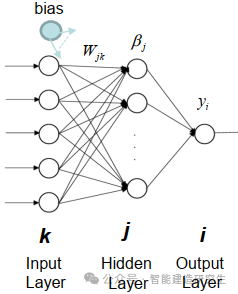
ELM的数学公式如下:
-
给定一个训练数据集 ,其中 ,
-
隐藏层的输出矩阵 的计算公式为:
-
其中,是输入矩阵, 是输入到隐藏层的权重矩阵,是偏置向量,是激活函数。
-
-
输出权重 的计算公式为:
-
其中,是隐藏层输出矩阵的广义逆,是输出矩阵。
-
ELM算法的应用场景
-
大规模数据集处理:ELM 在处理大规模数据集时表现良好,因为它的训练速度很快,适用于需要快速训练模型的场景,比如大规模图像分类、自然语言处理等任务。
-
工业预测:ELM 在工业预测领域有广泛的应用,比如工业生产过程中的质量控制、设备故障预测等。它可以快速训练预测模型,并对实时数据做出快速响应。
-
金融领域:ELM 可以用于金融数据分析和预测,比如股票价格预测、风险管理、信用评分等。由于金融数据通常是高维度的,ELM 的快速训练速度对处理这些数据很有优势。
-
医学诊断:在医学领域,ELM 可以用于疾病预测、医学影像分析等任务。它可以快速训练模型,并对患者数据进行分类或回归,帮助医生做出更快速和准确的诊断。
-
智能控制系统:ELM 可以用于智能控制系统中,比如智能家居、智能交通系统等。通过学习环境的特征和规律,ELM 可以帮助系统做出智能决策,提高系统的效率和性能。
Python实现ELM算法
我们使用 make_moons 数据集,这是一个常用于机器学习和深度学习分类任务的玩具数据集。它生成的点分布成两个相交的半月形状,非常适合用于展示分类算法的性能和决策边界。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
# 定义极限学习机(ELM)类
class ELM:
def __init__(self, n_hidden_units):
# 初始化隐藏层神经元数量
self.n_hidden_units = n_hidden_units
def _sigmoid(self, x):
# 定义Sigmoid激活函数
return 1 / (1 + np.exp(-x))
def fit(self, X, y):
# 随机初始化输入权重
self.input_weights = np.random.randn(X.shape[1], self.n_hidden_units)
# 随机初始化偏置
self.biases = np.random.randn(self.n_hidden_units)
# 计算隐藏层输出矩阵H
H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
# 计算输出权重
self.output_weights = np.dot(np.linalg.pinv(H), y)
def predict(self, X):
# 计算隐藏层输出矩阵H
H = self._sigmoid(np.dot(X, self.input_weights) + self.biases)
# 返回预测结果
return np.dot(H, self.output_weights)
# 创建数据集并进行预处理
X, y = make_moons(n_samples=1000, noise=0.2, random_state=42)
# 将标签转换为二维数组(ELM需要二维数组作为标签)
y = y.reshape(-1, 1)
# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# 训练和比较ELM与MLP
# 训练ELM
elm = ELM(n_hidden_units=10)
elm.fit(X_train, y_train)
y_pred_elm = elm.predict(X_test)
# 将预测结果转换为类别标签
y_pred_elm_class = (y_pred_elm > 0.5).astype(int)
# 计算ELM的准确率
accuracy_elm = accuracy_score(y_test, y_pred_elm_class)
# 训练MLP
mlp = MLPClassifier(hidden_layer_sizes=(10,), max_iter=1000, random_state=42)
mlp.fit(X_train, y_train.ravel())
# 预测测试集结果
y_pred_mlp = mlp.predict(X_test)
# 计算MLP的准确率
accuracy_mlp = accuracy_score(y_test, y_pred_mlp)
# 打印ELM和MLP的准确率
print(f"ELM Accuracy: {accuracy_elm}")
print(f"MLP Accuracy: {accuracy_mlp}")
# 可视化结果
def plot_decision_boundary(model, X, y, ax, title):
# 设置绘图范围
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
# 创建网格
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
np.arange(y_min, y_max, 0.01))
# 预测网格中的所有点
Z = model(np.c_[xx.ravel(), yy.ravel()])
Z = (Z > 0.5).astype(int)
Z = Z.reshape(xx.shape)
# 画出决策边界
ax.contourf(xx, yy, Z, alpha=0.8)
# 画出数据点
ax.scatter(X[:, 0], X[:, 1], c=y.ravel(), edgecolors='k', marker='o')
ax.set_title(title)
# 创建图形
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
# 画出ELM的决策边界
plot_decision_boundary(lambda x: elm.predict(x), X_test, y_test, axs[0], "ELM Decision Boundary")
# 画出MLP的决策边界
plot_decision_boundary(lambda x: mlp.predict(x), X_test, y_test, axs[1], "MLP Decision Boundary")
# 显示图形
plt.show()
# 输出:
'''
ELM Accuracy: 0.9666666666666667
MLP Accuracy: 0.9766666666666667
'''
可视化输出:
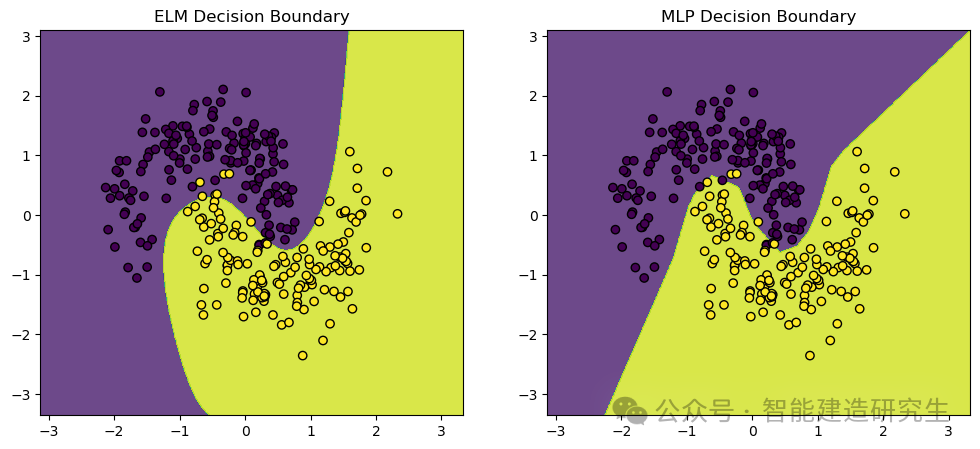
以上内容总结自网络,如有帮助欢迎转发,我们下次再见!











![[AI 大模型] 阿里巴巴 通义千问](https://i-blog.csdnimg.cn/direct/3436eef4ec9b41c7bc677eb4f551bfcb.jpeg#pic_center)