间隔重复算法
理论背景
遗忘曲线是一种描述记忆遗忘率的模型,艾宾浩斯在其著作《记忆:实验心理学的贡献》中首次详细描述了遗忘曲线,他使用了一些无意义的字母组合作为记忆对象,通过在不同的时间间隔后检查记忆的遗忘程度,得出了这一遗忘曲线。如图所示,就是典型的遗忘曲线。艾宾浩斯指出信息的遗忘速度随时间而非线性递减,遗忘最初非常迅速,然后逐渐放缓。基于这一发现,他提出了间隔效应(Spacing Effect),将复习活动分散到不同的日子进行,相比集中在一天内复习,可以显著减少所需的复习次数,并提高长期记忆的效率。这一发现对后续的研究产生了深远影响,启发了对间隔重复技术深入研究和应用的兴趣。
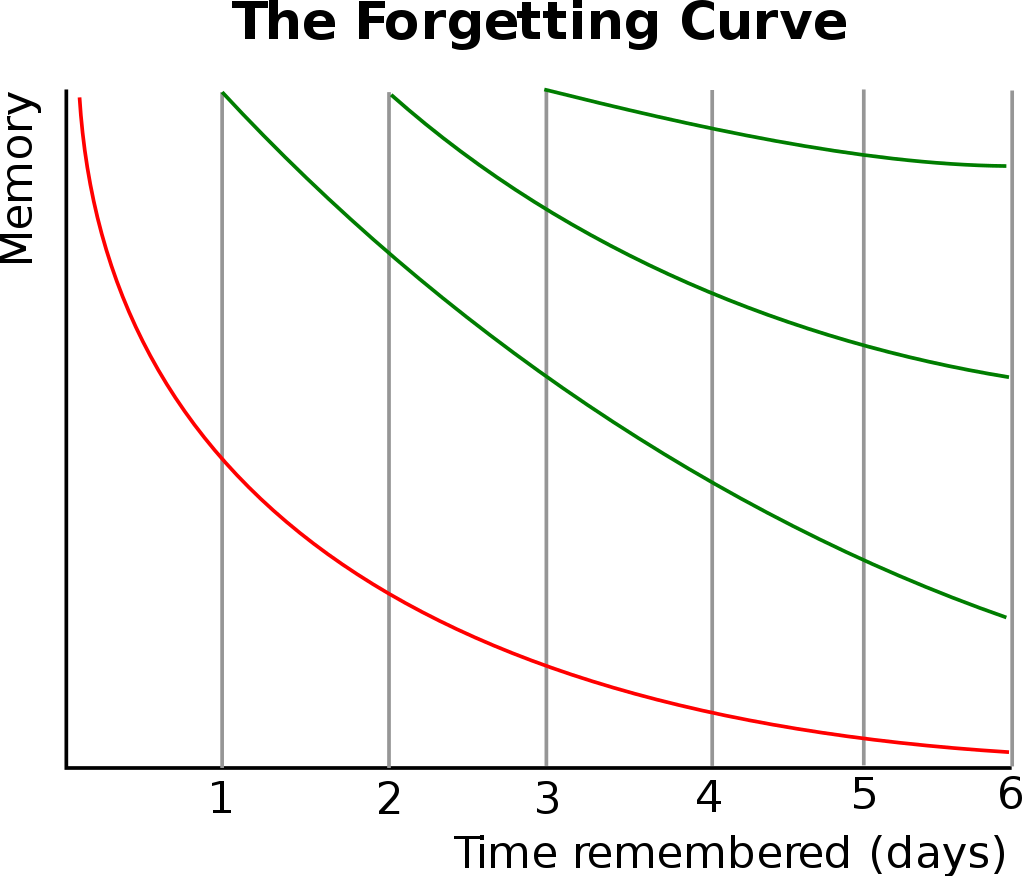
间隔重复(Spaced Repetition)是一种利用心理学间隔效应,通过不断复习所学内容并逐步增加复习期间的间隔来提升效率的学习方法。间隔重复方法适用于多种学习情境,特别是学习者需要牢固记忆大量知识的情形,比如外语词汇的学习,尤其是在目标语言的基础词汇数量很大的时候。将间隔重复应用到学习上的观点最初见于塞西尔·阿莱克·梅斯(Cecil Alec Mace)1932的著作《学习心理学》中,首次提出复习周期的概念:“Acts of revision should be spaced in gradually increasing intervals, roughly intervals of one day, two days, four days, eight days, and so on.” 在2009年的一篇名为《Spaced Repetition For Efficient Learning》的文章中,Gwern Branwen详细介绍了间隔重复技术在实现高效学习过程中的重要性。这篇文章讨论了间隔重复技术的原理和应用,旨在帮助学习者更有效地掌握知识和提高记忆效率,而非简单地死记硬背。

算法设计
本系统基于赫尔曼·艾宾浩斯(Hermann Ebbinghaus)遗忘曲线公式实现简易间隔重复模型,使用指数衰减模型Math.exp(-x)根据用户标识的单词状态(已掌握、认识、模糊、忘记)来动态调整复习间隔,以提高用户的学习效率。材料以抽认卡的形式呈现,正面是单词,背面是释义。用户可以通过翻转抽认卡的方式来检查自己的记忆情况,并选择相应的记忆状态。
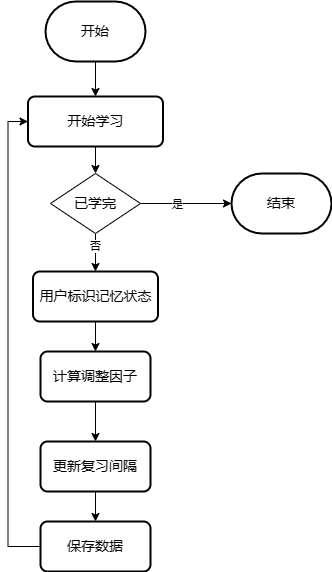
算法实现流程:
- 查询需要复习的单词:从数据库中查询到今日需要复习的单词列表。
- 状态评估:用户选择单词记忆的相应状态,如已掌握、认识、模糊、忘记。
- 间隔调整:根据单词的新状态,计算调整因子,并更新复习间隔。
- 更新数据库:将新的复习间隔和状态保存到数据库中,为下次复习做准备。
具体的流程如图所示。
调整因子的计算基于以下公式:
factor = e^{-forgettingRate}
其中,遗忘率forgettingRate与用户选择的单词记忆状态相关联,状态越好,遗忘率越低,调整因子越大,复习间隔相应延长。
每个单词根据用户的记忆表现被分类为以下四种状态,并分配相应的遗忘率:
- 忘记(Forgotten):遗忘率设置为 0.5,表示记忆较差,需要短时间内复习。
- 模糊(Blurry):遗忘率设置为 0.3,表示记忆有一定基础,但不够牢固。
- 熟悉(Known):遗忘率设置为 0.1,表示记忆相对稳定,可以延长复习间隔。
- 掌握(Mastered):遗忘率为 0.0,表示单词已被完全掌握,无需进一步复习。
复习间隔的动态调整根据每个单词当前的复习间隔和计算得到的调整因子,动态调整下一次复习的时间。具体实现步骤如下:对于每个需要复习的单词,根据其当前状态查找其复习间隔。使用从状态对应的遗忘率计算出的调整因子来修改复习间隔。更新单词的复习间隔和预计下次复习时间。
这样通过公式计算后,调整因子factor的值在e^{-0.5}到e^{-0.0}之间,即0.6065到1.0之间,再将其乘上默认的复习间隔"30,180,720,1440,2880,5760,10080,21600"(单位:分钟),即可得到新的复习间隔,并更新间隔索引。
对于计算用户的遗忘曲线,对数函数有助于模拟记忆衰减的减缓速度,具体计算公式如下:
forgettingRate = log((minutesUntilNextReview / FORGETTING_RATE_ADJUSTMENT) + 1)
其中,FORGETTING_RATE_ADJUSTMENT=30.0为遗忘率调整常量固定值,目前不考虑引入单词的难度级别或者是用户的记忆能力等因素。minutesSinceLastReview是距离上次复习以来的时间间隔,minutesUntilNextReview是距离下次复习的时间间隔,二者单位都为分钟。
最后,根据计算出的结果,通过以下公式计算出用户的记忆保留率:
retentionRate = e^(-forgetingRate * (minutesSinceLastReview / minutesUntilNextReview))
计算后将结果保存在数据库中,用于后续计算用户整体的遗忘曲线。
具体后端代码
间隔算法
controller
WordReviewController.java 调用服务层实现的方法对算法进行调整
package com.example.englishhub.controller;
import com.example.englishhub.entity.LearningPlans;
import com.example.englishhub.entity.WordReview;
import com.example.englishhub.entity.WordReviewVO;
import com.example.englishhub.service.WordReviewService;
import com.example.englishhub.utils.Result;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import jakarta.servlet.http.HttpServletRequest;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
import java.util.Map;
/**
* @Author: hahaha
* @Date: 2024/4/8 15:13
*/
@RestController
@RequestMapping("/wordReview")
@Tag(name = "单词复习管理")
public class WordReviewController {
@Autowired
private WordReviewService wordReviewService;
/**
* 调整复习
* @body wordReview
*/
@Operation(summary = "调整复习")
@PostMapping("/adjust")
public Result adjustReviewIntervals(@RequestBody Map<String, Integer> body) {
Integer wordId = body.get("wordId");
Integer wordBookId = body.get("wordBookId");
Integer status = body.get("status");
// System.out.println("wordId = " + wordId);
// System.out.println("wordBookId = " + wordBookId);
// System.out.println("status = " + status);
wordReviewService.adjustReviewIntervals(wordId, wordBookId, status);
Result result = new Result();
result.success("调整复习成功");
return result;
}
/**
* 获取当天需学单词
* @param wordBookId 单词书ID
* @param dailyNewWords 每日新学单词数
* @param dailyReviewWords 每日复习单词数
* @return 复习单词列表
*/
@Operation(summary = "获取当天需学单词")
@GetMapping("/getToday")
public Result getToday(Integer wordBookId, Integer dailyNewWords, Integer dailyReviewWords) {
Result result = new Result();
List<WordReviewVO> wordReviews = wordReviewService.getWordsToday(wordBookId, dailyNewWords, dailyReviewWords);
result.setData(wordReviews);
result.success("获取当天复习单词成功");
return result;
}
}
service
WordReviewService.java 定义各个方法
package com.example.englishhub.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.example.englishhub.entity.LearningPlans;
import com.example.englishhub.entity.WordReview;
import com.example.englishhub.entity.WordReviewVO;
import java.util.List;
/**
* @Author: hahaha
* @Date: 2024/4/8 15:14
*/
public interface WordReviewService extends IService<WordReview> {
void adjustReviewIntervals(Integer wordId, Integer wordBookId, Integer status);
List<WordReviewVO> getWordsToday(Integer wordBookId, Integer dailyNewWords, Integer dailyReviewWords);
List<WordReview> getAllWordsForUser(Integer userId);
List<WordReview> getWordsByUserId();
}
mapper
WordReviewMapper.java
package com.example.englishhub.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.englishhub.entity.WordReview;
import com.example.englishhub.entity.WordReviewVO;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
/**
* <p>
* 单词复习表 Mapper 接口
* </p>
* @Author: hahaha
* @Date: 2024/4/8 15:14
*/
@Mapper
public interface WordReviewMapper extends BaseMapper<WordReview> {
@Select("SELECT w.id, w.word, w.phonetic_uk, w.phonetic_us, w.definition," +
" wd.audio_url, wd.video_url, wd.definition AS definitionDetail, wd.subtext" +
" FROM word_relation wr" +
" JOIN word w ON wr.word_id = w.id" +
" JOIN words wd ON w.words_id = wd.id" +
" LEFT JOIN word_review wrv ON wrv.word_id = w.id AND wrv.user_id = #{userId}" +
" WHERE wr.word_book_id = #{wordBookId} AND wrv.id IS NULL" +
" ORDER BY w.id ASC" +
" LIMIT #{dailyNewWords}")
List<WordReviewVO> getNewWordsToday(Integer userId, Integer wordBookId, Integer dailyNewWords);
@Select("SELECT w.id, w.word, w.phonetic_uk, w.phonetic_us, w.definition," +
" wd.audio_url, wd.video_url, wd.definition AS definitionDetail, wd.subtext" +
" FROM word_review wr" +
" JOIN word w ON wr.word_id = w.id" +
" JOIN words wd ON w.words_id = wd.id" +
" WHERE wr.user_id = #{userId} AND wr.word_book_id = #{wordBookId}" +
" AND wr.next_review_time <= CURRENT_TIMESTAMP" +
" ORDER BY wr.next_review_time ASC" +
" LIMIT #{dailyReviewWords}")
List<WordReviewVO> getReviewWordsToday(Integer userId, Integer wordBookId, Integer dailyReviewWords);
}
impl
WordReviewServiceImpl.java
package com.example.englishhub.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.example.englishhub.entity.ForgettingCurve;
import com.example.englishhub.entity.WordReview;
import com.example.englishhub.entity.WordReviewVO;
import com.example.englishhub.mapper.WordReviewMapper;
import com.example.englishhub.service.ForgettingCurveService;
import com.example.englishhub.service.LearningPlansService;
import com.example.englishhub.service.WordReviewService;
import com.example.englishhub.utils.JwtUtil;
import jakarta.servlet.http.HttpServletRequest;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.time.LocalDateTime;
import java.time.temporal.ChronoUnit;
import java.time.temporal.Temporal;
import java.util.*;
import java.util.stream.Collectors;
/**
* @Author: hahaha
* @Date: 2024/4/8 15:18
*/
@Service
public class WordReviewServiceImpl extends ServiceImpl<WordReviewMapper, WordReview> implements WordReviewService {
@Autowired
private WordReviewMapper wordReviewMapper;
@Autowired
private HttpServletRequest request;
@Override
public void adjustReviewIntervals(Integer wordId, Integer wordBookId, Integer status) {
String token = request.getHeader("token");
String userId = JwtUtil.validateToken(token);
QueryWrapper<WordReview> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("word_id", wordId);
queryWrapper.eq("user_id", Integer.parseInt(userId));
queryWrapper.eq("word_book_id", wordBookId);
WordReview wordReview = this.getOne(queryWrapper);
if (wordReview == null) {
// 新学单词,使用默认的复习间隔并新增记录
String defaultIntervals = "30,180,720,1440,2880,5760,10080,21600";
List<Integer> intervals = Arrays.stream(defaultIntervals.split(","))
.map(Integer::parseInt)
.collect(Collectors.toList());
wordReview = new WordReview();
wordReview.setUserId(Integer.parseInt(userId));
wordReview.setWordId(wordId);
wordReview.setWordBookId(wordBookId);
wordReview.setStatus(status);
wordReview.setReviewIntervals(defaultIntervals);
wordReview.setReviewIntervalIndex(0);
// 计算调整因子
double factor = calculateAdjustmentFactor(status);
// 调整复习间隔,将intervals列表中的每个元素乘以调整因子,然后将结果转换为整数。
List<Integer> adjustedIntervals = intervals.stream()
.map(interval -> (int) (interval * factor))
.collect(Collectors.toList());
wordReview.setReviewIntervals(adjustedIntervals.stream()
.map(Object::toString)
.collect(Collectors.joining(",")));
// 设置下次复习时间
if (status == 4) { // 单词已掌握
wordReview.setNextReviewTime(null);
} else {
int newIndex = 0;
wordReview.setReviewIntervalIndex(newIndex);
wordReview.setNextReviewTime(LocalDateTime.now().plusMinutes(adjustedIntervals.get(newIndex)));
}
this.save(wordReview);
} else {
List<Integer> intervals = Arrays.stream(wordReview.getReviewIntervals().split(","))
.map(Integer::parseInt)
.collect(Collectors.toList());
if (status == 4) { // 单词已掌握
// 不再进行复习
wordReview.setNextReviewTime(null);
} else {
double factor = calculateAdjustmentFactor(status);
// 调整复习间隔,将intervals列表中的每个元素乘以调整因子,然后将结果转换为整数。
List<Integer> adjustedIntervals = intervals.stream()
.map(interval -> (int) (interval * factor))
.collect(Collectors.toList());
// 更新复习间隔,将adjustedIntervals列表中的每个元素转换为字符串,然后使用逗号(,)将这些字符串连接起来。
wordReview.setReviewIntervals(adjustedIntervals.stream()
.map(Object::toString)
.collect(Collectors.joining(",")));
// 确保索引在合理范围内
int newIndex = (wordReview.getReviewIntervalIndex() + 1) % adjustedIntervals.size();
wordReview.setReviewIntervalIndex(newIndex);
wordReview.setNextReviewTime(LocalDateTime.now().plusMinutes(adjustedIntervals.get(newIndex)));
this.updateById(wordReview);
}
}
}
private WordReview getByWordId(Integer wordId) {
QueryWrapper<WordReview> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("wordId", wordId);
return this.getOne(queryWrapper);
}
@Override
public List<WordReviewVO> getWordsToday(Integer wordBookId, Integer dailyNewWords, Integer dailyReviewWords) {
// 调用mapper层方法获取今天的所有复习记录
String token = request.getHeader("token");
String userId = JwtUtil.validateToken(token);
List<WordReviewVO> reviewWords = wordReviewMapper.getReviewWordsToday(Integer.parseInt(userId), wordBookId, dailyReviewWords);
List<WordReviewVO> newWords = wordReviewMapper.getNewWordsToday(Integer.parseInt(userId), wordBookId, dailyNewWords);
reviewWords.addAll(newWords);
return reviewWords;
}
@Override
public List<WordReview> getAllWordsForUser(Integer userId) {
// String token = request.getHeader("token");
// String userId = JwtUtil.validateToken(token);
QueryWrapper<WordReview> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("userId", userId);
return this.list(queryWrapper);
}
public List<WordReview> getWordsByUserId() {
String token = request.getHeader("token");
String userId = JwtUtil.validateToken(token);
return getAllWordsForUser(Integer.parseInt(userId));
}
public double calculateAdjustmentFactor(int status) {
double forgettingRate;
switch (status) {
case 1: // 忘记forgotten
forgettingRate = 0.5;
break;
case 2: // 模糊 blurry
forgettingRate = 0.3;
break;
case 3: // 熟悉 known
forgettingRate = 0.1;
break;
default: // 已掌握 mastered
forgettingRate = 0.0;
}
// 使用指数函数来计算调整因子,遗忘率越大,调整因子越小
// 原型是e^(-x)
return Math.exp(-forgettingRate);
}
}