一、本文介绍
本文给大家带来的改进机制是图像去雾MB-TaylorFormer,其发布于2023年的国际计算机视觉会议(ICCV)上,可以算是一遍比较权威的图像去雾网络, MB-TaylorFormer是一种为图像去雾设计的多分支高效Transformer网络,它通过应用泰勒公式展开的方式来近似softmax-attention机制,实现了线性的计算复杂性,原本的网络计算量和参数量比较高,我对其进行了一定的跳转参数量和计算量都大幅度的降低,其为高分辨率图像处理也提供了一种新的解决方案。
欢迎大家订阅我的专栏一起学习YOLO! 
专栏回顾:YOLOv10改进系列专栏——本专栏持续复习各种顶会内容——科研必备
目录
一、本文介绍
二、原理介绍
2.1 MB-TaylorFormer基本原理
2.2 泰勒公式展开的自注意力机制
2.3 多尺度注意力精化模块
2.4 多分支架构与多尺度贴片嵌入
三、核心代码
四、代码的使用方式
4.1 修改一
4.2 修改二
4.3 修改三
关闭混合精度验证(可能需要)!
打印计算量的问题!
五、yaml文件和运行记录
5.1 yaml文件
5.2 训练代码
5.3 训练过程截图
五、本文总结
二、原理介绍

官方论文地址:官方论文地址点击此处即可跳转
官方代码地址:官方代码地址点击此处即可跳转

2.1 MB-TaylorFormer基本原理
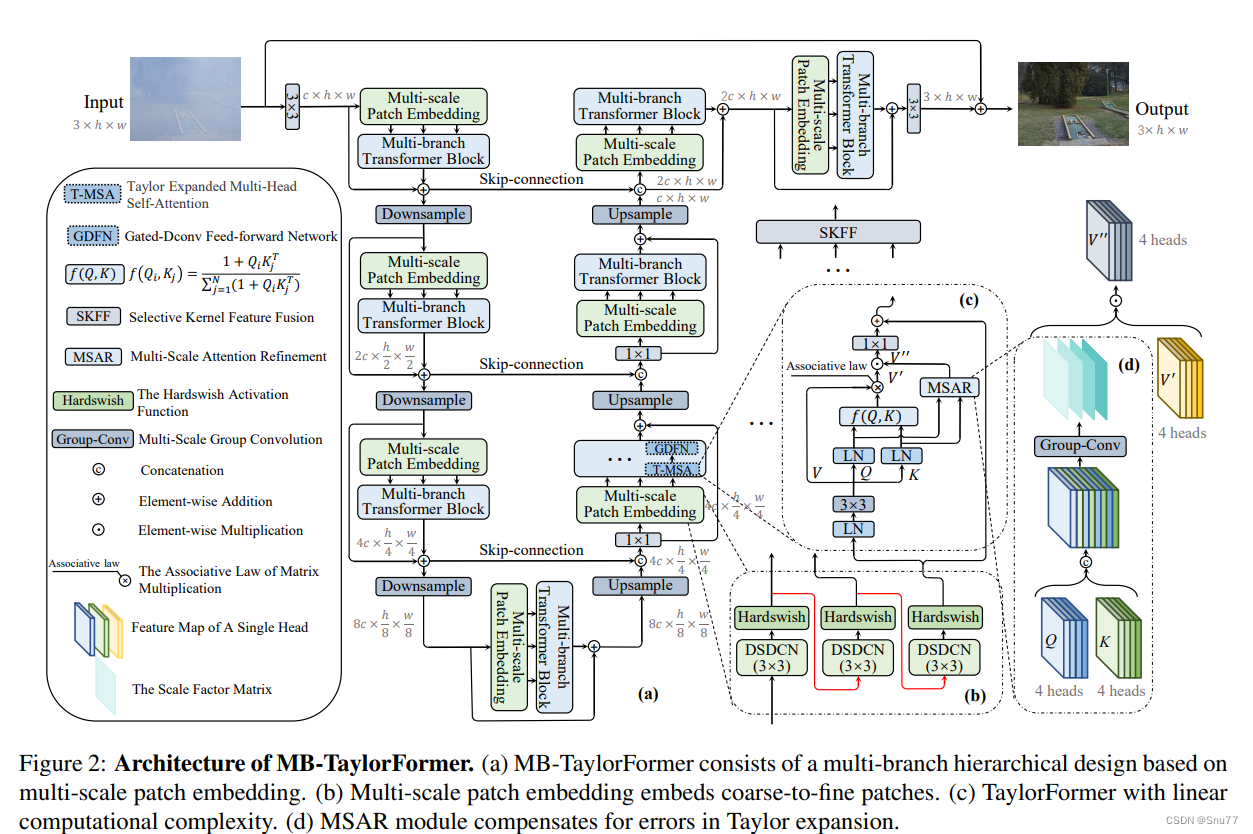
MB-TaylorFormer是一种为图像去雾设计的多分支高效Transformer网络,它通过应用泰勒公式展开的方式来近似softmax-attention机制,实现了线性的计算复杂性。该网络包含以下主要特点和创新:
1. 泰勒公式展开的自注意力机制:通过泰勓公式展开近似softmax-attention,MB-TaylorFormer能够以线性的计算复杂度处理图像,克服了传统Transformer在处理高分辨率图像时计算成本高的问题。
2. 多尺度注意力精化模块:为了补偿泰勒展开可能引入的误差,提出了一个多尺度注意力精化模块,通过学习查询和键的局部信息来纠正输出,提高了去雾效果的准确性和自然度。
3. 多分支架构与多尺度贴片嵌入:该网络引入了一种多分支架构,结合多尺度贴片嵌入策略,能够灵活地处理不同尺度的特征并捕获长距离的像素交互,这有助于在去雾任务中恢复更多细节和质量更高的图像。
总之:MB-TaylorFormer通过其创新的设计和有效的实现,在图像去雾任务中实现了高效和高性能的去雾效果,为高分辨率图像处理提供了一种新的解决方案。
2.2 泰勒公式展开的自注意力机制
MB-TaylorFormer采用泰勒公式对softmax-attention进行近似,实现了线性计算复杂度。这一机制通过将softmax函数中的指数函数用其泰勒级数展开来近似,有效降低了Transformer在处理图像时的计算负担。特别是在处理高分辨率图像时,该方法能够保持Transformer对全局信息的捕获能力,同时避免了传统softmax-attention因计算复杂度呈二次方增长而带来的计算资源消耗问题。

2.3 多尺度注意力精化模块
为了解决泰勒展开可能引入的近似误差,MB-TaylorFormer设计了一个多尺度注意力精化模块(MSAR)。这一模块通过对查询(Q)和键(K)的局部信息进行学习,并生成一个调制因子(gating tensor),用于校正和精化自注意力机制的输出。MSAR模块的引入不仅补偿了由泰勒展开引入的误差,还提升了图像去雾效果的准确性和视觉自然度,使得最终恢复的图像更加清晰和真实。
2.4 多分支架构与多尺度贴片嵌入
MB-TaylorFormer引入了一种多分支架构,配合多尺度贴片嵌入策略,增强了网络处理不同尺度特征的能力。这种架构允许网络在贴片嵌入阶段灵活地处理和融合不同尺度的特征,从而捕获从粗糙到精细的多层次语义信息。多尺度贴片嵌入通过不同尺度的重叠可变形卷积来实现,使得Transformer能够更好地适应图像中不同大小的物体和细节,从而在图像去雾任务中恢复出质量更高、细节更丰富的图像。
三、核心代码
核心代码的使用方式看下面章节四,这里说一下官方发布的版本计算量有一百多,我给降低到了18.1参数量也仅仅是略微上升,方便大家使用。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.ops.deform_conv import DeformConv2d
import numbers
import math
from einops import rearrange
import numpy as np
__all__ = ['MB_TaylorFormer']
freqs_dict = dict()
##########################################################################
def to_3d(x):
return rearrange(x, 'b c h w -> b (h w) c')
def to_4d(x, h, w):
return rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
class BiasFree_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(BiasFree_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
sigma = x.var(-1, keepdim=True, unbiased=False)
return x / torch.sqrt(sigma + 1e-5) * self.weight
class WithBias_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(WithBias_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
mu = x.mean(-1, keepdim=True)
sigma = x.var(-1, keepdim=True, unbiased=False)
return (x - mu) / torch.sqrt(sigma + 1e-5) * self.weight + self.bias
class LayerNorm(nn.Module):
def __init__(self, dim, LayerNorm_type):
super(LayerNorm, self).__init__()
if LayerNorm_type == 'BiasFree':
self.body = BiasFree_LayerNorm(dim)
else:
self.body = WithBias_LayerNorm(dim)
def forward(self, x):
h, w = x.shape[-2:]
return to_4d(self.body(to_3d(x)), h, w)
##########################################################################
## Gated-Dconv Feed-Forward Network (GDFN)
class FeedForward(nn.Module):
def __init__(self, dim, ffn_expansion_factor, bias):
super(FeedForward, self).__init__()
hidden_features = int(dim * ffn_expansion_factor)
self.project_in = nn.Conv2d(dim, hidden_features * 2, kernel_size=1, bias=bias)
self.dwconv = nn.Conv2d(hidden_features * 2, hidden_features * 2, kernel_size=3, stride=1, padding=1,
groups=hidden_features * 2, bias=bias)
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
def forward(self, x):
x = self.project_in(x)
x1, x2 = self.dwconv(x).chunk(2, dim=1)
x = F.gelu(x1) * x2
x = self.project_out(x)
return x
class refine_att(nn.Module):
"""Convolutional relative position encoding."""
def __init__(self, Ch, h, window):
super().__init__()
if isinstance(window, int):
# Set the same window size for all attention heads.
window = {window: h}
self.window = window
elif isinstance(window, dict):
self.window = window
else:
raise ValueError()
self.conv_list = nn.ModuleList()
self.head_splits = []
for cur_window, cur_head_split in window.items():
dilation = 1 # Use dilation=1 at default.
padding_size = (cur_window + (cur_window - 1) *
(dilation - 1)) // 2
cur_conv = nn.Conv2d(
cur_head_split * Ch * 2,
cur_head_split,
kernel_size=(cur_window, cur_window),
padding=(padding_size, padding_size),
dilation=(dilation, dilation),
groups=cur_head_split,
)
self.conv_list.append(cur_conv)
self.head_splits.append(cur_head_split)
self.channel_splits = [x * Ch * 2 for x in self.head_splits]
def forward(self, q, k, v, size):
"""foward function"""
B, h, N, Ch = q.shape
H, W = size
# We don't use CLS_TOKEN
q_img = q
k_img = k
v_img = v
# Shape: [B, h, H*W, Ch] -> [B, h*Ch, H, W].
q_img = rearrange(q_img, "B h (H W) Ch -> B h Ch H W", H=H, W=W)
k_img = rearrange(k_img, "B h Ch (H W) -> B h Ch H W", H=H, W=W)
qk_concat = torch.cat((q_img, k_img), 2)
qk_concat = rearrange(qk_concat, "B h Ch H W -> B (h Ch) H W", H=H, W=W)
# Split according to channels.
qk_concat_list = torch.split(qk_concat, self.channel_splits, dim=1)
qk_att_list = [
conv(x) for conv, x in zip(self.conv_list, qk_concat_list)
]
qk_att = torch.cat(qk_att_list, dim=1)
# Shape: [B, h*Ch, H, W] -> [B, h, H*W, Ch].
qk_att = rearrange(qk_att, "B (h Ch) H W -> B h (H W) Ch", h=h)
return qk_att
##########################################################################
## Multi-DConv Head Transposed Self-Attention (MDTA)
class Attention(nn.Module):
def __init__(self, dim, num_heads, bias, shared_refine_att=None, qk_norm=1):
super(Attention, self).__init__()
self.norm = qk_norm
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
# self.Leakyrelu=nn.LeakyReLU(negative_slope=0.01,inplace=True)
self.sigmoid = nn.Sigmoid()
self.qkv = nn.Conv2d(dim, dim * 3, kernel_size=1, bias=bias)
self.qkv_dwconv = nn.Conv2d(dim * 3, dim * 3, kernel_size=3, stride=1, padding=1, groups=dim * 3, bias=bias)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
if num_heads == 8:
crpe_window = {
3: 2,
5: 3,
7: 3
}
elif num_heads == 1:
crpe_window = {
3: 1,
}
elif num_heads == 2:
crpe_window = {
3: 2,
}
elif num_heads == 4:
crpe_window = {
3: 2,
5: 2,
}
self.refine_att = refine_att(Ch=dim // num_heads,
h=num_heads,
window=crpe_window)
def forward(self, x):
b, c, h, w = x.shape
qkv = self.qkv_dwconv(self.qkv(x))
q, k, v = qkv.chunk(3, dim=1)
q = rearrange(q, 'b (head c) h w -> b head (h w) c', head=self.num_heads)
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head (h w) c', head=self.num_heads)
# q = torch.nn.functional.normalize(q, dim=-1)
q_norm = torch.norm(q, p=2, dim=-1, keepdim=True) / self.norm + 1e-6
q = torch.div(q, q_norm)
k_norm = torch.norm(k, p=2, dim=-2, keepdim=True) / self.norm + 1e-6
k = torch.div(k, k_norm)
# k = torch.nn.functional.normalize(k, dim=-2)
refine_weight = self.refine_att(q, k, v, size=(h, w))
# refine_weight=self.Leakyrelu(refine_weight)
refine_weight = self.sigmoid(refine_weight)
attn = k @ v
# attn = attn.softmax(dim=-1)
# print(torch.sum(k, dim=-1).unsqueeze(3).shape)
out_numerator = torch.sum(v, dim=-2).unsqueeze(2) + (q @ attn)
out_denominator = torch.full((h * w, c // self.num_heads), h * w).to(q.device) \
+ q @ torch.sum(k, dim=-1).unsqueeze(3).repeat(1, 1, 1, c // self.num_heads) + 1e-6
# out=torch.div(out_numerator,out_denominator)*self.temperature*refine_weight
out = torch.div(out_numerator, out_denominator) * self.temperature
out = out * refine_weight
out = rearrange(out, 'b head (h w) c-> b (head c) h w', head=self.num_heads, h=h, w=w)
out = self.project_out(out)
return out
##########################################################################
class TransformerBlock(nn.Module):
def __init__(self, dim, num_heads, ffn_expansion_factor, bias, LayerNorm_type, shared_refine_att=None, qk_norm=1):
super(TransformerBlock, self).__init__()
self.norm1 = LayerNorm(dim, LayerNorm_type)
self.attn = Attention(dim, num_heads, bias, shared_refine_att=shared_refine_att, qk_norm=qk_norm)
self.norm2 = LayerNorm(dim, LayerNorm_type)
self.ffn = FeedForward(dim, ffn_expansion_factor, bias)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = x + self.ffn(self.norm2(x))
return x
class MHCAEncoder(nn.Module):
"""Multi-Head Convolutional self-Attention Encoder comprised of `MHCA`
blocks."""
def __init__(
self,
dim,
num_layers=1,
num_heads=8,
ffn_expansion_factor=2.66,
bias=False,
LayerNorm_type='BiasFree',
qk_norm=1
):
super().__init__()
self.num_layers = num_layers
self.MHCA_layers = nn.ModuleList([
TransformerBlock(
dim,
num_heads=num_heads,
ffn_expansion_factor=ffn_expansion_factor,
bias=bias,
LayerNorm_type=LayerNorm_type,
qk_norm=qk_norm
) for idx in range(self.num_layers)
])
def forward(self, x, size):
"""foward function"""
H, W = size
B = x.shape[0]
# return x's shape : [B, N, C] -> [B, C, H, W]
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
for layer in self.MHCA_layers:
x = layer(x)
return x
class ResBlock(nn.Module):
"""Residual block for convolutional local feature."""
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.Hardswish,
norm_layer=nn.BatchNorm2d,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
# self.act0 = act_layer()
self.conv1 = Conv2d_BN(in_features,
hidden_features,
act_layer=act_layer)
self.dwconv = nn.Conv2d(
hidden_features,
hidden_features,
3,
1,
1,
bias=False,
groups=hidden_features,
)
# self.norm = norm_layer(hidden_features)
self.act = act_layer()
self.conv2 = Conv2d_BN(hidden_features, out_features)
self.apply(self._init_weights)
def _init_weights(self, m):
"""
initialization
"""
if isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
"""foward function"""
identity = x
# x=self.act0(x)
feat = self.conv1(x)
feat = self.dwconv(feat)
# feat = self.norm(feat)
feat = self.act(feat)
feat = self.conv2(feat)
return identity + feat
class MHCA_stage(nn.Module):
"""Multi-Head Convolutional self-Attention stage comprised of `MHCAEncoder`
layers."""
def __init__(
self,
embed_dim,
out_embed_dim,
num_layers=1,
num_heads=8,
ffn_expansion_factor=2.66,
num_path=4,
bias=False,
LayerNorm_type='BiasFree',
qk_norm=1
):
super().__init__()
self.mhca_blks = nn.ModuleList([
MHCAEncoder(
embed_dim,
num_layers,
num_heads,
ffn_expansion_factor=ffn_expansion_factor,
bias=bias,
LayerNorm_type=LayerNorm_type,
qk_norm=qk_norm
) for _ in range(num_path)
])
self.aggregate = SKFF(embed_dim, height=num_path)
# self.InvRes = ResBlock(in_features=embed_dim, out_features=embed_dim)
# self.aggregate = Conv2d_aggregate(embed_dim * (num_path + 1),
# out_embed_dim,
# act_layer=nn.Hardswish)
def forward(self, inputs):
"""foward function"""
# att_outputs = [self.InvRes(inputs[0])]
att_outputs = []
for x, encoder in zip(inputs, self.mhca_blks):
# [B, C, H, W] -> [B, N, C]
_, _, H, W = x.shape
x = x.flatten(2).transpose(1, 2).contiguous()
att_outputs.append(encoder(x, size=(H, W)))
# out_concat = torch.cat(att_outputs, dim=1)
out = self.aggregate(att_outputs)
return out
##########################################################################
## Overlapped image patch embedding with 3x3 Conv
class Conv2d_BN(nn.Module):
def __init__(
self,
in_ch,
out_ch,
kernel_size=1,
stride=1,
pad=0,
dilation=1,
groups=1,
bn_weight_init=1,
norm_layer=nn.BatchNorm2d,
act_layer=None,
):
super().__init__()
self.conv = torch.nn.Conv2d(in_ch,
out_ch,
kernel_size,
stride,
pad,
dilation,
groups,
bias=False)
# self.bn = norm_layer(out_ch)
# torch.nn.init.constant_(self.bn.weight, bn_weight_init)
# torch.nn.init.constant_(self.bn.bias, 0)
for m in self.modules():
if isinstance(m, nn.Conv2d):
# Note that there is no bias due to BN
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(mean=0.0, std=np.sqrt(2.0 / fan_out))
self.act_layer = act_layer() if act_layer is not None else nn.Identity()
def forward(self, x):
x = self.conv(x)
# x = self.bn(x)
x = self.act_layer(x)
return x
class SKFF(nn.Module):
def __init__(self, in_channels, height=2, reduction=8, bias=False):
super(SKFF, self).__init__()
self.height = height
d = max(int(in_channels / reduction), 4)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_du = nn.Sequential(nn.Conv2d(in_channels, d, 1, padding=0, bias=bias), nn.PReLU())
self.fcs = nn.ModuleList([])
for i in range(self.height):
self.fcs.append(nn.Conv2d(d, in_channels, kernel_size=1, stride=1, bias=bias))
self.softmax = nn.Softmax(dim=1)
def forward(self, inp_feats):
batch_size = inp_feats[0].shape[0]
n_feats = inp_feats[0].shape[1]
inp_feats = torch.cat(inp_feats, dim=1)
inp_feats = inp_feats.view(batch_size, self.height, n_feats, inp_feats.shape[2], inp_feats.shape[3])
feats_U = torch.sum(inp_feats, dim=1)
feats_S = self.avg_pool(feats_U)
feats_Z = self.conv_du(feats_S)
attention_vectors = [fc(feats_Z) for fc in self.fcs]
attention_vectors = torch.cat(attention_vectors, dim=1)
attention_vectors = attention_vectors.view(batch_size, self.height, n_feats, 1, 1)
# stx()
attention_vectors = self.softmax(attention_vectors)
feats_V = torch.sum(inp_feats * attention_vectors, dim=1)
return feats_V
class DWConv2d_BN(nn.Module):
def __init__(
self,
in_ch,
out_ch,
kernel_size=1,
stride=1,
norm_layer=nn.BatchNorm2d,
act_layer=nn.Hardswish,
bn_weight_init=1,
offset_clamp=(-1, 1)
):
super().__init__()
# dw
# self.conv=torch.nn.Conv2d(in_ch,out_ch,kernel_size,stride,(kernel_size - 1) // 2,bias=False,)
# self.mask_generator = nn.Sequential(nn.Conv2d(in_channels=in_ch, out_channels=in_ch, kernel_size=3,
# stride=1, padding=1, bias=False, groups=in_ch),
# nn.Conv2d(in_channels=in_ch, out_channels=9,
# kernel_size=1,
# stride=1, padding=0, bias=False)
# )
self.offset_clamp = offset_clamp
self.offset_generator = nn.Sequential(nn.Conv2d(in_channels=in_ch, out_channels=in_ch, kernel_size=3,
stride=1, padding=1, bias=False, groups=in_ch),
nn.Conv2d(in_channels=in_ch, out_channels=18,
kernel_size=1,
stride=1, padding=0, bias=False)
)
self.dcn = DeformConv2d(
in_channels=in_ch,
out_channels=in_ch,
kernel_size=3,
stride=1,
padding=1,
bias=False,
groups=in_ch
) # .cuda(7)
self.pwconv = nn.Conv2d(in_ch, out_ch, 1, 1, 0, bias=False)
# self.bn = norm_layer(out_ch)
self.act = act_layer() if act_layer is not None else nn.Identity()
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2.0 / n))
if m.bias is not None:
m.bias.data.zero_()
# print(m)
# elif isinstance(m, nn.BatchNorm2d):
# m.weight.data.fill_(bn_weight_init)
# m.bias.data.zero_()
def forward(self, x):
# x=self.conv(x)
# x = self.bn(x)
# x = self.act(x)
# mask= torch.sigmoid(self.mask_generator(x))
# print('1')
offset = self.offset_generator(x)
# print('2')
if self.offset_clamp:
offset = torch.clamp(offset, min=self.offset_clamp[0], max=self.offset_clamp[1]) # .cuda(7)1
# print(offset)
# print('3')
# x=x.cuda(7)
x = self.dcn(x, offset)
# x=x.cpu()
# print('4')
x = self.pwconv(x)
# print('5')
# x = self.bn(x)
x = self.act(x)
return x
class DWCPatchEmbed(nn.Module):
"""Depthwise Convolutional Patch Embedding layer Image to Patch
Embedding."""
def __init__(self,
in_chans=3,
embed_dim=768,
patch_size=16,
stride=1,
idx=0,
act_layer=nn.Hardswish,
offset_clamp=(-1, 1)):
super().__init__()
self.patch_conv = DWConv2d_BN(
in_chans,
embed_dim,
kernel_size=patch_size,
stride=stride,
act_layer=act_layer,
offset_clamp=offset_clamp
)
"""
self.patch_conv = DWConv2d_BN(
in_chans,
embed_dim,
kernel_size=patch_size,
stride=stride,
act_layer=act_layer,
)
"""
def forward(self, x):
"""foward function"""
x = self.patch_conv(x)
return x
class Patch_Embed_stage(nn.Module):
"""Depthwise Convolutional Patch Embedding stage comprised of
`DWCPatchEmbed` layers."""
def __init__(self, in_chans, embed_dim, num_path=4, isPool=False, offset_clamp=(-1, 1)):
super(Patch_Embed_stage, self).__init__()
self.patch_embeds = nn.ModuleList([
DWCPatchEmbed(
in_chans=in_chans if idx == 0 else embed_dim,
embed_dim=embed_dim,
patch_size=3,
stride=1,
idx=idx,
offset_clamp=offset_clamp
) for idx in range(num_path)
])
def forward(self, x):
"""foward function"""
att_inputs = []
for pe in self.patch_embeds:
x = pe(x)
att_inputs.append(x)
return att_inputs
class OverlapPatchEmbed(nn.Module):
def __init__(self, in_c=3, embed_dim=48, bias=False):
super(OverlapPatchEmbed, self).__init__()
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=3, stride=1, padding=1, bias=bias)
# self.proj_dw = nn.Conv2d(in_c, in_c, kernel_size=3, stride=1, padding=1,groups=in_c, bias=bias)
# self.proj_pw = nn.Conv2d(in_c, embed_dim, kernel_size=1, stride=1, padding=0, bias=bias)
# self.bn=nn.BatchNorm2d(embed_dim)
# self.act=nn.Hardswish()
def forward(self, x):
x = self.proj(x)
# x = self.proj_dw(x)
# x= self.proj_pw(x)
# x=self.bn(x)
# x=self.act(x)
return x
##########################################################################
## Resizing modules
class Downsample(nn.Module):
def __init__(self, input_feat, out_feat):
super(Downsample, self).__init__()
self.body = nn.Sequential( # nn.Conv2d(n_feat, n_feat // 2, kernel_size=3, stride=1, padding=1, bias=False),
# dw
nn.Conv2d(input_feat, input_feat, kernel_size=3, stride=1, padding=1, groups=input_feat, bias=False, ),
# pw-linear
nn.Conv2d(input_feat, out_feat // 4, 1, 1, 0, bias=False),
# nn.BatchNorm2d(n_feat // 2),
# nn.Hardswish(),
nn.PixelUnshuffle(2))
def forward(self, x):
return self.body(x)
class Upsample(nn.Module):
def __init__(self, input_feat, out_feat):
super(Upsample, self).__init__()
self.body = nn.Sequential( # nn.Conv2d(n_feat, n_feat*2, kernel_size=3, stride=1, padding=1, bias=False),
# dw
nn.Conv2d(input_feat, input_feat, kernel_size=3, stride=1, padding=1, groups=input_feat, bias=False, ),
# pw-linear
nn.Conv2d(input_feat, out_feat * 4, 1, 1, 0, bias=False),
# nn.BatchNorm2d(n_feat*2),
# nn.Hardswish(),
nn.PixelShuffle(2))
def forward(self, x):
return self.body(x)
##########################################################################
##---------- Restormer -----------------------
class MB_TaylorFormer(nn.Module):
def __init__(self,
inp_channels=3,
dim=[6, 12, 24, 36],
num_blocks=[1, 1, 1, 1],
heads=[1, 1, 1, 1],
bias=False,
dual_pixel_task=True,
num_path=[1, 1, 1, 1], ## True for dual-pixel defocus deblurring only. Also set inp_channels=6
qk_norm=1,
offset_clamp=(-1, 1)
):
super(MB_TaylorFormer, self).__init__()
self.patch_embed = OverlapPatchEmbed(inp_channels, dim[0])
self.patch_embed_encoder_level1 = Patch_Embed_stage(dim[0], dim[0], num_path=num_path[0], isPool=False,
offset_clamp=offset_clamp)
self.encoder_level1 = MHCA_stage(dim[0], dim[0], num_layers=num_blocks[0], num_heads=heads[0],
ffn_expansion_factor=2.66, num_path=num_path[0],
bias=False, LayerNorm_type='BiasFree', qk_norm=qk_norm)
self.down1_2 = Downsample(dim[0], dim[1]) ## From Level 1 to Level 2
self.patch_embed_encoder_level2 = Patch_Embed_stage(dim[1], dim[1], num_path=num_path[1], isPool=False,
offset_clamp=offset_clamp)
self.encoder_level2 = MHCA_stage(dim[1], dim[1], num_layers=num_blocks[1], num_heads=heads[1],
ffn_expansion_factor=2.66,
num_path=num_path[1], bias=False, LayerNorm_type='BiasFree', qk_norm=qk_norm)
self.down2_3 = Downsample(dim[1], dim[2]) ## From Level 2 to Level 3
self.patch_embed_encoder_level3 = Patch_Embed_stage(dim[2], dim[2], num_path=num_path[2],
isPool=False, offset_clamp=offset_clamp)
self.encoder_level3 = MHCA_stage(dim[2], dim[2], num_layers=num_blocks[2], num_heads=heads[2],
ffn_expansion_factor=2.66,
num_path=num_path[2], bias=False, LayerNorm_type='BiasFree', qk_norm=qk_norm)
self.down3_4 = Downsample(dim[2], dim[3]) ## From Level 3 to Level 4
self.patch_embed_latent = Patch_Embed_stage(dim[3], dim[3], num_path=num_path[3],
isPool=False, offset_clamp=offset_clamp)
self.latent = MHCA_stage(dim[3], dim[3], num_layers=num_blocks[3], num_heads=heads[3],
ffn_expansion_factor=2.66, num_path=num_path[3], bias=False,
LayerNorm_type='BiasFree', qk_norm=qk_norm)
self.up4_3 = Upsample(int(dim[3]), dim[2]) ## From Level 4 to Level 3
self.reduce_chan_level3 = nn.Sequential(
nn.Conv2d(dim[2] * 2, dim[2], 1, 1, 0, bias=bias),
# nn.BatchNorm2d(dim * 2**2),
# nn.Hardswish(),
)
self.patch_embed_decoder_level3 = Patch_Embed_stage(dim[2], dim[2], num_path=num_path[2],
isPool=False, offset_clamp=offset_clamp)
self.decoder_level3 = MHCA_stage(dim[2], dim[2], num_layers=num_blocks[2], num_heads=heads[2],
ffn_expansion_factor=2.66, num_path=num_path[2], bias=False,
LayerNorm_type='BiasFree', qk_norm=qk_norm)
self.up3_2 = Upsample(int(dim[2]), dim[1]) ## From Level 3 to Level 2
self.reduce_chan_level2 = nn.Sequential(
nn.Conv2d(dim[1] * 2, dim[1], 1, 1, 0, bias=bias),
# nn.BatchNorm2d( dim * 2),
# nn.Hardswish(),
)
self.patch_embed_decoder_level2 = Patch_Embed_stage(dim[1], dim[1], num_path=num_path[1],
isPool=False, offset_clamp=offset_clamp)
self.decoder_level2 = MHCA_stage(dim[1], dim[1], num_layers=num_blocks[1], num_heads=heads[1],
ffn_expansion_factor=2.66, num_path=num_path[1], bias=False,
LayerNorm_type='BiasFree', qk_norm=qk_norm)
self.up2_1 = Upsample(int(dim[1]), dim[0]) ## From Level 2 to Level 1 (NO 1x1 conv to reduce channels)
self.patch_embed_decoder_level1 = Patch_Embed_stage(dim[1], dim[1], num_path=num_path[0],
isPool=False, offset_clamp=offset_clamp)
self.decoder_level1 = MHCA_stage(dim[1], dim[1], num_layers=num_blocks[0], num_heads=heads[0],
ffn_expansion_factor=2.66, num_path=num_path[0], bias=False,
LayerNorm_type='BiasFree', qk_norm=qk_norm)
self.patch_embed_refinement = Patch_Embed_stage(dim[1], dim[1], num_path=num_path[0],
isPool=False, offset_clamp=offset_clamp)
self.refinement = MHCA_stage(dim[1], dim[1], num_layers=num_blocks[0], num_heads=heads[0],
ffn_expansion_factor=2.66, num_path=num_path[0], bias=False,
LayerNorm_type='BiasFree', qk_norm=qk_norm)
#### For Dual-Pixel Defocus Deblurring Task ####
self.dual_pixel_task = dual_pixel_task
if self.dual_pixel_task:
self.skip_conv = nn.Conv2d(dim[0], dim[1], kernel_size=1, bias=bias)
###########################
# self.output = nn.Conv2d(dim*2**1, 3, kernel_size=3, stride=1, padding=1, bias=False)
self.output = nn.Sequential( # nn.Conv2d(n_feat, n_feat*2, kernel_size=3, stride=1, padding=1, bias=False),
# nn.BatchNorm2d(dim*2),
# nn.Hardswish(),
nn.Conv2d(dim[1], 3, kernel_size=3, stride=1, padding=1, bias=False, ),
)
def forward(self, inp_img):
inp_enc_level1 = self.patch_embed(inp_img)
inp_enc_level1_list = self.patch_embed_encoder_level1(inp_enc_level1)
out_enc_level1 = self.encoder_level1(inp_enc_level1_list) + inp_enc_level1
# out_enc_level1 = self.encoder_level1(inp_enc_level1_list)
inp_enc_level2 = self.down1_2(out_enc_level1)
inp_enc_level2_list = self.patch_embed_encoder_level2(inp_enc_level2)
out_enc_level2 = self.encoder_level2(inp_enc_level2_list) + inp_enc_level2
inp_enc_level3 = self.down2_3(out_enc_level2)
inp_enc_level3_list = self.patch_embed_encoder_level3(inp_enc_level3)
out_enc_level3 = self.encoder_level3(inp_enc_level3_list) + inp_enc_level3
inp_enc_level4 = self.down3_4(out_enc_level3)
inp_latent = self.patch_embed_latent(inp_enc_level4)
latent = self.latent(inp_latent) + inp_enc_level4
inp_dec_level3 = self.up4_3(latent)
inp_dec_level3 = torch.cat([inp_dec_level3, out_enc_level3], 1)
inp_dec_level3 = self.reduce_chan_level3(inp_dec_level3)
inp_dec_level3_list = self.patch_embed_decoder_level3(inp_dec_level3)
out_dec_level3 = self.decoder_level3(inp_dec_level3_list) + inp_dec_level3
inp_dec_level2 = self.up3_2(out_dec_level3)
inp_dec_level2 = torch.cat([inp_dec_level2, out_enc_level2], 1)
inp_dec_level2 = self.reduce_chan_level2(inp_dec_level2)
inp_dec_level2_list = self.patch_embed_decoder_level2(inp_dec_level2)
out_dec_level2 = self.decoder_level2(inp_dec_level2_list) + inp_dec_level2
inp_dec_level1 = self.up2_1(out_dec_level2)
inp_dec_level1 = torch.cat([inp_dec_level1, out_enc_level1], 1)
inp_dec_level1_list = self.patch_embed_decoder_level1(inp_dec_level1)
out_dec_level1 = self.decoder_level1(inp_dec_level1_list) + inp_dec_level1
inp_latent_list = self.patch_embed_refinement(out_dec_level1)
out_dec_level1 = self.refinement(inp_latent_list) + out_dec_level1
# nn.Hardswish()
#### For Dual-Pixel Defocus Deblurring Task ####
if self.dual_pixel_task:
out_dec_level1 = out_dec_level1 + self.skip_conv(inp_enc_level1)
out_dec_level1 = self.output(out_dec_level1)
###########################
else:
out_dec_level1 = self.output(out_dec_level1) + inp_img
return out_dec_level1
def count_param(model):
param_count = 0
for param in model.parameters():
param_count += param.view(-1).size()[0]
return param_count
if __name__ == "__main__":
from thop import profile
model = MB_TaylorFormer()
model.eval()
print("params", count_param(model))
inputs = torch.randn(1, 3, 640, 640)
output = model(inputs)
print(output.size())四、代码的使用方式
4.1 修改一
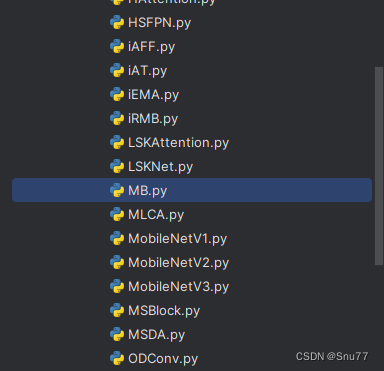
第一还是建立文件,我们找到如下ultralytics/nn/modules文件夹下建立一个目录名字呢就是'Addmodules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。
4.2 修改二
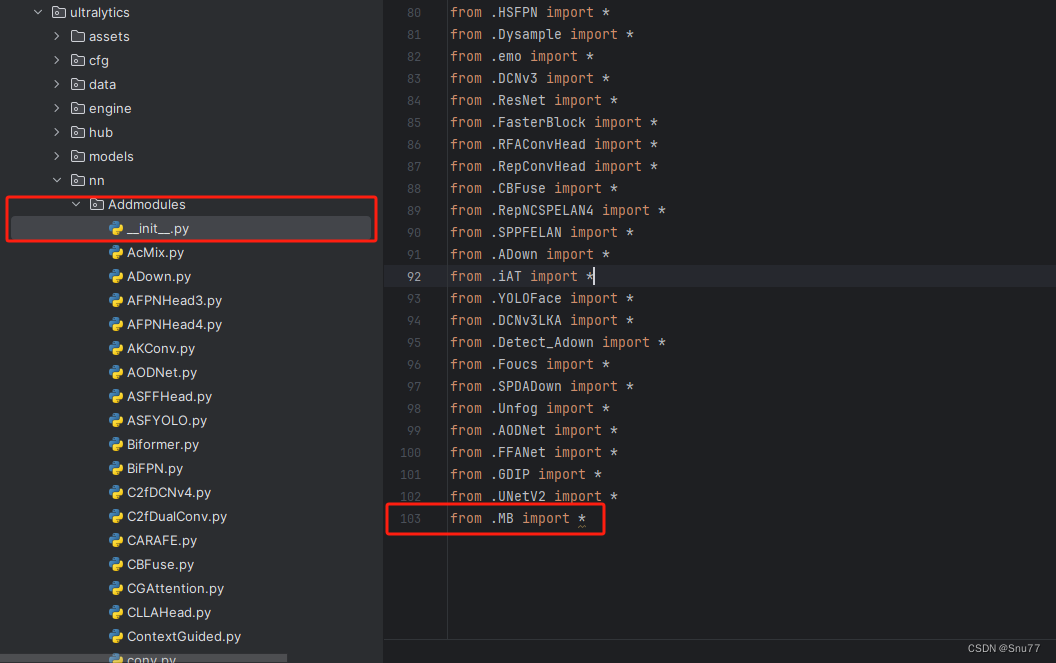
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。
4.3 修改三
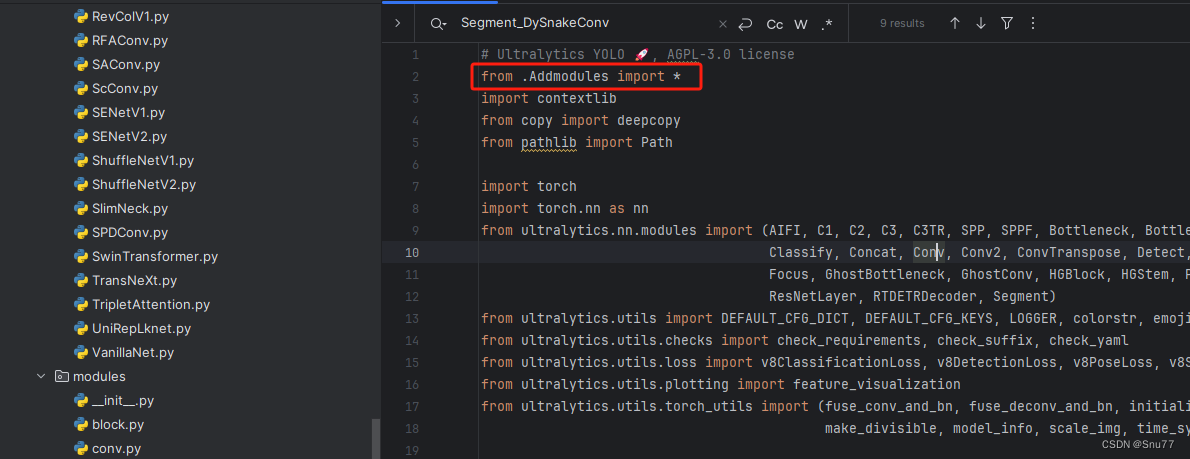
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块(用群内的文件的话已经有了无需重新导入直接开始第四步即可)!
从今天开始以后的教程就都统一成这个样子了,因为我默认大家用了我群内的文件来进行修改!!
关闭混合精度验证(可能需要)!
找到'ultralytics/engine/validator.py'文件找到 'class BaseValidator:' 然后在其'__call__'中 self.args.half = self.device.type != 'cpu' # force FP16 val during training的一行代码下面加上self.args.half = False
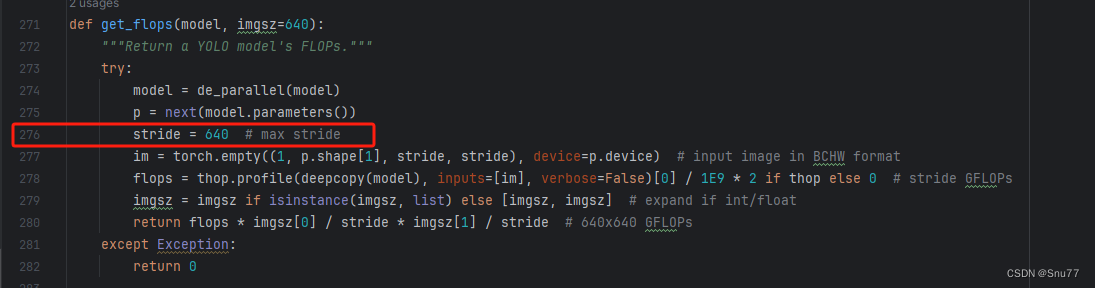
打印计算量的问题!
计算的GFLOPs计算异常不打印,所以需要额外修改一处, 我们找到如下文件'ultralytics/utils/torch_utils.py'文件内有如下的代码按照如下的图片进行修改,有一个get_flops的函数我们直接用我给的代码全部替换!
def get_flops(model, imgsz=640):
"""Return a YOLO model's FLOPs."""
if not thop:
return 0.0 # if not installed return 0.0 GFLOPs
try:
model = de_parallel(model)
p = next(model.parameters())
if not isinstance(imgsz, list):
imgsz = [imgsz, imgsz] # expand if int/float
try:
# Use stride size for input tensor
stride = 640
im = torch.empty((1, 3, stride, stride), device=p.device) # input image in BCHW format
flops = thop.profile(deepcopy(model), inputs=[im], verbose=False)[0] / 1e9 * 2 # stride GFLOPs
return flops * imgsz[0] / stride * imgsz[1] / stride # imgsz GFLOPs
except Exception:
# Use actual image size for input tensor (i.e. required for RTDETR models)
im = torch.empty((1, p.shape[1], *imgsz), device=p.device) # input image in BCHW format
return thop.profile(deepcopy(model), inputs=[im], verbose=False)[0] / 1e9 * 2 # imgsz GFLOPs
except Exception:
return 0.0
到此就修改完成了,大家可以复制下面的yaml文件运行。
五、yaml文件和运行记录
5.1 yaml文件
训练信息:YOLOv10n-MBformer summary: 737 layers, 2783444 parameters, 2783428 gradients, 18.3 GFLOPs
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv10 object detection model. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov10n.yaml' will call yolov10.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, MB_TaylorFormer, []] # 0-P1/2
- [-1, 1, Conv, [64, 3, 2]] # 1-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 2-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 4-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, SCDown, [512, 3, 2]] # 6-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, SCDown, [1024, 3, 2]] # 8-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 10
- [-1, 1, PSA, [1024]] # 11
# YOLOv10.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 7], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 14
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 5], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 20 (P4/16-medium)
- [-1, 1, SCDown, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 3, C2fCIB, [1024, True, True]] # 23 (P5/32-large)
- [[17, 20, 23], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
5.2 训练代码
大家可以创建一个py文件将我给的代码复制粘贴进去,配置好自己的文件路径即可运行。
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/v8/yolov8-C2f-FasterBlock.yaml')
# model.load('yolov8n.pt') # loading pretrain weights
model.train(data=r'替换数据集yaml文件地址',
# 如果大家任务是其它的'ultralytics/cfg/default.yaml'找到这里修改task可以改成detect, segment, classify, pose
cache=False,
imgsz=640,
epochs=150,
single_cls=False, # 是否是单类别检测
batch=4,
close_mosaic=10,
workers=0,
device='0',
optimizer='SGD', # using SGD
# resume='', # 如过想续训就设置last.pt的地址
amp=False, # 如果出现训练损失为Nan可以关闭amp
project='runs/train',
name='exp',
)5.3 训练过程截图
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv10改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv10改进系列专栏——本专栏持续复习各种顶会内容——科研必备