文章目录
- startupProbe探针
- startupProbe说明
- 示例配置
- 参数解释
- 使用场景说明
- 实例——要求: 容器在8秒内完成启动,否则杀死对应容器
- 工作流程说明
- timeoutSeconds: 和 periodSeconds: 参数顺序说明
- livenessProbe探针
- livenessProbe说明
- 示例配置
- 参数解释
- 使用场景说明
- 实例——题目要求:如果发现业务4秒后无响应,杀死对应容器,并进行重启
- 工作流程说明
- readnessProbe探针
- readnessProbe说明
- 示例配置
- 参数解释
- 使用场景说明
- 实例——如果发现业务3秒后无响应,访问流量将不会传值该容器,5秒内如果回复响应,访问流量将继续转发至该容器
- 工作流程说明
- 一个完整的包含3个探针的实例yaml文件
startupProbe探针
startupProbe是 Kubernetes 中的一种探针,用于检测容器的启动状态。- 如果容器未能在指定的时间内启动,Kubernetes 将杀死并重启该容器。【简单来说startupProbe 用于检测容器是否已经成功启动。如果
startupProbe失败,Kubernetes 将杀死容器并根据策略进行重启。】 startupProbe主要用于那些启动时间较长的应用,以确保它们在完全启动之前不会被其他探针(如livenessProbe和readinessProbe)误判为失败。也就是说,它通常用于那些启动时间较长的应用程序,以确保在应用程序完全启动之前不会触发 livenessProbe 和 readinessProbe。
- 如果容器未能在指定的时间内启动,Kubernetes 将杀死并重启该容器。【简单来说startupProbe 用于检测容器是否已经成功启动。如果
startupProbe说明
-
以下是
startupProbe的常用参数及其说明: -
- httpGet: 使用 HTTP GET 请求进行探测。
- path: 要探测的 HTTP 路径。
- port: 要探测的端口。
- scheme: 使用的协议(HTTP 或 HTTPS)。
示例:
httpGet: path: / port: 8080 scheme: HTTP - httpGet: 使用 HTTP GET 请求进行探测。
-
- tcpSocket: 使用 TCP 检查进行探测。
- port: 要探测的端口。
示例:
tcpSocket: port: 8080 - tcpSocket: 使用 TCP 检查进行探测。
-
- exec: 使用命令执行进行探测。
- command: 要执行的命令及其参数。
示例:
exec: command: - cat - /etc/hosts - exec: 使用命令执行进行探测。
-
- initialDelaySeconds: 在容器启动后等待多长时间开始进行第一次检查。
- 类型:整数
- 默认值:0
- initialDelaySeconds: 在容器启动后等待多长时间开始进行第一次检查。
-
- timeoutSeconds: 探针等待响应的时间。如果超过这个时间没有响应,则认为探针失败。
- 类型:整数
- 默认值:1
- timeoutSeconds: 探针等待响应的时间。如果超过这个时间没有响应,则认为探针失败。
-
- periodSeconds: 探针之间的间隔时间,即每隔多少秒进行一次检查。
- 类型:整数
- 默认值:10
-
- successThreshold: 探针连续成功的次数,只有达到这个次数才认为探针成功。
- 类型:整数
- 默认值:1
-
- failureThreshold: 探针连续失败的次数,只有达到这个次数才认为探针失败,并触发容器重启。
- 类型:整数
- 默认值:3
示例配置
- 以下是一个完整的
startupProbe配置示例:
startupProbe:
httpGet:
path: /
port: 8080
scheme: HTTP
initialDelaySeconds: 0
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
参数解释
- httpGet: 使用 HTTP GET 请求检查
/路径,端口为 8080,使用 HTTP 协议。 - initialDelaySeconds: 0: 容器启动后立即开始进行探测。
- timeoutSeconds: 5: 探针等待5秒以获取响应。如果超过5秒没有响应,则认为探针失败。
- periodSeconds: 10: 每10秒进行一次探测。
- successThreshold: 1: 探针只需一次成功就认为探测通过。
- failureThreshold: 3: 探针需要连续三次失败才认为探测失败,并触发容器重启。
使用场景说明
-
使用场景一般有下面2个:
- 启动时间较长的应用:对于启动时间较长的应用,使用
startupProbe可以确保它们在完全启动之前不会被误判为失败。 - 避免误判:在应用启动过程中,
livenessProbe和readinessProbe可能会误判应用为失败。使用startupProbe可以避免这种情况。
- 启动时间较长的应用:对于启动时间较长的应用,使用
-
通过合理配置
startupProbe,可以确保容器在启动过程中得到正确的检测和处理,避免因启动时间较长而导致的不必要的重启。
实例——要求: 容器在8秒内完成启动,否则杀死对应容器
- 根据题意,最终参数如下:
这种配置确保了探针能够每2秒检查一次容器状态,并且在容器未能在8秒内启动完成时杀死容器。探针等待4秒以获取响应,如果超过4秒没有响应,则认为探针失败。探针需要连续两次失败(即8秒内两次失败)才会将容器标记为启动失败并触发重启。
startupProbe:
exec:
command:
- cat
- /etc/hosts
initialDelaySeconds: 0
timeoutSeconds: 4
periodSeconds: 2
successThreshold: 1
failureThreshold: 2
工作流程说明
- 解析
startupProbe 【只启动一次】——容器启动的时候完成探针,失败就kill
exec: 通过在容器内执行命令来检查应用的健康状况。
command: 要执行的命令。
- cat
- /etc/hosts
`initialDelaySeconds 0` 用于指定在容器启动后多长时间开始进行首次健康检查。
它的作用是让容器有足够的时间来完成初始化操作,避免在容器还未完全启动时就进行健康检查,从而导致误判。
例如,如果将 `initialDelaySeconds` 设置为 `30`,那么 Kubernetes 会在容器启动后的 30 秒才开始进行第一次 `startupProbe` 检查。
`timeoutSeconds 4`: 探测的超时时间(秒)。
`periodSeconds 2`: 执行探测的周期(秒)。
`successThreshold 1`: 探测成功的阈值。连续成功达到这个阈值后,容器被认为已经成功启动。默认值是 1。如果设置为 1,只要有一次成功的探测,容器就会被认为启动成功。
`failureThreshold 2`: 探测失败的阈值。在达到这个阈值之前,容器不会被认为启动失败。
-
参数解释
-
exec: 使用命令执行方式进行探测,这里使用
ls /mnt命令。- command: 定义了要执行的命令,这里是
ls /mnt。
- command: 定义了要执行的命令,这里是
-
initialDelaySeconds: 在容器启动后等待多长时间开始进行第一次检查。
- 在你的配置中,
initialDelaySeconds: 0表示容器启动后立即开始进行探测。
- 在你的配置中,
-
timeoutSeconds: 探针等待响应的时间。如果超过这个时间没有响应,则认为探针失败。
- 在你的配置中,
timeoutSeconds: 4表示探针等待4秒以获取响应。如果超过4秒没有响应,则认为探针失败。
- 在你的配置中,
-
periodSeconds: 探针之间的间隔时间,即每隔多少秒进行一次检查。
- 在你的配置中,
periodSeconds: 2表示每2秒进行一次探测。
- 在你的配置中,
-
successThreshold: 探针连续成功的次数,只有达到这个次数才认为探针成功。
- 在你的配置中,
successThreshold: 1表示探针只需一次成功就认为探测通过。
- 在你的配置中,
-
failureThreshold: 探针连续失败的次数,只有达到这个次数才认为探针失败,并触发容器重启。
- 在你的配置中,
failureThreshold: 2表示探针需要连续两次失败才认为探测失败。
- 在你的配置中,
-
-
工作流程
-
- 容器启动后,探针会立即开始进行探测(
initialDelaySeconds: 0)。
- 容器启动后,探针会立即开始进行探测(
-
- 每2秒,探针会执行一次
ls /mnt命令(periodSeconds: 2)。
- 每2秒,探针会执行一次
-
- 如果探针在4秒内没有成功执行
ls /mnt命令(timeoutSeconds: 4),则认为探针失败。
- 如果探针在4秒内没有成功执行
-
- 探针需要连续两次失败(
failureThreshold: 2)才会触发容器重启。
- 探针需要连续两次失败(
-
-
适用场景
- initialDelaySeconds: 0:适用于希望容器启动后立即开始探测的场景。
- timeoutSeconds: 4:适用于希望容器在执行命令时有足够的时间响应。
- periodSeconds: 2:适用于希望频繁检查容器启动状态的情况。
- successThreshold: 1:适用于希望探针只需一次成功就认为容器启动成功的情况。
- failureThreshold: 2:适用于希望探针需要连续两次失败才认为容器启动失败的情况,避免偶发性故障导致不必要的重启。
-
结论
这个配置是合适的,因为它能够满足以下需求:
8秒内完成启动:探针每2秒检查一次容器状态,探针等待4秒以获取响应。如果超过4秒没有响应,则认为探针失败。探针需要连续两次失败(即8秒内两次失败)才会将容器标记为启动失败并触发重启。 -
口水话深度解析
- 容器启动后,探针会立即开始进行探测。
- 开始第一个循环,循环内容持续时间是4秒,循环内容为:探针每4秒(periodSeconds: 4)执行一次 ls /mnt 命令。持续时间为2秒(timeoutSeconds: 2)【时间是包含关系【(periodSeconds: 4)包含(timeoutSeconds: 2)】,而不能(periodSeconds: 4)x(timeoutSeconds: 2)=8秒】
- 【换种方式来说就是,4秒执行一次,持续时间4秒(periodSeconds: 4),4秒中做的事情是,2秒内(timeoutSeconds: 2)有没有成功执行 ls /mnt命令】
- 如果探针在2秒(timeoutSeconds: 2)内没有成功执行 ls /mnt 命令,则认为探针失败。然后开始下一个循环(failureThreshold: 2),一组循环的参数是(periodSeconds: 4)和(timeoutSeconds: 2)。
- 探针需要连续两次失败(即8秒内两次失败)才会触发容器重启。【时间计算是(periodSeconds: 4)x(failureThreshold: 2)】
- 而所谓的“否则杀死对应容器”,就是表示容器不运行而已
timeoutSeconds: 和 periodSeconds: 参数顺序说明
- 容器在8秒内完成启动,否则杀死对应容器,下面2个参数哪个更合适?
startupProbe:
exec:
command:
- ls
- /mnt
initialDelaySeconds: 0
timeoutSeconds: 2
periodSeconds: 4
successThreshold: 1
failureThreshold: 2
#和
startupProbe:
exec:
command:
- ls
- /mnt
initialDelaySeconds: 0
timeoutSeconds: 4
periodSeconds: 2
successThreshold: 1
failureThreshold: 2
根据你的需求:容器在8秒内完成启动,否则杀死对应容器。
-
区别
-
- timeoutSeconds:
- 配置1:
timeoutSeconds: 2,探针等待2秒以获取响应。如果超过2秒没有响应,则认为探针失败。 - 配置2:
timeoutSeconds: 4,探针等待4秒以获取响应。如果超过4秒没有响应,则认为探针失败。
-
- periodSeconds:
- 配置1:
periodSeconds: 4,每4秒进行一次探测。
-
配置2:
periodSeconds: 2,每2秒进行一次探测。
-
-
需求分析
- 8秒内完成启动:需要探针在8秒内检测到容器是否启动完成,否则杀死容器。
-
配置选择
-
配置1
- 探针每4秒检查一次容器状态。
- 探针等待2秒以获取响应。
- 探针需要连续两次失败(即8秒内两次失败)才会将容器标记为启动失败并杀死容器。
-
配置2
- 探针每2秒检查一次容器状态。
- 探针等待4秒以获取响应。
- 探针需要连续两次失败(即8秒内两次失败)才会将容器标记为启动失败并杀死容器。
-
-
结论
- 配置2 更合适,因为它能够更频繁地检查容器状态,并且在8秒内检测到容器是否启动完成。
- 这种配置确保了探针能够每2秒检查一次容器状态,并且在容器未能在8秒内启动完成时杀死容器。探针等待4秒以获取响应,如果超过4秒没有响应,则认为探针失败。探针需要连续两次失败(即8秒内两次失败)才会将容器标记为启动失败并杀死容器。
startupProbe:
exec:
command:
- ls
- /mnt
initialDelaySeconds: 0
timeoutSeconds: 4
periodSeconds: 2
successThreshold: 1
failureThreshold: 2
livenessProbe探针
livenessProbe说明
-
livenessProbe是 Kubernetes 中的一种探针,用于检测容器是否处于健康状态。- 如果探针失败,Kubernetes 会杀死容器并根据策略进行重启。
livenessProbe主要用于确保容器在运行过程中保持健康状态,如果容器进入不健康状态,可以通过重启来恢复。- 通过合理配置
livenessProbe,可以确保容器在运行过程中保持健康状态,并在出现问题时自动重启容器,从而提高应用的可靠性和可用性。
-
以下是
livenessProbe的常用参数及其说明:- httpGet: 使用 HTTP GET 请求进行探测。
- path: 要探测的 HTTP 路径。
- port: 要探测的端口。
- scheme: 使用的协议(HTTP 或 HTTPS)。
示例:
httpGet: path: / port: 8080 scheme: HTTP -
- tcpSocket: 使用 TCP 检查进行探测。
- port: 要探测的端口。
示例:
tcpSocket: port: 8080 -
- exec: 使用命令执行进行探测。
- command: 要执行的命令及其参数。
示例:
exec: command: - cat - /etc/hosts -
- initialDelaySeconds: 在容器启动后等待多长时间开始进行第一次检查。
- 类型:整数
- 默认值:0
-
- timeoutSeconds: 探针等待响应的时间。如果超过这个时间没有响应,则认为探针失败。
- 类型:整数
- 默认值:1
-
- periodSeconds: 探针之间的间隔时间,即每隔多少秒进行一次检查。
- 类型:整数
- 默认值:10
-
- successThreshold: 探针连续成功的次数,只有达到这个次数才认为探针成功。
- 类型:整数
- 默认值:1
-
- failureThreshold: 探针连续失败的次数,只有达到这个次数才认为探针失败,并触发容器重启。
- 类型:整数
- 默认值:3
示例配置
- 以下是一个完整的
livenessProbe配置示例:
livenessProbe:
httpGet:
path: /
port: 8080
scheme: HTTP
initialDelaySeconds: 10
timeoutSeconds: 1
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
参数解释
- httpGet: 使用 HTTP GET 请求检查
/路径,端口为 8080,使用 HTTP 协议。 - initialDelaySeconds: 10: 容器启动后等待10秒再开始进行探测。
- timeoutSeconds: 1: 探针等待1秒以获取响应。如果超过1秒没有响应,则认为探针失败。
- periodSeconds: 10: 每10秒进行一次探测。
- successThreshold: 1: 探针只需一次成功就认为探测通过。
- failureThreshold: 3: 探针需要连续三次失败才认为探测失败,并触发容器重启。
使用场景说明
- 使用场景如下
- 检测应用崩溃:如果应用进程崩溃或挂起,
livenessProbe可以检测到并触发容器重启。 - 检测死锁:如果应用进入死锁状态,
livenessProbe可以检测到并触发容器重启。 - 检测资源耗尽:如果应用耗尽了资源(如内存、CPU),
livenessProbe可以检测到并触发容器重启。
- 检测应用崩溃:如果应用进程崩溃或挂起,
实例——题目要求:如果发现业务4秒后无响应,杀死对应容器,并进行重启
- 题目要求:如果发现业务4秒后无响应,杀死对应容器,并进行重启
- 最终如下
这种配置确保了探针能够每秒检查一次服务状态,并且在服务无响应时更准确地将容器标记为不健康。探针等待2秒以获取响应,如果超过2秒没有响应,则认为探针失败。探针需要连续两次失败才会触发容器重启,同时在服务恢复响应时能够快速将容器标记为健康。
livenessProbe:
httpGet:
path: /
port: 8090
scheme: HTTP
initialDelaySeconds: 10
timeoutSeconds: 2
periodSeconds: 1
successThreshold: 1
failureThreshold: 2
工作流程说明
liveness【整个生命周期存在】——检测状态,失败就kill
#用于检测容器是否处于健康状态。如果探针失败,Kubernetes 会杀死容器并根据策略进行重启。
#适用于检测容器是否需要重启的情况。
tcpSocket: 过尝试建立 TCP 连接来检查应用的健康状况。
port: 8090 要连接的端口。
`initialDelaySeconds 10` 用于指定在容器启动后多长时间开始进行首次健康检查。
它的作用是让容器有足够的时间来完成初始化操作,避免在容器还未完全启动时就进行健康检查,从而导致误判。
例如,如果将 `initialDelaySeconds` 设置为 `30`,那么 Kubernetes 会在容器启动后的 30 秒才开始进行第一次 `startupProbe` 检查。
`timeoutSeconds 2`: 探测的超时时间(秒)。默认值是 1 秒。
`periodSeconds 1`: 执行探测的周期(秒)。默认值是 10 秒。
`successThreshold 1`: 探测成功的阈值。连续成功达到这个阈值后,容器被认为已经成功启动。默认值是 1。如果设置为 1,只要有一次成功的探测,容器就会被认为启动成功。
`failureThreshold 2`: 探测失败的阈值。在达到这个阈值之前,容器不会被认为启动失败。默认值是 3。
-
参数解释
-
httpGet: 使用 HTTP GET 请求进行探测。
-
path:
/,这是探针将要检查的路径。 -
port:
8090,这是探针将要检查的端口。 -
scheme:
HTTP,使用 HTTP 协议进行探测。 -
initialDelaySeconds: 在容器启动后等待多长时间开始进行第一次检查。
- 在你的配置中,
initialDelaySeconds: 10表示容器启动后等待10秒再开始进行探测。
- 在你的配置中,
-
timeoutSeconds: 探针等待响应的时间。如果超过这个时间没有响应,则认为探针失败。
- 在你的配置中,
timeoutSeconds: 2表示探针等待2秒以获取响应。如果超过2秒没有响应,则认为探针失败。
- 在你的配置中,
-
periodSeconds: 探针之间的间隔时间,即每隔多少秒进行一次检查。
- 在你的配置中,
periodSeconds: 1表示每1秒进行一次探测。
- 在你的配置中,
-
successThreshold: 探针连续成功的次数,只有达到这个次数才认为探针成功。
- 在你的配置中,
successThreshold: 1表示探针只需一次成功就认为探测通过。
- 在你的配置中,
-
failureThreshold: 探针连续失败的次数,只有达到这个次数才认为探针失败,并触发容器重启。
- 在你的配置中,
failureThreshold: 2表示探针需要连续两次失败才认为探测失败。
- 在你的配置中,
-
-
工作流程
-
- 容器启动后,探针会等待10秒再开始进行探测(
initialDelaySeconds: 10)。
- 容器启动后,探针会等待10秒再开始进行探测(
-
- 每1秒,探针会对
http://<容器IP>:8090/发起一次 HTTP GET 请求(periodSeconds: 1)。
- 每1秒,探针会对
-
- 如果探针在2秒内没有收到响应(
timeoutSeconds: 2),则认为探针失败。
- 如果探针在2秒内没有收到响应(
-
- 探针需要连续两次失败(
failureThreshold: 2)才会触发容器重启。
- 探针需要连续两次失败(
-
- 探针只需一次成功(
successThreshold: 1)就会将容器标记为健康。
- 探针只需一次成功(
-
-
适用场景
- initialDelaySeconds: 10:适用于希望容器启动后等待一段时间再开始探测的场景。
- timeoutSeconds: 2:适用于希望快速检测到服务无响应的情况。
- periodSeconds: 1:适用于希望频繁检查服务健康状态的情况。
- successThreshold: 1:适用于希望探针只需一次成功就认为服务健康的情况。
- failureThreshold: 2:适用于希望探针需要连续两次失败才认为服务不健康的情况,避免偶发性故障导致不必要的重启。
-
满足需求
- 10秒后开始探测:容器启动后等待10秒再开始进行探测。
- 2秒无响应:探针等待2秒以获取响应,如果超过2秒没有响应,则认为探针失败。
- 每1秒检查一次:探针每1秒检查一次服务状态。
- 连续两次失败:探针需要连续两次失败才会触发容器重启。
readnessProbe探针
readnessProbe说明
-
readinessProbe是 Kubernetes 中的一种探针,用于检测容器是否已经准备好接受流量。- 如果探针失败,Kubernetes 会将容器从服务的端点列表中移除,但不会杀死容器。
- 这主要用于确保只有健康且准备好处理请求的容器才会接收流量。
- 通过合理配置
readinessProbe,可以确保只有健康且准备好处理请求的容器才会接收流量,从而提高应用的可靠性和可用性。
-
readinessProbe参数说明
以下是readinessProbe的常用参数及其说明: -
- httpGet: 使用 HTTP GET 请求进行探测。
- path: 要探测的 HTTP 路径。
- port: 要探测的端口。
- scheme: 使用的协议(HTTP 或 HTTPS)。
示例:
httpGet: path: / port: 8080 scheme: HTTP -
- tcpSocket: 使用 TCP 检查进行探测。
- port: 要探测的端口。
示例:
tcpSocket: port: 8080 -
- exec: 使用命令执行进行探测。
- command: 要执行的命令及其参数。
示例:
exec: command: - cat - /etc/hosts -
- initialDelaySeconds: 在容器启动后等待多长时间开始进行第一次检查。
- 类型:整数
- 默认值:0
-
- timeoutSeconds: 探针等待响应的时间。如果超过这个时间没有响应,则认为探针失败。
- 类型:整数
- 默认值:1
-
- periodSeconds: 探针之间的间隔时间,即每隔多少秒进行一次检查。
- 类型:整数
- 默认值:10
-
- successThreshold: 探针连续成功的次数,只有达到这个次数才认为探针成功。
- 类型:整数
- 默认值:1
-
- failureThreshold: 探针连续失败的次数,只有达到这个次数才认为探针失败,并将容器标记为不就绪。
- 类型:整数
- 默认值:3
示例配置
以下是一个完整的 readinessProbe 配置示例:
readinessProbe:
httpGet:
path: /
port: 8080
scheme: HTTP
initialDelaySeconds: 10
timeoutSeconds: 1
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
参数解释
- httpGet: 使用 HTTP GET 请求检查
/路径,端口为 8080,使用 HTTP 协议。 - initialDelaySeconds: 10: 容器启动后等待10秒再开始进行探测。
- timeoutSeconds: 1: 探针等待1秒以获取响应。如果超过1秒没有响应,则认为探针失败。
- periodSeconds: 10: 每10秒进行一次探测。
- successThreshold: 1: 探针只需一次成功就认为探测通过。
- failureThreshold: 3: 探针需要连续三次失败才认为探测失败,并将容器标记为不就绪。
使用场景说明
- 检测应用是否准备好接受流量:在应用启动过程中,可能需要进行一些初始化操作(如加载配置、连接数据库等),
readinessProbe可以确保应用在完成这些操作后才开始接收流量。 - 动态调整服务流量:在运行过程中,如果应用暂时无法处理请求(如进行内部维护或资源不足),
readinessProbe可以将容器从服务的端点列表中移除,待应用恢复后再重新加入。
实例——如果发现业务3秒后无响应,访问流量将不会传值该容器,5秒内如果回复响应,访问流量将继续转发至该容器
- 题目要求:如果发现业务3秒后无响应,访问流量将不会传值该容器,5秒内如果回复响应,访问流量将继续转发至该容器
- 最终用下面参数
这种配置确保了探针能够每秒检查一次服务状态,并且在服务无响应时更准确地将容器标记为不就绪。探针等待3秒以获取响应,如果超过3秒没有响应,则认为探针失败。探针只需一次失败就会将容器标记为不就绪,同时在服务恢复响应时能够在5秒内检测到并将容器标记为就绪。
readinessProbe:
httpGet:
path: /
port: 8090
scheme: HTTP
initialDelaySeconds: 10
timeoutSeconds: 3
periodSeconds: 1
successThreshold: 1
failureThreshold: 1
工作流程说明
readness【整个生命周期存在】——检测业务,失败就不转发业务【不会kill掉容器】
#用于检测容器是否准备好接受流量。如果探针失败,Kubernetes 会将容器从服务的端点列表中移除,但不会杀死容器。
#适用于检测容器是否可以接受流量的情况。
httpGet: 通过发送 HTTP GET 请求来检查应用的健康状况。
path: / 要访问的 HTTP 路径。
port: 8090 要访问的端口。
scheme: HTTP 指定 HTTP 请求的协议,常见的值为 HTTP 和 HTTPS。
`initialDelaySeconds 10` 用于指定在容器启动后多长时间开始进行首次健康检查。
它的作用是让容器有足够的时间来完成初始化操作,避免在容器还未完全启动时就进行健康检查,从而导致误判。
例如,如果将 `initialDelaySeconds` 设置为 `30`,那么 Kubernetes 会在容器启动后的 30 秒才开始进行第一次 `startupProbe` 检查。
`timeoutSeconds 3`: 探测的超时时间(秒)。默认值是 1 秒。
`periodSeconds 1`: 执行探测的周期(秒)。默认值是 10 秒。
`successThreshold 1`: 探测成功的阈值。连续成功达到这个阈值后,容器被认为已经成功启动。默认值是 1。如果设置为 1,只要有一次成功的探测,容器就会被认为启动成功。
`failureThreshold 1`: 探测失败的阈值。在达到这个阈值之前,容器不会被认为启动失败。默认值是 3。
-
参数解释
-
httpGet: 使用 HTTP GET 请求进行探测。
- path:
/,这是探针将要检查的路径。 - port:
8090,这是探针将要检查的端口。 - scheme:
HTTP,使用 HTTP 协议进行探测。
- path:
-
initialDelaySeconds: 在容器启动后等待多长时间开始进行第一次检查。
- 在你的配置中,
initialDelaySeconds: 10表示容器启动后等待10秒再开始进行探测。
- 在你的配置中,
-
timeoutSeconds: 探针等待响应的时间。如果超过这个时间没有响应,则认为探针失败。
- 在你的配置中,
timeoutSeconds: 3表示探针等待3秒以获取响应。如果超过3秒没有响应,则认为探针失败。
- 在你的配置中,
-
periodSeconds: 探针之间的间隔时间,即每隔多少秒进行一次检查。
- 在你的配置中,
periodSeconds: 1表示每1秒进行一次探测。
- 在你的配置中,
-
successThreshold: 探针连续成功的次数,只有达到这个次数才认为探针成功。
- 在你的配置中,
successThreshold: 1表示探针只需一次成功就认为探测通过。
- 在你的配置中,
-
failureThreshold: 探针连续失败的次数,只有达到这个次数才认为探针失败,并将容器标记为不就绪。
- 在你的配置中,
failureThreshold: 1表示探针只需一次失败就认为探测失败。
- 在你的配置中,
-
-
工作流程
-
- 容器启动后,探针会等待10秒再开始进行探测(
initialDelaySeconds: 10)。
- 容器启动后,探针会等待10秒再开始进行探测(
-
- 每1秒,探针会对
http://<容器IP>:8090/发起一次 HTTP GET 请求(periodSeconds: 1)。
- 每1秒,探针会对
-
- 如果探针在3秒内没有收到响应(
timeoutSeconds: 3),则认为探针失败。
- 如果探针在3秒内没有收到响应(
-
- 探针只需一次失败(
failureThreshold: 1)就会将容器标记为不就绪。
- 探针只需一次失败(
-
- 探针只需一次成功(
successThreshold: 1)就会将容器标记为就绪。
- 探针只需一次成功(
-
-
适用场景
- initialDelaySeconds: 10:适用于希望容器启动后等待一段时间再开始探测的场景。
- timeoutSeconds: 3:适用于希望快速检测到服务无响应的情况。
- periodSeconds: 1:适用于希望频繁检查服务健康状态的情况。
- successThreshold: 1:适用于希望探针只需一次成功就认为服务就绪的情况。
- failureThreshold: 1:适用于希望探针只需一次失败就认为服务不就绪的情况,能够快速响应服务的异常状态。
-
满足需求
- 10秒后开始探测:容器启动后等待10秒再开始进行探测。
- 3秒无响应:探针等待3秒以获取响应,如果超过3秒没有响应,则认为探针失败。
- 每1秒检查一次:探针每1秒检查一次服务状态。
- 一次失败即标记为不就绪:探针只需一次失败就会将容器标记为不就绪。
- 一次成功即标记为就绪:探针只需一次成功就会将容器标记为就绪。
一个完整的包含3个探针的实例yaml文件
可以直接通过下面内容创建一个负载的
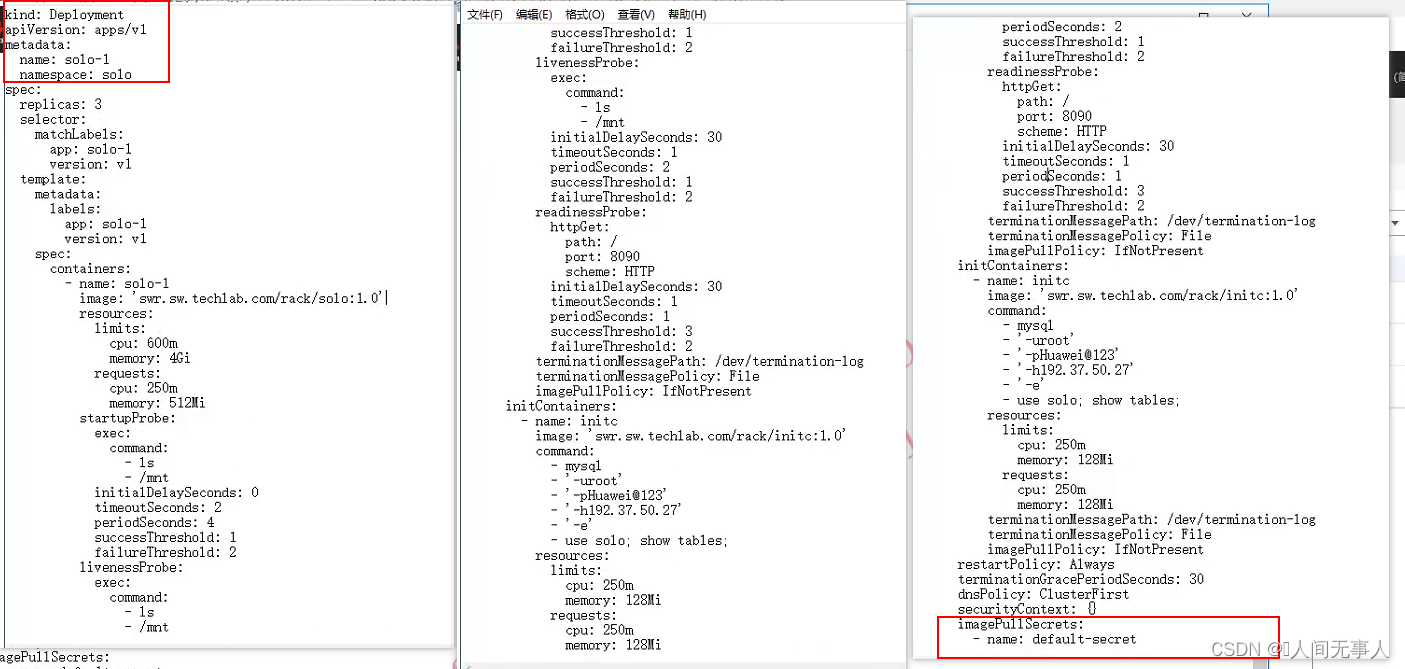




![[激光原理与应用-102]:南京科耐激光-激光焊接-焊中检测-智能制程监测系统IPM介绍 - 6 - 激光焊接系统的组成](https://i-blog.csdnimg.cn/direct/de88ab345368489c87e2394e64a9b89e.png)












