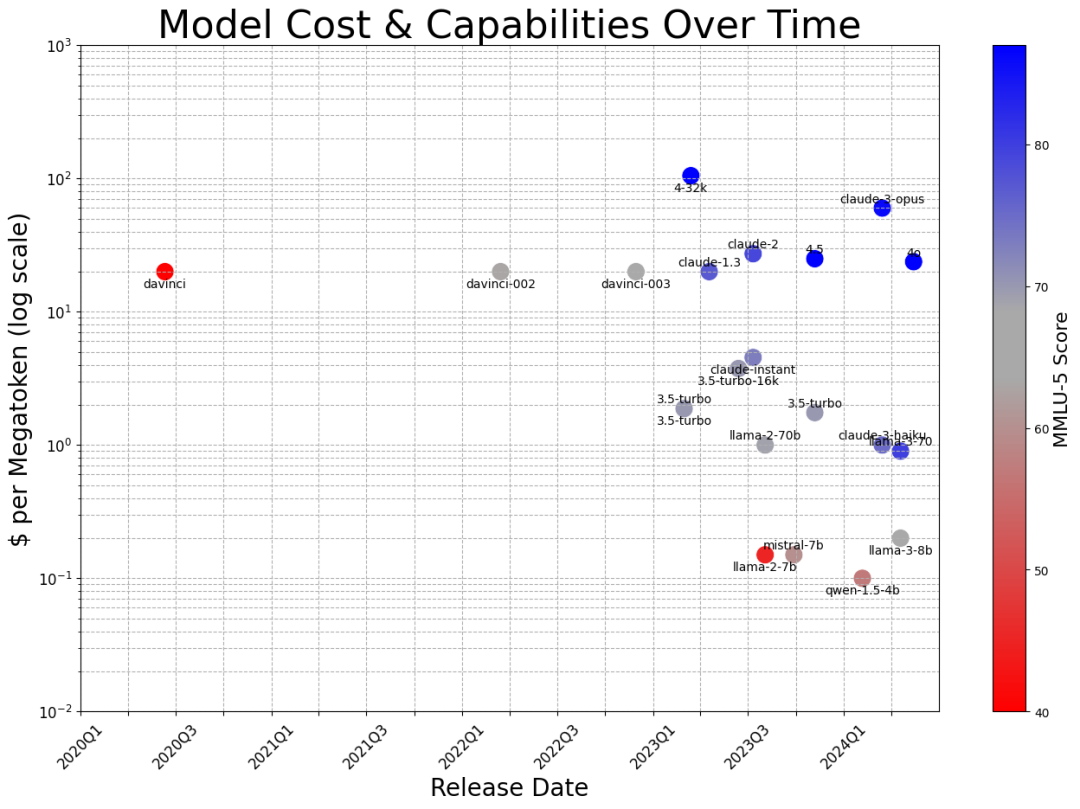
随着新的大型语言模型(LLMs)的持续发展,从业者发现自己面临着众多选择,需要从数百个可用选项中选择出最适合其特定需求的模型、提示[40]或超参数。例如,Chatbot Arena基准测试平台积极维护着近100个模型,以对用户指定的开放式查询进行基准测试。同样,AlpacaEval排行榜对805个问题上的200多个模型进行了基准测试。
Chatbot Arena基准测试平台:https://arena.lmsys.org/
AlpacaEval排行榜:https://github.com/tatsu-lab/alpaca_eval。
对大型语言模型(LLMs)进行广泛的评估需要在时间、计算和财务资源上进行重大投资。截至2024年5月20日,完全评估(表示为完整评估)AlpacaEval[官方包含的153个模型的估计成本接近800美元;使用Mistral-7B[评估205个零样本提示在784个GSM8K问题上需要78.2个Nvidia A6000 GPU小时。
尽管对测试集中的所有数据点进行全面评估是惯例,但从业者通常只关心整体性能排名。通常,目标是识别出表现最佳的方法或简单地说是最好的方法,而忽略排名较低的替代方案。因此,尽管对每个方法在数据集中的每个数据点进行全面评估是彻底的,但当目标仅仅是识别出更优的方法时,这可能不是成本效益的。
本文关注有限预算下的评估问题,即在给定预算内找到最佳方法。本文提出两种主动选择算法UCB-E和UCB-E-LRF。第一个算法是经典UCB-E [2]的扩展,用于解决多臂老虎机问题;第二个算法UCB-E-LRF,利用了评分矩阵内在的低秩性质。

1 相关背景
1.1 大型语言模型(LLM)应用评估工作流程
一个典型的大型语言模型(LLM)应用评估工作流程包括三个步骤:推理、评分和性能聚合,其中前两个步骤LLM可以扮演重要角色。
- 推理:给定一个数据集和一个基于LLM的方法,这个方法的输出是通过LLM生成的。每种方法可以是不同的LLM,用于基准测试不同的LLM性能,相同的LLM与不同的提示用于提示工程,或者不同的配置,如温度、解码策略等,用于超参数调整。
- 评分:不同方法的输出通过一个评分函数,即度量标准来评分。评分函数可以是规则基础的(如精确字符串匹配、BLEU 、ROUGE ),基于LLM的(如BERTScore 、LLM法官),或基于人类的,即用户研究。根据任务和数据集格式,研究人员采用了不同类型的评分函数。
- 性能聚合:每个方法的性能通过数据集中的所有示例进行聚合,通常通过对数据集中所有示例的简单平均值来实现。
1.2 符号和问题公式化 (Notations and Problem Formulation)

1.2.1 符号
- F = {f1, …, fn}:方法集合,包含 n 个不同的方法。
- X = {x1, …, xm}:例子集合,包含 m 个不同的例子。
- e : F × X → [0, 1]:评分函数,输入一个方法和一个例子,输出一个介于 0 到 1 之间的分数,表示该方法在该例子上的表现。
- E ∈ [0, 1]n×m:评分矩阵,其中 Ei,j = e(fi, xj) 表示方法 fi 在例子 xj 上的分数。
- µi = 1/m * Σ(Ei,j):方法 fi 的平均分数,通过对其在所有例子上的分数求平均得到。
- i∗ = arg max µi:最佳方法,即在所有方法中平均分数最高的方法。
1.2.2 问题公式化
给定一个固定的评估预算 T,一个方法集合 F 和一个例子集合 X,我们需要设计一个评估算法 A,该算法可以在 T 次评估预算内,最大化找到最佳方法 i∗ 的概率 PA(A(T, F, X) = i∗)。
2 UCB-E 算法及UCB-E-LRF 算法
2.1 UCB-E 算法
基于 UCB-E 算法,估计每个方法的置信上限,并选择置信上限最高的方法进行评估。
2.1.1 步骤
- 初始化每个方法的置信上限 Bi 和已评估示例集合 Si。
- 在每个步骤 t,选择置信上限 Bi 最大的方法 fit。
- 从未评估的示例集合中均匀随机选择一个示例 xjt。
- 对方法示例对 (fit, xjt) 进行推理,获取评分 e(fit, xjt) 并更新评分矩阵 Eobs。
- 更新置信上限 Bi 和已评估示例集合 Si。
- 重复步骤 2-5,直到达到预算 T。
优点: 理论上保证找到最佳方法的概率随着评估次数的增加而指数衰减。
缺点: 忽略了评分矩阵的低秩特性,可能导致效率不如 UCB-E-LRF。
2.2 UCB-E-LRF 算法
基于 UCB-E 算法,并结合低秩分解 (LRF) 来估计未评估方法示例对的评分。
2.2.1 步骤
- 随机选择 T0 个方法示例对进行评估,构建初始评分矩阵 Eobs 和观察矩阵 O。
- 使用 LRF 算法估计评分矩阵 ˆE 和不确定性矩阵 R。
- 在每个步骤 t,选择置信上限 Bi 最大的方法 fit。
- 从未评估的示例集合中,选择与 fit 相关的不确定性 Rit,jt 最大的 b 个示例 xjt。
- 对 b 个方法示例对进行推理,获取评分 e(fit, xjt) 并更新评分矩阵 Eobs 和观察矩阵 O。
- 使用 LRF 算法重新估计评分矩阵 ˆE 和不确定性矩阵 R。
- 更新置信上限 Bi。
- 重复步骤 3-7,直到达到预算 T。
优点: 利用 LRF 估计未评估方法示例对的评分,可以更有效地分配预算,提高找到最佳方法的概率。
缺点: 需要设置 LRF 的超参数,例如秩 r、集成大小 K、预热预算 T0 和批处理大小 b。
2.3 两种算法的比较
- 在较简单的数据集(例如 AlpacaEval)上,UCB-E 表现更好,因为方法之间的差距较大,不需要 LRF 估计未评估示例对的评分。
- 在较难的数据集(例如 GSM8K Prompts 和 PIQA Prompts)上,UCB-E-LRF 表现更好,因为方法之间的差距较小,LRF 可以更有效地估计未评估示例对的评分。
3 实验
3.1 数据集

3.1.1 AlpacaEval
- 数据集规模: 154 x 805 (方法 x 示例)
- 方法 (F): 包含 154 个不同的 LLM 模型,用于评估不同的 LLM 性能。
- 评分函数 (e): 使用 GPT-4-turbo 作为 LLM 判官,将每个模型的响应与基线模型 GPT-4-turbo 的响应进行比较,并给出分数。
- H1 值: 966
- 数据来源: 从 AlpacaEval 官方仓库收集,截至 2024 年 5 月 20 日。
3.1.2 AlpacaEval (Drop Annotator)
- 数据集规模: 153 x 805 (方法 x 示例)
- 方法 (F): 与 AlpacaEval 相同,但排除了 GPT-4-turbo 作为 annotator 模型。
- 评分函数 (e): 与 AlpacaEval 相同。
- H1 值: 4462
- 数据来源: 从 AlpacaEval 官方仓库收集,截至 2024 年 5 月 20 日。
- 设计目的: 去除 annotator 模型的偏见,使学习更具挑战性,并更有趣。
3.1.3 Grade School Math 8K (GSM8K)
- 数据集规模: 205 x 784 (方法 x 示例)
- 方法 (F): 包含 205 个不同的 prompt,用于模拟 prompt engineering 场景。
- 评分函数 (e): 使用正则表达式匹配 LLM 生成的最终答案与真实答案 (GSM8K) 或真实选择 (PIQA)。
- H1 值: 107445
- 数据来源: 使用 GPT-4 生成 prompt,并使用 Mistral-7B 模型进行推理和评分。
3.1.4 GSM8K Models 和 PIQA Models
- 数据集规模: 122 x 1000 (GSM8K Models) 和 103 x 1000 (PIQA Models)
- 方法 (F): 包含不同的 LLM 模型及其采样配置,用于模拟模型选择和超参数调整场景。
- 评分函数 (e): 与 GSM8K Prompts 和 PIQA Prompts 相同。
- H1 值: 20562 (GSM8K Models) 和 10273 (PIQA Models)
- 数据来源: 使用 11 个公开可用的 LLM 模型及其不同的采样配置,并使用随机选择的 1000 个问题进行评分。
3.1.5 PIQA Prompts 和 PIQA Models
- 数据集规模: 177 x 1546 (PIQA Prompts) 和 103 x 1000 (PIQA Models)
- 方法 (F): 与 GSM8K Prompts 和 GSM8K Models 相同。
- 评分函数 (e): 与 GSM8K Prompts 和 GSM8K Models 相同。
- H1 值: 66284 (PIQA Prompts) 和 10273 (PIQA Models)
- 数据来源: 使用 GPT-4 生成 prompt,并使用 Tulu-7B 模型进行推理和评分。
3.2 评估指标
- Top 1 精确度 (Top 1 Precision): 评估算法预测最佳方法的能力,考虑性能差距和统计显著性两种情况。
- NDCG (Normalized Discounted Cumulative Gain): 评估算法对前 10 个高绩效方法的排序能力。
3.3 基线算法
- Row Mean Imputation: 均匀随机选择方法示例对进行评估,并计算每个方法的平均评分。
- Filled Subset: 对每个示例随机选择所有方法进行评估,并计算每个方法的平均评分。
- LRF: 使用 LRF 估计未评估方法示例对的评分,并计算每个方法的平均评分。
3.4 实验结果
- 算法比较: UCB-E 和 UCB-E-LRF 在所有数据集上都显著优于基线算法,可以更快地达到相同的性能水平。
- UCB-E vs. UCB-E-LRF: 在较简单的数据集上,UCB-E 表现更好;在较难的数据集上,UCB-E-LRF 表现更好。