- MySQL索引B+树、全文索引、哈希索引
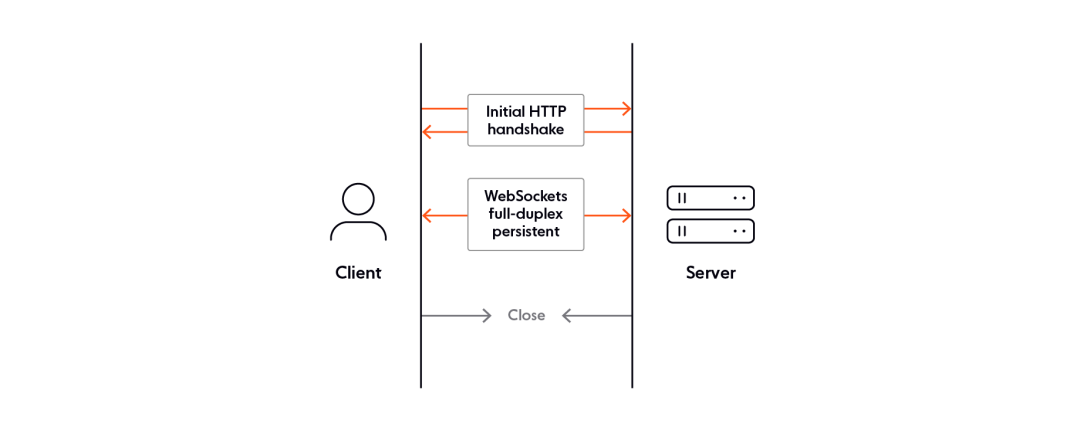
注意:B+树中B不是代表二叉树(binary),而是代表平衡(balance),因为B+树是从最早的平衡二叉树演化而来,但是B+树不是一个二叉树。
B+树的高度一般在2~4层,因此每次查询最多只需要2~4次IO。
1. B+树索引(BTREE)
特点:
B+树是一种自平衡的多路搜索树,它是一种高度平衡的结构,保证从根节点到任意叶子节点的路径长度几乎相等,从而保证了查询效率相对稳定。
B+树索引的所有数据都存储在叶子节点,并且叶子节点之间通过双向链表连接,形成了一个有序的数据集合。
支持范围查询、排序和分组操作,因为叶子节点是有序排列的。
可以是单列索引或多列索引(复合索引),并遵循最左前缀匹配原则,即在查询时,如果查询条件包含了复合索引的最左边部分列,就能利用索引进行高效查询。
适用于大部分查询场景,特别是等值查询、范围查询以及基于索引列的排序和分组。
优点:
查询效率较高,尤其是对于范围查询和有序结果集的获取。
能够处理大量数据,因为B+树的高度较低,即使数据量很大,查询深度也不会过高。
缺点:
对于非常小的数据集,建立和维护B+树索引可能比直接全表扫描更耗时。
对于等值查询,如果键值分布不均匀导致哈希冲突较少,哈希索引可能更快。
2. 全文索引
特点:
全文索引主要用于对文本类型的字段(如VARCHAR、TEXT)进行全文本搜索,能够处理复杂的查询条件,如包含某个词语或短语、近似匹配、词干提取等。
MySQL的全文索引通常基于倒排索引实现,即为每个单词建立一个索引项,记录下包含该单词的所有文档(在数据库中对应为记录)的列表及位置信息。
通常用于大型文本数据的全文检索,如博客文章、产品描述、文献资料等。
优点:
非常适合进行复杂文本内容的模糊查询和关键词搜索。
提供了对文本数据的高效过滤能力,显著减少针对文本字段进行LIKE '%keyword%'这类操作时的全表扫描。
缺点:
创建和维护全文索引需要消耗额外的空间和时间资源。
索引更新时有延迟,对于实时性要求较高的场景可能不合适(可通过手动刷新解决)。
对查询语法有一定要求,需要使用MATCH AGAINST语句,而非普通的WHERE子句。
对于短词、停用词(如“的”、“是”等常见词汇)的处理可能不够精确,可能需要配合语言分析器和定制化配置。
3. 哈希索引(HASH)
特点:
哈希索引基于哈希表实现,通过哈希函数将键值转换为固定长度的哈希值,然后通过哈希值直接定位到对应的记录。
主要适用于等值查询,查询效率极高,只需一次哈希计算即可找到相应记录(假设没有哈希冲突)。
不支持范围查询、排序和分组操作,因为哈希索引并不保持键值的有序性。
对于键值唯一性高的列(如唯一标识符),哈希索引效果尤为出色。
通常用于内存型存储引擎(如MEMORY引擎)或者InnoDB引擎的自适应哈希索引(Adaptive Hash Index,AHI)。
优点:
等值查询性能极高,尤其在键值分布均匀且唯一性强的情况下。
查找时间复杂度接近O(1),在理想情况下能提供极快的查询速度。
缺点:
只适用于等值查询,无法处理范围查询、排序和分组。
如果键值分布不均导致哈希冲突较多,性能会下降,尤其是在存在大量重复键值的情况下。
不支持部分索引列的匹配(如复合索引的部分列查询)。
哈希索引不存储原始键值,只存储哈希值和行指针,因此不能避免对数据行的访问来获取完整数据。
如果大家需要视频版本的讲解,欢迎关注我的B站: