这是一系列LLM介绍的可成,分以下五个不分
- 序言:大型语言模型LLM简史
- 第一部分:代币化——完整指南
- 第 2 部分:使用 Python 中的 Scratch 从零开始使用 word2vec 进行词嵌入
- 第 3 部分:用代码解释自注意力机制
- 第 4 部分:BERT 完整指南(附代码)
介绍
大型语言模型 (LLM) 在过去几年中一直是机器学习讨论的焦点,并在未来几年改变了人工智能的格局。本文是“从头开始构建 LLM”系列的序幕,该系列是理解和构建 LLM 的完整指南。假设您缺乏背景知识,本文旨在通过图表、动画、Python 代码和底层数学知识,从头开始直观地了解这些模型的工作原理。API 和在线用户界面使与 LLM 的交互变得像输入提示一样简单,但真正理解这些复杂模型的内部工作原理需要更仔细的检查。为了为接下来的文章奠定基础,我们将首先介绍 LLM 背后的背景:它们之前的模型、它们的局限性以及我们如何走到今天这一步。这样做的目的是为该系列的未来发展制定路线图。也就是说,这些文章将涵盖:Transformer 架构(LLM 的骨干)的每个主要组件、GPT-4 和 Llama 2 等最先进(SOTA)模型、如何使用 LLM 执行常见的自然语言处理(NLP)任务,例如命名实体识别(NER)和主题建模,以及其他关键主题,例如微调和检索增强生成(RAG)。
内容
1- Transformer 简介
2-走向大型语言模型
3 -结论
4 - 进一步阅读
1 — Transformer 简介
1.1 —什么是 Transformer?
在阅读有关 LLM 的文章时,无法避免使用“Transformer”一词。这两个概念似乎密不可分,至少到目前为止,它们确实如此。Transformer 是一种深度神经网络架构,构成了当今 LLM 的骨干。该架构最初是在 2017 年的论文“Attention is All You Need”中提出的 - 这是 Google Brain、Google Research 和多伦多大学 [2] 的合作成果。其目标是改进当时流行的基于循环神经网络 (RNN) 的模型,特别是对于机器翻译任务。也就是说,将一系列文本从源语言(例如英语)翻译成目标语言(例如法语)。生成的模型产生了 SOTA 结果,而不受基于循环的网络的限制。Transformer 不仅限于翻译任务,而且还在许多 NLP 任务(例如情绪分析、主题建模、对话聊天机器人等)上产生了 SOTA 结果。因此,这些类型的模型及其衍生物已成为当代 NLP 中的主导方法。随着 2022 年 11 月 ChatGPT 的发布,Transformer 最著名的用途可能是在 GPT-4、BERT 和 Llama 2 等 LLM 中的应用。
自 2020 年左右以来,Transformer 已被改编用于 NLP 领域之外。计算机视觉模型(例如 Vision Transformer (ViT))在自动驾驶应用中执行图像分割 [3],而诸如 iTransformer 之类的模型已用于时间序列预测 [4]。本文将重点介绍 Transformer 在 LLM 中的使用。
注意: “机器翻译”中的“机器”一词是 20 世纪 50 年代/60 年代人工智能术语的延续,因为当时在计算机解决的问题标题中包含“机器”是很常见的。机器翻译的第一个被广泛研究的用例出现在冷战期间,当时美国计算机科学家试图建立基于规则的模型将俄语文本翻译成英语。这些早期的语言模型效果有限,该项目最终被取消,尽管如此,它为未来的翻译工作奠定了基础。如果你有兴趣关于机器翻译的历史,2M Languages 在他们的博客 [5] 上有一个很好的总结。
1.2 —统计机器翻译(SMT)
要理解原始 Transformer 论文中的架构决策,我们首先需要了解作者试图解决的问题。考虑到这一点,让我们简要回顾一下机器翻译的历史、在此过程中开发的模型以及 Transformer 设计用于解决的问题。
在 Transformer 出现之前,机器学习的格局与现在大不相同,尤其是在 NLP 领域。在 20 世纪 60 年代基于规则的机器翻译系统衰落之后,研究停滞了大约 30 年。在 20 世纪 90 年代中期,研究工作重新兴起,并转向基于统计的方法,即统计机器翻译(SMT)。在这种方法中,源语言的文本被提取并使用对齐模型翻译成目标语言。这种“对齐”是指将一种语言中的单词或短语映射到另一种语言的过程,考虑到目标语言中单词的顺序和可能的遗漏/添加。让我们以日语到英语为例依次看一下这些:

日语至英语例句翻译。除非另有说明,所有图片均由作者提供。
- 单词/短语顺序:日语是主语-宾语-谓语 (SOV) 语言,因此动词放在句子末尾。英语是主语-谓语-宾语 (SVO) 语言,因此动词放在宾语之前。这意味着逐字逐句地将日语句子翻译成英语会产生非常糟糕的结果,而且几乎总是语法错误。在上面的例子中,日语动词行く(“去”)位于句子末尾,但英语翻译将动词放在宾语“电影院”之前。在这种情况下,需要训练对齐模型以根据单词在句子中的功能正确排列单词。
- 单词/短语省略:日语经常使用上下文来暗示句子的主语。例如,如果您正在与某人谈论您当天的计划,则无需说“我将去电影院”或“我将去游泳”。从上下文可以清楚地看出您是句子的主语,因此通常会省略“我”(私)这个词。这意味着在从英语翻译成日语时,在翻译中省略“我”会更自然,从而得到:“将去电影院”和“将去游泳”。
- 添加单词/短语:同样,如果模型从日语翻译成英语,不添加主语会非常不自然。模型必须能够推断主语并自动为句子添加正确的主题,从而添加源句子中没有的额外单词。在本例中,在每个句子的开头插入主语“I”。
有时候还会发生单词省略/添加。例如,在某些语言中,一个概念可以用一个单词来表示,而其他语言可能需要多个单词(例如 电影館 与 “movie theatre”)。另一种情况是使用不定冠词和定冠词,例如英语中的“a”和“the”,而许多东亚语言中并不存在这些冠词。为了捕捉这些复杂性,基于对齐的 SMT 模型使用了许多单独设计的组件。这些组件包括用于提取输入句子的语言模型、用于生成输出序列的翻译模型、用于解释输入和目标语言不同词序的重新排序模型、用于捕捉所用动词/形容词形式的词形变化模型等等 [6]。使用像这样的许多组件的组合带来了挑战。首先,需要大量的特征工程(即,输入文本需要在传递给模型之前进行预处理)。其次,需要频繁的人为干预来维护模型并确保它们作为一个整体和谐地工作。第三(也许是最重要的),组件需要针对每对语言重新设计,这意味着最终的模型并不是通用的翻译器。对于早期的翻译包,英语到法语需要一个模型,英语到德语需要一个模型,等等。这些统计语言模型的表现参差不齐,但总体而言,它们已经足够成功,谷歌于 2006 年 4 月推出了谷歌翻译。
1.3 — 早期神经机器翻译(NMT)
2010 年代初,神经网络的发展开始加速。硬件能力增强,因此训练大型神经网络变得更加可行。2013 年,Kalchbrenner 和 Blunsom 成功应用卷积神经网络 (CNN) 将英语翻译成法语 [7]。此前,CNN 几乎只用于计算机视觉任务,例如图像识别和物体检测,因此这标志着 NLP 研究发生了重大变化。2014 年,世界各地的研究人员也独立利用 RNN 进行翻译,制作了架构更简单、结果最好的模型 [8–9]。总的来说,这些事件构成了我们现在所说的神经机器翻译(NMT) 的开端——当今占主导地位的翻译方法。
1.4 — 编码器-解码器架构
机器翻译问题更广泛地属于序列到序列建模的范畴,也称为序列传导或seq2seq。序列到序列模型以一个序列作为输入(例如,组成句子的单词序列、组成图像的像素序列等),并输出另一个序列(例如,翻译、图像的标题等)。在具有里程碑意义的论文《使用 RNN 编码器-解码器学习短语表示进行统计机器翻译》中,作者展示了如何使用具有两个 RNN 的模型捕捉源语言和目标语言中“短语的语义和句法结构”以进行翻译 [8]。主要思想是,可以训练一个网络通过将源文本转换为嵌入向量来对其进行编码,可以训练另一个网络将模型的输出从嵌入解码为目标语言。这些网络分别称为编码器和解码器。将模型分为编码器和解码器的想法至少在 1997 年就被提出 [10],然而训练 RNN 来完成这些角色是一项突破性的进展。
1.5 早期 NMT 模型的局限性
传统的 RNN 存在一些重大限制,因此创建了长短期记忆 (LSTM) 模型来纠正其中的一些问题 [11]。但是,LSTM 仍然使用循环,因此基本问题尚未完全克服。为了生成更强大的模型,需要一个全新的架构:因此开发了 Transformer。从本质上讲,Transformer 旨在解决传统 RNN 和基于 LSTM 的模型的问题。为了了解这些问题是什么以及它们出现的原因,让我们简要了解一下 RNN 和 LSTM 的工作原理。
1.6 — 循环神经网络(RNN):
RNN 是一类基于您可能熟悉的典型前馈架构的神经网络。关键区别在于,循环神经元的输出在每个时间步骤中作为附加输入与输入序列中的下一个值一起传回。因此,RNN 中的信息流被称为双向的,在整个网络中向前和向后流动。这种区别也是术语“前馈”的来源,以明确网络何时不使用这种循环。
下面的动画展示了一个循环神经元,它有一系列输入X 。该序列由值x_t组成,其中t表示当前时间步长。在 NLP 环境中,输入序列可以是一个句子,其中每个值都是一个词嵌入。在第一个时间步长t=0,神经元的输入是x_0。这个输入首先像往常一样对前馈神经元进行处理:将输入乘以权重w_x,并添加偏置项b以形成加权输出。然后,加权输出通过激活函数,对于循环神经元来说,激活函数通常是 S 型或双曲正切函数tanh。然后,输出值y_0在下一个时间步长与输入序列中的下一个值x_1一起传回神经元。对序列中的每个值继续进行此操作,直到所有值都传递到神经元中。
注意:下图显示了一个简化的情况,其中每个词嵌入x_t都是一个数值,而不是一个向量。因此,在每个时间步骤中,我们都可以传入嵌入值,然后使用这个单个神经元迭代到下一个嵌入值。在实际模型中,使用多个循环神经元,每个嵌入维度一个神经元。这些神经元构成了 RNN 的输入层,并允许使用向量嵌入来编码每个词。
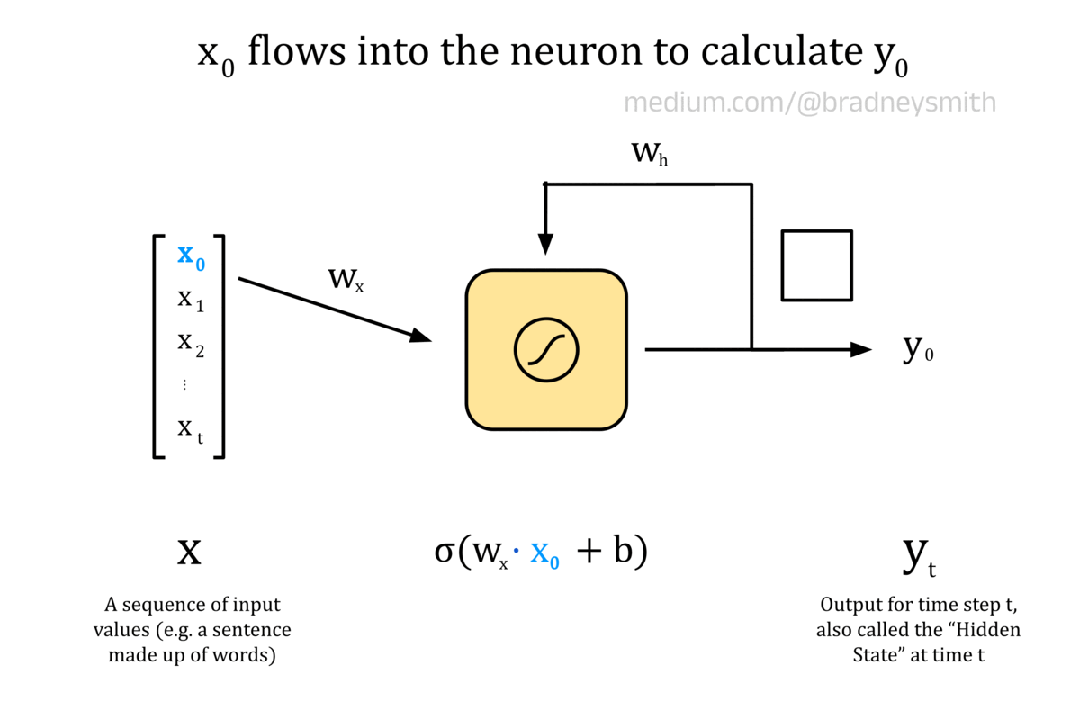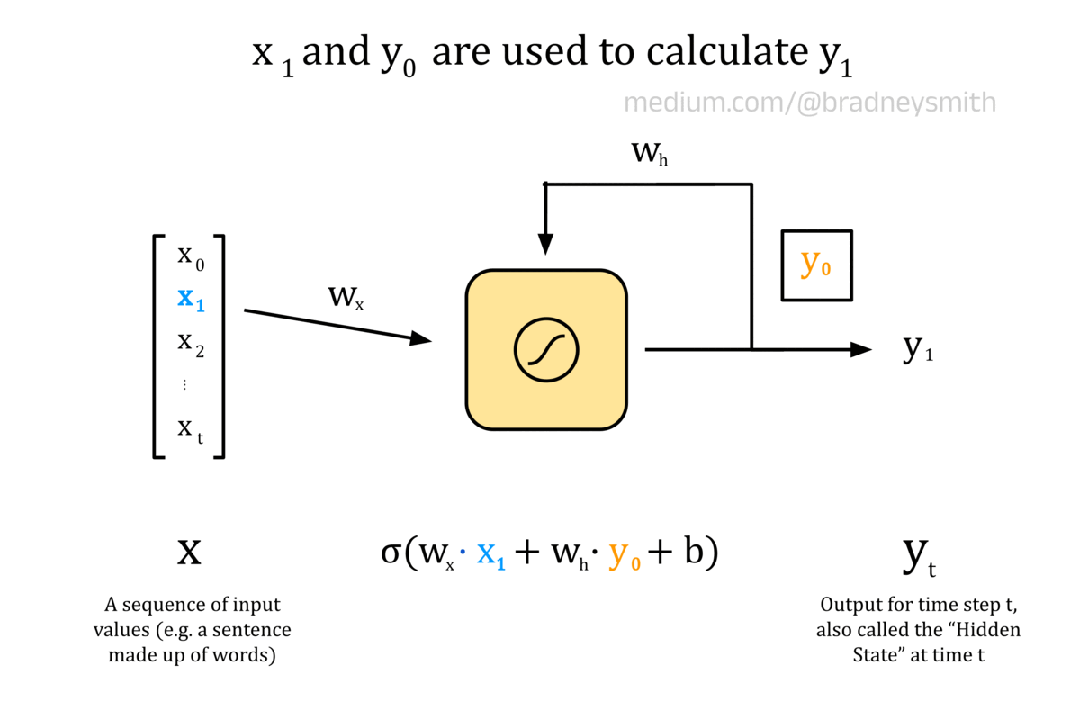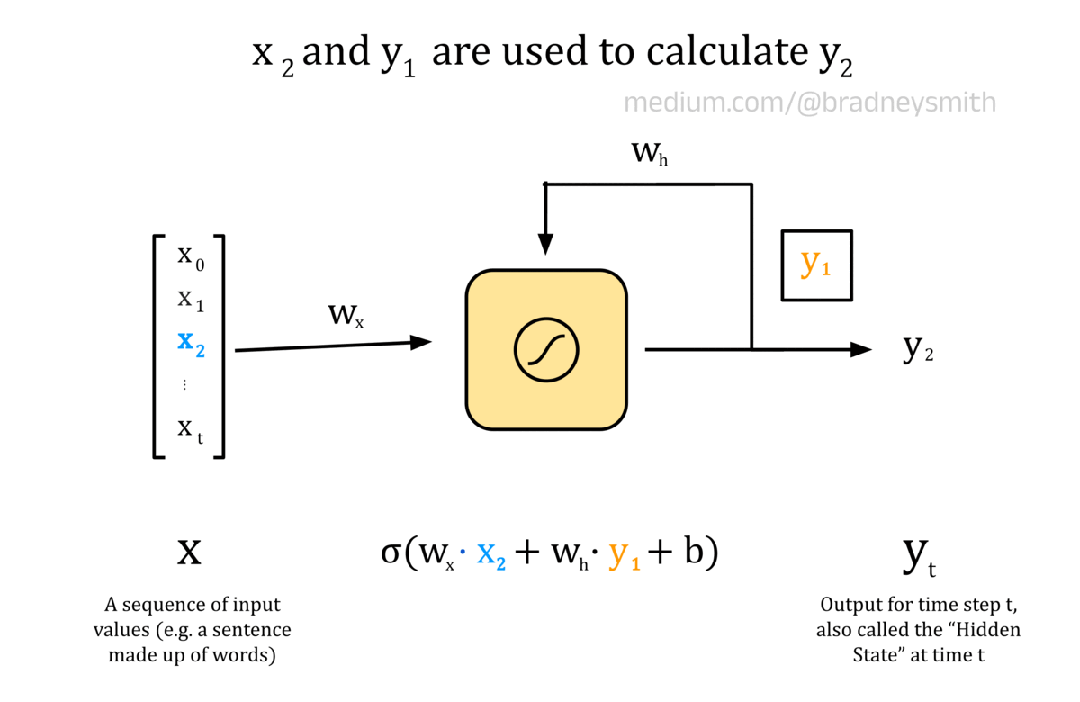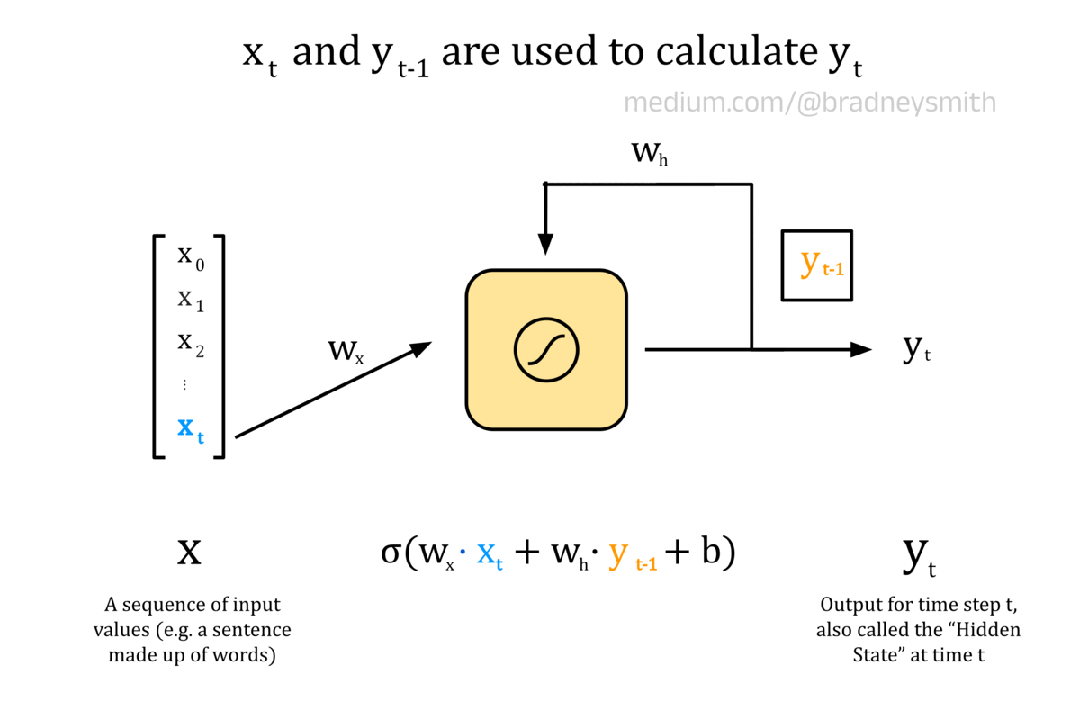
循环神经元的动画
y_0编码了序列中第一个值的一些信息,因此被称为隐藏状态。随着t 的增加,隐藏状态会编码更多关于输入序列中先前值的信息。对于我们的翻译任务,网络将一次传递一个单词的句子,并且每个神经元的输出将根据当前单词x_t以及隐藏状态y_t中编码的句子中的所有先前单词进行计算。与往常一样,权重和偏差项在训练期间使用反向传播迭代改进。循环神经元层连接起来形成 RNN。
1.7 — RNN 的问题:
RNN 有两个主要缺点:
梯度爆炸与消失:
- 回顾一下 RNN 的结构,我们就可以理解这个问题。每个神经元的输出y_t都依赖于神经元的前一个输出y_{t-1}。如果当前输出很大(即大于 2),则下一个输出将会更大。即使只有几个输入,这也会产生复合效应。考虑一个接受 10 个单词的句子的神经元。较大的y_0值将生成更大的y_1值,经过 10 次迭代复合后将产生一个指数级大的结果。这称为梯度爆炸问题。这对于训练网络来说并不理想,因为它会导致梯度下降算法中出现大的发散步骤,而不是收敛到最佳权重和偏差值的小步骤。简单来说,网络将无法很好地训练,因此性能不佳。另一方面,如果当前神经元的输出很小(即小于 1),则所有后续输出都会较小,从而导致梯度消失问题。在这种情况下,梯度下降的步长会太小,因此权重和偏差项永远不会收敛到最佳值。同样,这将导致网络行为不佳。
有限上下文窗口:
- 第二个问题与隐藏状态值有关。对于一个短句,你可以想象隐藏状态的单个浮点值可以捕获有关前面单词的大量信息。但是对于大段落(或整本书),隐藏状态值将不再依赖于早期时间步骤的值,而只捕获最近的输入。这称为有限上下文窗口,在 NLP 的上下文中可以被认为是网络“忘记”了前面的单词和句子。
1.8 - LSTM 的改进和缺点
LSTM 旨在解决上述传统 RNN 的两个问题,但从根本上讲,它仍然是一种循环网络,因此受到此类模型固有局限性的影响。在 LSTM 中,神经元通常被称为单位,以表示每个单元的复杂性增加。单元由三个关键组件组成:输入门、输出门和遗忘门。本文不会深入探讨 LSTM 的复杂性,但为了理解 Transformer,关键要点是与传统 RNN 相比,LSTM 改进了上下文窗口的大小。这意味着输入文本中较早出现的单词被更成功地捕获。但是,上下文窗口的大小仍然有限,因此模型在长输入序列中表现不佳。此外,由于 LSTM 引入了更多必须学习的参数,因此与传统 RNN 相比,训练需要更长的时间。
总而言之,Transformer 的设计是为了解决循环模型的两个局限性:
- 训练时间缓慢
- 有限的上下文窗口大小
2 — 迈向大型语言模型
2.1 — Transformers 如何克服 RNN 和 LSTM 的局限性
Transformers 通过使用巧妙的架构设计和利用并行计算克服了 LSTM 的两个主要问题。为了缩短训练时间,输入序列中的所有值都是同时而不是串行提取的。通过同时处理句子中的每个单词,该模型可以利用并行计算并将训练工作负载分配到 GPU 的多个核心(甚至多个 GPU)上。第二个重大进展是使用注意力机制,即模型如何确定哪些单词为其他单词提供上下文。使用注意力意味着该模型不依赖于随时间衰减的隐藏状态值,而是依赖于可以直接计算的注意力分数矩阵。如果有足够强大的计算机,这可以有效地将上下文窗口扩展到无限大小。
注:标题“Attention is All You Need”指的是之前的研究尝试将各种形式的注意力机制与其他组件相结合,但作者认为这是不必要的。因此,Transformer 是一个完全依赖注意力的模型。
2.2 — 创建“大型”语言模型
Transformer 利用并行化和注意力机制来实现高效训练。速度的提升使模型可以在网络中拥有更多层,从而可以学习输入数据的更复杂表示。因此,Transformer 可以比旧的网络架构大得多,并且包含更多参数(权重和偏差)。参数数量通常以数十亿计,而 Llama 2 7b(具有 70 亿个参数的模型)等模型被视为小型 LLM。使用大量模型参数是这些语言模型“大型”的特征,因此被称为“大型语言模型”。
2.3 — Transformer 的组件
本系列将详细介绍 Transformer 的每个主要组件,但目前,下面给出了一个高层次的总结。为简洁起见,这里省略了一些组件的更详细信息,并在后续文章中详细介绍。
编码器:
Transformer 基于编码器-解码器架构,就像之前基于 RNN 的翻译模型一样。下图取自“Attention is All You Need Paper” [2],分为两个块。左侧的块称为编码器,右侧的块称为解码器。模型的输入(在我们的例子中是句子中的单词)同时传递到编码器。与按顺序传递输入值的基于 RNN 和 LSTM 的模型相比,这显著提高了速度。因此,Transformer 还可以利用并行计算,从而进一步缩短训练时间。
输入嵌入:
输入序列首先被标记化,将句子分成单词和子单词片段(称为标记)。然后将标记映射到固定长度的向量表示(称为嵌入)。在此阶段,每个标记的嵌入都从预先训练的静态词嵌入查找表中提取。这些嵌入通常具有 512 或 768 维,并且至关重要的是,它们不是取自以前的词嵌入模型,例如 word2vec、GloVe 或 FastText。转换器的嵌入(通常称为转换器嵌入)是在模型的训练阶段学习的。一旦标记被映射到嵌入向量,它们就可以传递到下一个组件进行位置编码。
位置编码:
Transformer 同时处理输入,因此会丢失在 RNN 或 LSTM 等顺序模型中获得的词序的内在信息。为了解决这个问题,需要一个额外的组件来为每个输入添加位置信息。原始论文提出使用交替的正弦和余弦函数来编码位置信息,但一些研究表明,无需添加此类编码即可实现类似的性能 [12]。
注意力块:
注意力机制是 transformer 的关键组件,在很大程度上决定了它的成功。注意力是模型为输入和输出序列中的值提供上下文的方法。例如,这个词bank既可以表示储存钱的建筑物,也可以表示河边的草地。这个句子I withdrew money from the bank.有两个关键词,它们提供了我们理解这个句子所需的上下文:withdrew和money。同样,这个句子We sat on the bank and started fishing.通过这个词提供了上下文fishing。Transformer 使用两种注意力:
- 自注意力- 模型确定输入序列中的单词应如何关注输入序列中的其他单词,以便得出上下文
- 交叉注意- 模型确定输出序列中的单词应如何关注输入序列中的单词,以便得出上下文
解码器:
在第一个解码器时间步骤中,解码器接收编码的输入序列并生成一个输出标记。然后将编码的输入与下一个时间步骤的第一个输出标记一起传回解码器。此过程不断重复,直到解码器生成停止标记。然后将标记映射回自然语言单词以生成模型的最终响应。
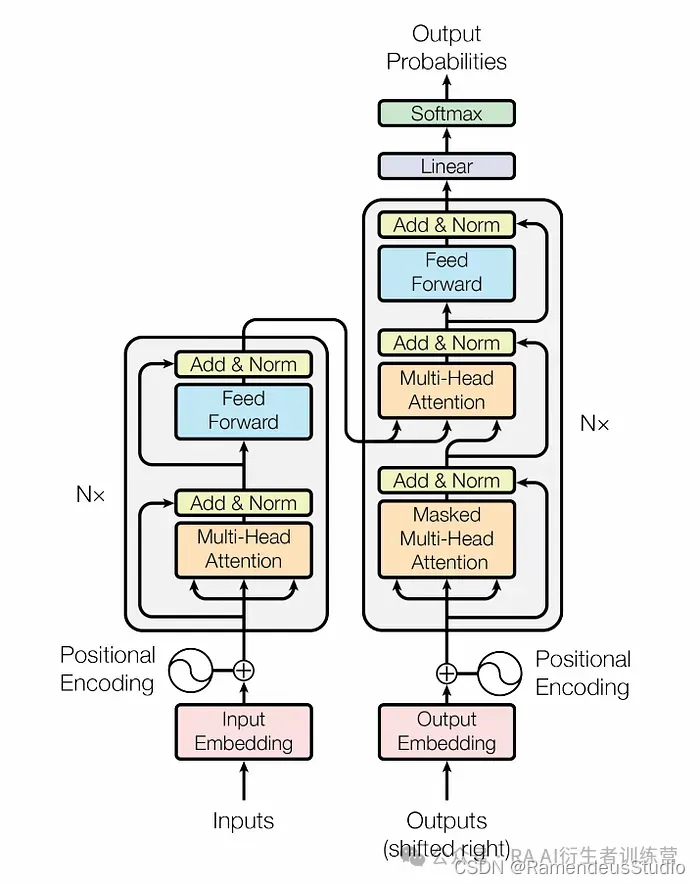
Transformer 架构图 [2]
2.4 — LLM 的进化树
在《注意力就是你所需要的一切》发布后,一波研究开始改进和完善以注意力为中心的 Transformer 设计。
2018 年发布了两个革命性的模型,现在可以被视为第一批现代 LLM:GPT 和 BERT。GPT,即生成式预训练 Transformer(流行的 ChatGPT 的前身),由 OpenAI 于 2018 年 6 月在其论文《通过生成式预训练提高语言理解能力》[13]中发表。GPT 使用仅解码器架构,这意味着该模型忽略了原始 Transformer 设计的编码器部分。四个月后的 2018 年 10 月,谷歌在其论文《BERT:用于语言理解的深度双向 Transformer 的预训练》[14]中发布了他们的模型 BERT,即来自 Transformer 的双向编码器表示。与 GPT 不同,BERT 是一个仅编码器的模型,忽略了 Transformer 的解码器部分。从那时起,Transformer 设计出现了许多新思路,每年都会产生越来越多的架构。下面展示了 LLM“进化树”的图像,重点介绍了过去几年发布的一些比较著名的模型。每个模型都具有独特的架构和预训练目标。但大致可以分为以下几类:仅编码器、仅解码器和编码器-解码器架构。值得注意的是,树的仅解码器分支比仅编码器和编码器-解码器分支的总和还要密集。这可能部分归因于自回归语言建模目标的流行,以及优先生成连贯且上下文丰富的输出序列的任务。这些想法将在后面的文章中得到进一步发展。
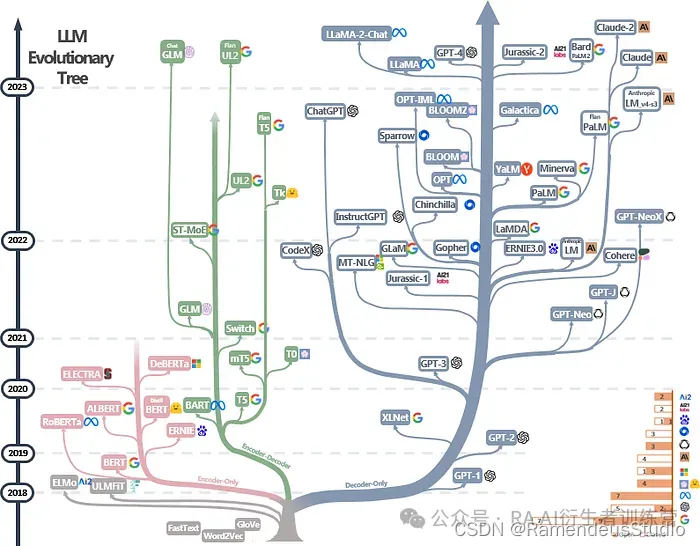
大型语言模型的进化树 [1]
结论
本文回顾了语言模型的历史,从冷战时期的翻译工作一直追溯到当今基于 Transformer 的前沿模型。这样做的目的是激发本系列的后续文章,这些文章将分解 NLP 历史上一些最重要模型的内部工作原理。了解 Transformer 的创建条件有助于理解让我们走到今天这一步的设计决策。未来的文章将探讨使这些模型发挥作用的关键机制,例如自注意力,所以如果您有兴趣了解更多信息,请继续阅读!
欢迎你分享你的作品到我们的平台上: www.shxcj.com 或者 www.2img.ai 让更多的人看到你的才华。
创作不易,觉得不错的话,点个赞吧!!!