作为一名数据工程师,我对测试一些生成式 AI 模型并在本地安装/运行模型很感兴趣。大型语言模型 (LLM) 和视觉语言模型 (VLM) 是最有趣的。OpenAI 提供了 ChatGPT 网站和移动应用程序。微软创建了 Windows 11 Copilot 供我们使用。但是,我们无法控制哪些数据被发送到互联网并存储在他们的数据库中。他们的系统不是开源的,就像神秘的黑匣子一样。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、LLM & VLM模型选择和评测环境
一些慷慨的公司(如 Meta 和 Mistral AI)或个人开源了他们的模型,活跃的社区逐层构建工具,以便我们可以轻松地在家用电脑上运行 LLM 和 VLM。本文(在 Raspberry Pi 上运行本地 LLM 和 VLM)测试了具有 8GB RAM 的 Raspberry Pi 5。它是一台信用卡大小的小型单板计算机 (SBC)。我希望找到更便宜的计算机/解决方案或虚拟机来测试生成令牌或字符的性能,以便它能为我或普通大众提供物有所值的服务。应该考虑的是文本输出速度、文本输出质量和金钱成本。
评估生成的内容由其他研究方完成。就像这个提到的 mistral-7b 在知识、推理和理解方面优于 llama2-13b。这就是为什么我在 LLM 测试中包含 mistral 和 llama2 的原因。
Ollama 目前可以在 macOS、Linux 和 Windows 上的 WSL2 上运行。使用 WSL2 不易控制内存使用率和 CPU 使用率,因此我排除了 WSL2 的测试。生态系统中可以下载多个 LLM 和 VLM 模型。这就是为什么我使用 Ollama 作为测试平台,在多个系统上使用不同的 AI 模型进行基准测试。
Ollama安装非常简单。在终端中,运行以下命令即可:
curl https://ollama.ai/install.sh | sh我构建了一个工具来测试不同系统上 Ollama LLM 生成的 token/sec 的吞吐量。代码 (ollama-benchmark) 用 Python3 编写,并根据 MIT 许可开源。如果你觉得应该添加更多功能或修复错误,请告诉我。文本输出质量可能不容易衡量,因此我在此实验中专注于文本输出速度。(token/s 越高越好)
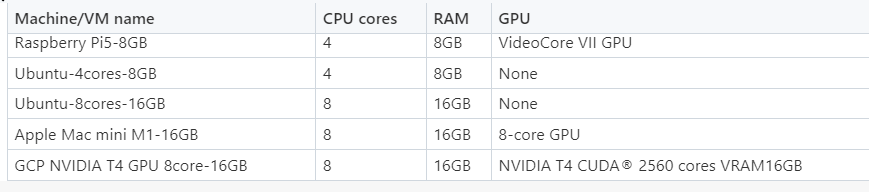
用于测试的机器或虚拟机的技术规格:
- Raspberry Pi 5,8GB RAM((Ubuntu 23.10 64 位操作系统)四核 64 位 Arm CPU)
- Ubuntu 23.10 64 位操作系统,4 核处理器和 8GB RAM,通过安装在 Windows 11 笔记本电脑主机上的 VMware Player 17.5。
- Ubuntu 23.10 64 位操作系统,8 核处理器和 16GB RAM,通过安装在 Windows 11 桌面主机上的 VMware Player 17.5。
- Apple Mac mini(Apple M1 芯片)(macOS Sonoma 14.2.1 操作系统)8 核 CPU(4 个性能核心和 4 个效率核心)、8 核 GPU、16GB RAM
- NVIDIA T4 GPU(Ubuntu 23.10 64 位操作系统)、8 vCPU、16GB RAM
为了使比较更具说服力和一致性,Raspberry Pi 5 安装了 Ubuntu 23.10 64 位操作系统。操作系统安装步骤可参见此视频 :

视频 1:Raspberry Pi 5 安装 Ubuntu 23.10 64 位操作系统
在 Ollama 网站的 llama2 模型页面中,提到了以下内容。
内存要求:
- 7b 参数模型通常需要至少 8GB 的 RAM
- 13b 参数模型通常需要至少 16GB 的 RAM
我们要测试的模型:
- mistral:7b (LLM)
- llama2:7b (LLM)、llama2:13b (LLM)
- llava:7b、llava:13b(图像转文本、图像问答)(VLM)
从内存限制来看,以下是我想在不同机器上测试性能的模型:

示例提示存储在 benchmark.yml 中:
version: 1.0
modeltypes:
- type: instruct
models:
- model: mistral:7b
prompts:
- prompt: Write a step-by-step guide on how to bake a chocolate cake from scratch.
keywords: cooking, recipe
- prompt: Develop a python function that solves the following problem, sudoku game
keywords: python, sudoku
- prompt: Create a dialogue between two characters that discusses economic crisis
keywords: dialogue
- prompt: In a forest, there are brave lions living there. Please continue the story.
keywords: sentence completition
- prompt: I'd like to book a flight for 4 to Seattle in U.S.
keywords: flight booking每一轮,使用 5 个不同的提示来评估输出 token/s。记录 5 个数字的平均值。我首先运行了 Raspberry Pi 5,这是录制的视频 :
视频 2:Raspberry Pi 5 运行 ollama-benchmark
2、基准测试结果
不同模型在不同系统上 token/s 的基准测试总结如下:
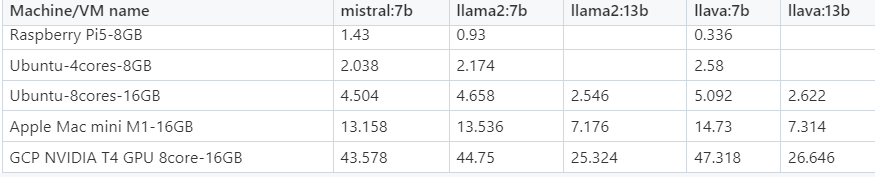
表 3:运行 ollama-benchmark 的机器/虚拟机吞吐量性能结果
关于 LLMs & VLM 推理吞吐量性能结果的思考:
- 从上面的视频中我们可以看到,计算利用率主要发生在 GPU 核心和 GPU VRAM 上。
- 要更快地运行推理,请选择功能强大的 GPU。
- 假设人类与 AI 模型之间的舒适交互伴随着 7 个 token/秒的吞吐量流速,13 个 token/秒的速度对于大多数人来说太快了,如视频 6 所示。
- 未来支持 AI 的操作系统(Copilot)将至少拥有 16GB 的 RAM。AI 的输出有意义/值得信赖,不会太快,也不会太慢。这部分也与微软宣布的消息一致:微软为 AI PC 设置了 16GB 的默认 RAM — 机器还需要 40 TOPS 的 AI 计算:报告。
3、结束语
在本地运行 LLM 不仅可以增强数据安全性和隐私性,还可以为专业人士、开发人员和爱好者打开一个充满可能性的世界。
有了这个吞吐量性能基准,我不会使用 Raspberry Pi 5 作为 LLM 推理机,因为它太慢了。我想说在 Apple Mac mini M1(16GB RAM)上运行 LLM 和 VLM 就足够了。如果你想要更强大的机器来更快地运行 LLM 推理,那就去租用带有 GPU 的云虚拟机吧。
原文链接:本地LLM & VLM性能评测 - BimAnt



















