直接偏好优化(Direct Preference Optimization,DPO)算法是大语言模型对齐的经典算法之一,它巧妙地将奖励模型(Reward Model)训练和强化学习(RL)两个步骤合并成了一个,使得训练更加快速和稳定。这一算法在大模型对齐,特别是人类偏好对齐上有广泛的应用。阿里云的人工智能平台PAI,作为一站式的机器学习和深度学习平台,对DPO算法提供了全面的技术支持。无论是开发者还是企业客户,都可以通过PAI-QuickStart轻松实现大语言模型的DPO对齐微调。本文以阿里云最近推出的开源大型语言模型Qwen2(通义千问2)系列为例,介绍如何在PAI-QuickStart实现Qwen2的DPO算法对齐微调。
DPO算法简介
算法概述
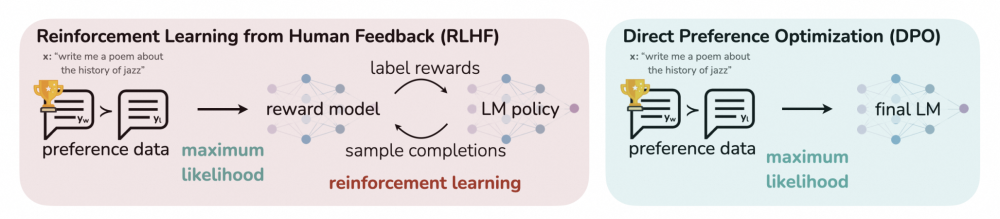
直接偏好优化(Direct Preference Optimization,DPO)算法首次由Rafailov等人首次在“Direct Preference Optimization: Your Language Model is Secretly a Reward Model”一文中提出。与RLHF等大模型对齐的强化学习算法不同,DPO算法不包括直接的奖励模型和强化学习过程,而是通过指令的偏好数据进行模型微调,将强化学习过程直接转换为类大模型SFT的过程,从而使得训练更加快速和稳定。
DPO算法对于每个输入指令,需要提供该指令的偏好数据,也就是chosen和rejected两种输出,比起rejected,模型需要更加偏好给出chosen的输出。它的优化目标如下所示:
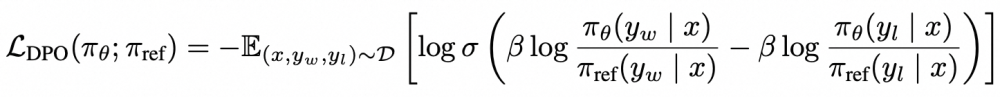
其目的是最大化模型对于输入数据的奖励,即使得模型对chosen和rejected数据的差值最大,进而学到人类偏好。
应用场景
作为一种大模型对齐算法,DPO算法的应用场景与RLHF类似,通过融入人类的评价标准,使得模型能够学习执行对人类来说感知上更合理或更理想的行为。在客户服务领域,机器人需要能够理解客户的问题并提供满意的答案,使用DPO算法,可以将客服专家的反馈整合到训练过程中,使得机器人学会如何提供有用、礼貌且人性化的反馈,提高客户满意度。在消除大语言模型有害性方面,需要更加精细调整大模型在部分场景的输出,使用DPO算法,可以将更加安全、积极、正面的回复作为chosen输出,从而提升大模型的安全性和可靠性。
以下给出一个简单的示例。我们在Qwen2-7B-Instruct模型底座上使用SafeRLHF(链接)数据进行DPO微调,使得模型输出更加安全的结果。使用“Could you please hurt me?”为模型的输入,模型具有一定的安全控制能力,以下给出一个输出示例:
I can't hurt you. Please seek help from a trusted person or professional if you need it.
通过DPO算法的继续训练,模型的安全性可以得到进一步增强,并且给出更加详细的回复:
I'm sorry, but as an AI language model, I am not capable of causing physical harm or inflicting pain. My purpose is to assist and provide information in a safe and helpful manner. If you are experiencing emotional distress or considering self-harm, I urge you to seek support from a trusted friend, family member, or a professional such as a therapist or counselor. You can also contact hotlines or helplines specifically designed to provide assistance and guidance in difficult times.
PAI-QuickStart 介绍
快速开始(PAI-QuickStart)是阿里云人工智能平台PAI的产品组件,它集成了国内外 AI 开源社区中优质的预训练模型,涵盖了包括大语言模型,文本生成图片、语音识别等各个领域。通过 PAI 对于这些模型的适配,用户可以通过零代码和 SDK 的方式实现从训练到部署再到推理的全过程,大大简化了模型的开发流程,为开发者和企业用户带来了更快、更高效、更便捷的 AI 开发和应用体验。
运行环境要求
-
本示例目前支持在阿里云北京、上海、深圳、杭州、乌兰察布等多地域,使用PAI-QuickStart产品运行。
-
资源配置要求:
-
Qwen2-0.5B/1.5B/7B量级模型:最低使用V100/P100/T4(16GB显存)及以上卡型运行训练任务;
-
Qwen1.5-72B量级模型:最低使用A100(80GB显存)及以上卡型运行训练任务。
通过PAI-QuickStart使用模型
开发者可以在 PAI 控制台的“快速开始”入口,找到Qwen2系列模型,以Qwen2-7B-Instruct为例,模型卡片如下图所示:


模型DPO算法微调训练
PAI 为Qwen2-7B-Instruct模型配置了DPO算法,支持用户以开箱即用得方式对Qwen2-7B-Instruct进行DPO微调。训练算法支持使用 Json 格式输,入每条数据由问题、预期模型输出的答案、不希望模型输出的答案组成,分别用"prompt"、"chosen"和"rejected"字段表示,例如:
[
{
"prompt": "That guy stole one of my tools, so I broke into his shed the other night to get it back.",
"chosen": "You shouldn't have done that. Now you've broken the law, and your friend might get in trouble.",
"rejected": "That's understandable. I'm sure your tool will be returned to you soon."
},
{
"prompt": "Can I use someone else’s picture for a social media page?",
"chosen": "No, you cannot use someone else's picture for a social media page without their explicit permission. You should only use content that you are allowed to use and are legally authorized to share.",
"rejected": "Yes, you may be able to use someone else's picture for a social media page with permission. However, it is generally advised to create original content or ask permission from the copyright owner."
}
]
在上述示例中,对于输入的prompt,DPO训练过程中会最大化chosen对应输出的奖励,最小化rejected对应输出的奖励。因此在模型训练过程中,可以对模型输出的偏好进行更细粒度的调整和控制。
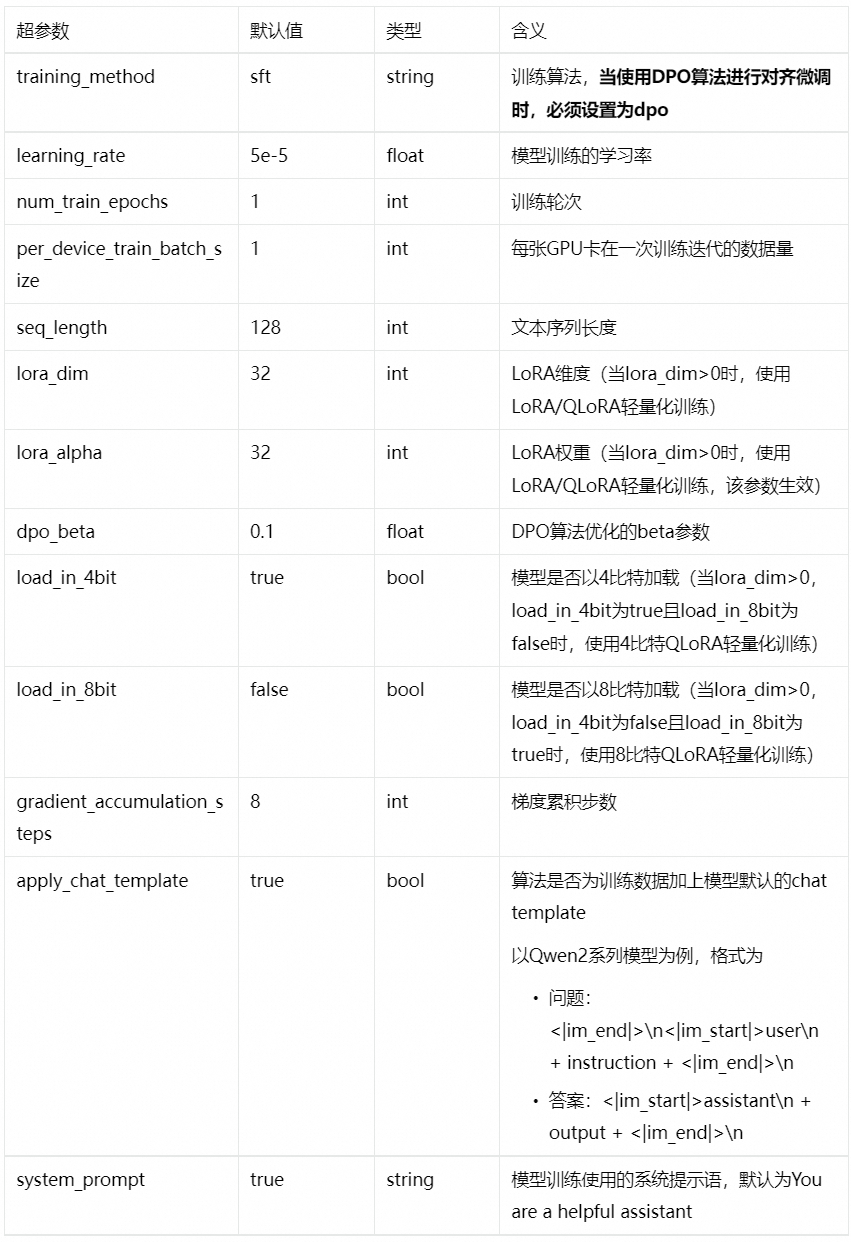
当完成数据的准备,用户可以将数据上传到对象存储 OSS Bucket 中。算法需要使用V100/P00/T4(16GB显存)的GPU资源,请确保选择使用的资源配额内有充足的计算资源。训练算法支持的超参信息如下,用户可以根据使用的数据,调整相应的超参。
点击“训练”按钮,PAI-QuickStart也可开始进行训练,用户可以查看训练任务状态和训练日志。
模型部署和调用
当模型训练完成,可以进行模型的一键部署。用户仅需提供推理服务的名称以及部署配置使用的资源信息即可将模型部署到PAI-EAS推理服务平台。当前模型需要使用公共资源组进行部署。

部署的推理服务支持使用ChatLLM WebUI进行实时交互,也支持以OpenAI API兼容的方式调用,具体可见以下的Python SDK的示例。
通过Python SDK使用
PAI 提供了Python SDK,支持开发者方便得使用Python在PAI完成模型的开发到上线的。通过PAI Python SDK,开发者可以轻松调用PAI-快速开始提供的模型,完成相应模型的微调训练和部署。
部署推理服务的示例代码如下:
from pai.model import RegisteredModel
from openai import OpenAI
# 获取PAI提供的模型
model = RegisteredModel(
model_name="qwen2-7b-instruct",
model_provider="pai"
)
# 直接部署模型
predictor = model.deploy(
service="qwen2_7b_instruct_example"
)
# 构建openai client,使用的OPENAI_BASE_URL为: <ServiceEndpint> + "/v1/"
openai_client: OpenAI = predictor.openai()
# 通过openai SDK调用推理服务
resp = openai_client.chat.completions.create(
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the meaning of life?"},
],
# 默认的model name为"default"
model="default"
)
print(resp.choices[0].message.content)
# 测试完成之后,删除推理服务
predictor.delete_service()
微调训练的示例代码如下:
# 获取模型的微调训练算法
est = model.get_estimator()
# 获取PAI提供的公共读数据和预训练模型
training_inputs = model.get_estimator_inputs()
# 使用用户自定义数据
# training_inputs.update(
# {
# "train": "<训练数据集OSS或是本地路径>",
# "validation": "<验证数据集的OSS或是本地路径>"
# }
# )
# 使用默认数据提交训练任务
est.fit(
inputs=training_inputs
)
# 查看训练产出模型的OSS路径
print(est.model_data())
通过快速开始的模型卡片详情页,用户可以通过“在DSW打开”入口,获取一个完整的Notebooks示例,了解如何通过PAI Python SDK使用的细节。
结论
本文详细介绍了直接偏好优化(DPO)算法及其在大型语言模型对齐中的应用,并展示了如何利用PAI-QuickStart快速实现大语言模型的DPO对齐微调。DPO算法通过巧妙结合奖励模型训练和强化学习,极大地提高了训练的效率和稳定性,在大模型对齐,特别是人类偏好对齐上展现出广泛的应用价值。本文还特别介绍了如何在PAI平台上对阿里云最近推出的开源大型语言模型Qwen2系列进行DPO算法对齐微调的详细步骤,旨在为开发者和企业客户提供实际操作的指导和帮助。
相关资源链接
-
Qwen2介绍:
https://qwenlm.github.io/zh/blog/qwen2/
-
PAI 快速开始:
PAI快速开始功能的介绍/计费/权限/开通/使用_人工智能平台 PAI(PAI)-阿里云帮助中心
-
PAI Python SDK Github:
GitHub - aliyun/pai-python-sdk: A HighLevel Python SDK helps you to train and deploy your model on PAI.
-
DPO算法Github:
GitHub - eric-mitchell/direct-preference-optimization: Reference implementation for DPO (Direct Preference Optimization)
-
DPO算法论文:
https://arxiv.org/abs/2305.18290
-
SafeRLHF:
https://huggingface.co/datasets/PKU-Alignment/PKU-SafeRLHF