「AI秘籍」系列课程:
-
人工智能应用数学基础
-
人工智能Python基础
-
人工智能基础核心知识
-
人工智能BI核心知识
-
人工智能CV核心知识
多项式回归的过度拟合及其避免方法
通过添加现有特征的幂,多项式回归可以帮助你充分利用数据集。它允许我们甚至使用简单的模型(如线性回归)来建模非线性关系。这可以提高模型的准确性,但如果使用不当,可能会发生过度拟合。我们希望避免这种情况,因为它会导致你的模型在未来表现不佳。
在本文中,我们将解释多项式回归的概念,并说明它如何导致过度拟合。我们还将讨论一些可用于避免过度拟合的技术。这些包括使用 k 倍交叉验证或保留集,但最重要的是,我们将讨论如何应用领域知识来帮助你避免过度拟合。在文章我不会讨论任何代码,但是你可以在GitHub1上找到完整的项目,本文项目 polynomial_regression_overfitting.ipynb。
什么是多项式回归?
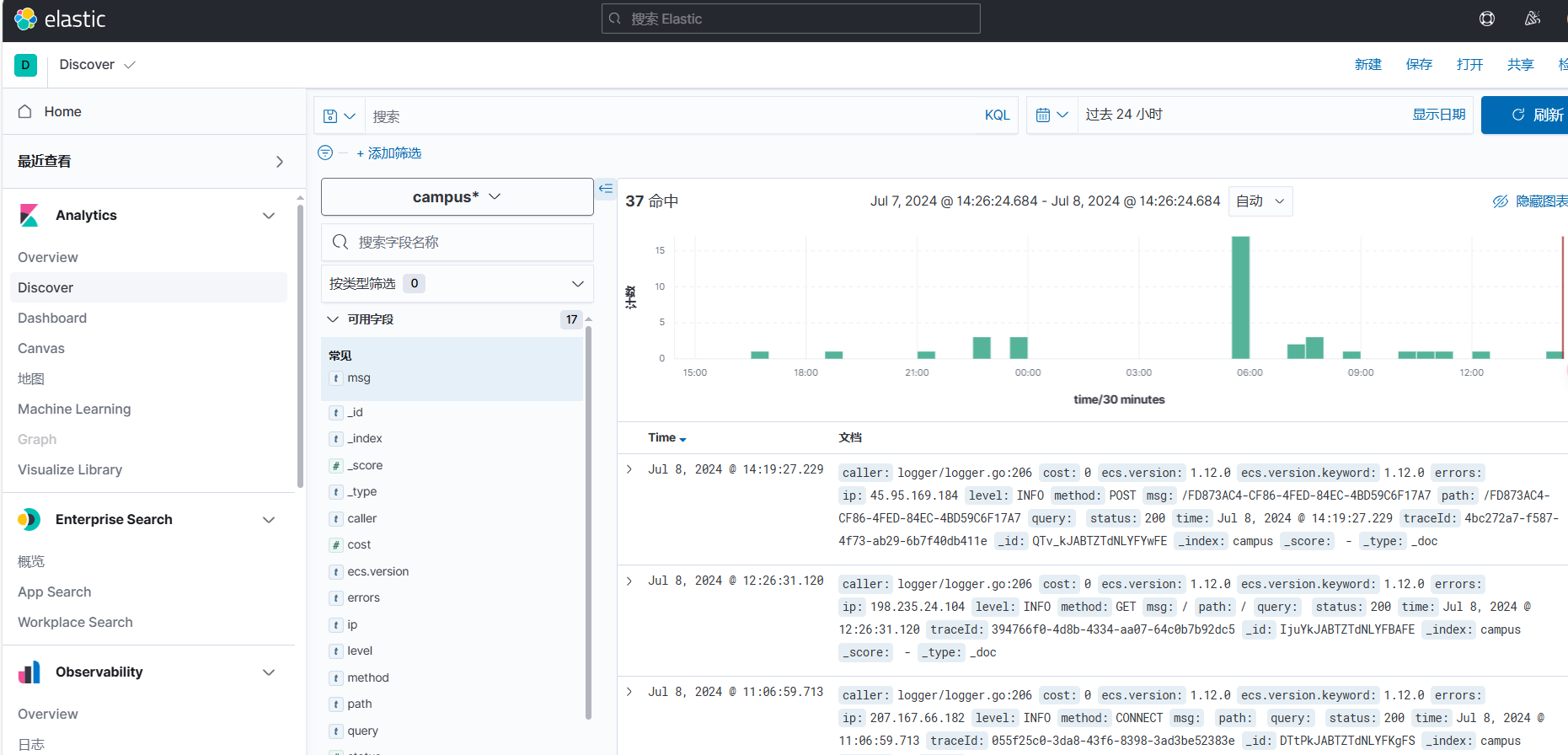
让我们通过将一些线性回归模型拟合到数据集来直接深入研究这个概念。我们将使用一个房地产估价数据集2,其中包含有关已售出的 414 栋房屋的信息。为了简单起见,我们只看两个变量——单位面积房价和房屋年龄。我们可以在下面的图 1 中看到这两个变量之间的关系。这个想法是使用房屋房龄来预测价格。
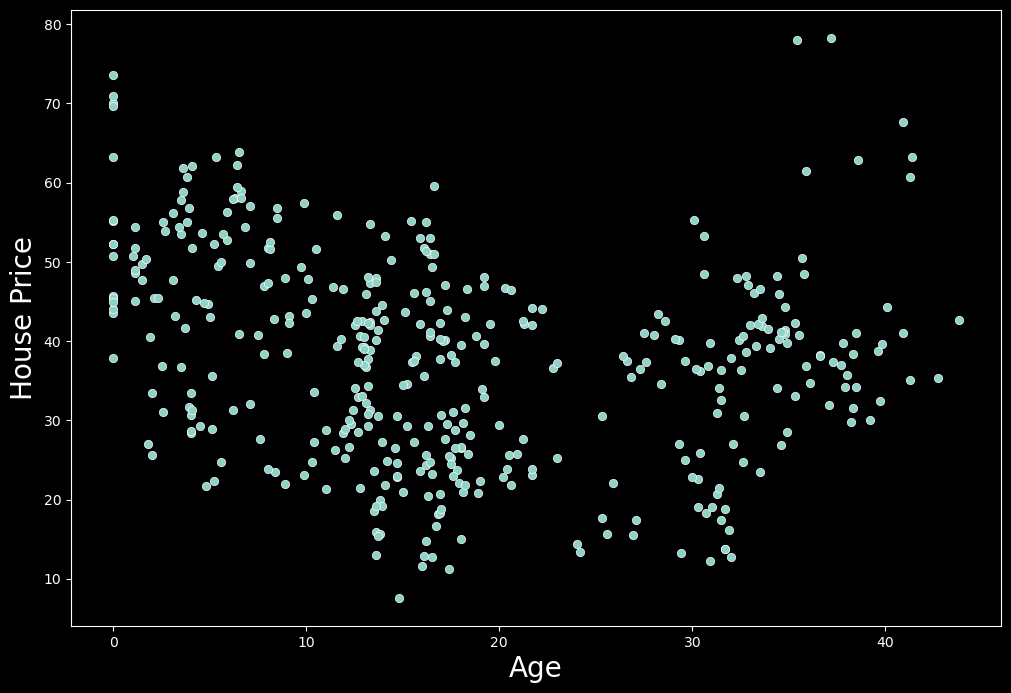
从图 1 可以看出,这两个变量之间似乎不存在线性关系。这意味着这种关系不能用直线表示。在我们的例子中,房价最初随着房龄的增长而下降。然而,大约 25 年后,房价开始随着房龄的增长而上涨。这表明这种关系可能是二次的。在开始建模之前,让我们讨论一下为什么会这样。我们稍后会看到,当涉及到多项式回归时,对数据中的关系有充分的理由/理由很重要。
最初的行为是有道理的。随着房屋的老化,它们会变得越来越破旧,价值也会下降。房地产专家对此有更好的理解,但也许经过较长时间后,房屋就会变得古老。随着人们开始重视房屋的悠久历史,它们的房龄会增加价值。也可能存在一些选择偏差,这可以解释这种上升趋势。也就是说,昂贵的房屋往往不会被拆除,因此唯一出售的老房子就是这些昂贵的房屋。
标准线性回归
无论出于什么原因,由于关系不是线性的,我们不会指望标准线性模型能很好地完成这项工作。让我们尝试使用线性回归仅使用房龄来模拟房价,以证明这一点。我们这样做:
- 将数据集随机分成训练集(70%)和测试集(30%)。
- 使用训练集对模型进行训练。
- 通过对测试集进行预测并计算 MSE 来评估模型[。](https://en.wikipedia.org/wiki/Mean_squared_error#:~:text=In statistics%2C the mean squared,values and the actual value.)
按照这个过程,我们最终会得到一个由以下方程表示的模型:
p
r
i
c
e
=
β
1
(
a
g
e
)
+
β
0
price = \beta_1(age)+\beta_0
price=β1(age)+β0
其中 β₁ 和 β₀ 是模型估计的参数。这个方程也可以称为模型的预测线。它给出了给定房龄的预测房价。
在图 2 中,我们可以看到在数据集上使用此模型的结果。这里,红线表示预测线。查看这条线,我们发现该模型在捕捉潜在的二次趋势方面做得很差。我们可以使用测试集 MSE 总结该模型的准确性,即 145.91。
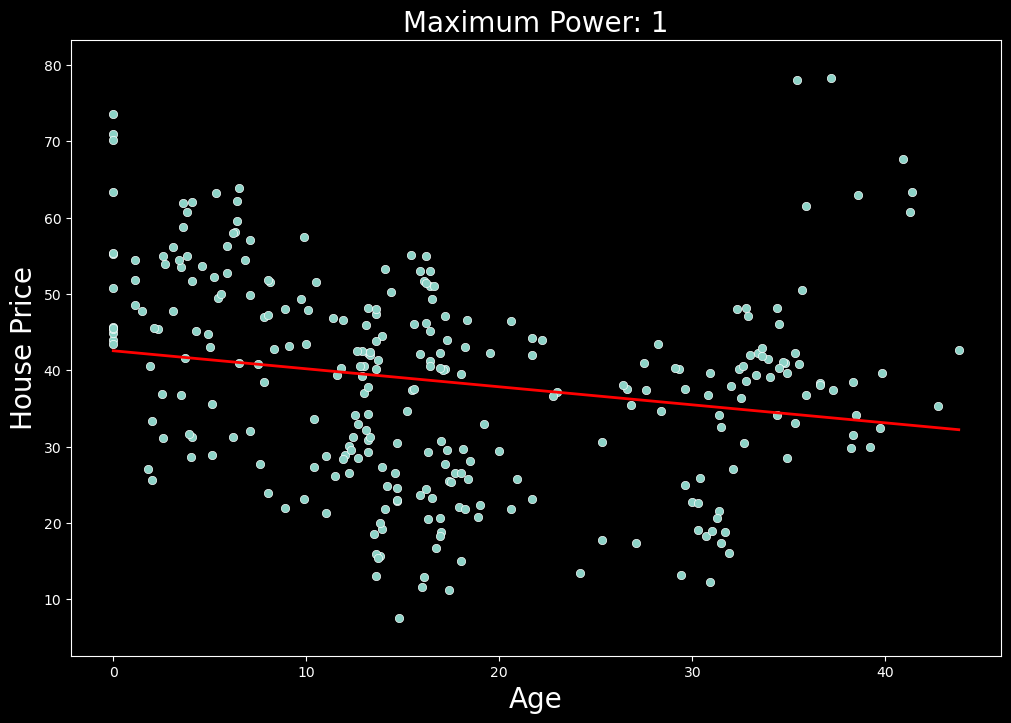
多项式回归
现在让我们尝试使用多项式回归来改进我们的模型。最终,由于关系似乎是二次的,我们期望以下方程能做得更好:
p
r
i
c
e
=
β
2
(
a
g
e
2
)
+
β
1
(
a
g
e
)
+
β
0
price = \beta_2(age^2) + \beta_1(age) + \beta_0
price=β2(age2)+β1(age)+β0
问题是,如果我们对当前数据集使用线性回归,就不可能得到这样的方程。为了解决这个问题,我们可以简单地在数据集中添加一个新变量
a
g
e
2
age^2
age2。为了避免混淆,我们将其重新标记为 age_squared。添加此功能后,我们可以将非线性方程重写为线性方程:
p
r
i
c
e
=
β
2
(
a
g
e
_
s
q
u
a
r
e
d
)
+
β
1
(
a
g
e
)
+
β
0
price = \beta_2(age\_squared)+\beta_1(age)+\beta_0
price=β2(age_squared)+β1(age)+β0
我们现在有两个变量(即 age_squared 和 age)的线性函数,它实际上是一个变量(即 age)的非线性函数。这使我们能够像以前一样使用线性回归来估计 β 参数。我们可以在图 3 中看到生成的预测线。在这种情况下,测试 MSE 为 127.42,比我们之前的模型低 13%。因此,这个新模型在预测房价方面做得更好。
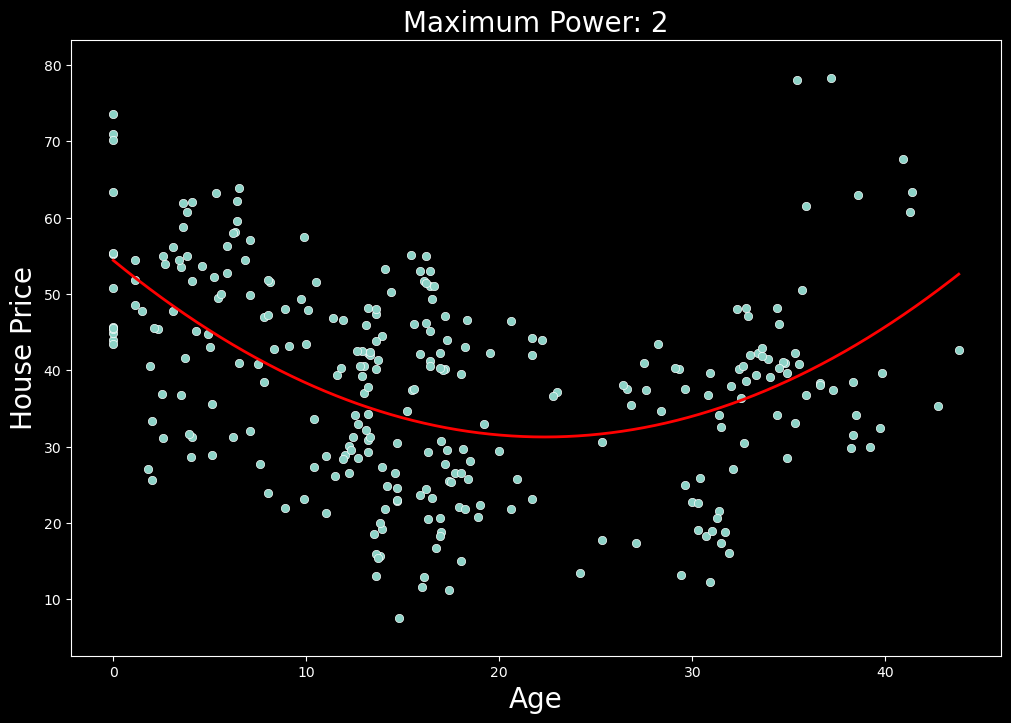
通过使用这个新特征
a
g
e
2
age^2
age2,我们正在进行多项式回归。概括地说,每当你使用 n 次多项式来模拟目标和特征之间的关系时,你都会进行多项式回归。例如:
p
r
i
c
e
=
β
n
(
a
g
e
n
)
+
.
.
.
+
β
2
(
a
g
e
2
)
+
β
1
(
a
g
e
)
+
β
0
price = \beta_n(age^n) + ...+ \beta_2(age^2) + \beta_1(age)+\beta_0
price=βn(agen)+...+β2(age2)+β1(age)+β0
通过添加这些特征,我们可以在数据集中建模更复杂的关系。在上面的模型中,
n
=
2
n = 2
n=2,但使用更高次多项式可能会获得更好的结果。话虽如此,通过添加更多特征,我们也可能最终过度拟合数据。
多项式回归的过度拟合
当模型与训练数据集的拟合度过高时,我们就说模型过度拟合了。模型会捕捉数据中的噪声,而不仅仅是潜在的趋势。其结果是,模型在训练数据集上可能表现良好,但在测试数据集上则表现不佳。事实上,我们不会期望模型在任何未经训练的数据集上表现良好。
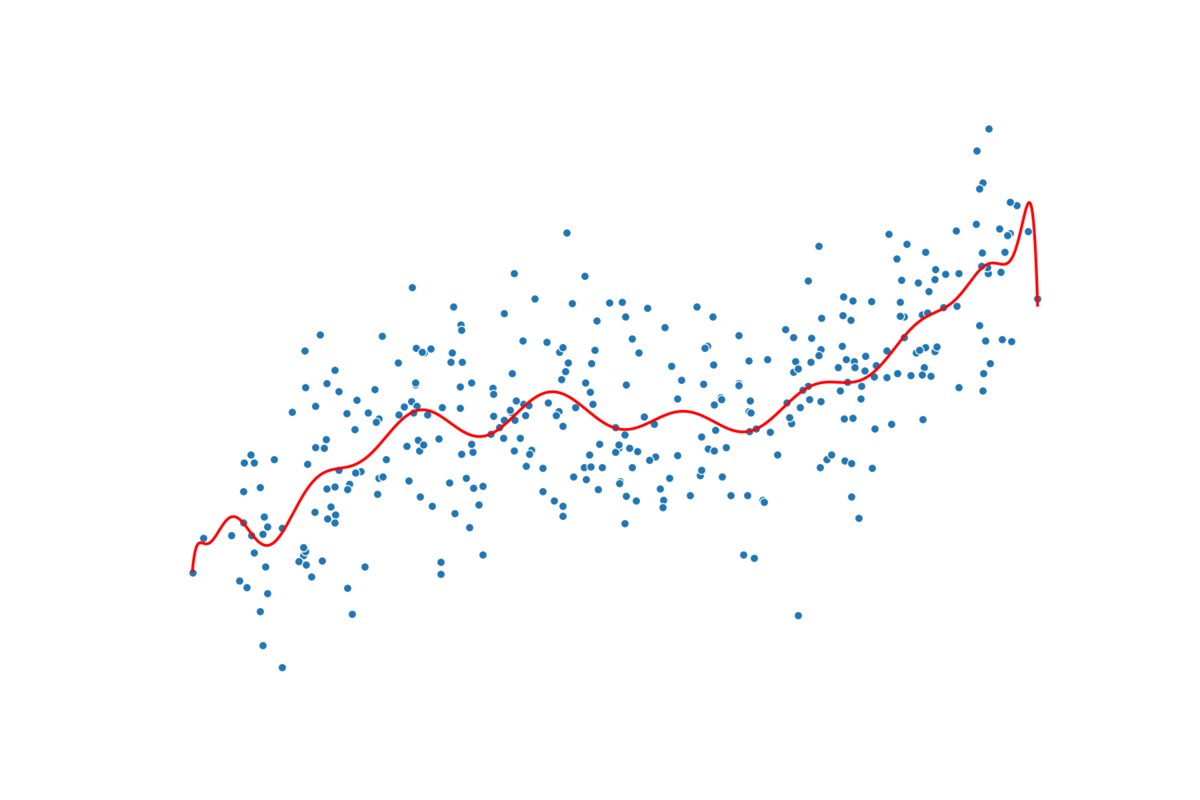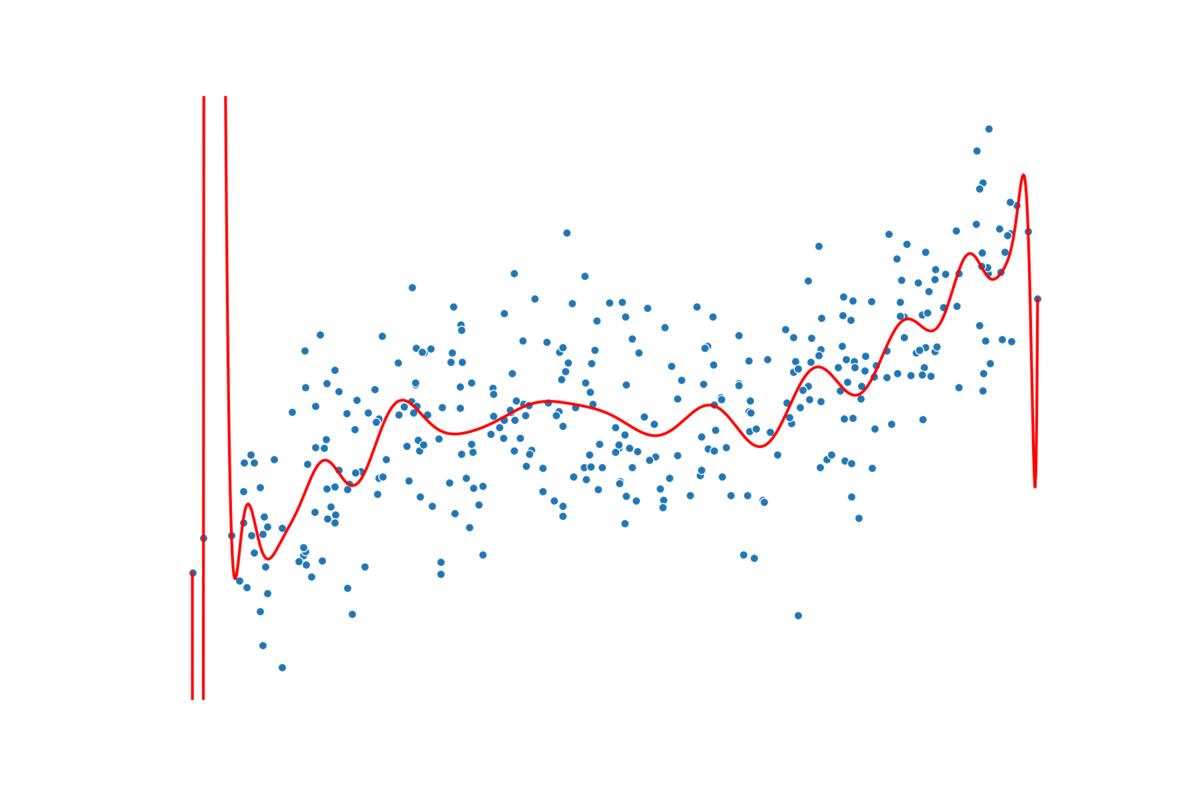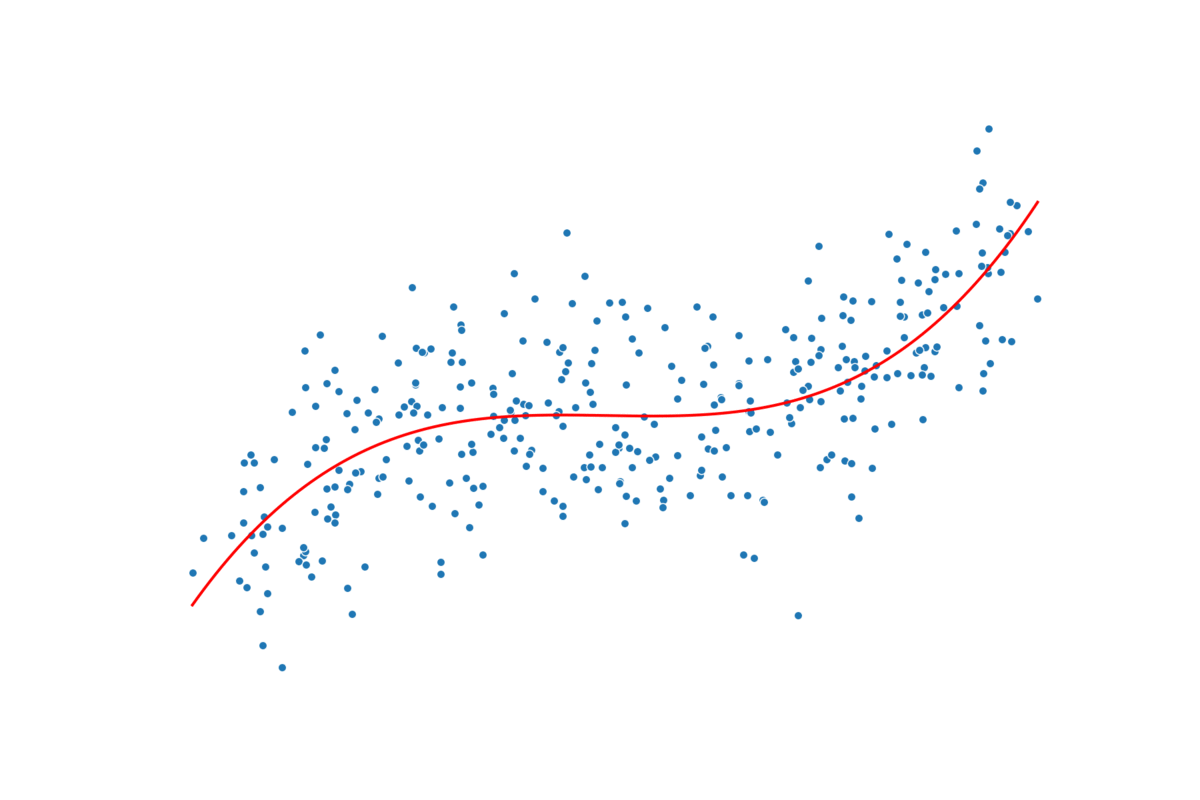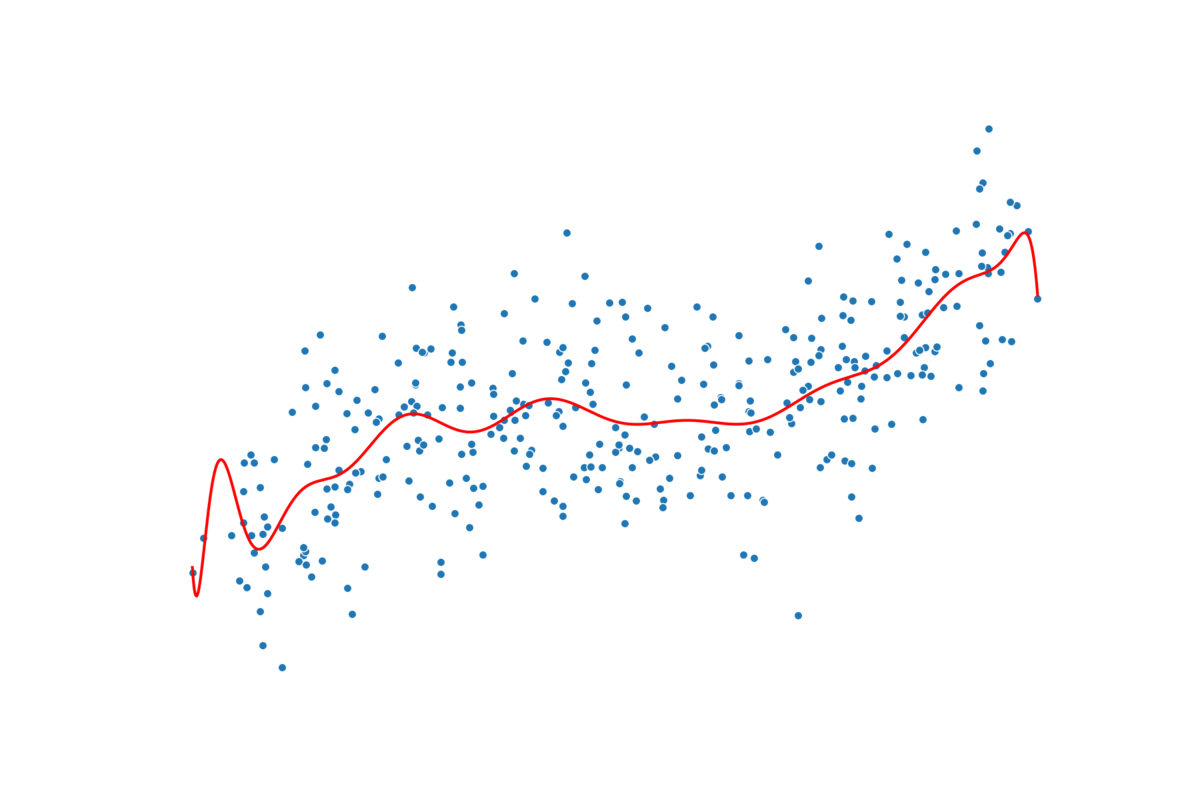
过度拟合通常是因为模型太复杂或特征太多。随着特征的增加,过度拟合的可能性就越大。在多项式回归中,增加次数也会出现同样的情况。在图 3 中,你可以看到我的意思。我们遵循相同的建模过程,但每一步都会增加多项式的次数。我们从 n=1 开始,以 n=25 结束。请注意,随着次数的增加,预测线会变得更加扭曲。
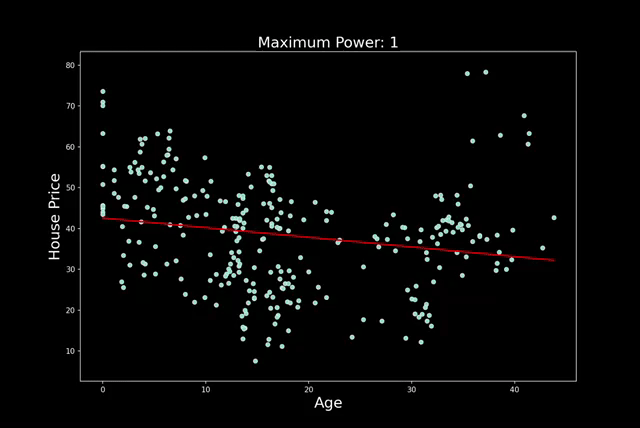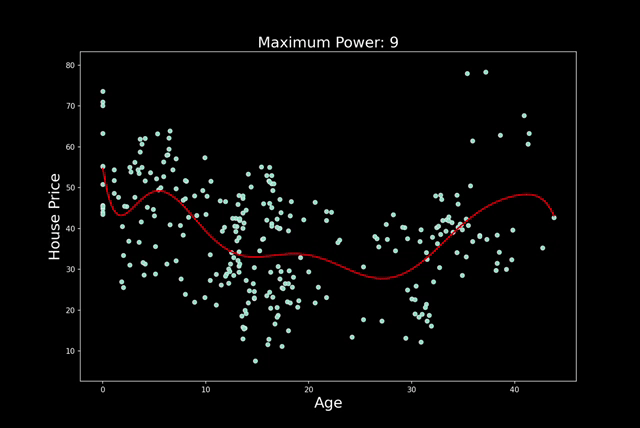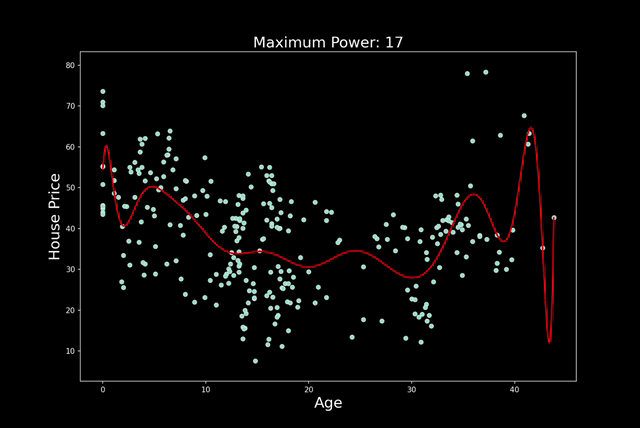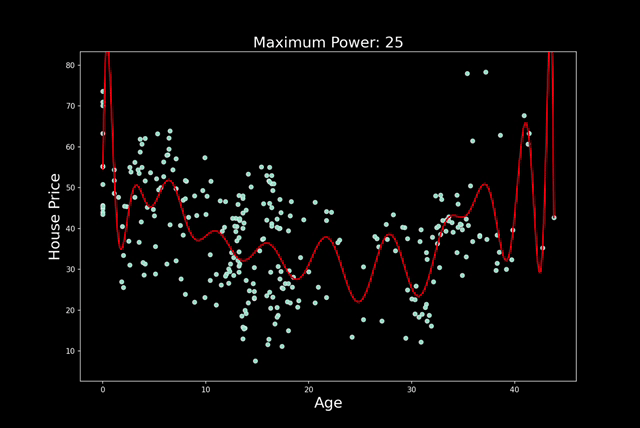
实际情况是,随着阶数的增加,模型可以拥有更多转折点。2 阶多项式有 1 个转折点,3 阶多项式有 2 个转折点,依此类推……每增加一个转折点,我们就会给予模型更多自由,使其更贴近训练数据集。对于更高的阶数,模型可能只是捕捉噪音。真正的潜在趋势不太可能如此复杂。
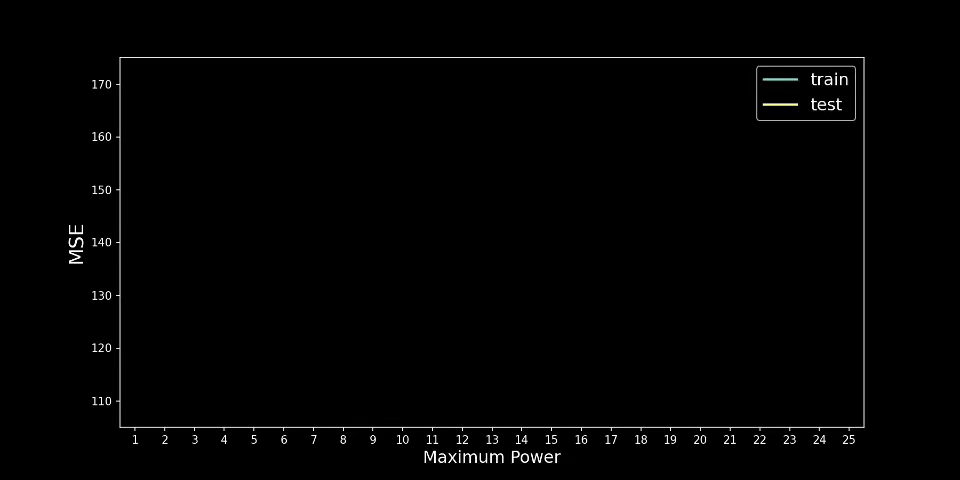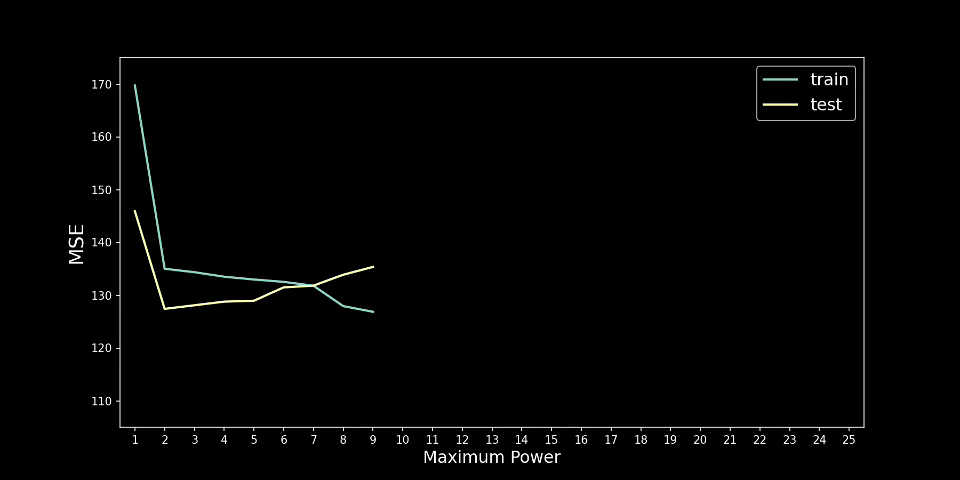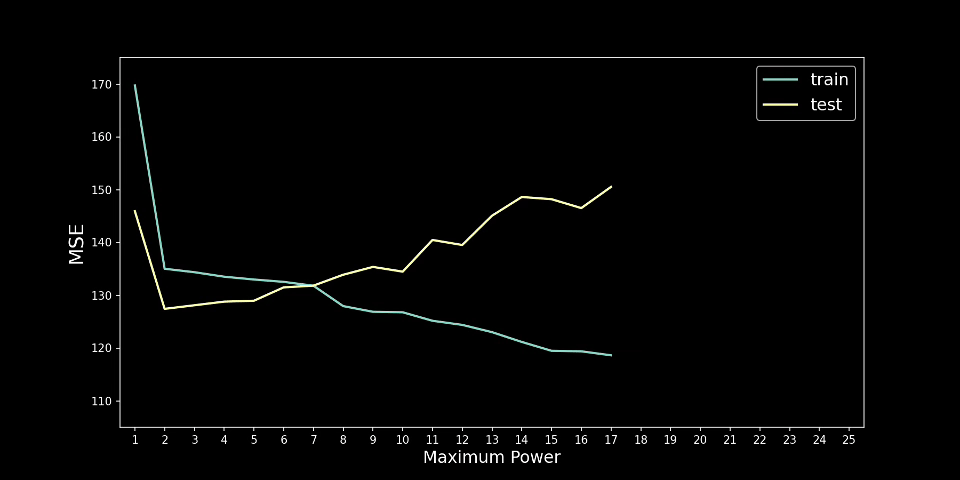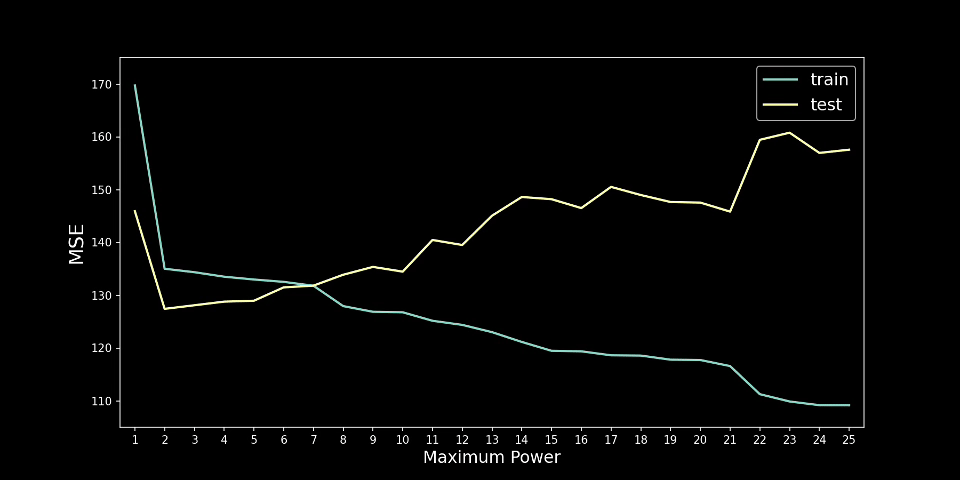
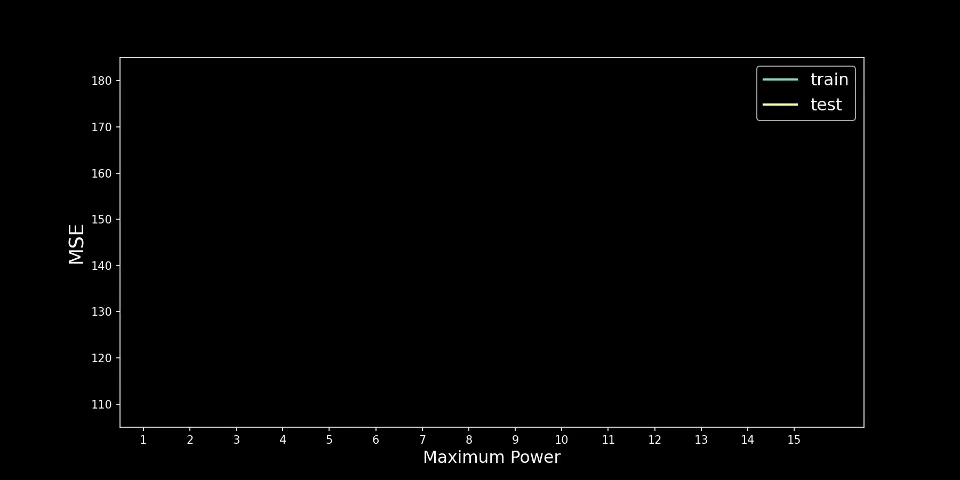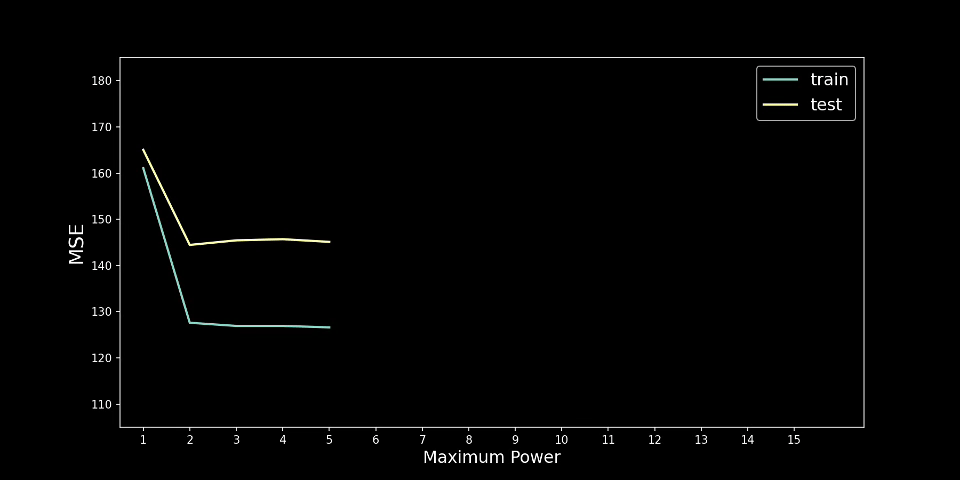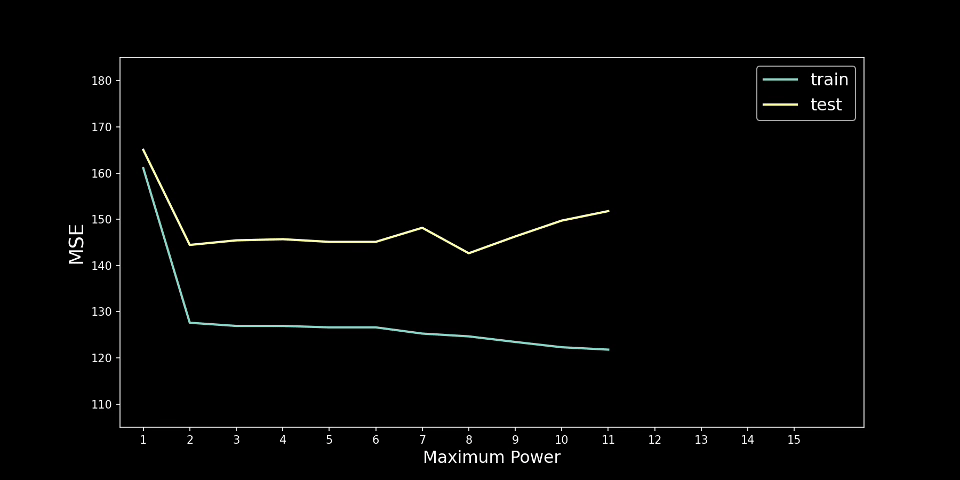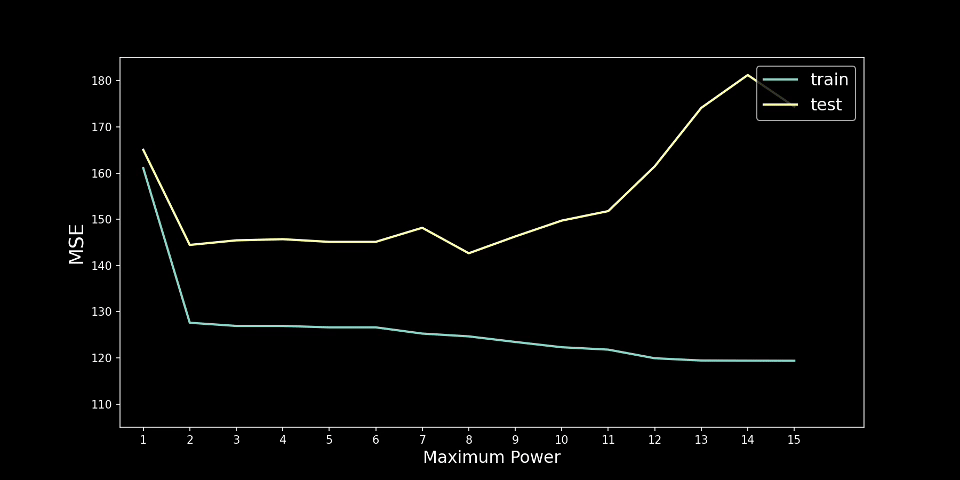
另一种可视化方法是查看训练和测试集上的 MSE。如图 4 所示,训练 MSE 趋于随着程度的增加而减小。这意味着模型在训练集上变得越来越准确。测试 MSE 讲述了一个不同的故事。当 n=2 时,测试 MSE 最小,然后趋于增加。这意味着模型在测试集上的表现越来越差。换句话说,随着我们增加程度,模型变得越来越过度拟合。
如何避免过度拟合
我们已经看到了多项式回归可能出错的原因。现在的问题是,我们如何选择正确的程度并避免过度拟合。与任何机器学习模型一样,我们希望训练一个具有在测试集和训练集上表现良好的特征组合的模型。这样,选择多项式回归的最佳特征的过程与任何其他机器学习问题没有什么不同。
Hold-out set
一种常见的方法是使用Hold-out set。说实话,我也不太清楚这个应该怎么翻译,如果是按字面翻译的话,我们应该称呼它为「保留集」。对于这种方法,数据集被分成训练集和保留集/测试集。对于不同的特征集,模型在训练集上进行训练,在测试集上进行评估。我们使用一些指标(例如 MSE)来评估性能。我们通常会选择在测试集上表现最好的特征集。
看看上面所做的工作,我们可以将此方法应用于房价示例。在这种情况下,n=2 的模型具有最小的测试 MSE。这意味着我们将在最终模型中仅使用 a g e 2 age^2 age2 和 a g e age age。这似乎是一个合理的结果,因为真正的潜在趋势似乎是二次的。我们还提出了一些逻辑理由来支持这一结果。
K 折交叉验证
类似的方法是使用 k 折交叉验证。在这里,我们将数据集划分为大小相等的 k 个子集\折叠。然后,我们在 k-1 折叠上进行训练,并计算剩余折叠的 MSE。我们重复此步骤 k 次,以便每个折叠都轮流作为测试集。模型的最终得分将是所有测试折叠的 MSE 的平均值。平均 MSE 最低的模型将被选为最终模型。图 5 显示了如何使用 5 倍交叉验证划分数据集的示例。在这种情况下,我们将计算 5 个测试折叠的平均 MSE。

领域知识和常识
使用保留集和 k 折交叉验证通常可以得到一个好的模型。但数据很混乱,可能会出现统计异常。如果只是盲目使用这些方法而不考虑你的问题,你仍然会偶然得到一个糟糕的模型。到目前为止,我们已经使用一个特定的训练测试分割进行了上述分析。在这种情况下,我们得出结论, a g e 2 age^2 age2 的模型是最好的。但如果我们使用不同的随机训练测试分割会怎样?
你可以在图 6 中看到我们的意思。这里我们遵循与之前完全相同的过程,只是这次我们使用了不同的随机训练测试分割。在这种情况下,测试 MSE 在 n = 8 时最低。通过仅使用保留方法,我们将使用它作为最终模型。
此时,你应该问自己,使用 8 次多项式是否合乎逻辑。我们的预测线将采用以下形式:
p
r
i
c
e
=
β
8
(
a
g
e
8
)
+
β
7
(
a
g
e
7
)
+
.
.
.
+
β
1
(
a
g
e
)
+
β
0
price = \beta_8(age^8) + \beta_7(age^7) + ... + \beta_1(age) + \beta_0
price=β8(age8)+β7(age7)+...+β1(age)+β0
价格和房龄之间的关系真的那么复杂吗?还是上述结果只是统计异常?答案可能是后者,这强调了为什么我们不应该仅仅依赖像 K 折交叉验证这样的方法。
在选择特征时,考虑你的问题并应用任何领域知识非常重要。在我们的房价示例中,n = 2 的模型似乎捕捉到了潜在趋势。我们还提出了这种关系的一些很好的潜在原因。考虑到这一点,这个模型可能更好。一般来说,如果你包含的特征有逻辑上的原因说明它们为什么具有预测性,那么你就不太可能捕获噪音和过度拟合。
更多K 折交叉验证的内容,可以查看「AI 企业项目实战」中第三章的相关课程。

参考
茶桁的公共文章项目仓库:https://github.com/hivandu/public_articles ↩︎
Dataset: https://archive.ics.uci.edu/ml/datasets/Real+estate+valuation+data+set ↩︎