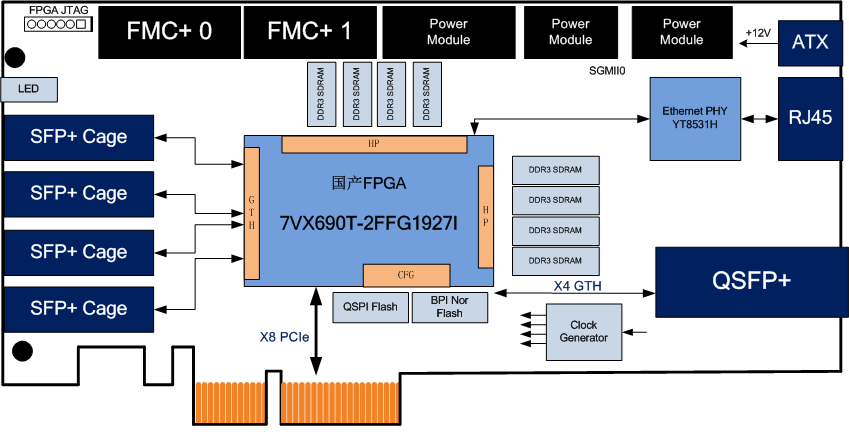
1.1 简介
GoogLeNet(有时也称为GoogleNet或Inception Net)是一种深度学习架构,由Google的研究团队在2014年提出,主要设计者为Christian Szegedy等人。这个模型是在当年的ImageNet大规模视觉识别挑战赛(ILSVRC)中获得冠军(亚军为VGG)的网络结构,因其在图像分类任务上展现出了卓越的性能而备受瞩目。
主要特点与创新点:
-
Inception模块:GoogLeNet的核心创新是引入了名为"Inception"的模块。这些模块通过并行地使用不同大小的卷积核(例如1x1, 3x3, 5x5)和最大池化操作(通常为3x3),能够在同一层级捕捉不同尺度的特征信息,从而显著增加了网络的宽度(即每层的特征通道数),同时保持了相对浅的深度,以控制过拟合风险和计算复杂度。
-
1x1卷积核的降维应用:为了减少计算成本和控制模型复杂度,Inception模块中巧妙地利用了1x1卷积核进行降维。这种操作在执行更复杂的卷积(如3x3, 5x5)之前减少输入数据的通道数,既降低了计算负担,又保持了模型的表达能力。
-
无全连接层:与早期的深度学习模型(如AlexNet、VGG)不同,GoogLeNet摒弃了传统的全连接层,转而使用全局平均池化(Global Average Pooling)来直接从特征图中提取分类信息。这一改变大幅减少了网络参数的数量,提升了模型的泛化能力和训练效率。
-
辅助分类器(Auxiliary Classifiers):为了改善梯度流并促进网络内部的训练,GoogLeNet还在网络中间位置加入了辅助分类器。这些辅助输出层有助于提供额外的正则化效果,并在训练过程中辅助主分类器学习,尽管在实际预测时通常不使用它们的输出。
-
参数效率:尽管具有较深的网络结构(共22层),GoogLeNet通过上述设计优化,成功地将模型参数数量控制在一个相对较低的水平,大约是AlexNet参数量的1/12,这对于计算资源和内存使用而言是一大优势。
GoogLeNet的成功不仅在于其在图像分类任务上的表现,还因为它所开创的设计理念影响了后续一系列深度学习模型的发展,包括后续的Inception V2、V3、V4等版本,这些版本不断优化了原始架构,提高了性能和效率。
该模型出自《Going deeper with convolutions》。
(注:inception这个名字取自盗梦空间,论文的题目也是取自盗梦空间的一句台词“we need to go deeper”,l论文的参考文献第一个就是引用了一个盗梦空间的meme图)




1.2 Inception 模块
Inception模块的设计初衷是为了解决深度学习网络中常见的几个问题,包括计算量大、参数过多导致的过拟合风险以及模型效率。以下是Inception模块的基本原理和设计理念:
原理概述
Inception模块的核心思想是同时使用多个不同大小的卷积核以及池化操作来提取特征,以此实现对图像特征的多尺度捕捉。具体来说,一个典型的Inception模块包含以下几种类型的层:
-
1x1卷积层:用作降维操作,减少后续层的计算负担。这一步骤在执行更大尺寸卷积之前进行,可以显著降低计算复杂度而不损失太多信息。
-
3x3和5x5卷积层:用于捕捉局部特征,其中3x3卷积核适合捕捉中等尺度的特征,而5x5卷积核适合捕捉更大范围的特征。这些卷积层在应用前通常也会经过1x1卷积降维。
-
最大池化层:通常使用3x3的最大池化操作,进一步增加网络对不同尺度特征的鲁棒性,并提供一定程度的平移不变性。
所有这些层的输出会在深度维度上被拼接(concatenated)起来,形成一个非常“宽”的特征图。这样的设计允许网络在不显著增加计算成本的情况下,探索多种不同的特征组合,从而提高模型的表达能力。
降维策略
特别值得注意的是,Inception模块中的1x1卷积核除了用于降维外,还能够实现通道间的交叉信息处理,有助于模型学习更复杂的特征关系。通过这种机制,Inception模块能够在增加网络宽度(即增加每层的特征图数量)的同时,保持或减少模型的总体参数量和计算量。
版本演进
从最初的Inception v1开始,Google团队继续优化这一模块,推出了Inception v2至v4等多个版本,每个新版本都在原有基础上进行了改进,比如引入Batch Normalization、优化卷积结构以减少计算成本等,使模型更加高效和强大。
总之,Inception模块通过并行使用多种尺寸的卷积和池化操作,实现了对图像特征的全面而高效的提取,是深度学习领域中一项重要的技术创新,对后续的网络设计有着深远的影响。
注意下图有一些不严谨,下图的四个结果厚度可以不一样,但是长宽是一样的。

下图左为原始版本,这种操作容易越摞越厚导致计算量的爆炸。为了避免这个问题就产生了下图右侧的版本:在进行3x3,5x5卷积之前进行1x1卷积进行降维,对于3x3最大池化的结果也用1x1卷积进行降维,把四路变薄的作业本摞在一起,就可以减少参数量和运算量。

9个inception模块堆在一起:



优化的Inception模块变体


1.3 1x1卷积
1x1卷积在深度学习尤其是卷积神经网络(CNN)中扮演着多种关键角色,以下是其主要作用:
-
降维(Dimensionality Reduction):1x1卷积可以显著减少网络中的参数量和计算负担。通过应用具有较少输出通道的1x1卷积,可以在不影响输入特征图的空间维度(高度和宽度)的情况下,减少特征图的深度(通道数)。这有助于降低模型的复杂性,减少过拟合的风险,并加速训练过程。
-
升维(Dimensionality Increase):与降维相反,1x1卷积也可以用来增加特征图的深度,即增加输出通道的数量。这对于扩展模型的表达能力,捕获更多样化的特征是有益的。
-
特征重校准(Feature Re-calibration):1x1卷积能够对输入特征图的每个通道进行线性变换,实现通道间的信息重组。这相当于在每个空间位置上对输入特征的各个通道进行加权求和,有助于强调或抑制某些特征,实现特征选择和优化。
-
跨通道信息整合(Cross-channel Information Integration):由于1x1卷积在每个输入通道上独立操作并聚合结果,它能够促进不同特征通道之间的相互作用,实现跨通道的特征融合,增强网络对复杂模式的学习能力。
-
计算代价低的深度操作:相比于较大的卷积核,1x1卷积的计算成本低,但在保持空间维度不变的同时,提供了对特征图深度的有效操作,因此常用于构建高效的网络结构,如Inception模块中。
-
替代全连接层(Fully Connected Layer Replacement):在全卷积网络(FCN)中,1x1卷积可以替代传统的全连接层,使得网络能够处理任意尺寸的输入图像,提高模型的灵活性和适应性,提高表示能力。


1.4 GAP(global average pooling)全局平均池化
全局平均池化(Global Average Pooling,简称GAP)是一种在深度学习,尤其是卷积神经网络(CNN)中的池化技术,它在模型的最后阶段被应用,发挥着重要作用。
-
减少参数数量:GAP通过替代全连接层(Fully Connected Layers, FC),显著减少了模型中的参数数量。在传统CNN结构中,全连接层往往包含大量的权重参数,容易导致过拟合并增加计算复杂度。GAP直接将每个特征图的所有元素平均,生成一个标量值,因此即使在多通道特征图的情况下,输出也是一个与通道数相等的向量,极大降低了模型复杂性。
-
正则化和防止过拟合:通过减少模型参数,GAP自然地起到了正则化的效果,有助于模型更好地泛化到未见数据,降低过拟合风险。GAP实际上对整个网络结构施加了一种形式的正则化,提高了模型的稳健性。
-
特征图到类别得分的直接映射:GAP使得每个特征图的平均值可以被视为该特征图代表类别得分的总体表示,从而赋予了特征图以类别层面的解释性。每个通道的平均值可以理解为对应类别的一个置信度值。
-
增强对空间变换的鲁棒性:GAP通过对特征图进行整体平均,降低了对特定空间位置信息的依赖,使得模型对输入图像的空间变换更加鲁棒。这有助于模型关注于全局特征而非局部细节,从而在一定程度上增强了对图像旋转、缩放等变换的不变性。
-
提高训练速度:由于参数量的减少,模型训练所需的计算资源和时间也随之减少,从而加快了训练速度。
-
挑战与改进:尽管GAP有效,但其简单平均的特性可能导致一些局部重要特征的丢失。为解决这个问题,研究人员引入了多种改进策略,比如结合全局最大池化(Global Max Pooling, GMP)和注意力机制(Attention Mechanism),以更细致地加权和保留特征图中的关键信息。
-
便于迁移学习和fine tunning。
GAP作为一种有效的池化策略,通过简化模型结构、减少过拟合风险以及提高训练效率,对深度学习模型尤其是图像识别和分类任务的性能产生了积极影响。
GAP能将多通道的特征图变成一个一维向量,这样可以直接softmax或者构建全连接网络进行分类,大大减少参数量。如果不采用GAP而按照传统的CNN,我们需要把每一个channel的每一个元素用flatten进行展平,这样会导致全连接层都需要跟这个长向量都有权重,因此会带来参数量和计算量的爆炸。

下图,GAP保留了原来channel的信息,因此这个权重就能够反映这一个类别对每一个channel的关注程度,而下图是FCN(全卷积网络),空间信息没有丢失,channel又保留了原图上的空间信息,所以用这个图像分类的模型,我们就可以进行定位甚至是语义分割。

1.5 CS231N公开课的一些讲解


辅助分类器
GoogLeNet(特别是其Inception V1版本)中引入辅助分类器的设计,是为了克服深层网络训练中的一些挑战,特别是梯度消失问题,以及提高网络的训练效率。下面详细介绍辅助分类器的原理和细节:
原理
-
梯度消失问题的缓解:随着网络深度的增加,梯度在反向传播过程中可能会变得非常小,导致网络前面层的权重更新缓慢甚至停滞。辅助分类器位于主网络的中间层,它们的输出也参与到最终的损失计算中,这样可以为网络的早期层提供更多直接的梯度信号,帮助梯度更有效地反向传播,从而缓解梯度消失问题。
-
训练加速:辅助分类器提供了一个额外的监督信号,使得网络在训练初期就能得到关于中间层特征质量的反馈,有助于网络更快地学习到有意义的特征,加速训练过程。
细节
-
位置与结构:在Inception V1中,辅助分类器通常放置在网络较深的位置,例如在Inception(4a)模块之后。这些辅助分类器通常包括全局平均池化(Global Average Pooling, GAP)层,用于将特征图转换成固定长度的向量,随后是若干全连接层(也称为密集连接层),最终通过一个Softmax层输出分类概率。
-
权重分配:辅助分类器的输出通常会以一个小的权重(例如0.3)加入到最终的损失函数中。这样做是为了确保主分类器仍然是训练的主要目标,而辅助分类器则作为一个辅助性的指导,避免它们过度主导训练过程。
-
功能与输出:辅助分类器不仅有助于梯度流,还能评估网络中间层的特征表示能力。它们的输出虽然也是对图像类别的预测,但精度通常低于最终的分类器,因为它们基于相对较低级别的特征。
-
训练与测试阶段:在训练阶段,辅助分类器积极参与模型的训练过程;而在实际部署或测试阶段,为了减少推理时间,通常会移除这些辅助分类器,仅使用主分类器进行预测。
-
优化与调整:辅助分类器的设计(如位置、结构、权重分配等)可以根据具体任务和网络架构进行调整。后续的Inception版本(如Inception V3)虽然也可能包含辅助分类器,但设计细节可能有所不同,比如可能减少辅助分类器的数量或调整其结构以进一步优化性能。
总之,辅助分类器是GoogLeNet设计中的一项创新,它通过在深度网络中引入中间监督,提高了训练的效率和稳定性,同时也为深层网络的训练提供了一种实用的解决方案。
下图蓝框中的是一个辅助分类器,目的是为了进行梯度注入防止梯度消失。

2. pytorch模型复现
待更新











![【Java]认识泛型](https://i-blog.csdnimg.cn/direct/180d6e14c46247c9a56611f612d81282.png)