在当今,网络数据采集作为获取行业信息的重要手段,尤其在竞争激烈的商业环境中,Python作为一种强大的编程语言,广泛应用于开发各种数据爬虫来自动化地抓取网络信息。然而,网站普遍采用防护措施,即使我们合规访问,但高频访问也有可能被误判为:非典型的或潜在的自动化访问,导致无法继续采集网页公开信息,此时可采代理IP用提升爬虫真实性与高效性。
代理IP不仅可以帮助爬虫保护个人真实身份,还能通过轮换不同的代理IP来把握请求的频次和真实性,提高数据采集的成功率。
目录
代理IP的重要性
保护隐私
全球公开访问
提高稳定性
代理IP的类型与选择
公共代理与私有代理
HTTP与HTTPS代理
SOCKS代理
选择代理的考虑因素
配置代理IP的技术实现
获取代理IP
使用Python的requests库配置代理
集成代理到Scrapy框架
管理代理池
实现高级代理管理
动态代理选择
验证代理有效性
处理代理失败
实战应用:控制请求频率,智取数据
设置合理的请求头
使用随机的用户代理和间隔
动态IP轮换和错误处理
案例分析:爬取大型电商网站的产品数据
总结
代理IP的重要性
代理IP在Python爬虫中的应用非常广泛,主要体现在以下几个方面
-
保护隐私
使用代理IP的主要好处之一是可以保护爬虫采集活动的隐私性。当爬虫通过代理IP发送请求时,目标网站看到的只是代理的IP地址,而不是爬虫服务器的实际IP地址。这样不仅可以减少直接对爬虫服务器的攻击风险,还可以避免因频繁请求同一网站而被误判。
-
全球公开访问
很多网站仅对部分地区的用户开放,比如某些视频内容只允许某些国家的IP地址访问。为了合法有效地获取公开数据信息,可使用目标国家的代理IP进行访问,从全球范围抓取所需数据。这对于进行国际市场分析或全球数据采集的项目尤其重要。
-
提高稳定性
在爬虫运行过程中,可能会遇到某些代理IP突然失效的情况,这会影响数据抓取的连续性和完整性。构建一个动态代理IP池,实现在代理失效时自动轮换到另一个代理,可以显著提高爬虫的稳定性和抓取效率。
代理IP的类型与选择
在实际部署Python爬虫时,选择合适的代理IP类型是非常重要的。了解不同类型的代理及其特点可以帮助你更有效地规划和实现爬虫项目。代理主要分为以下几类:
公共代理与私有代理
- 公共代理(Public Proxies):这些代理通常是免费提供的,用户可以在多个网站上找到这类代理的列表。虽然它们的使用成本低,但通常存在稳定性差和安全性低的问题。公共代理由于被大量用户共享,无法保证IP的纯净度和成功率。
- 私有代理(Private Proxies):私有代理是付费服务,提供专属的IP地址供个人或团队使用。相比公共代理,私有代理的速度更快,稳定性和安全性也更高。它们适合用于需要长期、大量访问公开数据的爬虫项目。
HTTP与HTTPS代理
- HTTP代理:这种类型的代理只能用于HTTP连接,是最基本的代理类型,适用于普通的网页数据抓取。
- HTTPS代理:与HTTP代理类似,但它支持HTTPS协议,可以为加密的HTTPS连接提供中介服务。使用HTTPS代理更安全,因为它保障了数据传输过程的加密,防止中间人攻击。
SOCKS代理
- SOCKS代理:这种代理提供了比HTTP代理更为广泛的应用可能,不仅支持HTTP和HTTPS,还支持FTP等协议。SOCKS代理因其灵活性和较强的匿名性,特别适合于需要处理复杂网络请求的爬虫。
选择代理的考虑因素
- 可靠性:选择用户使用数多、评价良好、代理IP稳定的平台。
- 速度:代理的响应速度直接影响爬虫的效率,特别是在处理大量数据时。
- 地理位置:根据爬取数据需求选择相应的代理位置,选择覆盖更多国家的平台。
- 成本:根据项目预算选择适合的代理类型,权衡成本和效益。
配置代理IP的技术实现
在Python中配置和使用代理IP是提高爬虫匿名性的关键步骤。本部分将详细讨论如何通过编程手段在Python爬虫中设置代理IP,以及如何管理代理池以提高爬虫的效率和可靠性。
获取代理IP
正常三大运营商的代理IP很多都已经进到了黑名单,什么意思呢,当一个代理IP被多人频繁使用时,特别是当这些用户用它进行大量的请求、或者进行不当行为时,目标服务器可能会注意到这个IP的异常活动,并将其列入黑名单。当你再使用这个被多人使用过并且被污染的代理IP时,目标服务器会拒绝你的访问请求。这种情况特别常见于公共代理服务器和共享代理服务,因为它们的IP地址经常被大量用户重复使用。
所以今天使用一家海外代理IP平台IPIDEA ,亲测他们的IP可用性高、速度快,完全可满足我们对可靠性、和地理位置等要求,现在新人注册送试用流量,需要的朋友点击这里领取,正常爬虫测试个几万条数据够够的,需要注意因为使用的是海外IP,所以需要我们有海外网络环境,切记!
点击【API获取】 -> 选择【代理类型】 -> 设置【提取参数】 -> 点击【生成链接】并复制接
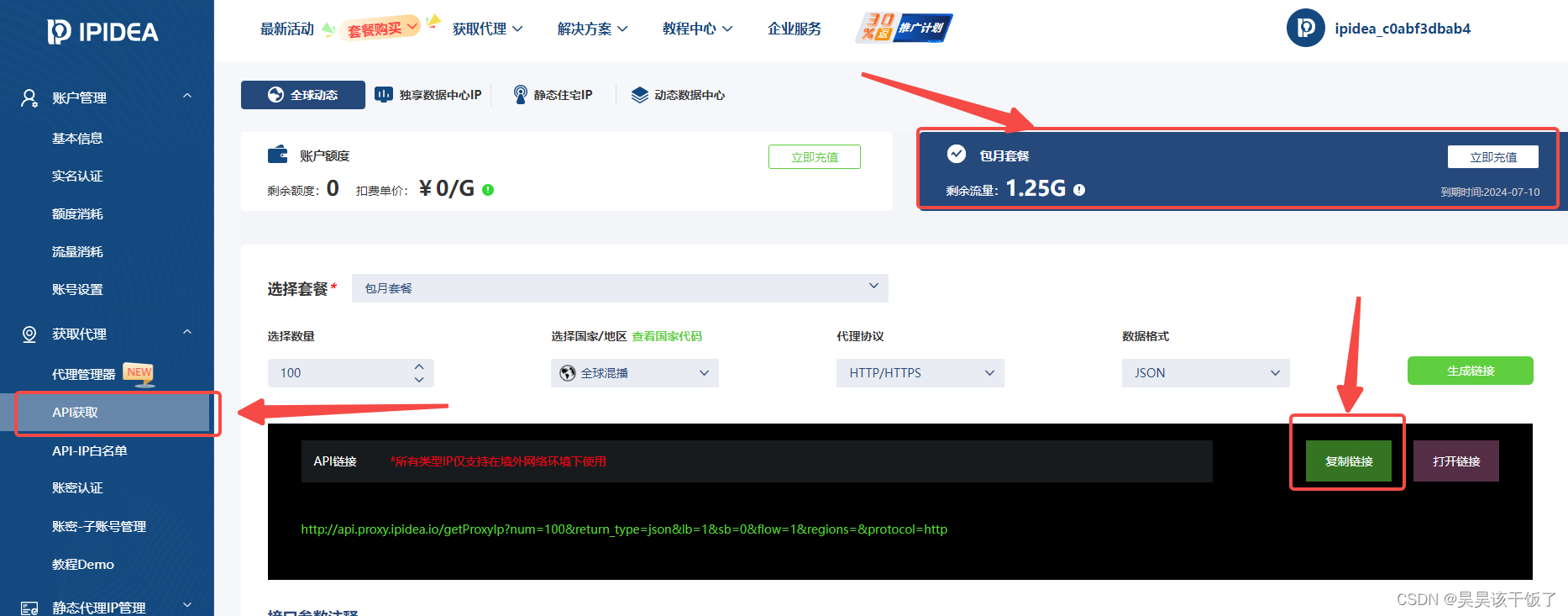
我们打开一个连接看一下,会返回很多ip,我们按之后的配置使用即可:

使用Python的requests库配置代理
requests是Python中最常用的HTTP客户端库之一,支持从简单的GET和POST请求到更复杂的HTTP协议操作。要在requests中配置代理,可以简单地传递一个代理字典到请求函数中。下面是一个基本示例:
import requests
# 把获取的代理ip和端口放过来
proxies = {
'http': 'http://43.159.53.192:19394',
'https': 'https://43.159.53.192:19394',
}
url = 'http://example.com'
response = requests.get(url, proxies=proxies)
print(response.text)
集成代理到Scrapy框架
对于更复杂或大规模的爬虫项目,使用Scrapy框架可能是更好的选择。Scrapy是一个强大的爬虫框架,支持异步处理和中间件管理,非常适合构建复杂的爬取任务。在Scrapy中配置代理主要通过中间件来实现,以下是一个配置代理的中间件示例:
from scrapy import signals
import scrapy
class ProxyMiddleware(object):
def process_request(self, request, spider):
request.meta['proxy'] = "http://43.159.53.192:19394"
return None
管理代理池
在大规模爬虫应用中,单一代理可能因为请求频率过高而被封禁,或因为代理服务器的不稳定而失效。为了解决这一问题,可以创建一个代理池,动态地管理多个代理,从而提高爬虫的健壮性和数据抓取的连续性。以下是一个简单的代理池管理示例:
import random
import requests
proxy_list = [
'http://43.159.53.192:19394',
'http://129.226.148.192:19394',
'http://43.159.53.192:19657',
]
def get_proxy():
return random.choice(proxy_list)
url = 'http://example.com'
proxies = {'http': get_proxy()}
response = requests.get(url, proxies=proxies)
print(response.text)
实现高级代理管理
在大规模和高频率的爬虫操作中,简单的代理设置可能不足以满足需求。高级代理管理涉及动态选择代理、处理代理失败、验证代理有效性等功能。本部分将详细介绍如何在Python中实现这些高级功能。
动态代理选择
动态选择代理需要一个能够根据代理的健康状况和历史表现动态更新的代理池。
import random
import requests
class ProxyPool:
def __init__(self):
self.proxies = [
'http://43.159.53.192:19394',
'http://129.226.148.192:19394',
'http://43.159.53.192:19657',
]
self.blacklist = []
def get_proxy(self):
if not self.proxies:
raise RuntimeError("All proxies are blacklisted!")
return random.choice(self.proxies)
def report_failed_proxy(self, proxy):
self.blacklist.append(proxy)
self.proxies.remove(proxy)
print(f"Proxy {proxy} blacklisted.")
proxy_pool = ProxyPool()
def fetch(url):
while True:
proxy = proxy_pool.get_proxy()
try:
response = requests.get(url, proxies={"http": proxy})
response.raise_for_status() # will raise an exception for 4XX/5XX errors
return response.text
except requests.RequestException as e:
print(f"Request failed with {proxy}: {e}")
proxy_pool.report_failed_proxy(proxy)
验证代理有效性
在使用代理之前验证其有效性是一个好习惯。这可以通过发送简单的HTTP请求到一个可靠的目标(如 httpbin.org)来实现:
def validate_proxy(proxy):
try:
response = requests.get("http://httpbin.org/ip", proxies={"http": proxy}, timeout=5)
response.raise_for_status() # 校验HTTP响应状态码
return True
except requests.RequestException:
return False
def refresh_proxies():
valid_proxies = []
for proxy in proxy_pool.proxies:
if validate_proxy(proxy):
valid_proxies.append(proxy)
proxy_pool.proxies = valid_proxies
refresh_proxies()
看这个网站返回的ip是否已经不再是我们本机ip

处理代理失败
在实际爬虫应用中,代理可能会在任何时刻失效。因此,合理处理这种情况是必要的。在上面的fetch函数中,我们已经展示了当请求失败时如何处理。但更细致的错误处理,如区分不同类型的HTTP错误(如403禁止访问、404找不到页面等),也是很有必要的。
实战应用:控制请求频率,智取数据
在部署实际的爬虫项目时,仅仅拥有代理管理技能还不够。面对越来越复杂的网站验证技术,需要综合运用各种策略来有效地控制请求频率,保证数据抓取的连续性和准确性。以下是一些常用的实战策略:
设置合理的请求头
网站服务器通常会检查来访请求的请求头(Headers),其中包括用户代理(User-Agent)、引用页(Referer)等信息,以判断请求是否来自真实用户的浏览器。为了模仿真实用户,爬虫应该设置逼真的请求头:
import requests
def get_headers():
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/602.4.8 (KHTML, like Gecko) Version/10.0.3 Safari/602.4.8",
# 更多用户代理字符串...
]
headers = {
'User-Agent': random.choice(user_agents),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Referer': 'https://www.google.com/'
}
return headers
response = requests.get('http://example.com', headers=get_headers(), proxies={"http": proxy_pool.get_proxy()})
使用随机的用户代理和间隔
除了设置请求头,还应定期更换用户代理(User-Agent)并设置随机的访问间隔,以降低被网站识别为机器人的风险。以下是一个示例:
import time
def fetch_with_random_timing(url):
time.sleep(random.uniform(1, 10)) # 随机等待1到10秒
response = requests.get(url, headers=get_headers(), proxies={"http": proxy_pool.get_proxy()})
return response.text
动态IP轮换和错误处理
在面对高度防护的网站时,IP可能会被快速识别并失效。因此,使用动态IP轮换策略,并在遇到如403错误时立即轮换IP,是提高爬取效率的有效手段:
def robust_fetch(url):
try:
response = requests.get(url, headers=get_headers(), proxies={"http": proxy_pool.get_proxy()})
response.raise_for_status()
except requests.exceptions.HTTPError as e:
if e.response.status_code == 403:
print("We've been detected! Changing IP...")
proxy_pool.report_failed_proxy(proxy)
return robust_fetch(url) # 递归重试
except requests.exceptions.RequestException as e:
print(f"Network error: {e}")
return response.text
案例分析:爬取大型电商网站的产品数据
在本案例中,我们将展示如何使用先前讨论的技术和策略来爬取一个大型电商网站的产品数据。我们将通过动态更换请求头、用户代理,以及使用代理池和随机请求间隔来实现此目标。以下是一个简化的Python脚本,展示了整个过程:
import requests
import random
import time
class ProxyPool:
def __init__(self):
self.proxies = [
'http://10.10.1.10:3128',
'http://10.10.2.10:3128',
'http://10.10.3.10:3128',
]
self.blacklist = []
def get_proxy(self):
if not self.proxies:
raise RuntimeError("All proxies are blacklisted!")
return random.choice(self.proxies)
def report_failed_proxy(self, proxy):
self.blacklist.append(proxy)
self.proxies.remove(proxy)
print(f"Proxy {proxy} blacklisted.")
def get_headers():
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/602.4.8 (KHTML, like Gecko) Version/10.0.3 Safari/602.4.8",
]
headers = {
'User-Agent': random.choice(user_agents),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Referer': 'https://www.google.com/'
}
return headers
def fetch_product_data(url, proxy_pool):
while True:
try:
proxy = proxy_pool.get_proxy()
headers = get_headers()
print(f"Using proxy: {proxy} with headers: {headers['User-Agent']}")
response = requests.get(url, headers=headers, proxies={'http': proxy})
response.raise_for_status()
return response.text
except requests.exceptions.HTTPError as e:
if e.response.status_code == 403:
print("Access denied, switching proxy...")
proxy_pool.report_failed_proxy(proxy)
else:
raise
except requests.exceptions.RequestException as e:
print(f"Network error: {e}")
# Setup
proxy_pool = ProxyPool()
product_url = "https://www.example-ecommerce.com/product/12345"
# Fetching data
product_data = fetch_product_data(product_url, proxy_pool)
print(product_data)
- 代理池管理:
ProxyPool类用于管理代理IP,包括获取、报告失败并自动从池中移除失效的代理。 - 动态请求头:
get_headers函数生成随机的用户代理和其他HTTP头部信息,模拟不同的浏览器行为。 - 数据抓取:
fetch_product_data函数负责发起HTTP请求。这个函数处理代理更换、访问拒绝(403错误)和网络错误,确保在遇到问题时能够自动切换代理。 - 循环尝试:在访问被拒绝或发生网络错误时,会更换代理并重试,直到成功抓取数据。
总结
通过本文的详细介绍,相信大家对代理IP的重要性、类型选择、配置实现以及在实际爬虫应用中的技巧有了全面的了解。我们详细讨论了如何通过代理IP保护隐私、提高稳定性和实现全球公开访问,同时也介绍了如何在Python和Scrapy中配置和使用代理。在实际操作过程中,通过IPIDEA提供的稳定、高速的代理IP,为我们的爬虫项目带来了显著的提升,能够有效提高爬取效率,并应对复杂的验证机制,其简单易用的管理平台也大大简化了代理池管理和动态代理选择的流程,提升了整体工作效率。
总体而言,通过合理选择和配置代理IP,结合有效的爬虫策略,可以显著提高爬虫任务的成功率和数据抓取效率。



![【Java]认识泛型](https://i-blog.csdnimg.cn/direct/180d6e14c46247c9a56611f612d81282.png)










![[ICS] Modbus未授权攻击S7协议漏洞利用](https://img-blog.csdnimg.cn/img_convert/b56c60c312288a5c430d374d2db43b99.jpeg)