文末有福利!
引言
今天给大家分享的这篇文章是关于LoRA微调大模型实操技巧,讨论了从实验中得出的主要经验和教训;此外,本文将解答一些与LoRA技术相关的常见问题。如果你对于微调定制化的大语言模型感兴趣,希望这些见解能够帮助你快速起步。
LoRA背景
增加数据量和模型的参数量是公认的提升神经网络性能最直接的方法。目前主流的大模型的参数量已扩展至千亿级别,「大模型」越来越大的趋势还将愈演愈烈。
这种趋势带来了多方面的算力挑战。想要微调参数量达千亿级别的大语言模型,不仅训练时间长,还需占用大量高性能的内存资源。
为了让大模型微调的成本「打下来」,微软的研究人员开发了低秩自适应(LoRA)技术。LoRA 的精妙之处在于,它相当于在原有大模型的基础上增加了一个可拆卸的插件,模型主体保持不变。LoRA 随插随用,轻巧方便。
对于高效微调出一个定制版的大语言模型来说,LoRA 是最为广泛运用的方法之一,同时也是最有效的方法之一。如果你对开源 LLM 感兴趣,LoRA 是值得学习的基本技术,不容错过。
LoRA简介
由于GPU内存的限制,在训练过程中更新整个模型权重成本很高。例如,假设有一个7B参数的语言模型,用一个权重矩阵W表示。在反向传播期间,模型需要学习一个ΔW矩阵,旨在更新原始权重,让损失函数值最小。权重更新如下:
Wupdated=W+ΔW
如果权重矩阵包含7B个参数,则权重更新矩阵也包含7B个参数,计算矩阵非常耗费计算和内存。
由Edward Hu等人提出的LoRA将权重变化的部分分解为低秩表示。确切地说,它不需要显示计算。相反,LoRA在训练期间学习的分解表示,如下图所示,这就是LoRA节省计算资源的奥秘。
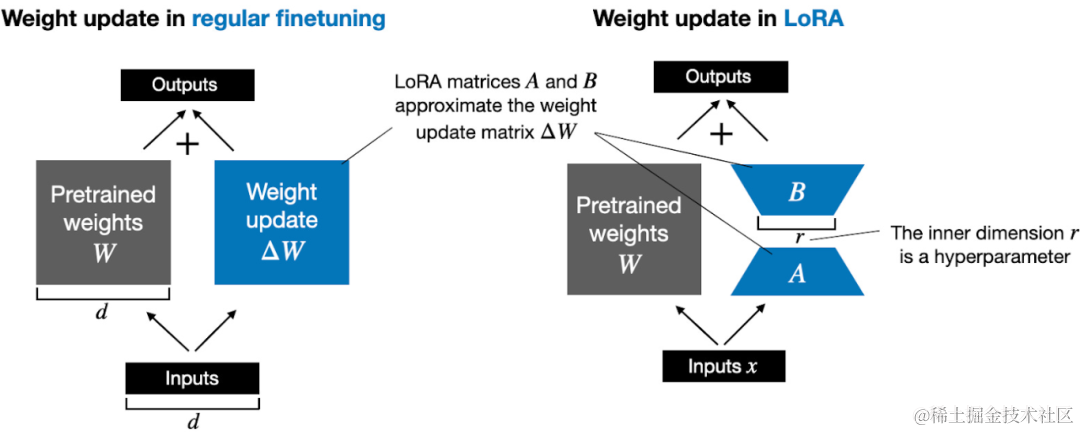
如上所示,的分解意味着我们需要用两个较小的LoRA矩阵A和B来表示较大的矩阵。如果A的行数与相同,B的列数与相同,可以将以上的分解记为。(AB是矩阵A和B之间的矩阵乘法结果。)
这种方法节省了多少内存呢?还需要取决于秩r,秩r是一个超参数。例如,如果有10000行20000列,则需存储200000000个参数。如果我们选择的A和B,则A有10000行和8列,B有8行和20000列,即 个参数,比200000000个参数少约830 倍。
当然,A和B无法捕捉到涵盖的所有信息,但这是LoRA的设计所决定的。在使用LoRA时,我们假设模型是一个具有全秩的大矩阵,以收集预训练数据集中的所有知识。当我们微调LLM 时,不需要更新所有权重,只需要更新比更少的权重来捕捉核心信息,低秩更新就是这么通过矩阵实现的。

LoRA一致性
虽然LLM在GPU上训练的随机性不可避免,但是采用LoRA进行多次实验,LLM最终的基准结果在不同测试集中都表现出了惊人的一致性。对于进行其他比较研究,这是一个很好的基础。
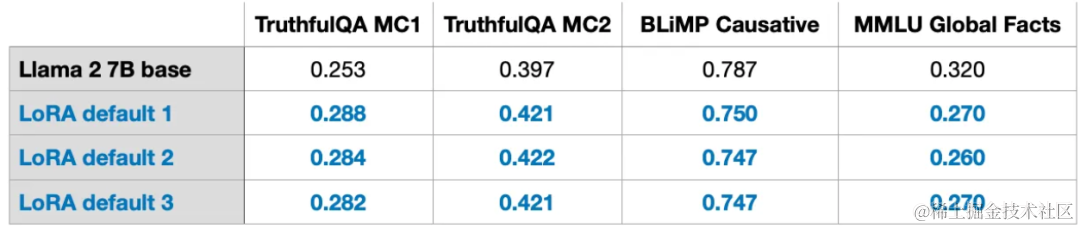
注,以上这些结果是在默认设置下,使用较小的值获得的。实验详情可见论文:https://lightning.ai/pages/community/lora-insights/
QLoRA计算
QLoRA 是由 Tim Dettmers 等人提出的量化 LoRA 的缩写。QLoRA 是一种在微调过程中进一步减少内存占用的技术。在反向传播过程中,QLoRA 将预训练的权重量化为 4-bit,并使用分页优化器来处理内存峰值。
使用LoRA时可以节省33%的GPU内存。然而,由于QLoRA中预训练模型权重的额外量化和去量化,训练时间增加了39%。
默认LoRA具有16bit浮点精度:
- 训练时长:1.85 小时
- 内存占用:21.33GB
具有4位正常浮点数的 QLoRA
- 训练时长为:2.79h
- 内存占用为:14.18GB

此外,可以发现模型的性能几乎不受影响,如下图所示。这说明QLoRA可以作为 LoRA 训练的替代方案,更进一步解决常见GPU内存瓶颈问题。
学习率调度器
学习率调度器会在整个训练过程中降低学习率,从而优化模型的收敛程度,避免loss值过大。
余弦退火(Cosine annealing)是一种遵循余弦曲线调整学习率的调度器。它以较高的学习率作为起点,然后平滑下降,以类似余弦的模式逐渐接近0。一种常见的余弦退火变体是半周期变体,在训练过程中只完成半个余弦周期,如下图所示。

实验中,在LoRA微调脚本中添加了一个余弦退火调度器,它显著地提高了SGD的性能。但是它对Adam和AdamW优化器的增益较小,添加之后几乎没有什么变化。接下来,将讨论 SGD 相对于 Adam 的潜在优势。

SGD VS Adam
Adam 和 AdamW 优化器在深度学习中很受欢迎。尽管在处理大型模型时它们非常占用内存,原因是Adam优化器为每个模型参数维护两个移动平均值:梯度的一阶矩(均值)和梯度的二阶矩(非中心方差)。换句话说,Adam优化器在内存中为每个模型参数存储两个附加值,即如果我们正在训练一个7B参数的模型,那使用Adam就能够在训练的过程中跟踪额外的14B参数,相当于在其他条件不变的情况下,模型的参数量翻了一番。
SGD 优化器在训练期间不需要存储任何额外参数,所以在训练LLM时,相比于Adam,SGD在峰值内存方面有什么优势呢?
在实验中,使用AdamW和LoRA(默认设置 r=8)训练一个7B参数的Llama2模型需要14.18GB的GPU内存。用SGD训练同一模型需要14.15GB 的GPU内存。相比于AdamW,SGD只节省了0.03GB的内存,作用微乎其微。
为什么只节省了这么一点内存呢?这是因为使用LoRA时,LoRA已经大大降低了模型的参数量。例如,如果r=8,在7B的Llama2模型的所有 6738415616个参数,只有4194304个可训练的LoRA参数。
只看数字,4194304 个参数可能还是很多,但是其实这么多参数仅占用 4194304×2×16bit=134.22mbit = 16.78mbyte。(观察到存在0.03 Gb = 30 Mb 的差异,这是由于在存储和复制优化器状态时,存在额外的开销。)其中:2代表Adam存储的额外参数的数量,而16位指的是模型权重的默认精度。

如果把LoRA矩阵的r从8拓展到256,那么SGD相比AdamW的优势就会显现:
- 使用 AdamW 将占用内存 17.86 GB
- 使用 SGD 将占用 14.46 GB
因此,当矩阵规模扩大时,SGD 节省出的内存将发挥重要作用。由于SGD不需要存储额外的优化器参数,因此在处理大模型时,SGD相比Adam等其他优化器可以节省更多的内存。这对于内存有限的训练任务来说是非常重要的优势。
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~ , 【保证100%免费】

篇幅有限,部分资料如下:
👉LLM大模型学习指南+路线汇总👈
💥大模型入门要点,扫盲必看!

💥既然要系统的学习大模型,那么学习路线是必不可少的,这份路线能帮助你快速梳理知识,形成自己的体系。

👉大模型入门实战训练👈
💥光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉国内企业大模型落地应用案例👈
💥《中国大模型落地应用案例集》 收录了52个优秀的大模型落地应用案例,这些案例覆盖了金融、医疗、教育、交通、制造等众多领域,无论是对于大模型技术的研究者,还是对于希望了解大模型技术在实际业务中如何应用的业内人士,都具有很高的参考价值。 (文末领取)

💥《2024大模型行业应用十大典范案例集》 汇集了文化、医药、IT、钢铁、航空、企业服务等行业在大模型应用领域的典范案例。

👉LLM大模型学习视频👈
💥观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。 (文末领取)

👉640份大模型行业报告👈
💥包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

👉获取方式:
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓