任务描述
知识点:安装配置Spark
重 点: 安装配置Spark
难 点:无
内 容:
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
本任务主要内容是安装配置Spark,并搭建Spark HA高可用架构。
任务指导
安装Spark集群主要包括以下步骤:
1、下载Spark安装包,在各节点中安装部署spark集群
2、配置整合
3、启动并测试
注:Spark的运行方式分为三种,这里使用在工作中最常用的方式 Spark on YARN,将Spark托管到YARN上运行
任务实现
1. 下载Spark
可以从官方网站下载合适的版本。当前环境已经提供了安装包,存放在 /opt/software目录下。
2. 在node1节点上安装Spark
- 解压安装Spark
[root@node1 ~]# cd /opt/software/
[root@node1 software]# tar -xzf spark.tar.gz -C /opt/module/- 配置Spark环境变量,修改系统配置文件/etc/profile。
输入【# vim /etc/profile】命令,编辑/etc/profile文件,增加如下内容:
export SPARK_HOME=/opt/module/spark/
export PATH=$PATH:$SPARK_HOME/bin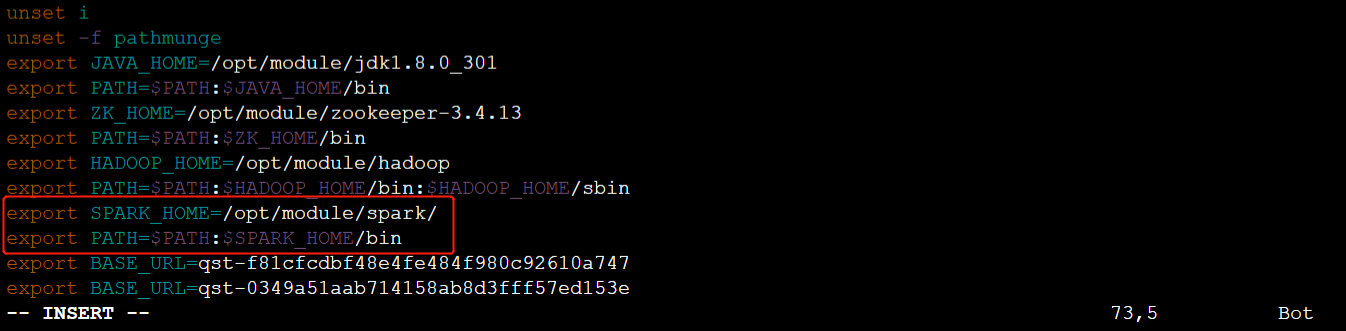
- 使用【source /etc/profile】命令使配置文件生效
[root@node1 software]# source /etc/profile- 进入/opt/module/spark/conf 配置文件夹
[root@node1 software]# cd $SPARK_HOME/conf- 配置spark-env.sh文件,配置过程如下:
使用【cp】命令,从spark-env.sh.template模板文件复制并创建spark-env.sh文件
[root@node1 conf]# cp spark-env.sh.template spark-env.sh然后使用【 vim spark-env.sh】命令编辑该文件
[root@node1 conf]# vim spark-env.sh添加如下内容:
export JAVA_HOME=/opt/module/jdk1.8.0_301
export HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop
3. 将node1节点上的Spark分别都拷贝到node2、node3节点上
- 将配置好的Spark复制到其他节点对应位置上,通过scp命令发送。
[root@node1 conf]# scp -rq /opt/module/spark node2:/opt/module/
[root@node1 conf]# scp -rq /opt/module/spark node3:/opt/module/- 将配置好的环境变量/etc/profile复制到其他节点对应位置上,通过scp命令发送。
[root@node1 conf]# scp -rq /etc/profile node2:/etc/
[root@node1 conf]# scp -rq /etc/profile node3:/etc/4. Spark配置的常见问题
- Spark相关命令比较灵活,这里使用【 spark-shell --master yarn】进行测试,代码指定将Spark托管到YARN上
- 由于YARN调度机制的问题,Spark的资源无法被正确申请,所以需要修改Hadoop中的yarn-site.xml
- 进入node1的Hadoop配置目录
[root@node1 ~]# cd $HADOOP_HOME/etc/hadoop- 使用【vim】命令修改yarn-site.xml文件
[root@node1 hadoop]# vim yarn-site.xml - 在yarn-site.xml文件的<configuration>标签内,添加如下配置
<property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>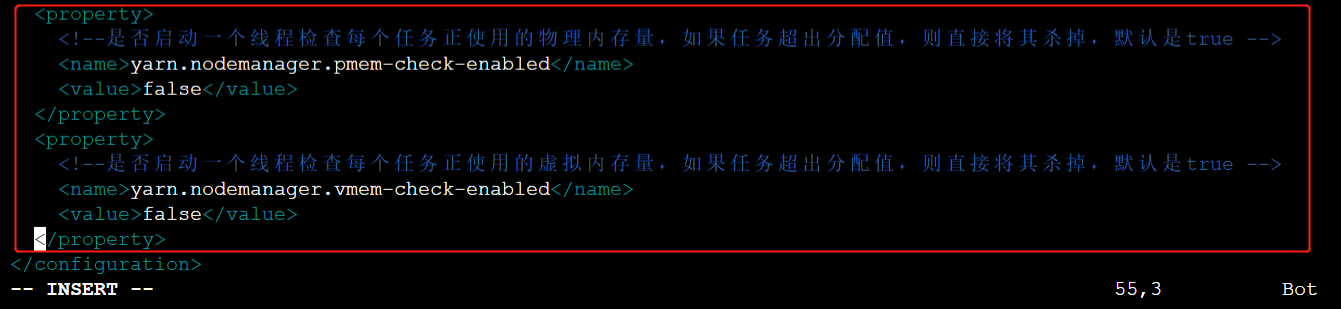
- 修改完成后将更新的yarn-site.xml文件分发至node2、node3的Hadoop配置文件目录中
[root@node1 hadoop]# scp yarn-site.xml node2:/opt/module/hadoop/etc/hadoop/
[root@node1 hadoop]# scp yarn-site.xml node3:/opt/module/hadoop/etc/hadoop/
- 在node1节点上,重启YARN集群
[root@node1 hadoop]# stop-yarn.sh
[root@node1 hadoop]# start-yarn.sh5. 测试Spark
- 在node1节点上,首先上传一个文件至HDFS目录
[root@node1 ~]# cd $HADOOP_HOME/
[root@node1 hadoop]# hdfs dfs -put README.txt /- 进入Spark Shell
[root@node1 hadoop]# spark-shell --master yarn
- 在Spark客户端执行如下代码,实现对HDFS上的 README.txt 文件的内容进行词频统计(即,统计每个单词在文档中出现的总次数),并将统计的结果保存到HDFS上的 /result目录下。
scala> sc.textFile("hdfs://node1:9000/README.txt").flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey((a,b) => a+b).saveAsTextFile("hdfs://node1:9000/result")- 输入【:quit】退出 Spark Shell
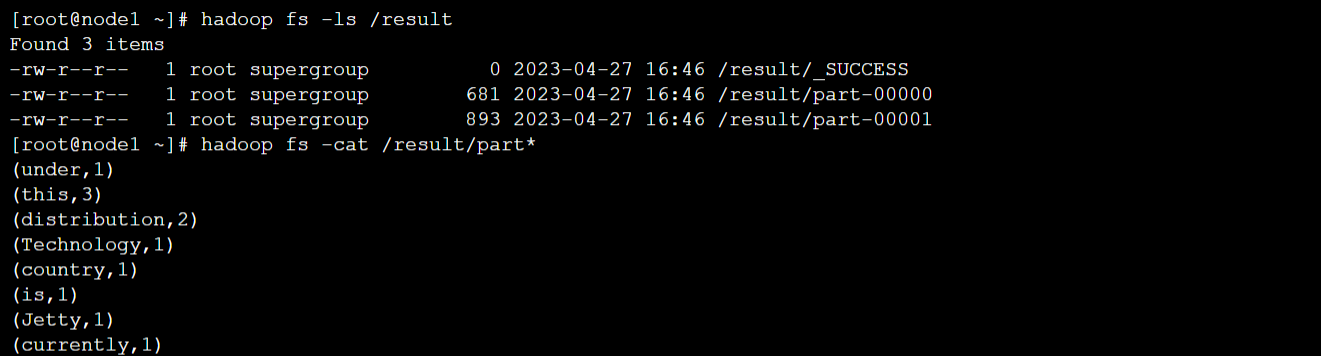
scala> :quit- 观察HDFS的/result目录中的数据,如果可以查看到词频统计的结果,则说明集群运行正常
[root@node1 hadoop]# hadoop fs -ls /result
[root@node1 hadoop]# hadoop fs -cat /result/part*