描述性统计量和数据聚合
描述性统计量
描述性统计量通过量化数据来概括数据集。DataFrame和Series可以通过sum、mean、count等方法来获取各种描述性统计量。在默认情况下会按照axis=0返回一个Series,也就是说会得到一个有关列的统计量:

如果要计算行的统计量,需要设置axis=1:
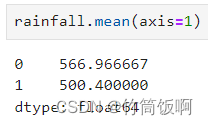
在默认情况下缺失的值不会参与sum和mean的计算。
分组
计算每个大洲学院平均分。首先按大洲分组,随后再应用mean方法。所有包含非数值数据的列都会被自动排除。(书上说会自动屏蔽非数值列,然而我报错了,有没有大佬懂的)

解决方法:显式地选择只包含数值数据的列

使用agg可以使用自己的函数:

透视和熔化

要创建数据透视表,需要将DataFrame作为第一个参数传递给pivot_table函数。index和columns分别指定了哪一列会成为数据透视表的行标签和列标签。values会通过aggfunc被聚合到结果DataFrame中的数据部分。margins对应的是Excel中的Grand Total,如果省略margins和margins_name,则结果中不会出现Total列:

如果想要将列标题转换为列的值,以便从另一个角度透视数据,可以使用melt。id_vars参数定义了标识,values_vars定义了想要反透视的列。