NLP 面试八股:“Transformers / LLM 的词表应该选多大?" 学姐这么告诉我答案
原创 看图学 看图学 2024年07月03日 07:55 北京
![]()
题目:
Transformers/大模型的 token vocabulary 应该选多大?
答案
先说一下结论:
-
数据量够大的情况下,vocabulary 越大,压缩率越高,模型效果越好。
-
太大的 vocabulary 需要做一些训练和推理的优化,所以要 。
-
要考虑内存对齐。vocabulary 的大小设置要是 8 的倍数,在 A100 上则是 64 的倍数。(不同的GPU可能不一样)
下面分别说一下这三点.
越大越好
目前已经有很多研究表明,词表越大模型效果会更好。 比如最近刚发的一篇《Large Vocabulary Size Improves Large Language Models》,里面就详细对比了词表大小分别为:5k, 10k, 50k, 100k and 500k 的效果。如下图所示
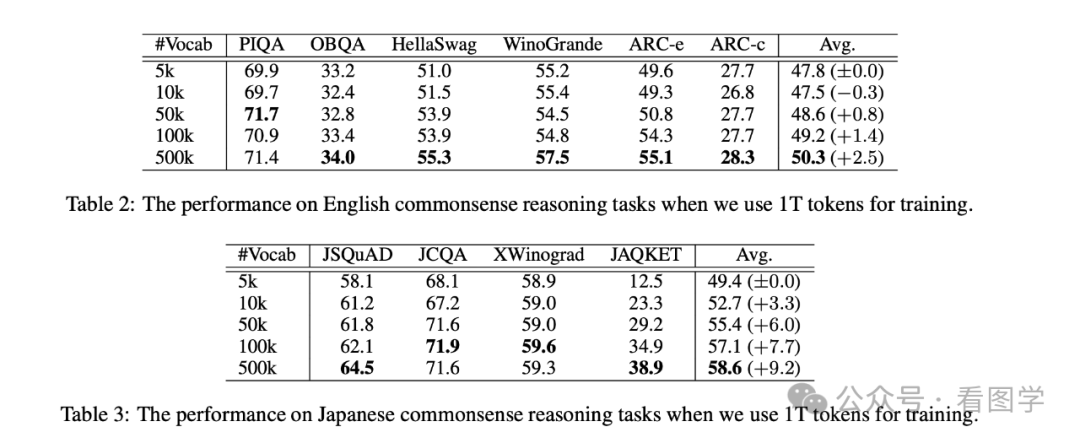
注意这里是完全从头训练的 GPT-3 Large 模型,模型的参数量为 760M。
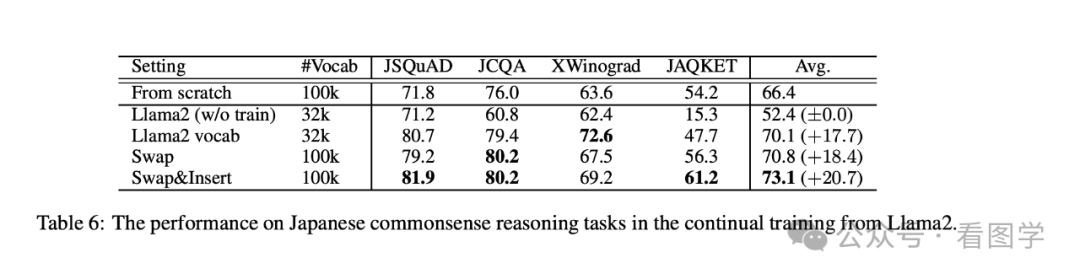
然后作者还尝试了在 llama 的基础上扩大词表继续训练,扩大了词表后效果依然有提升。如下表所示:
为什么词表变大会更好?个人觉得有如下几个原因:
计算效率的提升
相同的文本,转换为token后越短越好。通常用压缩率来衡量文本转换为token后的压缩比例。
更高的压缩率代表了相同数量的token能够表达更多的信息,相同的信息 token 越短则训练效率更高。
Baichuan 在技术报告里给出的一些模型的压缩率如下
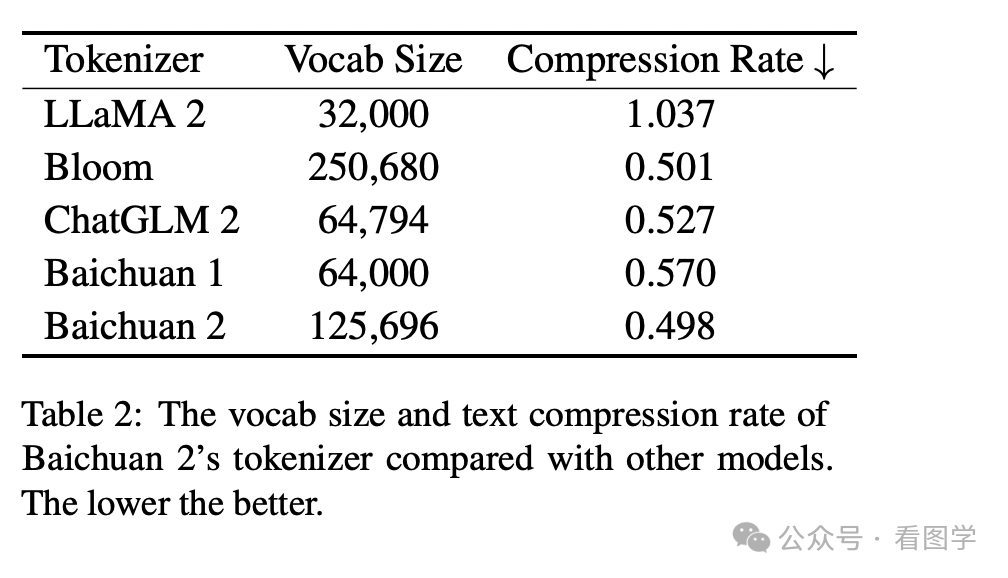
然后千问在技术报告里也提到自家模型的压缩率比其他家更好。
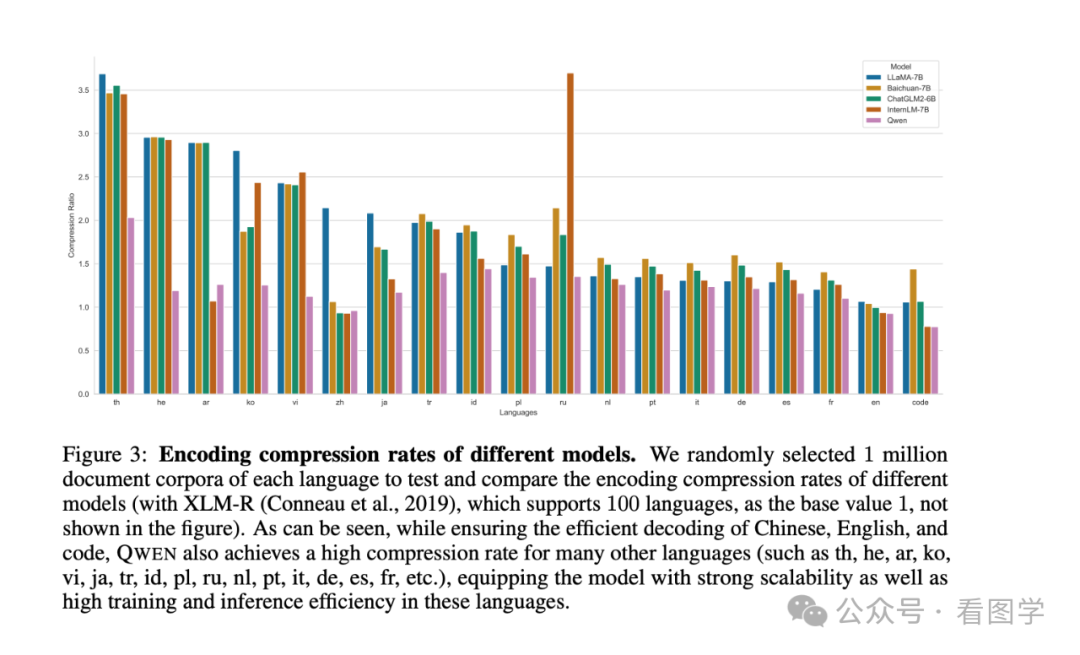
有助于理解文本
更多的词汇能够减少 OOV (Out of Vocabulary)的影响, 训练的信息不会丢失,推理的时候泛化能力也更强。
同时更多的词汇可以减少词汇分解后的歧义,从而更好地理解和生成文本。
更长的上下文
预训练阶段往往都有最大序列长度的限制,压缩率更高代表着能看到更多的上下文,就能 attention 到更多的信息。
还有一些论文比如《Impact of Tokenization on Language Models: An Analysis for Turkish》等也有类似的结论。
计算效率的考虑
虽然 vocabulary 越大越好,但是也不能无限扩大。因为 vocabulary 变大后,Embedding 层变大,最后输出的 Head layer 也会变大。比如 Llama3 将 vocabulary 从 llama2 的 32000 扩展到 128256,参数量就变大了。llama2 还不到7B,但是 Llama3 有 8B了(当然这里面还有其他参数的改动)。
参数更大,更占内存,而且输出的时候 softmax 也更大,计算就更慢。虽然大多数情况下 token 量的减少,整体上是算得更快的。
所以也不能设置得过大,目前业界普遍设置在 10万 到 20万左右。比如 Qwen 的 词表大小为 152064,baichuan2为125696,llama3 为128256,deepseek 为 102400。
多模态的会更大一些。
当然 softmax 过大的问题目前也有解法,可以用 Adaptive softmax,参考论文《Efficient softmax approximation for GPUs》。
内存对齐
之前就有人看到 qwen 的readme 和 训练代码中 vocabulary 的数量不一样, readme 中为 151643,但是实际上代码里写的是 152064。
这就是为了内存对齐。所以很多时候模型上的一些设置其实跟硬件息息相关。
因为最终Embedding 矩阵和输出时候的 Head Layer 最终都会转换成矩阵放到 GPU 的 Tensor Core 中计算。而根据英伟达的开发手册,矩阵运算最好根据 GPU 和计算类型满足如下的条件:
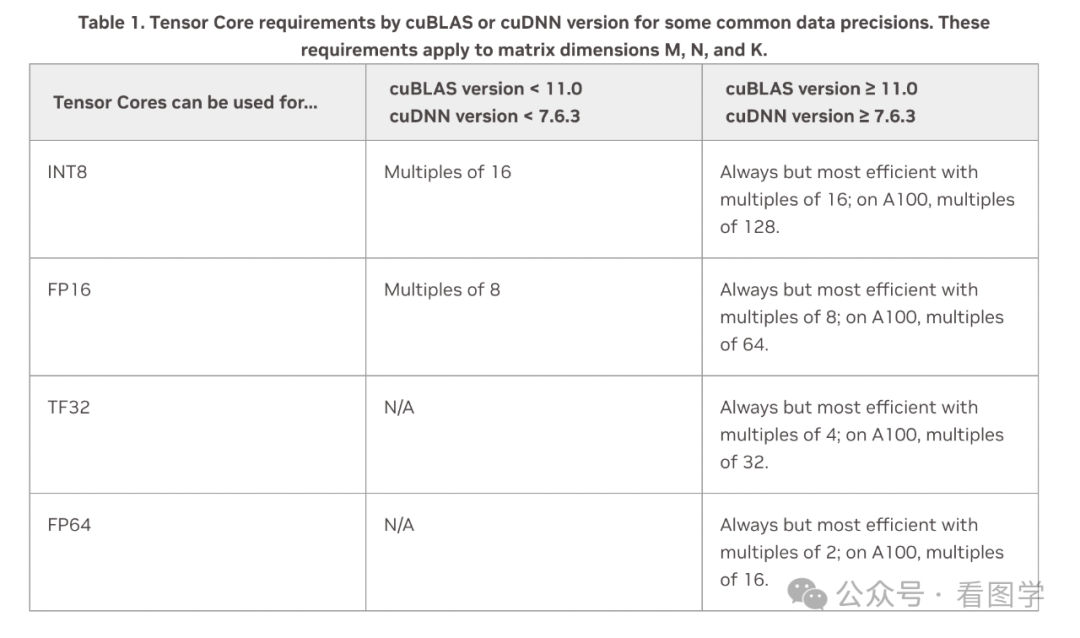
Karpathy 也曾经证实了这一点,他当时写了个 nanoGPT,提升最大的点就是把词表从 50257 改成了 50304,后一个是64的倍数。然后带来了25%的速度上的提升。
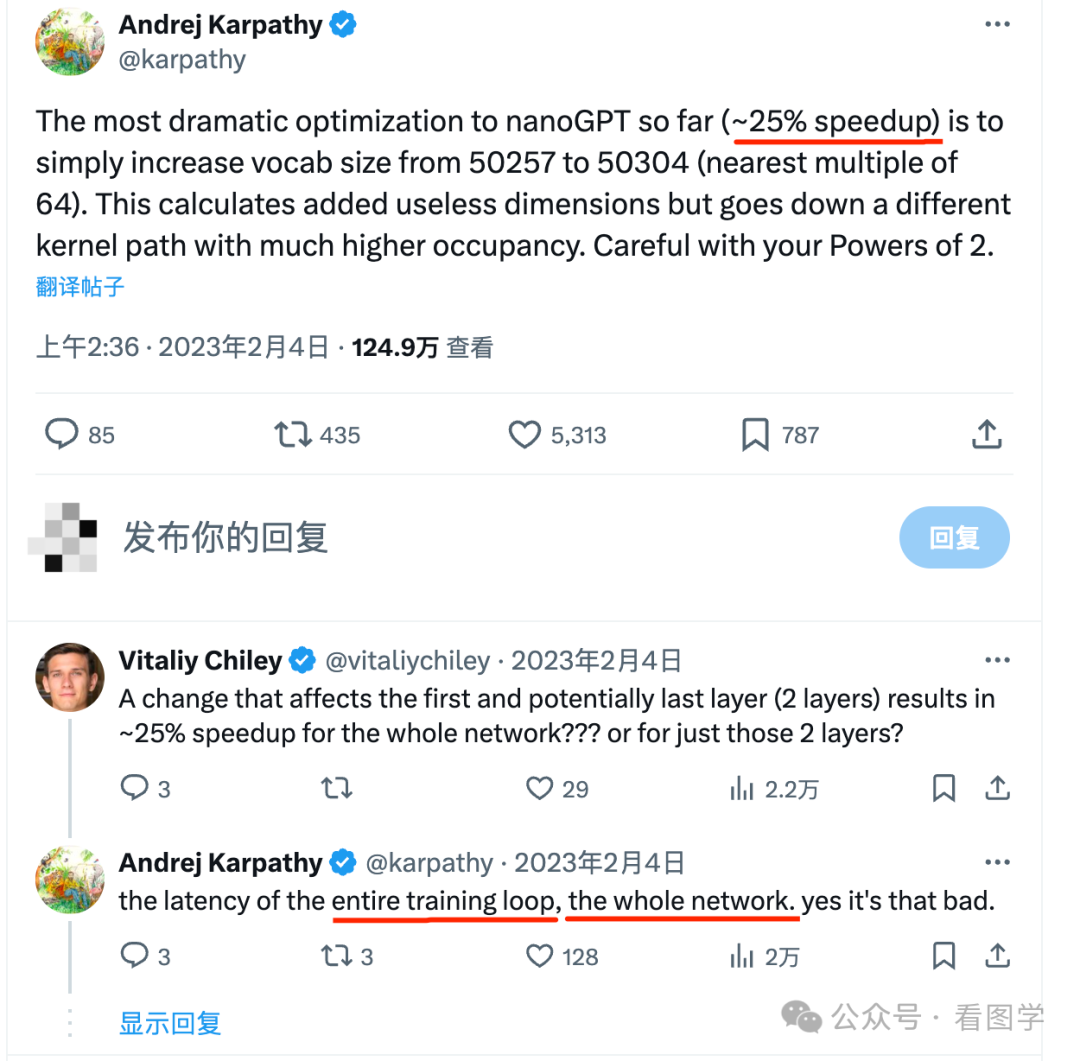
所以目前大多数训练都在 A100 上训练,所以基本上都是64的倍数。如果某个模型的词表不是 64的倍数,那可能不知不觉浪费了很多计算资源。
— END —
推荐阅读:
显卡重要还是女朋友重要?GPU 为什么让人如此着迷?
NLP面试官:“ 简单说下GPU 是怎么工作的?” 算法女生面露难色
看图学大模型:Transformers 的前生今世(上)
RoPE 旋转位置编码,详细解释(下)NLP 面试的女生彻底说明白了