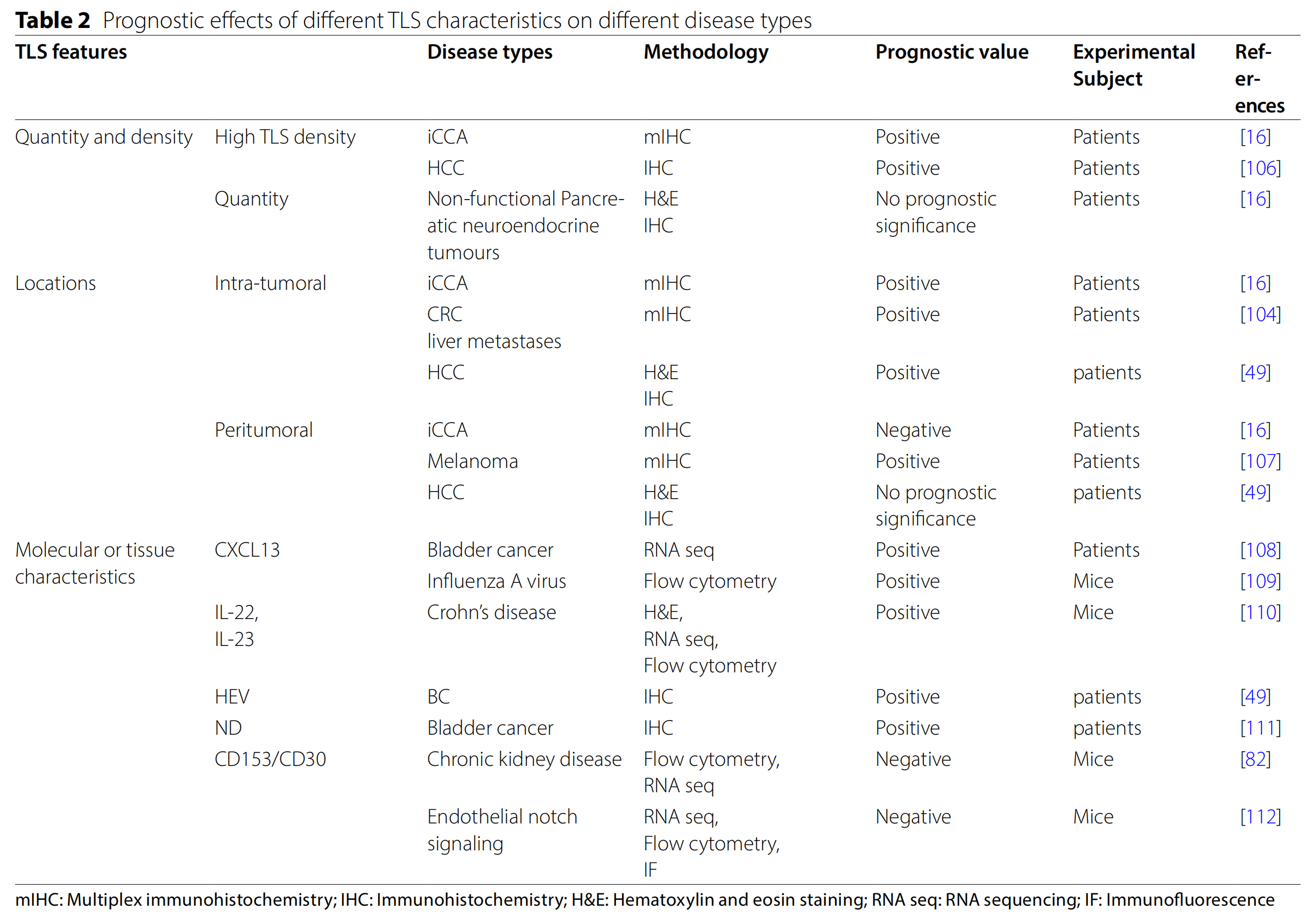
Retriever 是 RAG(Retrieval Augmented Generation)管道中最重要的部分。在本文中,我们将使用 LlamaIndex 实现一个结合关键字和向量搜索检索器的自定义检索器,并且使用 Gemini大模型来进行多个文档聊天。
通过本文,我们将了解到如下内容:
- 深入了解 RAG 管道中 Retriever 和 Generator 组件在上下文生成响应中的作用;
- 学习集成关键字和矢量搜索技术以开发自定义检索器,从而提高 RAG 应用程序中搜索的准确性;
- 熟练掌握使用 LlamaIndex 进行数据摄取,提供给LLMs上下文信息;
- 了解自定义检索器在通过混合搜索机制减轻LLM响应中的幻觉方面的重要性;
- 探索高级检索器实现,例如rerank和 HyDE,以增强 RAG 中的文档相关性;
- 了解如何在 LlamaIndex 中集成 Gemini LLM 和嵌入,以生成响应和存储数据,从而提高 RAG 功能;
- 开发自定义检索器配置的决策技能,包括在 AND 和 OR 操作之间进行选择以优化搜索结果。
一、retriever的重要性

要开发自定义retriever,确定最适合我们需求的retriever类型至关重要。这里,我们将实现一个集成关键字搜索和矢量搜索的混合搜索。
矢量搜索根据相似性或语义搜索来识别用户查询的相关文档,而关键字搜索则根据术语出现的频率来查找文档。使用 LlamaIndex 可以通过两种方式实现这种集成。为混合搜索生成自定义检索器时,一个重要的决策是在使用 AND 或 OR 操作之间进行选择:
- AND 操作:此方法检索包含所有指定术语的文档,使其更具限制性,但确保高度相关性。可以将其视为关键字搜索和矢量搜索之间的结果交集;
- OR 操作:此方法检索包含任何指定术语的文档,从而增加结果的广度,但可能会降低相关性。可以将其视为关键字搜索和矢量搜索之间的结果联合。
二、构建自定义retriever
现在让我们使用 LlamaIndex 构建自定义retriever,大致需要如下步骤:
2.1 安装所需的包
在我们的例子中,使用 LlamaIndex 来构建自定义检索器,使用 Gemini 来构建嵌入模型和LLM推理,并使用 PyPDF 来构建数据连接器,因此,需要安装所需的库。
!pip install llama-index!pip install llama-index-multi-modal-llms-gemini!pip install llama-index-embeddings-gemini
2.2 设置Google API密钥
利用 Google Gemini 作为大型语言模型来生成响应,并作为嵌入模型,使用 LlamaIndex 将数据转换和存储在vector数据库或内存中。
如果没有Google API Key,可以在这里(http://ai.google.dev/)申请。
from getpass import getpassGOOGLE_API_KEY = getpass("Enter your Google API:")
2.3 加载数据并创建文档节点
在 LlamaIndex 中,数据加载是使用 SimpleDirectoryLoader 完成的。首先,需要创建一个文件夹并将任何格式的数据上传到此数据文件夹中。在我们的示例中,我们将把一个 PDF 文件上传到 data 文件夹中。加载文档后,将文档拆分为更小的段,将其解析为节点。节点是在 LlamaIndex 框架中定义的数据架构。
最新版本的 LlamaIndex 更新了其代码结构,现在包括节点解析器、嵌入模型和LLM设置中的定义。
from llama_index.core import SimpleDirectoryReaderfrom llama_index.core import Settingsdocuments = SimpleDirectoryReader('data').load_data()nodes = Settings.node_parser.get_nodes_from_documents(documents)
2.4 设置嵌入模型和大型语言模型
Gemini 有各种型号,包括 gemini-pro、gemini-1.0-pro、gemini-1.5、视觉模型等。这里,我们将使用默认模型并提供 Google API Key。对于 Gemini 中的嵌入模型,我们目前使用的是 embedding-001。
from llama_index.embeddings.gemini import GeminiEmbeddingfrom llama_index.llms.gemini import GeminiSettings.embed_model = GeminiEmbedding(model_name="models/embedding-001", api_key=GOOGLE_API_KEY)Settings.llm = Gemini(api_key=GOOGLE_API_KEY)
2.5 定义Storage context,并存储数据
一旦数据被解析为节点,LlamaIndex 就会提供一个存储上下文,它提供默认的文档存储,用于存储数据的向量嵌入。此存储上下文将数据保留在内存中,以便以后对其进行索引。
from llama_index.core import StorageContextstorage_context = StorageContext.from_defaults()storage_context.docstore.add_documents(nodes)

为了构建自定义检索器以执行混合搜索,我们需要创建两个索引。第一个可以执行向量搜索的向量索引,第二个可以执行关键字搜索的关键字索引。为了创建索引,我们需要存储上下文和节点文档,以及嵌入模型和LLM的默认设置。
from llama_index.core import SimpleKeywordTableIndex, VectorStoreIndexvector_index = VectorStoreIndex(nodes, storage_context=storage_context)keyword_index = SimpleKeywordTableIndex(nodes, storage_context=storage_context)
2.6 构建自定义Retriever
要使用 LlamaIndex 构建用于混合搜索的自定义检索器,我们首先需要定义架构,尤其是配置合适的节点。需要矢量索引检索器和关键字检索器来执行混合搜索,是通过指定模式(AND 或 OR)来实现这两种检索器的组合,集成这两种技术以最大限度地减少幻觉。
一旦节点配置好后,我们就可以使用 vector 和 keyword 检索器查询每个节点 ID 的数据。然后,根据所选模式,最终确定自定义检索器。
from llama_index.core import QueryBundlefrom llama_index.core.schema import NodeWithScorefrom llama_index.core.retrievers import (BaseRetriever,VectorIndexRetriever,KeywordTableSimpleRetriever,)from typing import Listclass CustomRetriever(BaseRetriever):def __init__(self,vector_retriever: VectorIndexRetriever,keyword_retriever: KeywordTableSimpleRetriever,mode: str = "AND") -> None:self._vector_retriever = vector_retrieverself._keyword_retriever = keyword_retrieverif mode not in ("AND", "OR"):raise ValueError("Invalid mode.")self._mode = modesuper().__init__()def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:vector_nodes = self._vector_retriever.retrieve(query_bundle)keyword_nodes = self._keyword_retriever.retrieve(query_bundle)vector_ids = {n.node.node_id for n in vector_nodes}keyword_ids = {n.node.node_id for n in keyword_nodes}combined_dict = {n.node.node_id: n for n in vector_nodes}combined_dict.update({n.node.node_id: n for n in keyword_nodes})if self._mode == "AND":retrieve_ids = vector_ids.intersection(keyword_ids)else:retrieve_ids = vector_ids.union(keyword_ids)retrieve_nodes = [combined_dict[r_id] for r_id in retrieve_ids]return retrieve_nodes
2.7 定义retriever
定义好自定义检索器类后,我们需要实例化检索器并合成查询引擎。响应合成器用于根据用户查询和给定的文本块集生成LLM响应。Response Synthesizer 的输出是一个 Response 对象,该对象将自定义检索器作为参数之一。
from llama_index.core import get_response_synthesizerfrom llama_index.core.query_engine import RetrieverQueryEnginevector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k=2)keyword_retriever = KeywordTableSimpleRetriever(index=keyword_index)# custom retriever => combine vector and keyword retrievercustom_retriever = CustomRetriever(vector_retriever, keyword_retriever)# define response synthesizerresponse_synthesizer = get_response_synthesizer()custom_query_engine = RetrieverQueryEngine(retriever=custom_retriever,response_synthesizer=response_synthesizer,)
2.8 运行自定义检索查询引擎
最后,我们已经开发好了自定义的retriever,它可以显著减少幻觉。为了测试其有效性,我们使用一个包括上下文的提示和一个不包括上下文的提示来评估生成的响应。
query = "what does the data context contain?"print(custom_query_engine.query(query))print(custom_query_engine.query("what is science?")