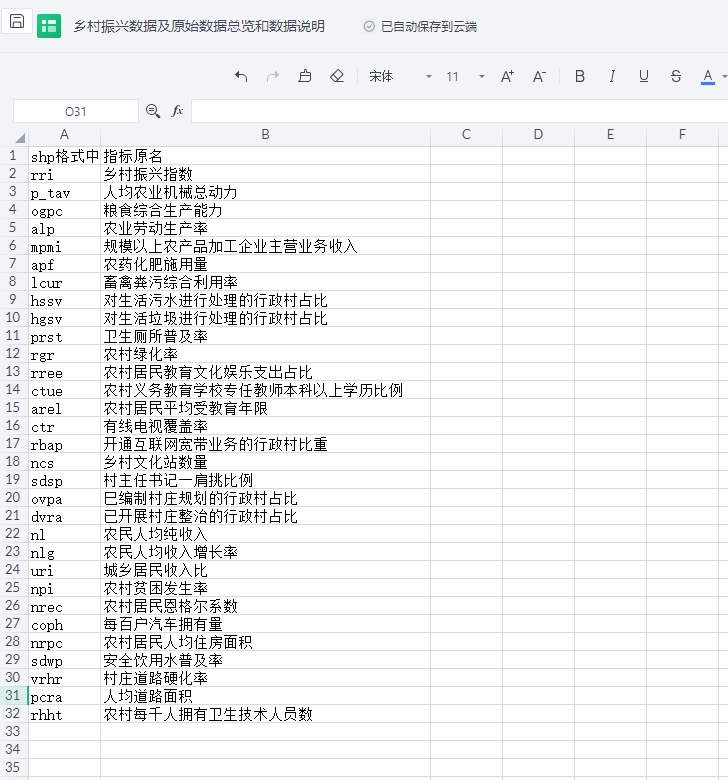
论文:arxiv.org/pdf/2312.00858
代码:horseee/DeepCache: [CVPR 2024] DeepCache: Accelerating Diffusion Models for Free (github.com)
介绍
DeepCache是一种新颖的无训练且几乎无损的范式,从模型架构的角度加速了扩散模型。DeepCache利用 扩散模型顺序去噪步骤中观察到的固有时间冗余,缓存和检索相邻去噪阶段的特征,从而减少冗余计算。利用U-Net的特性,重用高级特征,同时以低成本的方式更新低级特征。将 Stable Diffusion v1.5 加速了 2.3 倍,CLIP 分数仅下降了 0.05 倍,LDM-4-G(ImageNet) 加速了 4.1 倍,FID 降低了 0.22。
动机:
由于顺序去噪过程和繁琐的模型尺寸,训练扩散模型会产生大量的计算成本。本文希望在没有额外训练的情况下,减少每个去噪步骤的计算开销,从而实现对扩散模型的无成本压缩。
背景:
反向扩散过程的加速。反向扩散过程的固有性质减慢了推理速度。目前的研究主要集中在两种加速扩散模型推理的方法上:
- 优化采样效率。侧重于减少采样步骤的数量。DDIM、一致性模型将随机噪声转换为初始图像,只需要进行一次模型评估。
- 优化结构效率。减少每个采样步骤的推理时间。
U-Net的高级和低级特征。由于跳跃式连接,UNet具有很强的合并低级和高级特征的能力。U-Net构建在堆叠的下采样和上采样块上,将输入图像编码为高级表示,然后对其进行解码,用于下游任务。表示为![]() 的块对,通过额外的跳过路径连接,直接将低级的信息从Di转发到Ui。在U-Net体系结构的前向传播过程中,数据通过两条路径并发地遍历:主分支和跳过分支。这些分支汇聚在一个连接模块,主分支提供处理过的高级特征,这些特征来自前面的上采样块Ui+1,而跳过分支提供来自对称块Di的相应特征。因此,U-Net模型的核心是来自跳过分支的低级特征和来自主分支的高级特征的连接:
的块对,通过额外的跳过路径连接,直接将低级的信息从Di转发到Ui。在U-Net体系结构的前向传播过程中,数据通过两条路径并发地遍历:主分支和跳过分支。这些分支汇聚在一个连接模块,主分支提供处理过的高级特征,这些特征来自前面的上采样块Ui+1,而跳过分支提供来自对称块Di的相应特征。因此,U-Net模型的核心是来自跳过分支的低级特征和来自主分支的高级特征的连接:![]()

原理
序列去噪中的特征冗余
去噪过程中的相邻步骤在高级特征上表现出显著的时间相似性。
图2实验揭示了两个主要观点:
- 在去噪过程中,相邻步骤之间,存在明显的时间特征相似性,表明连续步骤之间的变化通常较小。
- 无论使用哪种扩散模型,如稳定扩散、LDM和DDPM,对于每个时间步长,至少有10%的相邻时间步长与当前步长表现出高度相似(>0.95),这表明某些高级特征以渐进的速度变化。

每次计算,得到的特征都与前一步相似,存在大量冗余计算,产生边际效益。本文目标是利用这一特性来加速去噪过程。
扩散模型的深度缓存
DeepCache利用反向扩散过程中步骤之间的时间冗余来加速推理。从计算机系统中的缓存机制中获得灵感,结合了为随时间变化最小的元素设计的存储组件。应用于扩散模型,通过缓存那些变化缓慢的特征,来消除冗余计算,从而无需在后续步骤中重复计算。
实现重点为U-Net中的跳过连接,它本质上提供了双路径优势:主分支需要大量的计算来遍行整个网络,而跳过分支只需要通过一些浅层,从而产生非常小的计算负载。主要分支中突出的特征相似性允许重用已经计算的结果,而不是为所有时间步重复计算。
去噪中的可缓存特性。
在两个连续时间步长 𝑡 和 𝑡−1 之间,根据反向过程,𝑥𝑡−1 将基于先前的结果 𝑥𝑡 进行条件生成。实验:首先生成 𝑥𝑡,计算跨整个U-Net进行。为了获得下一个输出 𝑥𝑡−1,我们检索在先前时间步长 𝑡 中生成的高层次特征。即,考虑U-Net中的一个跳跃分支 𝑚,它连接 𝐷𝑚 和 𝑈𝑚,在时间 𝑡 从先前的上采样块缓存特征图:
![]()
这是时间步长 𝑡 的主分支中的特征。这些缓存的特征将在后续推理中使用。
在下一个时间步长 𝑡−1 中,推理并不在整个网络上进行,只计算 m-th 跳跃分支中所需的部分,并用缓存中的特征替代主分支的计算。因此,时间步长 𝑡−1 中 𝑈𝑡−1𝑚 的输入可表示为:
![]()
𝐷𝑡−1𝑚 代表 m-th 下采样块的输出,如果选择一个较小的 𝑚,则只包含几层。例如,如果我们在第一层执行 DeepCache 并选择 𝑚=1,则只需要执行一个下采样块以获得![]() 。至于第二个特征
。至于第二个特征 ![]() ,由于可以简单地从缓存中检索,因此不需要额外的计算成本。过程如图3.
,由于可以简单地从缓存中检索,因此不需要额外的计算成本。过程如图3.

在第t - 1步,通过重用第t步缓存的特征,来生成xt - 1,并且为了更有效的推理,不执行D2, D3, U2, U3块。
扩展到1:N推理。缓存的特征计算一次,可以在后续的N−1步中重用,以取代原始的![]() 。对于所有去噪的T步,执行完全推理的时间步长序列为:
。对于所有去噪的T步,执行完全推理的时间步长序列为:

非均匀1:N推理。
基于1:N策略,在假定高级特征在连续N步中不变的前提下,成功地加速了扩散推理。然而,并非总是如此,特别是对于N,如图2(c)所示,特征的相似性并不是在所有步骤中都保持不变。对于像LDM这样的模型,特征的时间相似性会在去噪过程中显著降低40%左右。
因此,对于非均匀的1:N推理,我们倾向于对那些与相邻步骤相似度相对较小的步骤进行更多采样。在这里,执行完整推理的时间步长序列变为:








使用
import torch
from diffusers import StableDiffusionPipeline
from DeepCache import DeepCacheSDHelper
# 加载 Stable Diffusion 模型
pipe = StableDiffusionPipeline.from_pretrained('runwayml/stable-diffusion-v1-5', torch_dtype=torch.float16).to("cuda:0")
# 创建 DeepCacheSDHelper 对象
helper = DeepCacheSDHelper(pipe=pipe)
# 设置缓存参数
helper.set_params(
cache_interval=3,
cache_branch_id=0,
)
# 启用缓存机制
helper.enable()
# 定义输入提示词
prompt = "a beautiful landscape with mountains and rivers"
# 生成图像
deepcache_image = pipe(
prompt,
output_type='pt'
).images[0]
# 禁用缓存机制
helper.disable()
库:
diffusers==0.24.0
transformer
仅需要用DeepCache提供的Pipeline替换Diffusers库的Pipeline,即可实现扩散模型加速。目前支持 StableDiffusionPipeline 可以加载的模型。可以通过参数指定模型名称。
尝试1:将 DeepCacheSDHelper 应用于整个 pipeline,并确保缓存机制只启用一次
pipe = Pose2VideoPipeline(
vae=vae,
image_encoder=image_enc,
reference_unet=reference_unet,
denoising_unet=denoising_unet,
pose_guider=pose_guider,
scheduler=scheduler,
)
pipe = pipe.to("cuda", dtype=weight_dtype)
# 初始化 DeepCacheSDHelper
helper = DeepCacheSDHelper(pipe=pipe)
# 设置缓存参数
helper.set_params(
cache_interval=3,
cache_branch_id=0,
)
# 启用缓存机制
helper.enable()报错:
AttributeError: 'Pose2VideoPipeline' object has no attribute 'unet'报错信息显示 Pose2VideoPipeline 对象没有 unet 属性,这说明 DeepCacheSDHelper 无法找到所需的 UNet 模型。要解决这个问题,必须确保传递给 DeepCacheSDHelper 的 pipeline 具有 unet 属性,并且该属性指向实际的 UNet 模型。
而 Pose2VideoPipeline 包含多个 UNet 模型( reference_unet 和 denoising_unet),需要对 DeepCacheSDHelper 进行修改,使其能够处理这种情况。一种解决方法是扩展 DeepCacheSDHelper 以接受多个 UNet 模型。解决方案:修改DeepCacheSDHelper类,将 pipe 和包含所有 UNet 模型的列表传递给 DeepCacheSDHelper:
pipe = Pose2VideoPipeline(
vae=vae,
image_encoder=image_enc,
reference_unet=reference_unet,
denoising_unet=denoising_unet,
pose_guider=pose_guider,
scheduler=scheduler,
)
pipe = pipe.to("cuda", dtype=weight_dtype)
# Initialize DeepCacheSDHelper with both UNet models
helper = DeepCacheSDHelper(pipe=pipe, unets=[reference_unet, denoising_unet])
helper.set_params(
cache_interval=3,
cache_branch_id=0,
)
helper.enable()
尝试2:分别对 reference_unet 和 denoising_unet 初始化并启用 DeepCacheSDHelper。
reference_unet = UNet2DConditionModel.from_pretrained(
config.pretrained_base_model_path,
subfolder="unet",
).to(dtype=weight_dtype, device="cuda")
# Import the DeepCacheSDHelper
helper = DeepCacheSDHelper(reference_unet=reference_unet)
helper.set_params(
cache_interval=3,
cache_branch_id=0,
)
helper.enable()
inference_config_path = config.inference_config
infer_config = OmegaConf.load(inference_config_path)
denoising_unet = UNet3DConditionModel.from_pretrained_2d(
config.pretrained_base_model_path,
config.motion_module_path,
subfolder="unet",
unet_additional_kwargs=infer_config.unet_additional_kwargs,
).to(dtype=weight_dtype, device="cuda")
helper = DeepCacheSDHelper(denoising_unet=denoising_unet)
helper.set_params(
cache_interval=3,
cache_branch_id=0, # 指定缓存的分支 ID,上下两个unet是否需要不同分支?
)
helper.enable()
TypeError: DeepCacheSDHelper.__init__() got an unexpected keyword argument 'reference_unet', DeepCacheSDHelper 需要对 pipeline 中所有相关的 UNet 模型进行统一处理,而不是分别处理。