【大模型】可商用且更强的 LLaMA2 来了
- LLaMA2 简介
-
- 论文
- GitHub
- huggingface
- 模型列表
- 训练数据
- 训练信息
- 模型信息
- 论文
- 许可证
- 参考
LLaMA2 简介
2023年7月19日:Meta 发布开源可商用模型 Llama 2。
Llama 2是一个预训练和微调的生成文本模型的集合,其规模从70亿到700亿个参数不等。
经过微调的LLMs称为Llama-2-Chat,针对对话用例进行了优化。Llama-2-Chat模型在我们测试的大多数基准测试中都优于开源聊天模型,在对有用性和安全性的人工评估中,与ChatGPT和PaLM等一些流行的封闭源代码模型不相上下。
LLaMA-2-chat 几乎是开源模型中唯一做了 RLHF 的模型。LLaMA-2 经过 5 轮 RLHF 后,在 Meta 自己的 reward 模型与 GPT-4 的评价下,都表现出了超过 ChatGPT 性能。
论文
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
GitHub
地址:
https://github.com/facebookresearch/llama
huggingface
地址:
https://huggingface.co/meta-llama
模型列表

Llama2-chat:
Llama2-chat-7B
Llama2-chat-13B
Llama2-chat-70B
其他模型请查看:
https://huggingface.co/meta-llama
训练数据
- 在超过2万亿tokens数据集上训练。
- 微调数据包括公开可用的指令数据集,以及超过100万个新的人工注释示例。
- 预训练数据的截止日期为2022年9月
训练信息
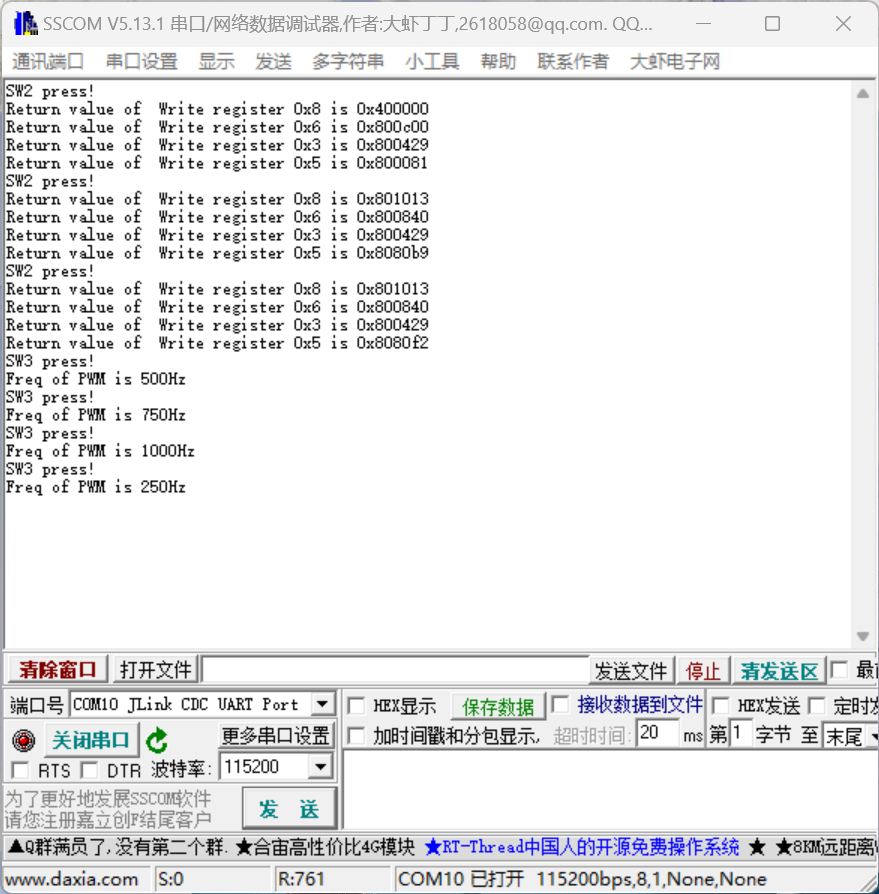
- 所有模型都使用全局批量大小为4M tokens进行训练。
- 更大的700亿参数模型使用Grouped-Query Attention(GQA)来提高推理可扩展性。
- 训练时间为2023年1月至2023年7月。
- 是一个纯文本模型。
- 预训练过程中,在 A100-80GB 花费了33万GPU小时。
模型信息
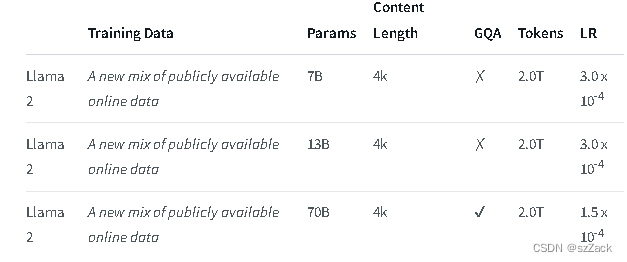
上下文长度为 4K。
许可证
免费商用
需要注册申请
参考
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
https://github.com/facebookresearch/llama
https://huggingface.co/meta-llama
Llama2-chat-7B
Llama2-chat-13B
Llama2-chat-70B













![[激光原理与应用-100]:南京科耐激光-激光焊接-焊中检测-智能制程监测系统IPM介绍 - 4 - 3C电池行业应用 - 不同的电池类型、焊接方式类型](https://i-blog.csdnimg.cn/direct/4fc7a89800b04930a6c750d4d42de69b.png)