目录
- 1. 入门实战目的
- 2. Hive源数据准备
- 3. 创建project并添加Hive数据源
- 4. 定义model
- 5. 定义Cube
- 6. 构建cube
- 7. 查询cube构建后的结果
- 8. 查询限制
1. 入门实战目的
实现从不同的维度统计员工的工资,例如从岗位类型、员工年龄、部门等不同维度,进行多维度的工资查询
2. Hive源数据准备
创建数据库
0: jdbc:hive2://kylin1:10000> create database kylin_test;
0: jdbc:hive2://kylin1:10000> use kylin_test;
创建员工表和部门表
0: jdbc:hive2://kylin1:10000> create external table if not exists employee(
emp_no int comment '员工ID',
emp_name string comment '员工姓名',
job string comment '岗位名称',
birthday string comment '员工生日',
salary double comment '薪水',
reward double comment '奖金',
depart_no int comment '部门ID'
) row format delimited fields terminated by '\t';
0: jdbc:hive2://kylin1:10000>
0: jdbc:hive2://kylin1:10000> create external table if not exists department(
depart_no int comment '部门ID',
depart_name string comment '部门名称',
city string comment '城市'
) row format delimited fields terminated by '\t';
0: jdbc:hive2://kylin1:10000>
查看源数据文件
[root@kylin1 ~]# cat employee.txt
1 emp_name_1 大数据工程师 2000-01-01 13000 400 1
2 emp_name_2 大数据工程师 2000-01-01 13000 400 1
3 emp_name_3 大数据工程师 2000-01-01 13000 400 1
4 emp_name_4 大数据工程师 2000-01-01 13000 400 1
5 emp_name_5 大数据工程师 2000-01-01 13000 400 1
6 emp_name_6 Java工程师 2001-01-01 12000 300 2
7 emp_name_7 Java工程师 2001-01-01 12000 300 2
8 emp_name_8 Java工程师 2001-01-01 12000 300 2
9 emp_name_9 Java工程师 2001-01-01 12000 300 2
10 emp_name_10 Java工程师 2001-01-01 12000 300 2
11 emp_name_11 前端工程师 2002-01-01 11000 200 3
12 emp_name_12 前端工程师 2002-01-01 11000 200 3
13 emp_name_13 前端工程师 2002-01-01 11000 200 3
14 emp_name_14 前端工程师 2002-01-01 11000 200 3
15 emp_name_15 前端工程师 2002-01-01 11000 200 3
16 emp_name_16 产品经理 2003-01-01 10000 100 4
17 emp_name_17 产品经理 2003-01-01 10000 100 4
18 emp_name_18 产品经理 2003-01-01 10000 100 4
19 emp_name_19 产品经理 2003-01-01 10000 100 4
20 emp_name_20 产品经理 2003-01-01 10000 100 4
[root@kylin1 ~]#
[root@kylin1 ~]# cat department.txt
1 数据部 北京
2 后端部 北京
3 前端部 上海
4 产品部 上海
[root@kylin1 ~]#
导入源数据到Hive
0: jdbc:hive2://kylin1:10000> load data local inpath '/root/employee.txt' into table employee;
0: jdbc:hive2://kylin1:10000> load data local inpath '/root/department.txt' into table department;
3. 创建project并添加Hive数据源
创建project
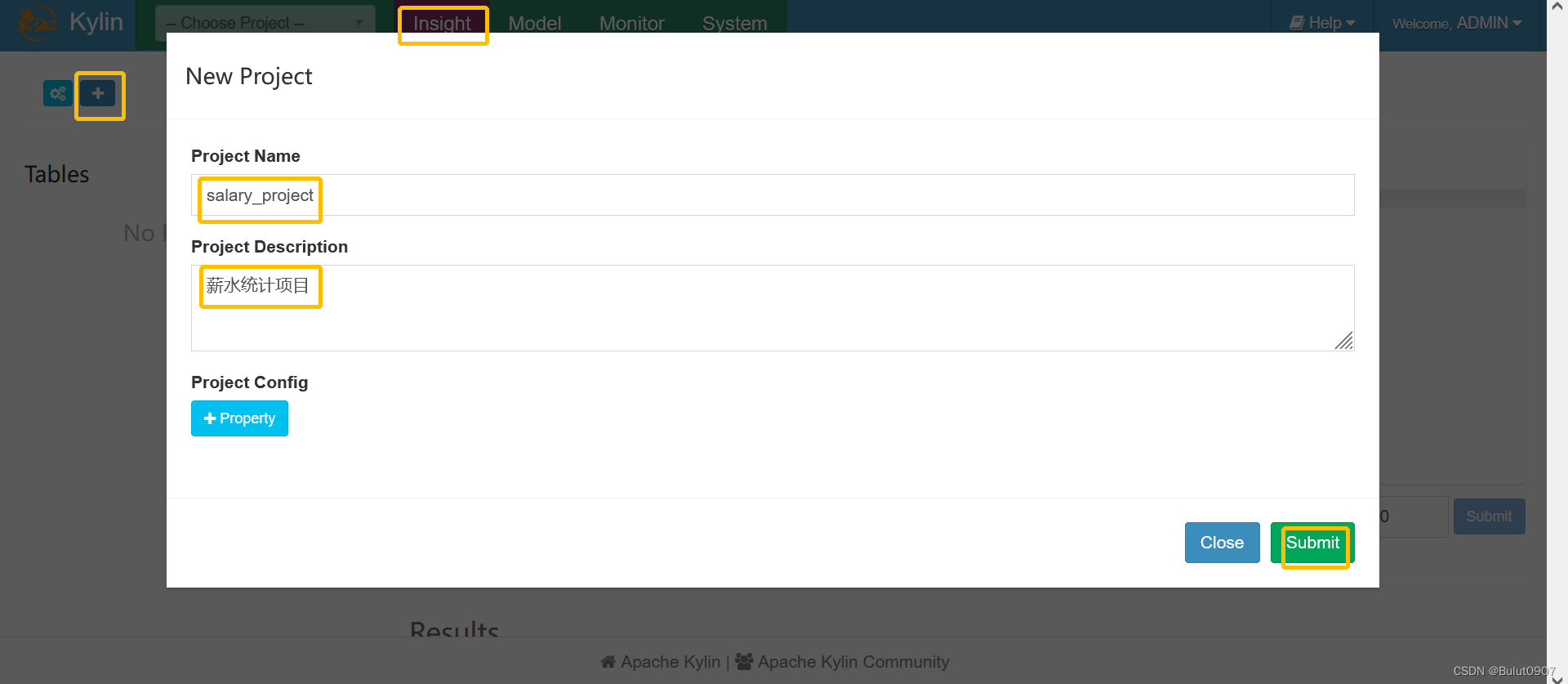
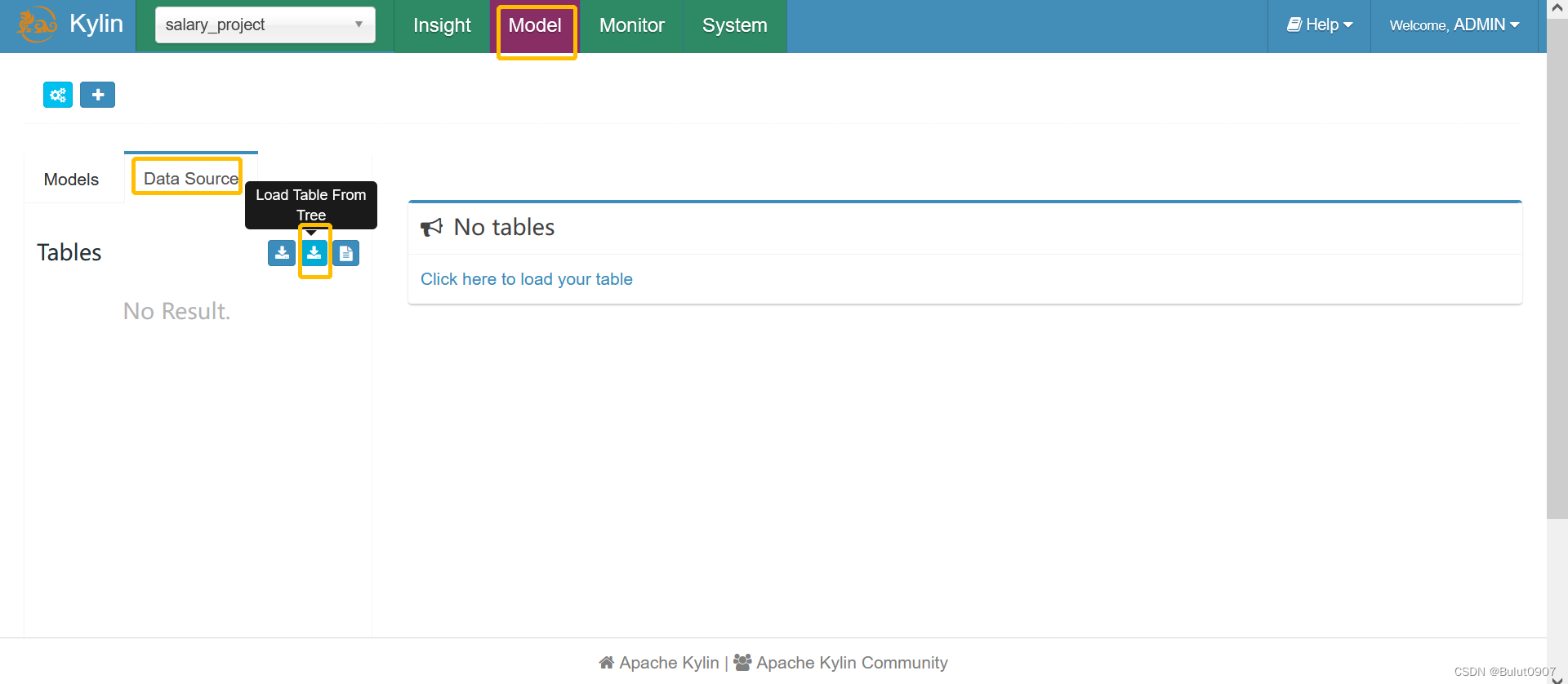
这里有三种添加kylin数据源的方式:
- 手动输入想添加的Hive表,格式为:db1.tb1,db2.tb2
- 从hive数据库表结构中,选择需要添加的数据源
- 上传CSV文件,并选择第一行是否是表头、每列的分隔符,再输入一个虚拟的数据库和表名,比如:db1.tb1
这里我们选择第二种。将选择的数据源信息元数据同步到mysql
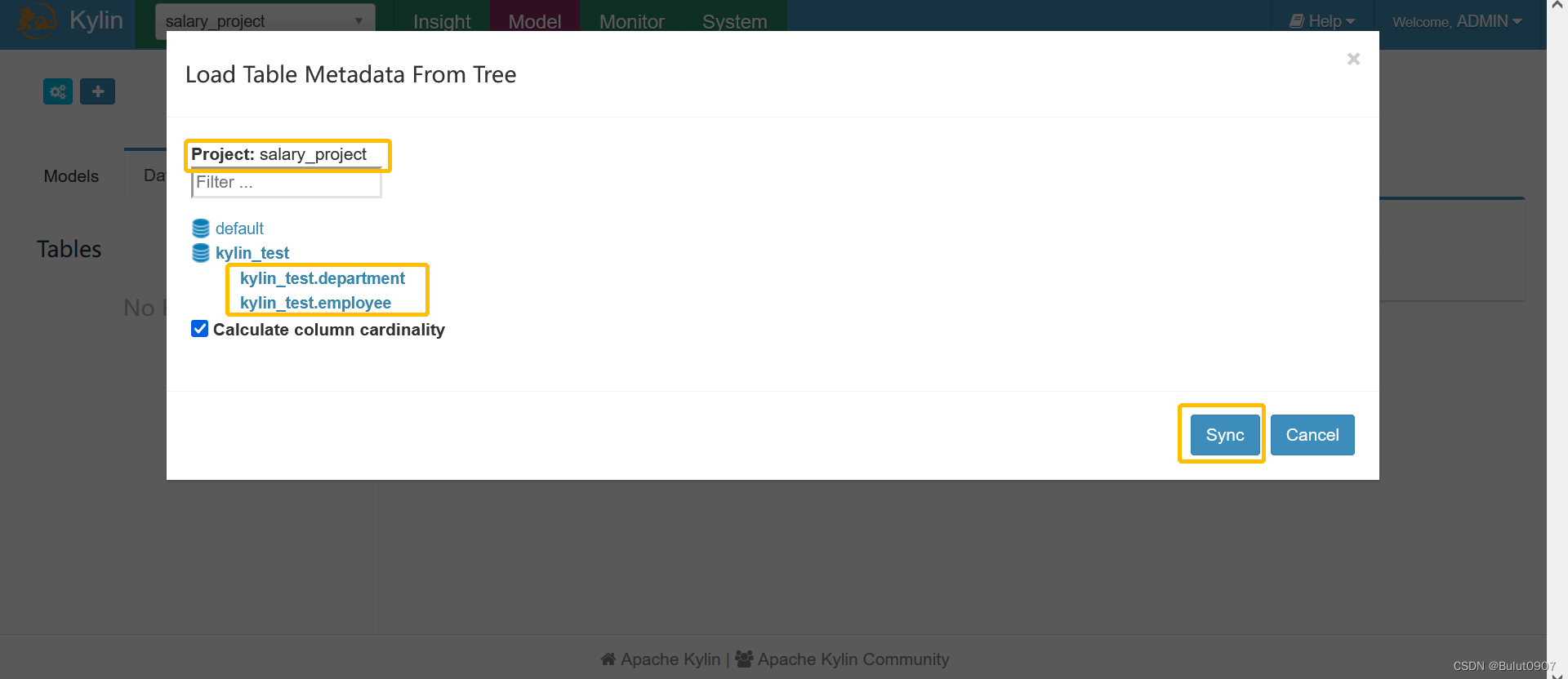
4. 定义model
新建model
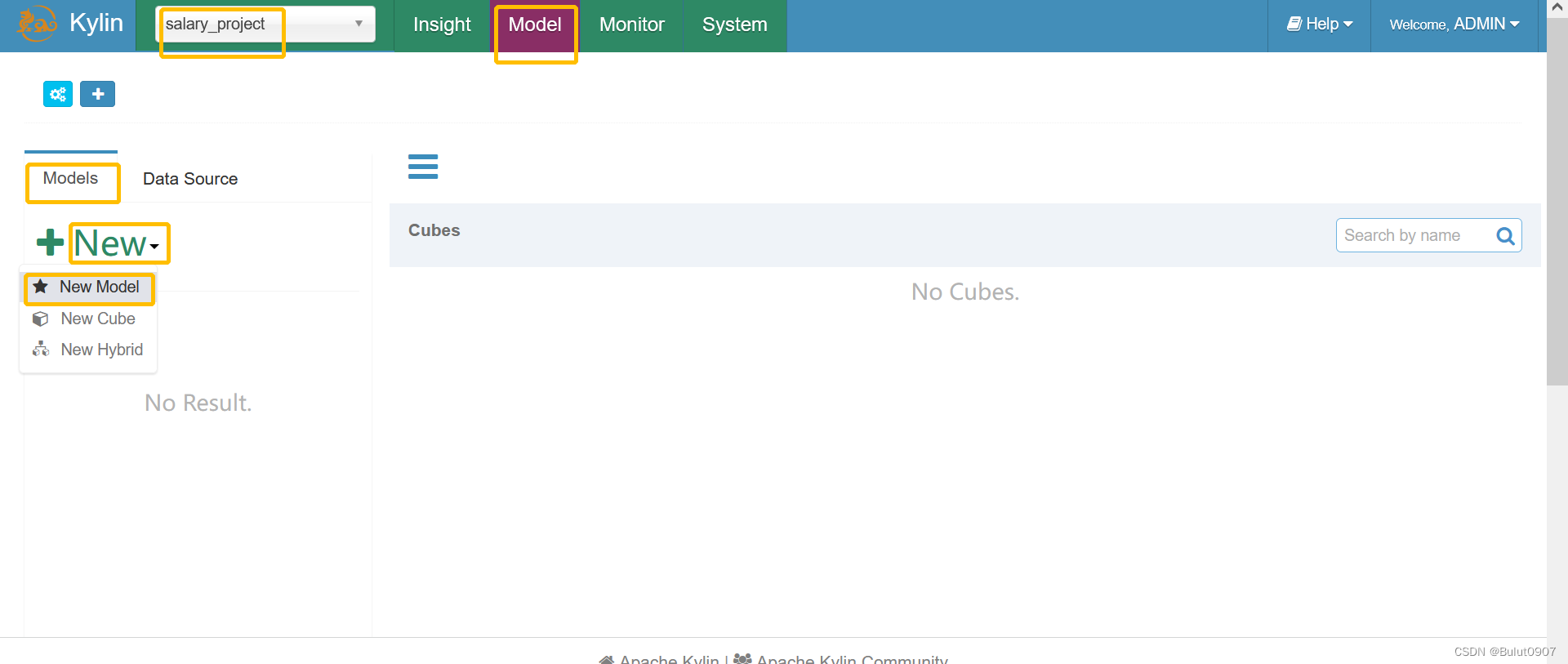 第一步:定义model信息
第一步:定义model信息
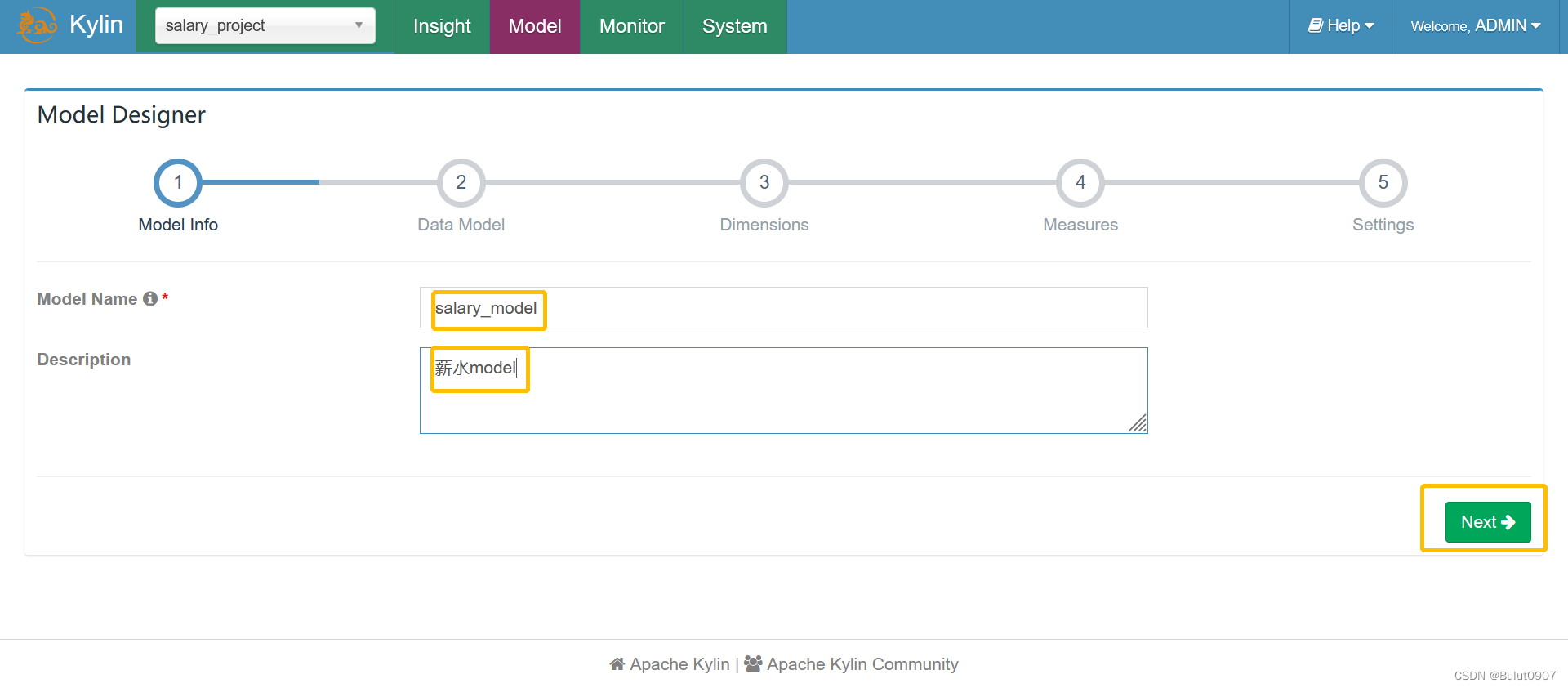
第二步:定义model的表
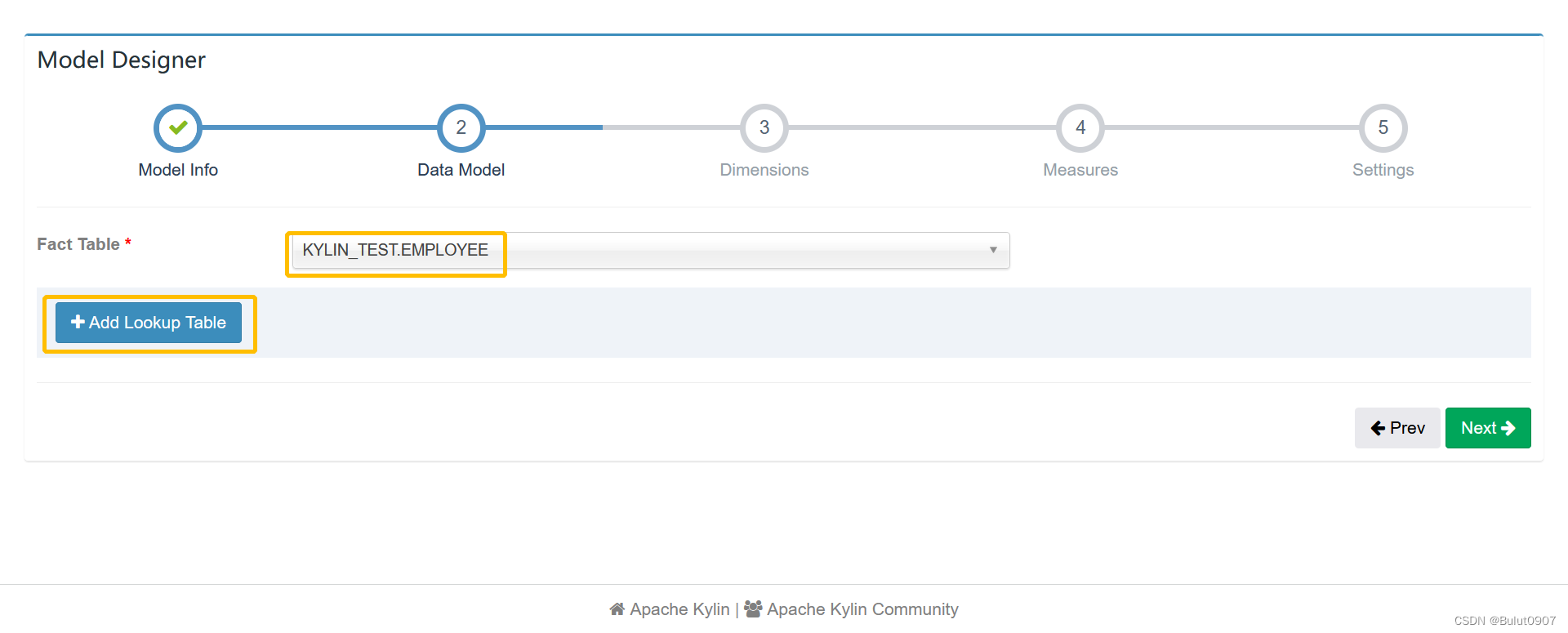
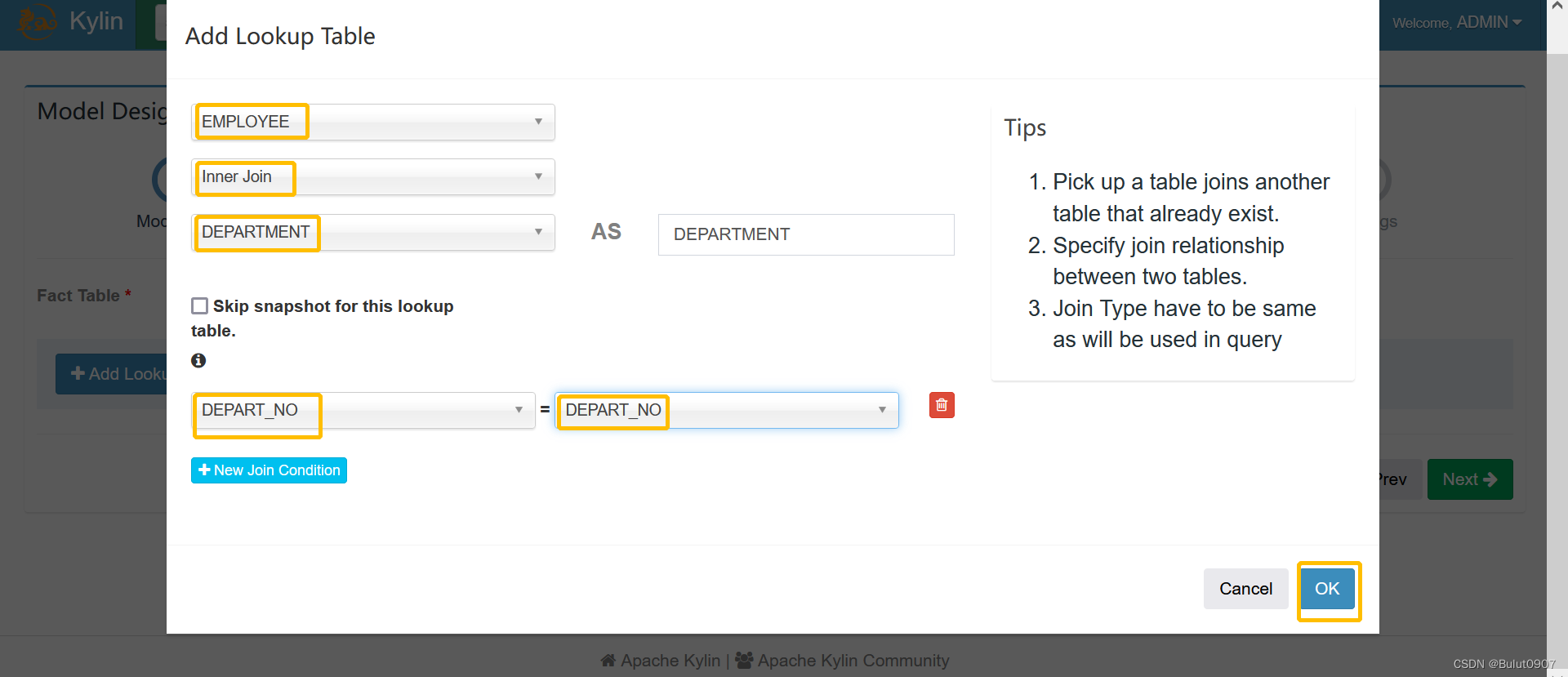 说明:
说明:
- 如果维度表太大,比如大于300MB,则不要对该维度表进行snapshot。导致不能直接查询该维度表,和不能从该维度表定义Cube的衍生维度字段
- 两个表的join字段类型必须一致
再点击Next,进入下一步
第三步:选择model的维度字段
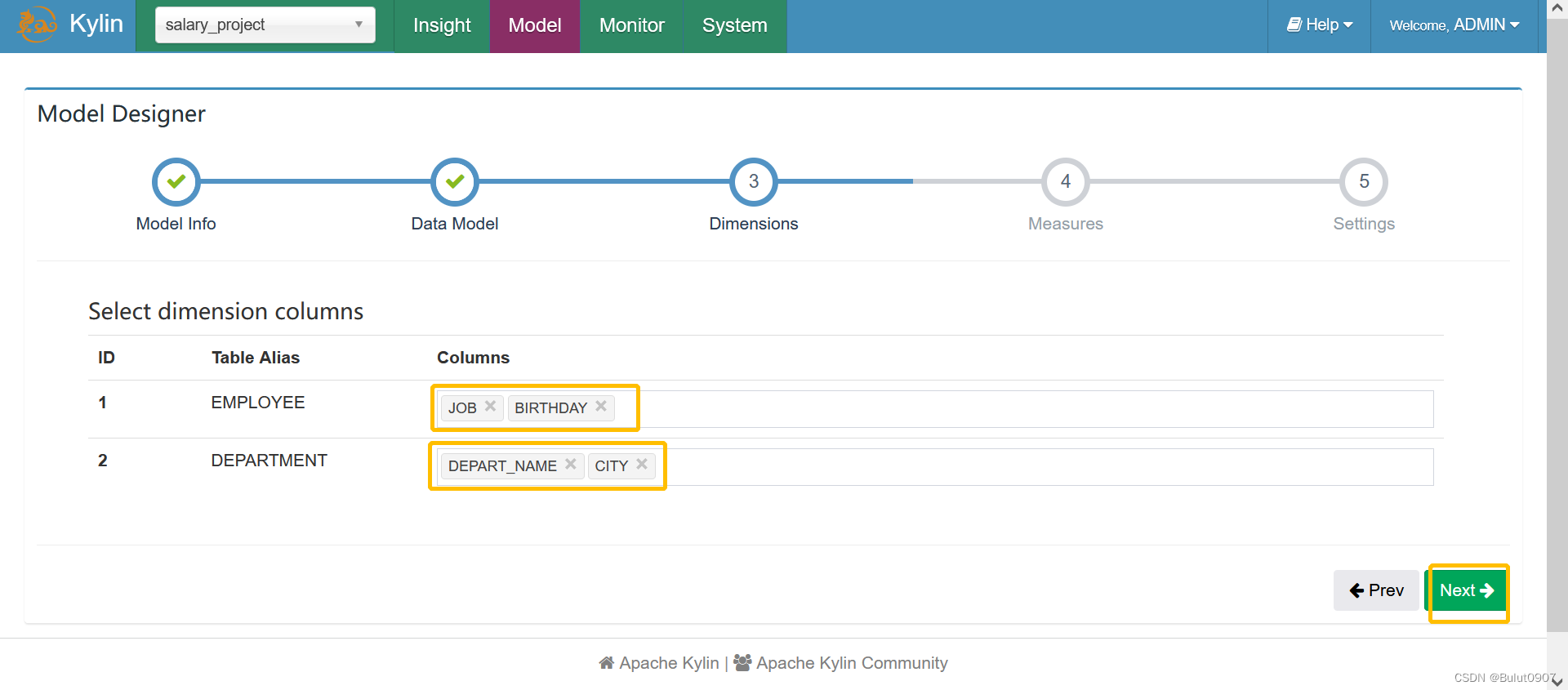
第四步:选择model的度量字段
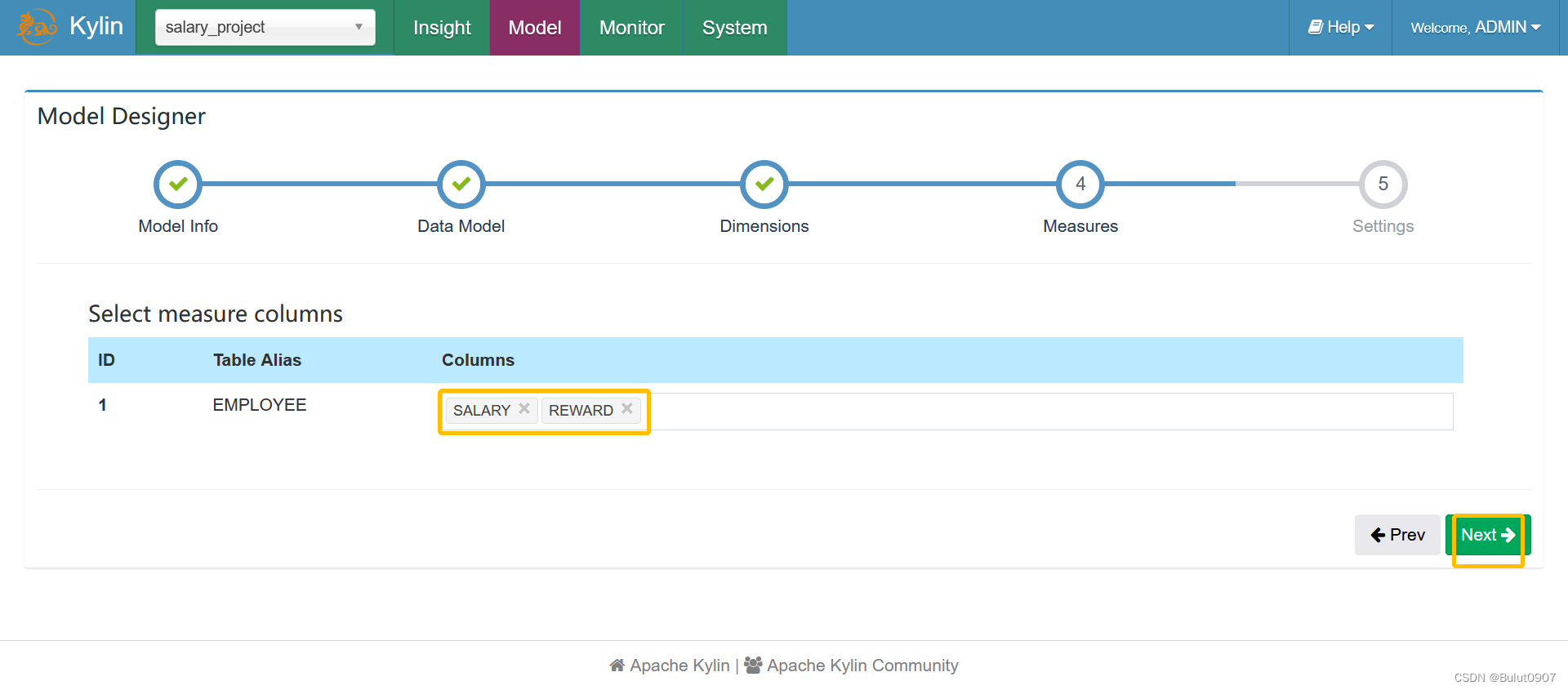
第五步:model的分区和条件过滤设置
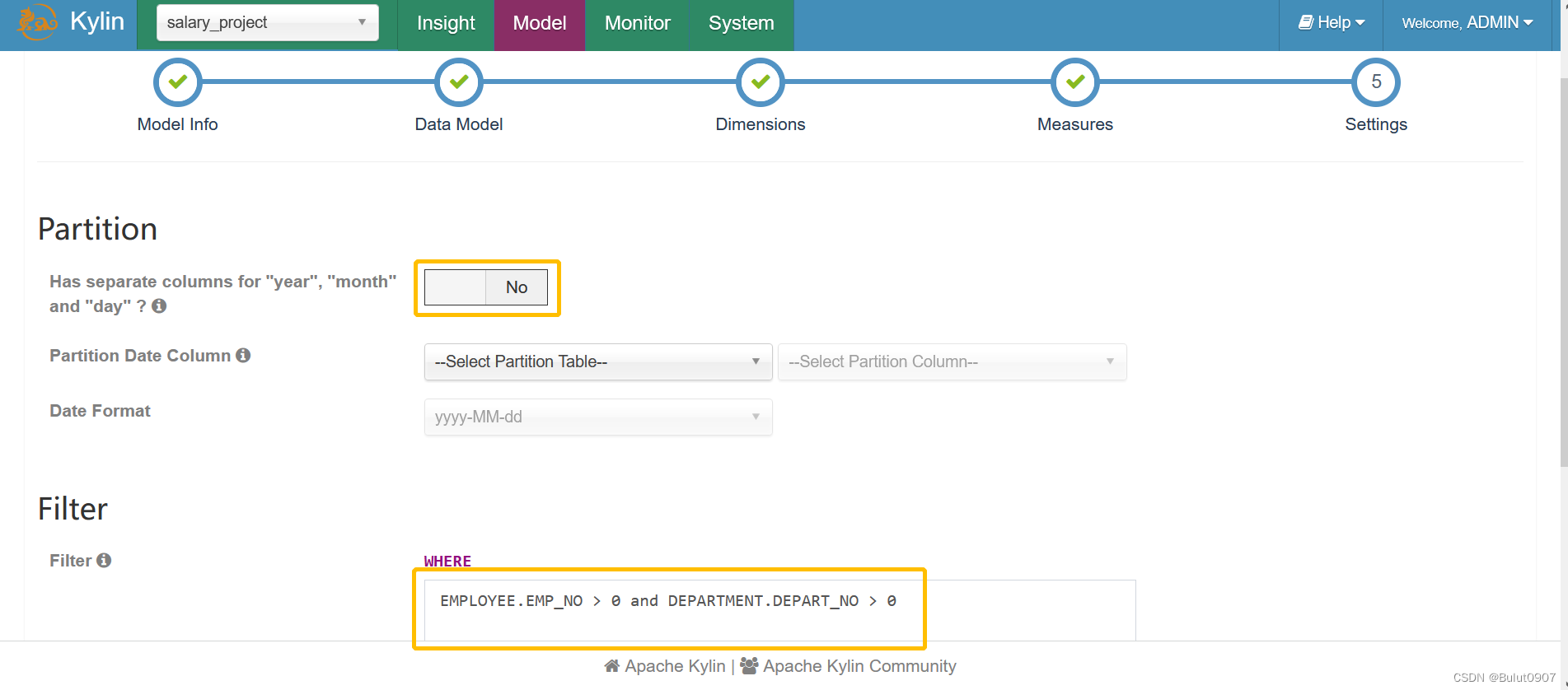
由于我们的Hive测试表不是分区表,所以不用定义事实表的分区字段信息,进行的是全量数据构建。生产环境需要定义实时表的分区字段信息,进行增量数据构建。维度表只能进行全量数据构建
最后点击Save进行保存
5. 定义Cube
新建cube
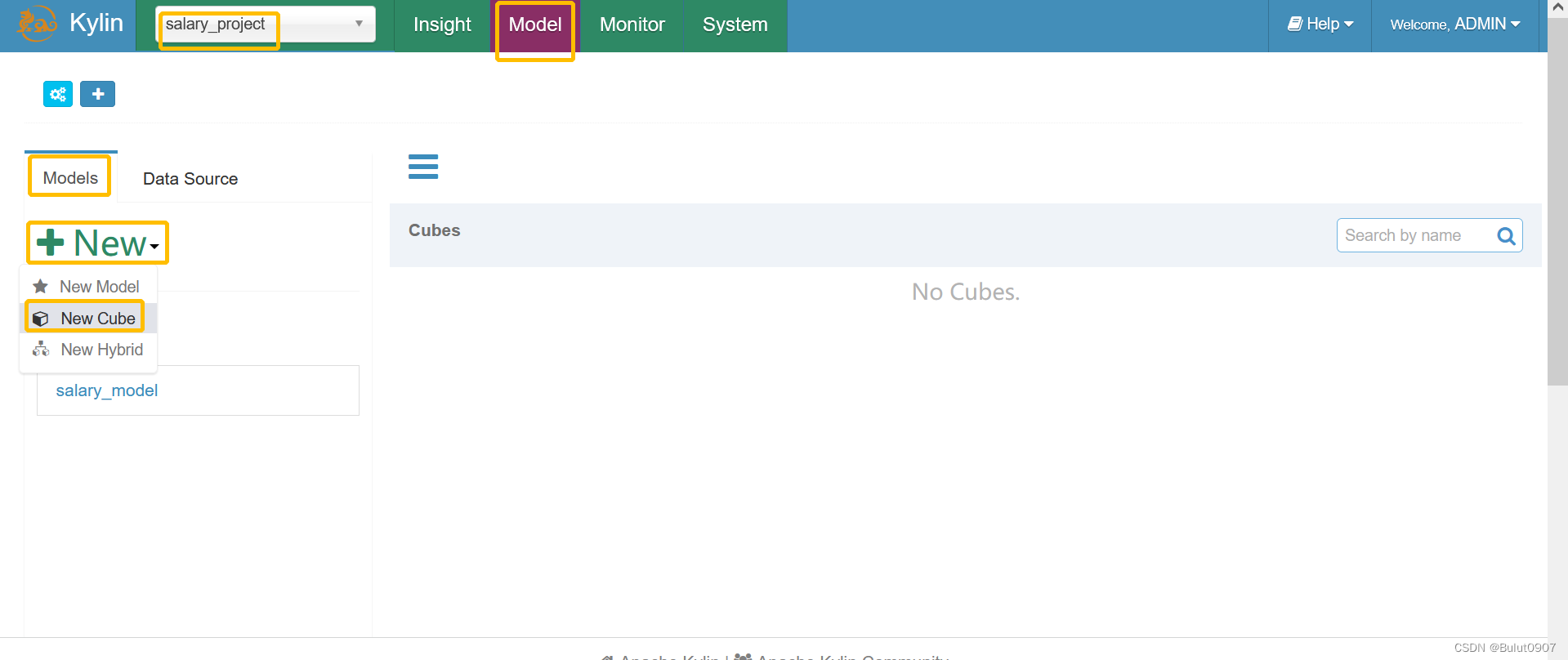
第一步:定义cube信息
 由于我们部署Kylin的时候,没有配置Email报警,所以这里不用进行设置
由于我们部署Kylin的时候,没有配置Email报警,所以这里不用进行设置
第二步:选择cube计算的维度
点击Add Dimensions,然后选择cube计算的维度,再点击OK,再点击Next进入下一步
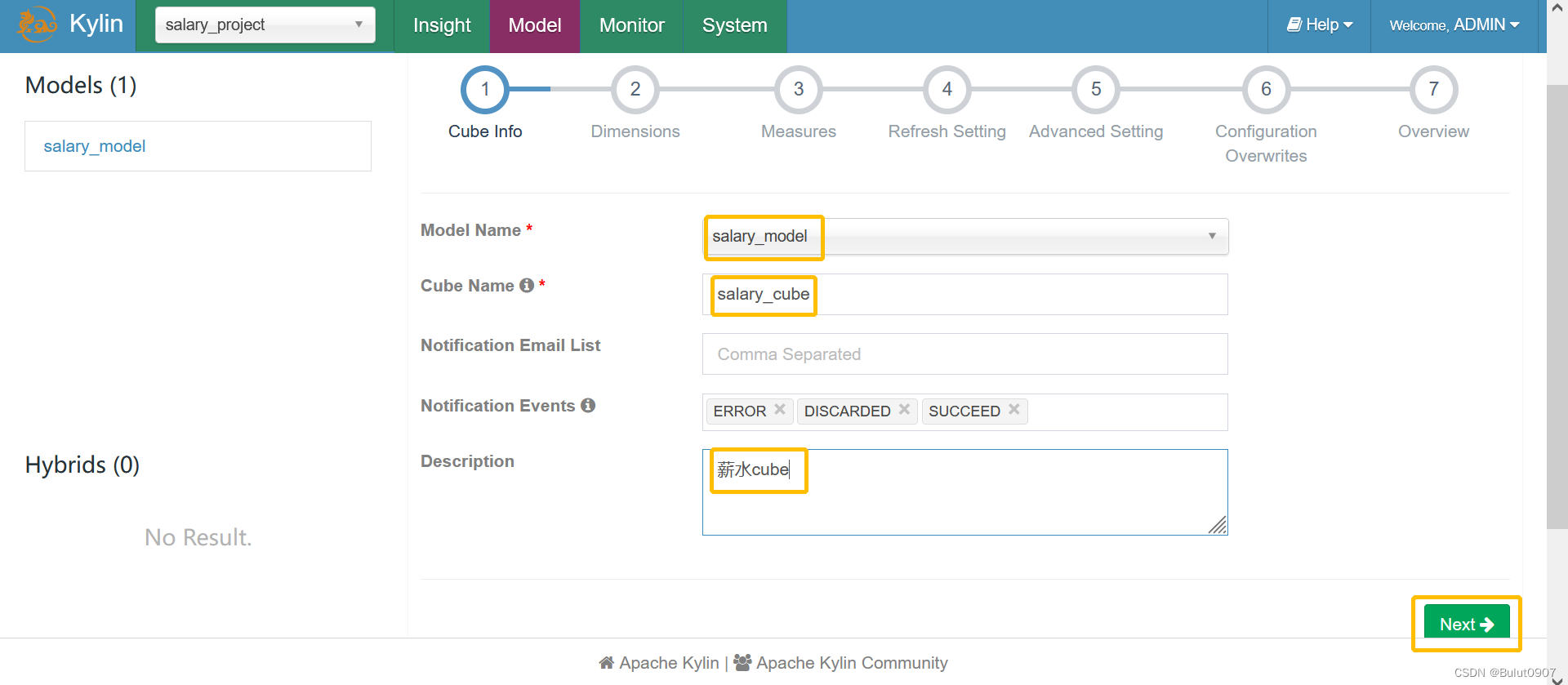
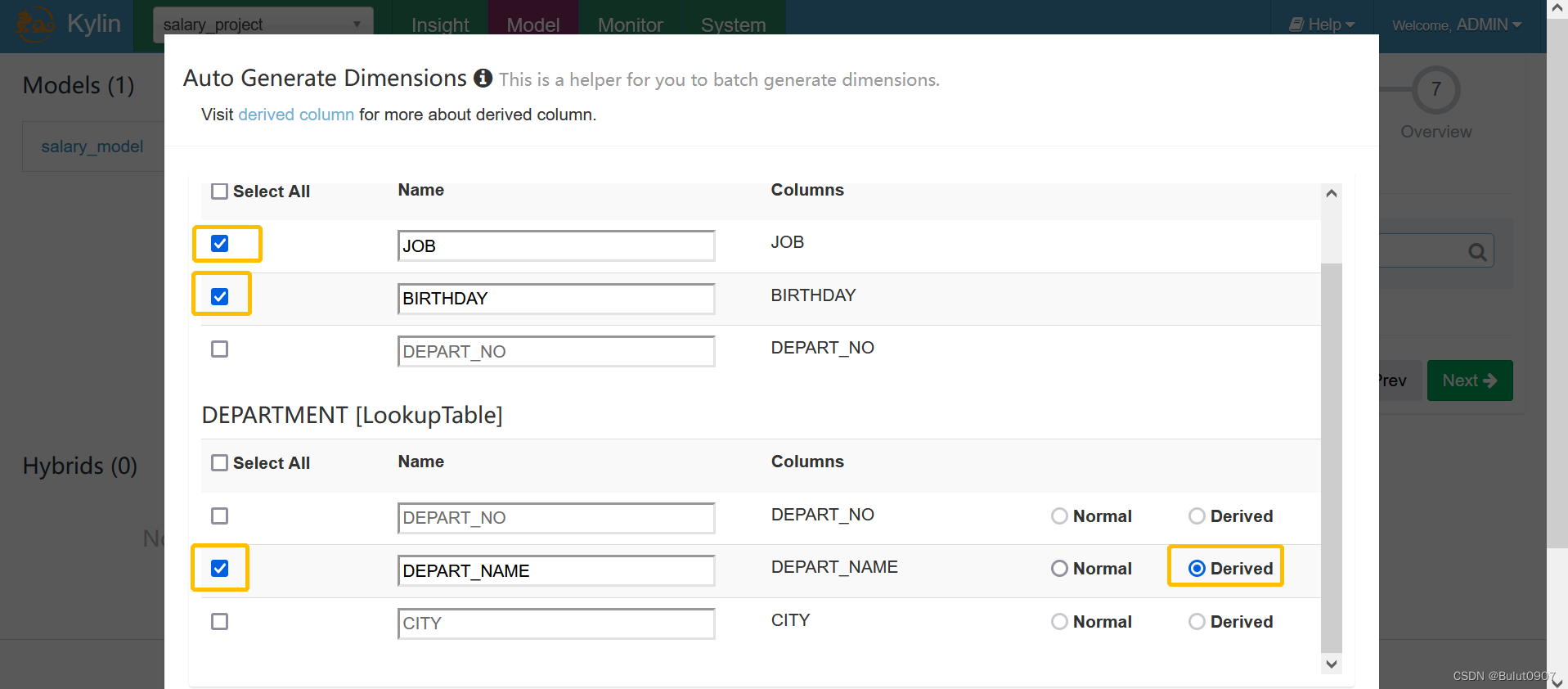 从model中定义的维度中进行选择,这里选择的维度个数会影响cuboid的个数
从model中定义的维度中进行选择,这里选择的维度个数会影响cuboid的个数
这里DEPART_NAME字段定义的维度类型为衍生维度
衍生维度的作用说明:假如我们在维度表选择了DEPART_NAME、CITY这两个维度,维度类型为正常维度,就会产生2的N次方 - 1,共3个维度。但是如果是衍生维度,这两个字段都可以通过DEPART_NO推导出来,则共有1个维度,减少了cuboid的个数
第三步:定义cube的度量计算字段
点击 + Measure,然后定义cube的度量计算字段,再点击OK,再点击Next进入下一步
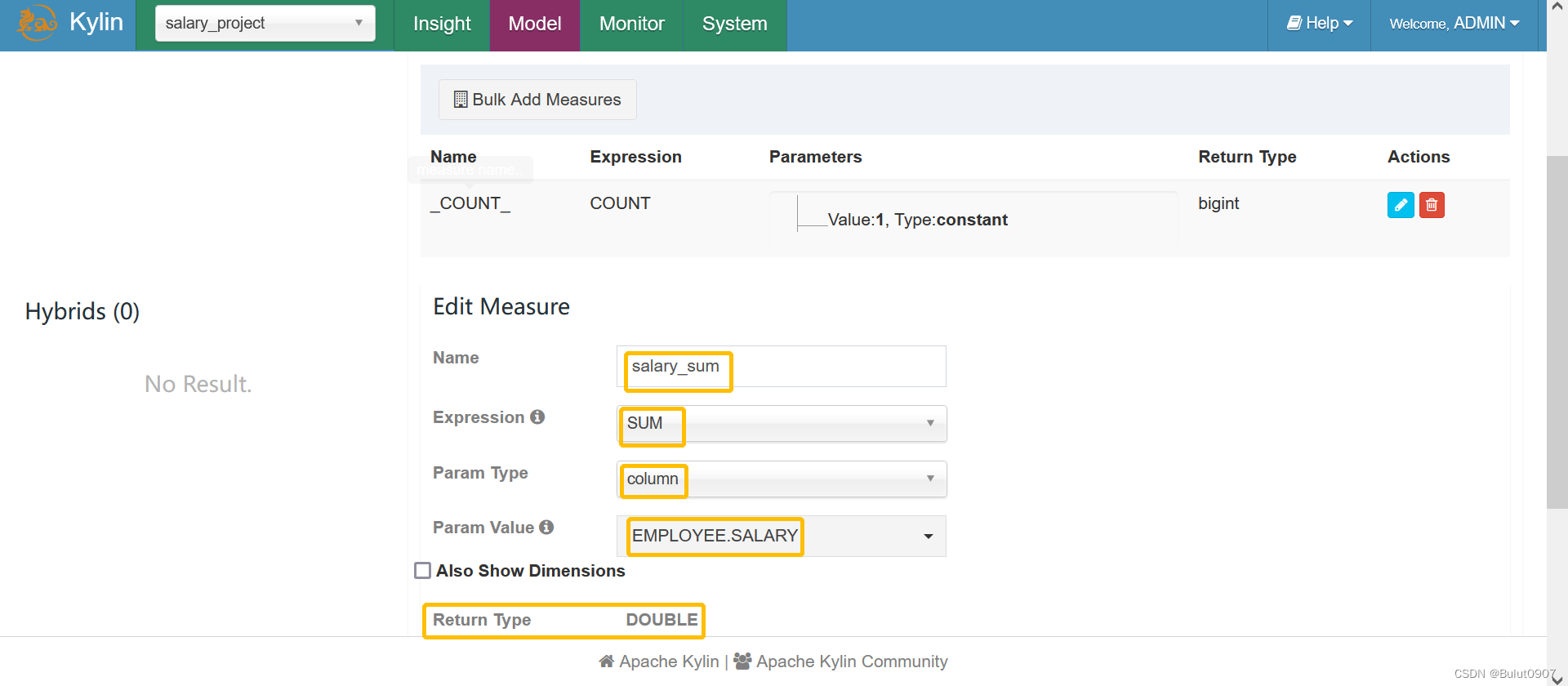 从model中定义的度量字段中进行选择
从model中定义的度量字段中进行选择
第四步:动态更新设置,这里保持默认就好了,点击Next进入下一步
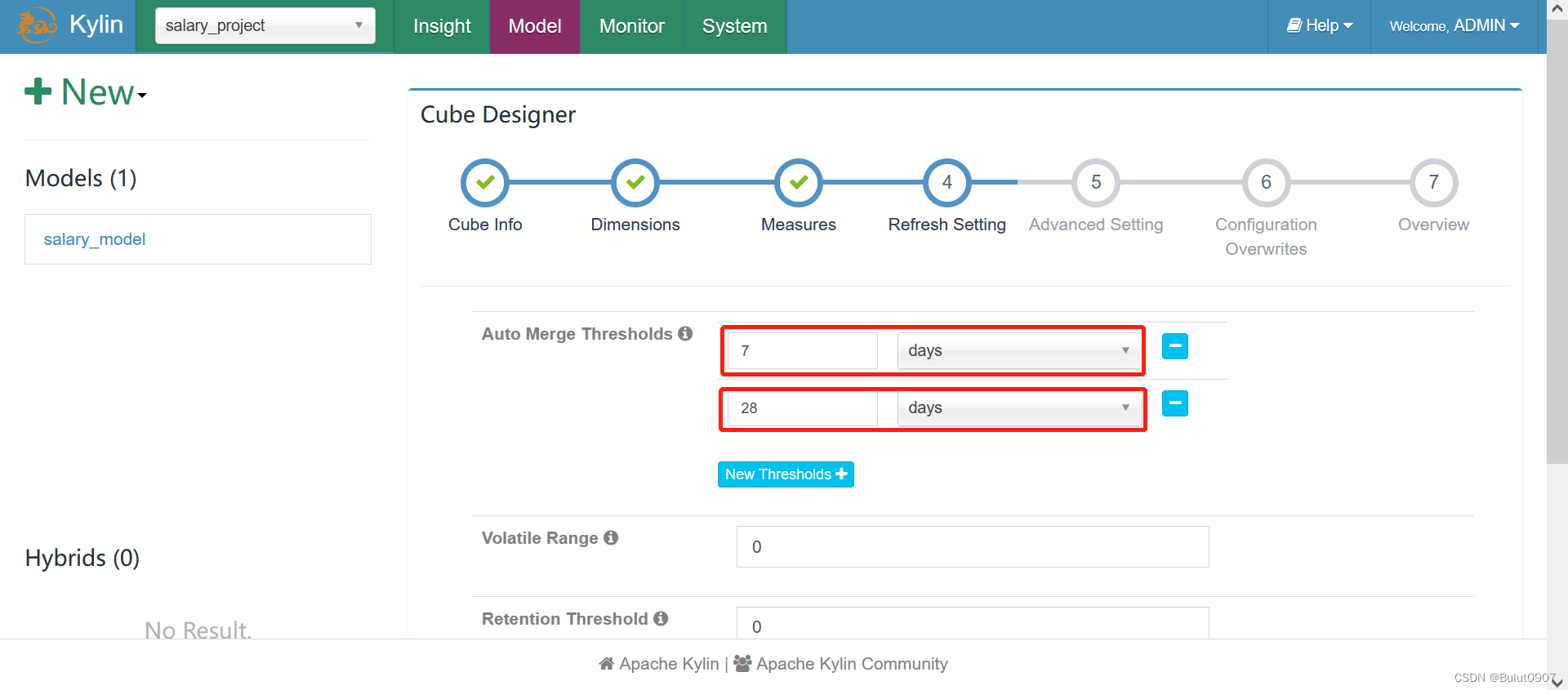 这里的自动合并设置,值为7天和28天。含义是:我们每天对cube进行增量构建,每天的segment都会产生一个parquet文件,每过7天合并最近7天的parquet文件成一个小文件,每过28天合并最近的3个小文件和最近7天的parquet文件,合并成一个大文件
这里的自动合并设置,值为7天和28天。含义是:我们每天对cube进行增量构建,每天的segment都会产生一个parquet文件,每过7天合并最近7天的parquet文件成一个小文件,每过28天合并最近的3个小文件和最近7天的parquet文件,合并成一个大文件
第五步:高级设置,这里保持默认就好了,点击Next进入下一步
 Cube的构建Engine默认就是Spark
Cube的构建Engine默认就是Spark
第六步:配置覆盖,这里保持默认就好了,点击Next进入下一步
最后点击Save保存就可以了
cube详细信息查看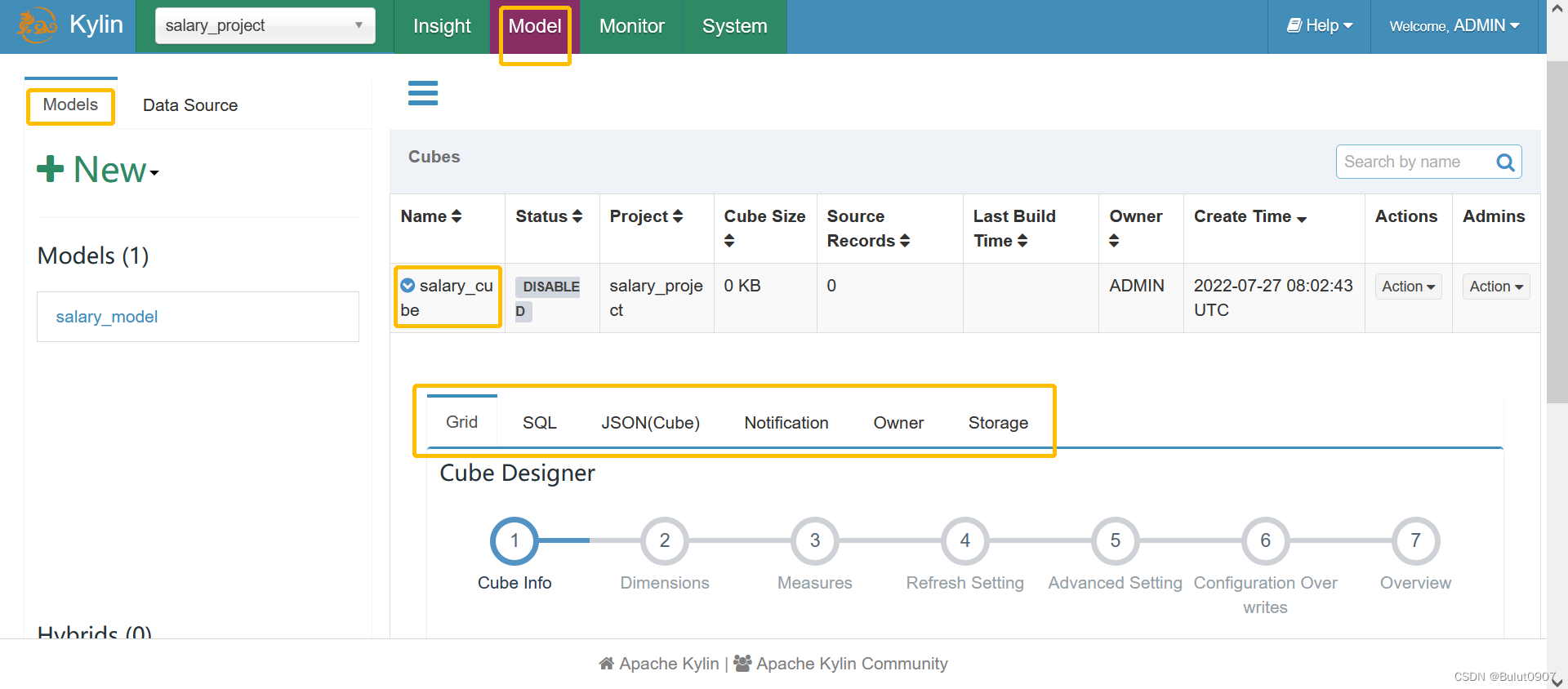 可以看到如下信息:
可以看到如下信息:
- Grid:cube定义时,各步骤的信息
- SQL:查看cube构建时运行的SQL
- JSON(Cube):生成的json格式的cube元数据信息
- Owner:cube所属的kylin用户
- Storage:构建完成后的cube,所占的磁盘信息
6. 构建cube
构建cube
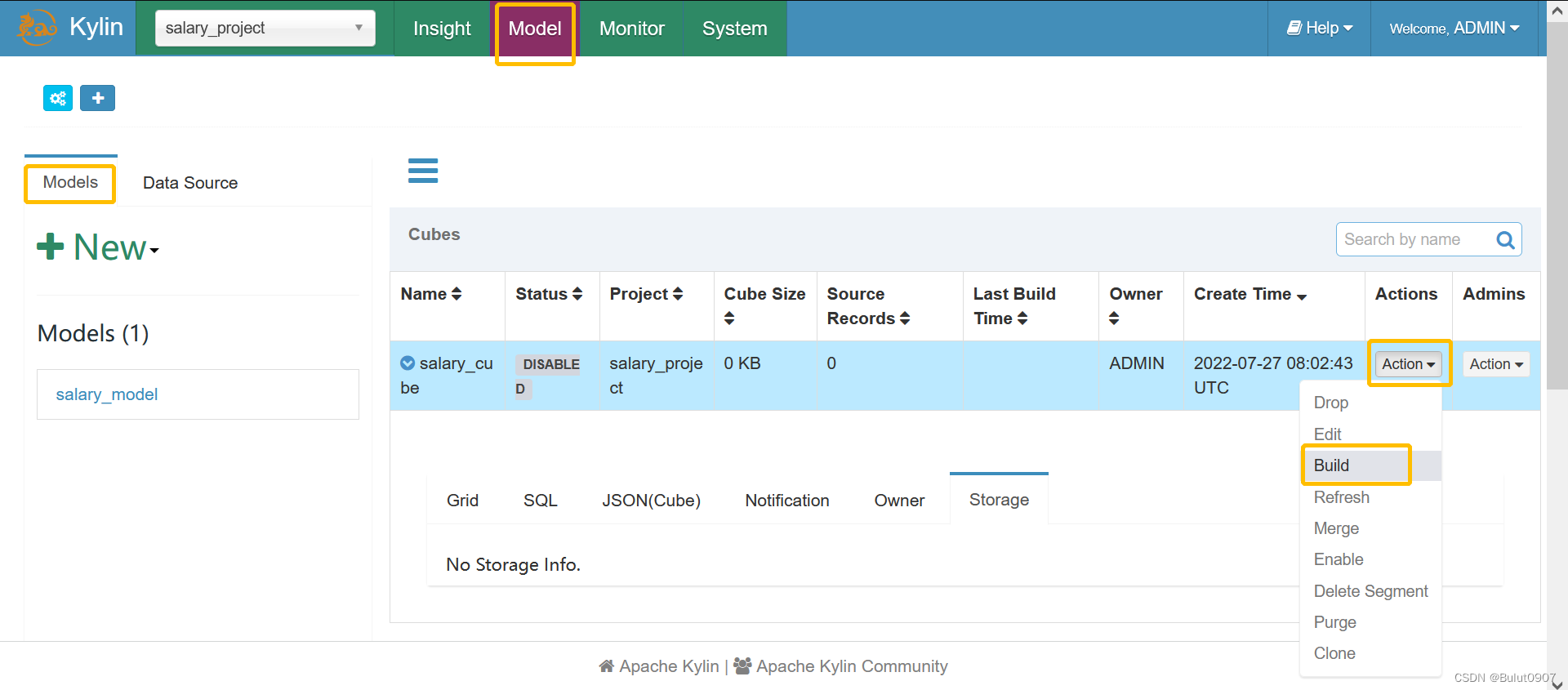 查看构建状态
查看构建状态
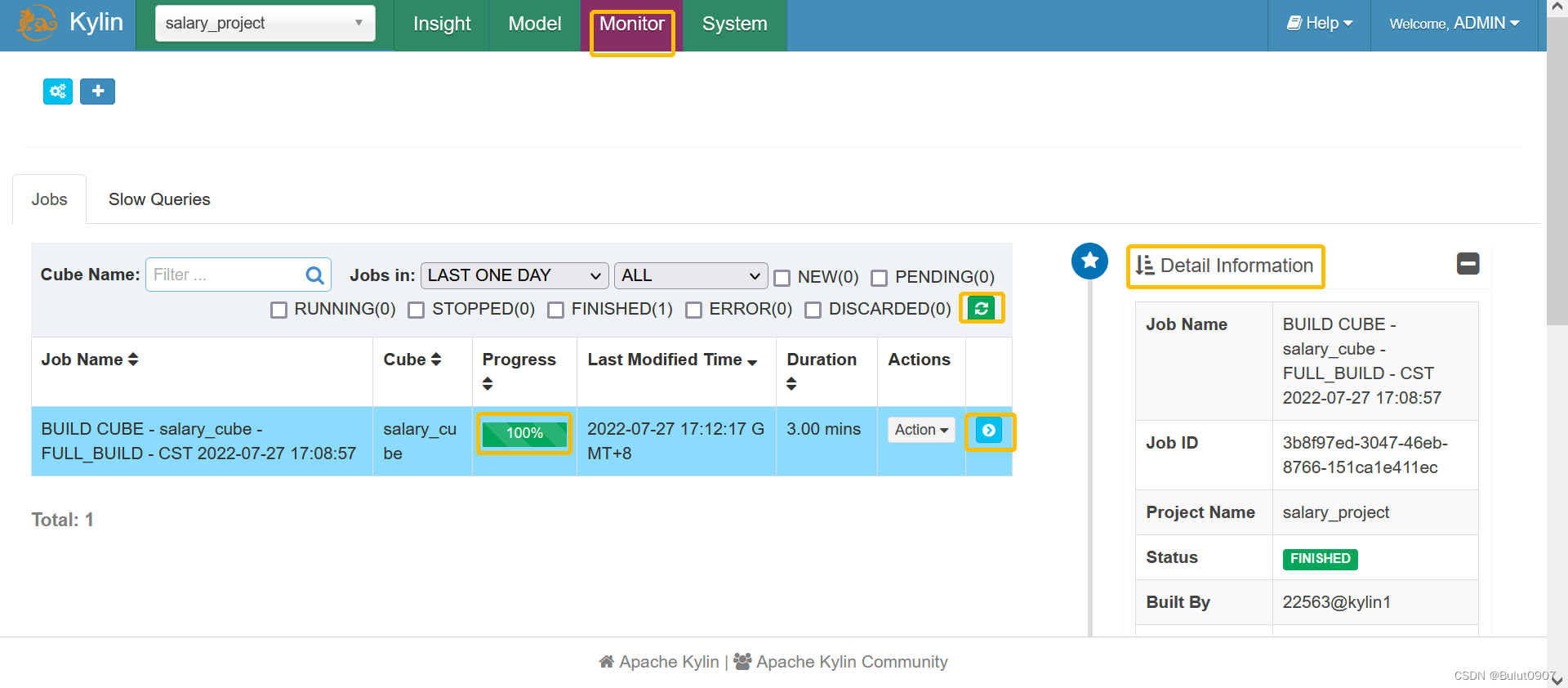
点击小箭头图表,查看构建的详细信息,构建过程总共分两步,可以查看每步的构建日志,第二步还可以跳转到spark application的页面
查看spark的页面,提交application运行完成

7. 查询cube构建后的结果
输入SQL,查询cube构建后的结果:
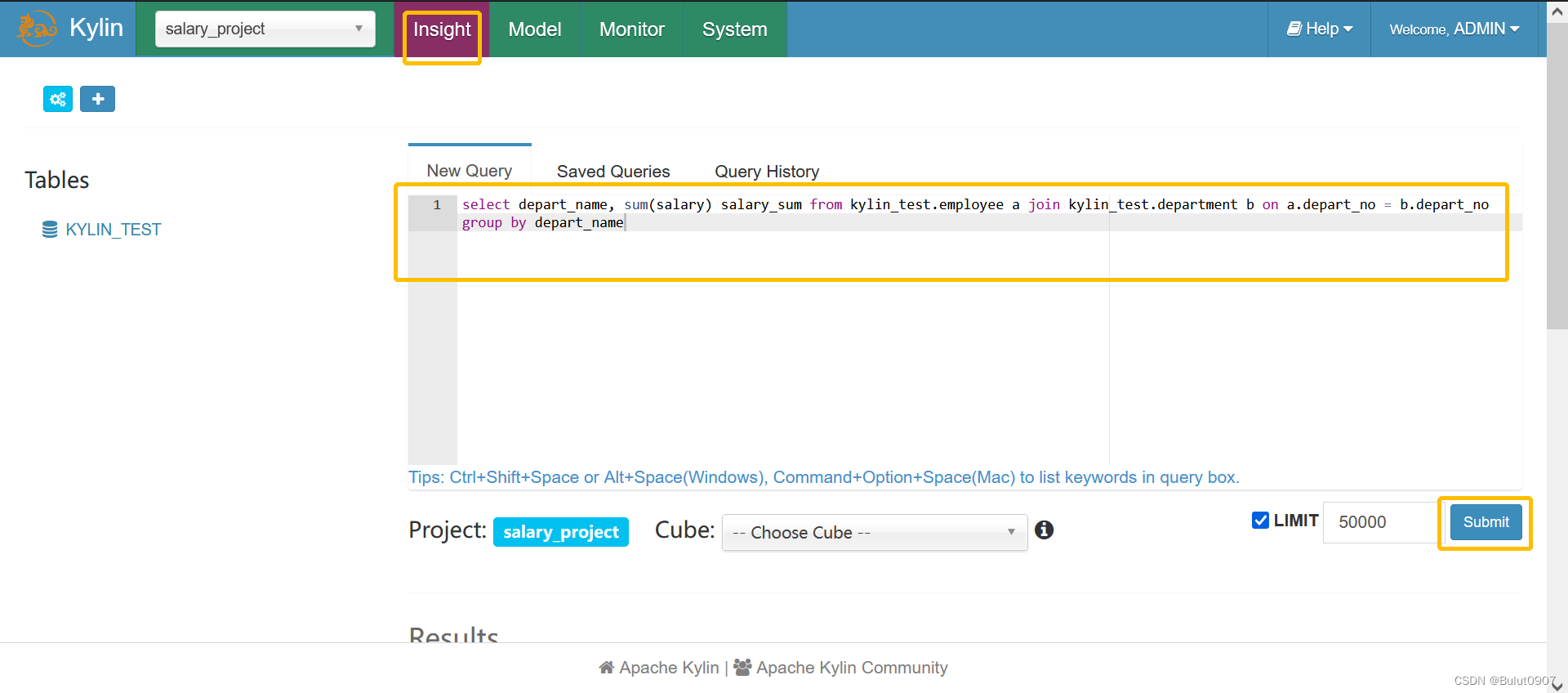 点击Submit之后,会在Spark启动一个一直运行的Spark(Sparder)任务,用于对后续所有的查询提供服务
点击Submit之后,会在Spark启动一个一直运行的Spark(Sparder)任务,用于对后续所有的查询提供服务

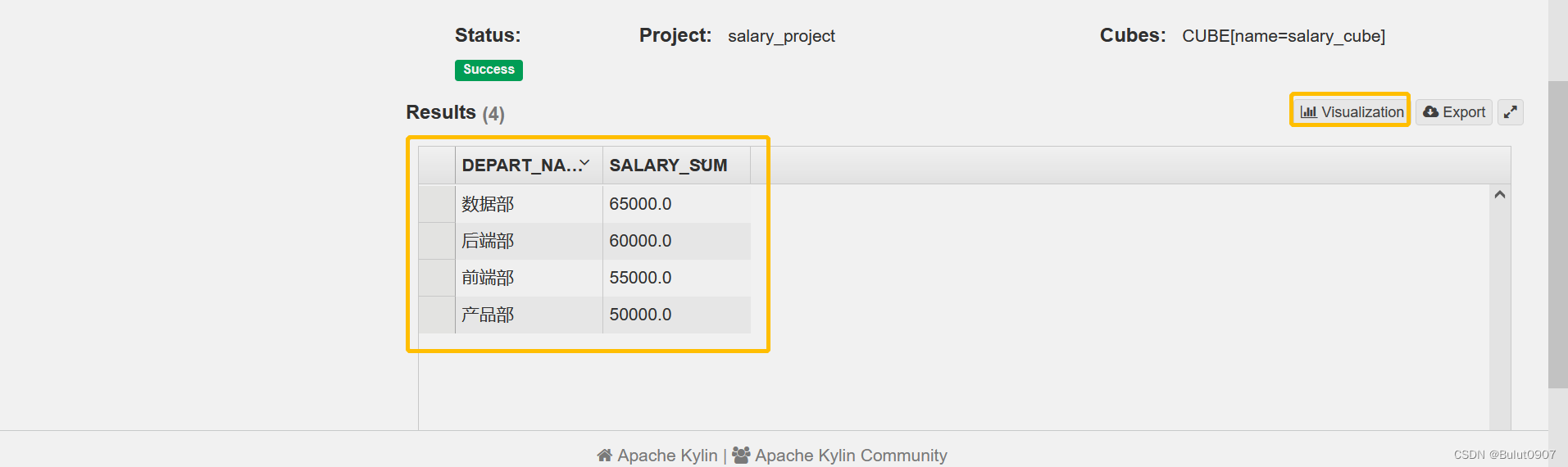
查询的结果如下:
8. 查询限制
我们这里没有做查询下压,所以查询有很多限制,如下所示:
- model构建时,两表关联是inner join,查询的时候只能是inner join,其它类型的join(如left join)会报错
- 查询时表做join关联,必须事实表在前,维度表在后
- group by的维度字段,只能是cube定义时选择的字段,和join关联字段,其它字段会报错
- 聚合计算的值,只能选择cube定义的度量值。比如cube定义了count(1)、sum(salary),则只能计算count、sum(salary)、avg(salary),不能计算max(salary)、sum(reward)等