原文出处
[2111.09734] ClipCap: CLIP Prefix for Image Captioning (arxiv.org)
原文笔记
What
ClipCap: CLIP Prefix for Image Captioning
一言以蔽之:使用 CLIP 编码作为标题的前缀,使用简单的映射网络,然后微调语言模型以生成图像标题。
优点:
- 无需额外的注释或预训练
- 即使只训练映射网络,而 CLIP 和语言模型都保持冻结,我们的方法也能很好地工作。从而允许具有更少可训练参数的轻量级架构。
- 训练快速
本文的主要贡献如下
- 一种轻量级的字幕方法,它利用预训练的冻结模型进行视觉和文本处理。
- 即使语言模型进行了微调,我们的方法也更简单、更快进行训练,同时在具有挑战性的数据集上展示了与最先进的模型的相当的结果。
Why
1、传统的图像描述的两阶段模型需要大量的资源来 弥合视觉和文本表示之间具有挑战性的差距。
(我们在训练期间的主要挑战是在 CLIP 和语言模型的表示之间进行翻译。尽管这两个模型都开发了一个丰富多样的文本表示,但它们的潜在空间是独立的,因为它们没有联合训练。)
2、轻量型描述模型更受青睐(训练时间的问题)
3、以往的图像描述模型应用到不同数据集需要再微调
(每个Caption数据集都包含不同的风格,如果训练集和测试集合来源于不同的数据集,这对于预训练的语言模型来说生成的Caption可能是不自然的。)
Challenge
在图像任务中主要存在两个挑战:
1、semantic understanding语义理解(就是生成特征阶段)
2、how to describe a single image描述图片(就是用特征生成描述阶段)
3、如何在1、2中做好衔接,并保证模型的轻量化与泛化性
Idea
1、作者利用强大的视觉语言预训练模型来简化字幕过程——利用CLIP(它的视觉和文本表示密切相关解决了why的1)这种相关性节省了训练时间和数据要求。(选CLIP是因为它包含的语义信息足够多,所以用它来作为Encoder部分,解决了why的3)
2、至于解码器:传统的基于Transformer的预训练范式需要大量时间来预训练由于我们的视觉信息驻留在前缀中,我们使用了强大的自回归语言模型GPT-2[30]。考虑到训练损失项,早期的工作采用有效交叉熵,而当代的方法也采用自临界序列训练[15,32,45]。也就是说,需要一个额外的训练阶段来优化CIDEr指标。我们故意避免这种优化,以保留一个快速的培训过程。
Model

一些总结
mapper/mapper输出的带prefix的序列 就是做一个CLIP和GPT2的桥梁,如果是训练时不冻结decoder则decoeder和mapper都适应clip,效果自然好,这会儿用mlp或者tansformer结构的mapper都可以,但是作者又通过实验证明:我们得出结论,当采用语言模型的微调时,转换器体系结构的表达能力是不必要的。;如果decoder冻结,mapper就完全当一个转接器做一个承上启下的作用,这时候就更建议用能力更强的Transformer结构的mapper
从模型的角度来看要看方法上是否创新,效果怎么样,模型时空规模怎么样(测试效率怎么样,训练效率怎么样,内存占用怎么样),泛化性怎么样,衍生性怎么样
mapper解决Clip和GPT2 潜在语义空间的gap,训练数据集不同的gap,训练策略不同的gap(对比学习,监督学习)
总体而言,我们基于 CLIP 的图像字幕方法易于使用,不需要任何额外的注释,并且训练速度更快。尽管我们提出了一个更简单的模型,但随着数据集变得更加丰富和更多样化,它展示了更多优点。我们将我们的方法视为新的图像字幕范式的一部分,专注于利用现有模型,同时只训练最小映射网络。这种方法本质上学会了将预训练模型的现有语义理解适应目标数据集的风格,而不是学习新的语义实体。我们相信,在不久的将来利用这些强大的预训练模型将获得牵引力。因此,了解如何利用这些组件是非常有意义的。在未来的工作中,我们计划通过利用映射网络将预训练模型(例如 CLIP)合并到其他具有挑战性的任务中,例如视觉问答或图像到 3D 翻译。
原文翻译
Abstract
图像字幕是视觉语言理解的一项基本任务,其中模型预测到给定输入图像的文本信息字幕。在本文中,我们提出了一种简单的方法来解决此任务。我们使用 CLIP 编码作为标题的前缀,使用简单的映射网络,然后微调语言模型以生成图像标题。最近提出的 CLIP 模型包含丰富的语义特征,这些特征使用文本上下文进行训练,使其最适合视觉语言感知。我们的关键思想是,将Clip与预训练的语言模型 (GPT2) 结合在一起,使我们对视觉和文本数据都有了广泛的理解。因此,我们的方法只需要相当快速的训练并产成有能力的字幕模型。无需额外的注释或预训练,它有效地为大规模和多样化的数据集生成有意义的标题。令人惊讶的是,即使只训练映射网络,而 CLIP 和语言模型都保持冻结,我们的方法也能很好地工作。从而允许具有更少可训练参数的轻量级架构。通过定量评估,我们证明了我们的模型在具有挑战性的概念字幕和nocaps数据集上取得了与最先进方法相当的结果,同时更简单、更快、更轻。我们的代码可在 https://github 获得。com/rmokady/CLIP_prefix_caption。
1. Introduction
在图像字幕中,任务是给输入图像提供有意义且有效的自然语言的描述。这项任务带来了两个主要挑战。第一个是语义理解。这方面的范围从简单的任务,例如检测主对象,到更多涉及的任务,例如理解图像描述部分之间的关系。例如,在图 1 的左上角图像中,模型理解对象是礼物。第二个挑战是描述单个图像的大量可能方法。在这方面,训练数据集通常指示给定图像的首选选项。

已经提出了许多用于图像字幕的方法[4,9,13,19,34,35,42,44,47]。通常,这些作品利用编码器的视觉线索和文本解码器来产生最终的标题。从本质上讲,这导致需要弥合视觉和文本表示之间具有挑战性的差距。由于这个原因,这些模型需要大量的资源。它们需要大量的训练时间、大量的可训练参数、大量的数据集,在某些情况下甚至需要额外的注释(如检测结果),这限制了它们的实际适用性。(两阶段的问题)
过多的训练时间对于需要多个培训步骤的应用程序来说甚至更有限制。例如,在不同的数据集上训练多个字幕模型会给不同的用户(或应用程序)提供相同图像的不同字幕(过多的训练时间会造成更大的限制)。此外,给定新的样本,需要用新数据定期更新模型。因此,轻量级字幕模型更可取。具体来说,具有更快的训练时间和更少的可训练参数的模型将是有益的,特别是如果它不需要额外的监督的话更好。(轻量级的问题)
在本文中,我们利用强大的视觉语言预训练模型来简化字幕过程。更具体地说,我们使用Radford等人[29]最近引入的CLIP(对比语言-图像预训练)编码器。CLIP 旨在为图像和文本对提供强加共享表示。它使用对比损失在大量图像和文本描述上进行训练。因此,它的视觉和文本表示密切相关。正如我们所展示的,这种相关性节省了训练时间和数据要求。
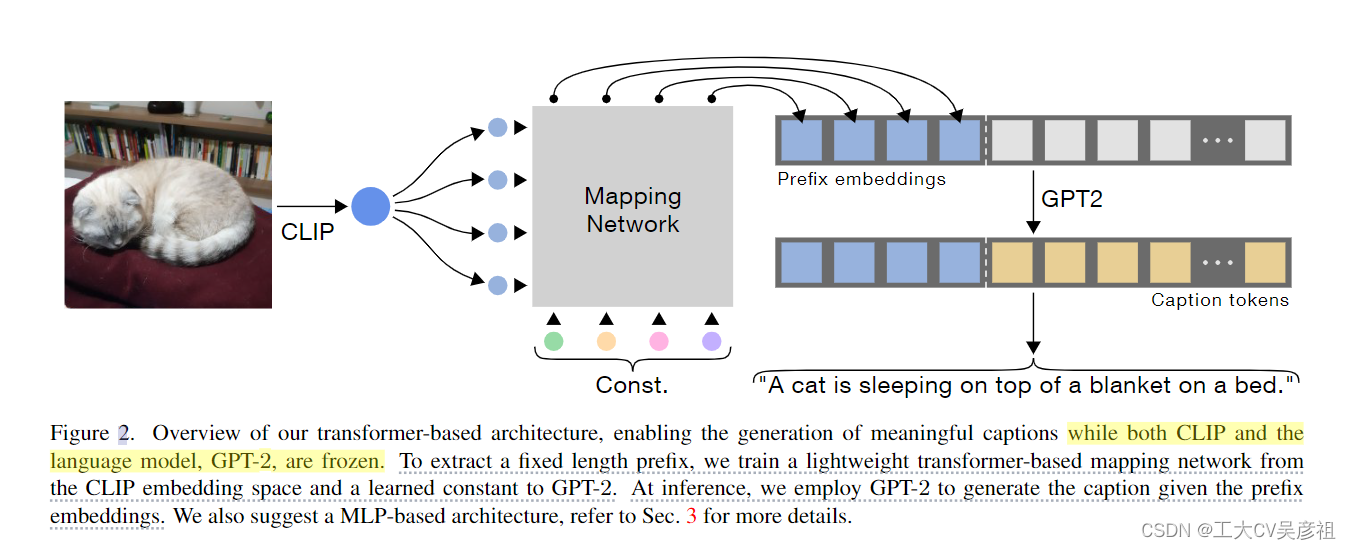
如图 2 所示,我们的方法通过在 CLIP 嵌入上应用映射网络为每个描述生成一个前缀。这个前缀是一个固定大小的嵌入序列,拼接到字幕嵌入前面。这些被馈送到语言模型,该模型与映射网络训练一起进行了微调。在推理时,语言模型逐个单词的生成图片描述,从 CLIP 前缀开始。该方案缩小了视觉和文本世界之间的上述差距,允许使用简单的映射网络。为了实现更轻的模型,我们引入了我们方法的另一个变体,我们只训练映射网络,而 CLIP 和语言模型都保持冻结。通过利用富有表现力的转换器架构,我们成功地生成了有意义的字幕,同时强加的可训练参数要少得多。我们的方法受到Li等人[20]的启发,它展示了通过拼接学习到的前缀来有效地将现有语言模型适应到新任务的能力。我们使用 GPT-2 [30] 作为我们的语言模型,该模型已被证明可以生成丰富多样的文本。
由于我们的方法利用了CLIP的丰富视觉文本表示,我们的模型需要更少的训练时间。例如,我们仅仅在单个 Nvidia GTX1080 GPU 上用大规模概念字幕数据集的 300 万个样本训练我们的模型 80 小时,尽管如此,我们的模型可以很好地推广到复杂场景,如图一所示(例如,在日落的海滩上练习瑜伽)。
我们广泛评估了我们的方法,展示了成功的真实和有意义的字幕。尽管我们的模型需要更少的训练时间,但它仍然在具有挑战性的Conceptual Captions [33] 和 nocaps [1] 数据集上实现了与最先进的方法相当的结果,并且在更受限制的 COCO [7, 22] 基准上略低。此外,我们对所需的前缀长度和微调语言模型的效果进行了彻底的分析,包括对我们生成的前缀的解释。总体而言,我们的主要贡献如下:
- 一种轻量级的字幕方法,它利用预训练的冻结模型进行视觉和文本处理。
- 即使语言模型进行了微调,我们的方法也更简单、更快进行训练,同时在具有挑战性的数据集上展示了与最先进的模型的相当的结果。
2. Related Works
最近,Radford等人[29]提出了一种新的方法,称为CLIP,以联合表示图像和文本描述。CLIP包括两个编码器,一个用于视觉线索,一个用于文本。它在由无监督对比损失指导下利用超过 4 亿个图像-文本对进行训练,从而产生视觉和文本数据共享的丰富语义潜在空间。许多作品已经成功地将CLIP应用于需要理解一些辅助文本的计算机视觉任务,例如基于自然语言条件生成图像或编辑图像 [5, 14, 28]。在本文中,我们利用强大的 CLIP 模型来完成图像字幕的任务。请注意,我们的方法不使用 CLIP 的文本编码器,因为没有输入文本,输出文本由一个语言模型生成。
通常,图像描述[34]模型首先将输入像素编码为特征向量,然后这些特征向量用于生成最终的单词序列。早期的作品利用了从预训练的分类网络中提取的特征[6,9,13,42],而后来的作品[4,19,47]则利用了目标检测网络更具表现力的特征[31]。虽然预训练的目标检测网络可用于流行的COCO基准[7,22],但对于其他数据集并不一定正确。这意味着大多数方法需要额外的对象检测注释来操作新的和不同的数据集。为了进一步利用视觉线索,通常利用注意力机制[4,6,42]来关注特定的视觉特征。此外,最近的模型应用自注意[16,43]或使用表达性视觉Transformer[12]作为编码器[23]。我们的作品使用CLIP的表达嵌入来进行视觉表现。由于CLIP是在非常多的图像上训练的,我们可以在任何一组自然图像上操作,而不需要额外的注释。
为了产生描述本身,使用了文本解码器。早期的作品使用了LSTM变体[8,38,39],而最近的作品[16,26]采用了改进的Transformer架构[36]。在变压器的基础上,最著名的作品之一是BERT[11],展示了新引入的范式的主导地位。使用这种范式,语言模型首先在大型数据集上进行预训练,以解决辅助任务。然后,针对特定的任务对模型进行微调,其中使用了额外的监督。由于我们的视觉信息驻留在前缀中,我们使用了强大的自回归语言模型GPT-2[30]。考虑到训练损失项,早期的工作采用有效交叉熵,而当代的方法也采用自临界序列训练[15,32,45]。也就是说,需要一个额外的训练阶段来优化CIDEr指标。我们故意避免这种优化,以保留一个快速的培训过程。
与我们最接近,是使用视觉和语言预训练来创建视觉和文本的共享潜在空间的工作 [19,25,35,46,47]。Zhou等人[47]使用从对象检测器中提取的视觉token作为caption token的前缀。然后预训练整个模型以使用 BERT [11] 架构进行预测。Li等人[19]和Zhang等人[46]也利用了BERT,但需要对对象标签进行额外的监督。因此,这些方法仅限于此类对象检测器或注释可用的数据集。Wang等人[40]的方法减轻了对补充注释的需求,但仍然进行了广泛的预训练过程,其中包含数百万个图像文本对,导致训练时间很长。这种详尽的预训练步骤需要弥补语言和视觉的联合表示的不足,(因为Clip利用对比学习的范式训练了大规模的图像文本对,内在的包含了很全面很精准的视觉问本潜在空间,所以)我们直接地通过使用 CLIP 获得(完备的语言和视觉的联合表示)。
3. Method
我们从我们的问题陈述开始。给定一个成对的图像和标题 {xi, ci}i=1->N 的数据集,我们的目标是学习为从未见过的输入图像生成有意义的标题。我们可以将图片描述称为一系列tokens ci = ci1,。, ci l,我们将标记填充到最大长度 l。那么我们的训练目标如下:

其中 θ 表示模型的可训练参数。我们的关键思想是使用CLIP的丰富语义嵌入,它几乎包含基本的视觉数据作为条件。继最近的工作 [47] 之后,我们将条件视为标题的前缀。由于所需的语义信息被封装在前缀中,我们可以利用自回归语言模型来预测下一个标记,而不考虑未来的标记。因此,我们的目标可以描述为:

3.1. Overview
我们的方法的说明如图2所示。我们使用GPT-2(large)作为我们的语言模型,并利用其tokenizer将caption投影到一系列嵌入中。为了从图像xi中提取视觉信息,我们使用预训练的CLIP[29]模型的视觉编码器。接下来,我们使用表示为 F 的轻量级映射网络将 CLIP 嵌入映射到 k 个嵌入向量:

其中每个向量 pi j 与词嵌入具有相同的维度。然后,我们将获得的视觉嵌入拼接到标题嵌入ci后边:
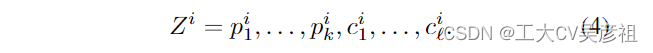
在训练期间,我们将前缀标题连接 {Zi}N i=1 馈送到我们的大语言模型(GPT2-)当中。我们的训练目标是以自回归方式预测以前缀为条件的字幕标记。为此,我们使用简单而有效的交叉熵损失来训练映射组件 F:
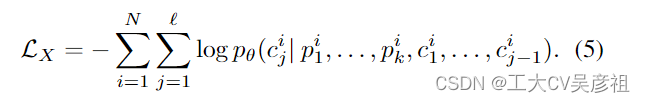
我们现在转向讨论我们方法的两个变体,以了解语言模型的额外微调及其含义。
3.2. Language model fine-tuning
我们在训练期间的主要挑战是在 CLIP 和语言模型的表示之间进行翻译。尽管这两个模型都开发了一个丰富多样的文本表示,但它们的潜在空间是独立的,因为它们没有联合训练。此外,每个Caption数据集都包含不同的风格,这对于预训练的语言模型来说可能不是自然的。因此,我们建议在映射网络训练期间微调语言模型。这为网络提供了额外的灵活性,并产生更具表现力的结果。
然而,微调语言模型自然会显着增加可训练参数的数量。因此,我们提出了一种我们方法的附加变体,其中我们在训练期间保持语言模型固定。我们调整冻结语言模型的尝试受到 Li 和 Liang [20] 工作的启发。在他们的工作中,他们通过仅学习前缀,将这样的预训练模型应用到新的任务中。这种前缀经过自动优化,以在标准训练过程中引导语言模型朝着新目标方向发展。按照这种方法,我们建议避免微调以实现更轻的模型,其中只训练映射网络。如第 4 节所述,我们的模型不仅产生了现实和有意义的字幕,而且在没有微调语言模型的情况下,在一些实验中也取得了优异的结果。请注意,微调 CLIP 不会有利于结果质量,而是会增加训练时间和复杂性。因此,我们假设 CLIP 空间已经封装了所需的信息,并使其适应特定样式会限制模型的灵活性。
3.3. Mapping Network Architecture
我们的关键组件是映射网络,它将 CLIP 嵌入转换为 GPT-2 空间。当语言模型(伴随mapping网络的训练)同时进行微调时,映射就不那么困难了,因为我们很容易控制两个网络。因此,在这种情况下,我们可以使用一个简单的多层感知器 (MLP)。即使仅使用单个隐藏层,我们也实现了现实和有意义的字幕,因为 CLIP 是针对视觉-语言目标进行预训练的。
然而,当语言模型被冻结时,我们建议利用更具表现力的Transformer [36] 架构。Transformer 在减少长序列的参数数量的同时,可以在输入标记之间进行全局注意力。这使我们能够通过增加前缀大小来改进我们的结果,如第 4 节所述。我们向变压器网络提供两个输入,CLIP的视觉编码和可学习的常数输入。该常数具有双重作用,首先,通过多头注意力从 CLIP 嵌入中检索有意义的信息。其次,它通过学习将固定语言模型适应新数据(mapper/mapper输出的带prefix的序列 就是做一个CLIP和GPT2的桥梁,如果是训练时不冻结decoder则decoeder和mapper都适应clip,效果自然好,这会儿用mlp或者tansformer结构的mapper都可以,但是作者又通过实验证明:我们得出结论,当采用语言模型的微调时,转换器体系结构的表达能力是不必要的。;如果decoder冻结,mapper就完全当一个转接器做一个承上启下的作用,这时候就更建议用能力更强的Transformer结构的mapper)。这将在第 1 节中演示。4,其中我们为生成的前缀提供可解释性。可以看出,当语言模型固定时,Transformer映射网络在没有任何文本含义的情况下学习一组细致的嵌入。这些优化使中间特征适应语言模型。
3.4. Inference
在推理过程中,我们使用CLIP编码器和映射网络f提取输入图像x的视觉前缀。我们首先生成以视觉前缀为条件的标题,并在语言模型输出的指导下逐个预测下一个标记。对于每个标记,语言模型输出词汇表中所有词汇token的概率,这些概率用于(通过贪婪方法或波束搜索的方法)确定下一个单词token。
4. Results
实验部分以及prefix的语义解释见下篇
《ClipCap》论文笔记(下)-CSDN博客






![BUUCTF[PWN][fastbin attack]](https://img-blog.csdnimg.cn/img_convert/f4d6c22660d4d1fc1e551769a12ef9de.png)










