本系列目录
《带你自学大语言模型》系列部分目录及计划,完整版目录见:带你自学大语言模型系列 —— 前言
第一部分 走进大语言模型(科普向)
- 第一章 走进大语言模型
-
-
1.1 从图灵机到GPT,人工智能经历了什么?——《带你自学大语言模型》系列
-
第二节 如何让机器理解人类语言?(本篇)
-
第三节 Transformer做对了什么?(next)
-
第四节 大语言模型,大在哪?
-
- … …
第二部分 构建大语言模型(技术向)
- 第二章 基础知识
-
- 2.1 大语言模型的训练过程 —— 《带你自学大语言模型》系列
- 第二节 大模型理论基础:Transformer(next)
- 第三节 大模型硬件基础:AI芯片和集群(next,next)
- 第三章 预训练
-
- … …
本节目录
- 1.2.1 语言模型的理论基石
- 1.2.2 基于语法规则(20世纪50 - 70年代)
- 1.2.3 基于统计的语言模型(20世纪70 - 90年代)
-
- 1.2.3.1 N-gram
- 1.2.4 基于神经网络的语言模型(1990年代中期-至今)
-
- 1.2.4.1 前馈神经网络
- 1.2.4.2 循环神经网络模型(RNN)
- 1.2.4.3 词向量
- 1.2.4.4 注意力机制
- 1.2.4.5 Transformer
【思考】
- 在让机器说人话这件事上,人们都做了哪些尝试?
- 基于神经网络的语言模型,核心的任务有哪几步?
- 人理解语言的方式和计算机理解语言的方式有什么相同和不同?
欢迎关注同名公众号【陌北有棵树】,关注AI最新技术与资讯。

【前言】
语言既是人类的最基础活动,同时又是最复杂的信息游戏。如果一个东西同时具有“最基础”和“最复杂”两种属性,那么这其中必然隐含了许多隐性的、约定俗成的内在知识。比如下面这些“意思”,都代表着不同的意思:
- “你这是什么意思?”
- “没什么意思,意思意思。”
- “你这就不够意思了。”
- “小意思,小意思。”
- “你这人真有意思。”
- “其实也没有别的意思。”
- “那我就不好意思了。”
- “是我不好意思。”
尽管我不说,但你仍然能心领神会都是什么意思,但如果让只认识0和1的计算机去理解这些“意思”,那可真是太有意思了。
但是,NLP的核心目的,就是让计算机去理解这样复杂且抽象的人类语言。
上一节我们回顾了人工智能的发展史,与人工智能所经历的发展曲线类似,自然语言处理也经历了类似的路径,一般称之为从理性主义到经验主义。理性主义基于规则,经验主义基于统计。
关于什么是“理性主义”,我们不妨思考传统编程下的机器语言,这是最极致的“基于规则”,本质上就是一个个逻辑判断,逻辑和规则被固化在代码的一个个if…else和for循环里,计算机做的只是存储数据,指令计算,它不需要有所谓的“智能”,智能在程序员的脑子里,通过代码固化下来。
但到了自然语言这里,最大的难点在于语言的歧义性和动态变化,上面提到的“意思”的例子,还只是歧义的一种,叫语义歧义。在此之前,计算机还要解决结构歧义、省略歧义、指代歧义等等这些在人类看起来根本不是问题的问题。
在传统计算机采用的编码方式下,数字并不代表文字背后隐藏的意义,电脑也不需要理解文字背后的意义,使用电脑的人理解这个意义即可。但是,如果一个系统的所有功能都需要预先编码好而不具有学习的能力,恐怕很难认为它具有智能。而人工智能试图做的,就是代替人类智能的那部分。
本节我们依旧从发展史的角度,来看计算机是一步步“学会”人类的语言的。
【正文】
正如人们对于智能的探索一样,人们对于语言奥秘的探索,也从未停歇。最近读杨立昆的自传《科学之路》,读到美国女作家帕梅拉·麦科多克(Pamela McCorduck)写的一句话,人工智能的历史始于“人类扮演上帝的古老愿望”, 写的极妙,于是人类一直试图创造出带有生命特征的机器。
一直以来,语言被认为是人类拥有智能的标志,同时,用机器做语言翻译又有着极强的需求,尤其是在二战和冷战期间,所以自然语言处理可以说一直是备受关注。
1.2.1 语言模型的理论基石
一般我们说“语言模型”,通常是指基于统计的语言模型。虽然“基于规则”的繁荣期要早于“基于统计”,但从时间顺序来看,基于统计的萌芽可以追溯到上个世纪初。之所以要花很大篇幅讲这段历史,是因为尽管技术日新月异,但其所依据的底层原理仍是基于100年前的发现。这个发现最大的意义在于:证明了通过统计学方法进行自然语言研究的可能性。
这样一件对自然语言处理(NLP)领域如此重大的事件,起源却是一场关于自由意志与宿命论的神学辩论,可以说是无心插柳。
涅克拉索夫是俄国一位具有神学背景的数学家,他在1902年发表的一篇论文中,为了证明自由意志的存在,即人类的恶行和上帝无关,他将大数定律注入神学研究的论证中。他的论点大致如下:自愿行为是自由意志的表达,就像概率论中的独立事件,它们之间没有因果联系。大数定律只适用于这样的独立事件。社会科学家收集的数据,如犯罪统计数据等,符合大数定律。因此,个人的基本行为必须是独立和自愿的。
论文传到俄国另一个大名鼎鼎的数学家马尔科夫手中,马尔可夫在意识形态立场上,可以说是与涅克拉索夫的观点完全对立,但是在他发起攻击时,却几乎不谈派系或宗教,而是直指其中一个数学错误——大数定律需要独立性原则。
尽管自雅各布·伯努利时代以来,这一概念一直是概率论的常识,马尔可夫却开始证明这个假设是不必要的。如果满足某些标准,大数定律同样适用于依赖变量系统。简单来说,就是大数定理不需要独立性假设。
于是他的论证方法就是,找到不符合独立性假设的事件并证明其中大数定理的存在。他选择了普希金的诗歌小说《尤金·奥涅金》,手工统计了元音和辅音的出现规律,发现它们的出现频率最终收敛到固定值,即大数定律。
同时,这本书中的元音和辅音出现的概率分别是是0.28和0.72。首先我们不妨假设元音和辅音的出现都是独立事件,那么根据独立事件的乘法定理,连续出现两次元音的概率应该是0.28×0.28,所以在这本有20多万个字母的书中,应该出现大约16500对两个连续的元音。这本书中的真实情况是两个连续的元音只出现了7388对,所以元音和辅音的出现是独立事件的假设并不成立,但同时他们的统计结果却确实显现了大数定律。
1913 年 1 月 23 日,他在圣彼得堡皇家科学院的演讲中总结了他的发现。基于上面的结论进一步扩展,把元音和辅音各自看作一个状态,而这两个连续字母的四种情况看作是两个状态之间的四种转移方式,每种转移都按照一个特定的概率发生,这就是马尔可夫链,马尔可夫链在当今科学界无处不在,比如语音识别、DNA识别、网络搜索等,但本文我们只讨论其在自然语言处理领域所起到的开创性作用。
马尔可夫的发现揭示了通过统计方法进行自然语言研究的可能性。这成为今天仍活跃的N-gram模型的前身,甚至今天的LLM和ChatGPT本质上也是用前面的词预测后面的词。
虽然这一研究成果极具开创性意义,但由于当时客观条件的限制(甚至还没有计算机)纯粹用纸笔进行统计实在无法激起学者们的兴趣,于是又沉寂了35年。
直到1948年,香农在《通信的数学原理》中,对马尔可夫过程进行了进一步的详细说明。在这篇论文中,香农详细地描述了自然语言中存在的马尔可夫随机过程。香农指出:语言的统计特性可以被建模,同时,还可以根据这个概率模型有效地生成语言。 这篇论文中甚至出现了对N-gram模型的描述。
1.2.2 基于语法规则(20世纪50 - 70年代)
虽然两位如此有影响力的大佬都证明了自然语言的统计特性,可以说是开局极好。但在后面的20年,自然语言处理领域的进展却是乏善可陈。一方面是客观条件的限制,当时计算能力和语料规模都还不足以支撑数理统计的研究,另一方面是则是由于主观上人们惯性思维,当时的语言学家认为,用“简陋”的统计学方法去研究复杂且精密自然语言,多少有点“不够严肃”…
而基于规则的自然语言处理方法,主要思想是通过词汇、形式文法等制定的规则引入语言学知识,从而完成相应的自然语言处理任务。具体的理论与方法,并不是本文的重点,所以不再详细说明。从某种程度上来说,这种方式也是在试图模拟人类完成某个任务时的思维过程。
语言学家们认为,解决语言问题的关键是语法,试图以将所有语法输入给计算机从而让机器学会说人话,但他们似乎忘记了,语言的核心是语义,有限的符号和语法规则,能幻化出无限的语义可能性。试想如果这套方法管用,为什么你学了那么多年的英语语法,结果还是要靠各种翻译软件了。
但是语言学家们不信邪,于是在1950-1970近二十年间,与专家系统类似,语言学家也在用一种近乎愚公移山的方式,试图补全所有语法规则。但是,自然语言的复杂性却似乎超出了他们的想像。将庄子那句“吾生也有涯,而知也无涯。以有涯随无涯,殆已!”放在这里同样十分合适。
自然语言生成的研究几乎处于停滞状态,除了使用模板生成一些简单的语句,并没有什么太有效的解决办法。
1966年,美国科学院发表了报告《语言与机器》,全面否定机器翻译的可行性,并提出停止对机器翻译项目的资金支持的建议。但是由于机器翻译的需求场景真的很大,又没有可替代的技术,直至80年代之前,NLP的主要实现方式还是基于规则。
后来1988年,美国工程院院士贾里尼克在自然语言处理评测讨论会上的发言中说过这样的话:“ 我每开除一个语言学家, 语音识别系统的性能就会有所提高 😂😂 ”
1.2.3 基于统计的语言模型(20世纪70 - 90年代)
如上节结尾所述,经历了20多年的挣扎后,人们开始对基于规则方法产生了失望,于是从70年代开始,一部分人开始回到最初的起点,从香农和马尔可夫的理论中去寻找灵感,想起香农在20多年前提出的N-gram。
随着加入统计派的研究者越来越多,研究也越来越深入,基于统计学方法的自然语言处理技术,在这期间确实取得了相当不错的成绩,尽管一定程度上是靠同行衬托得好。
比如在马尔可夫链的基础上,人们进一步提出了隐马尔可夫模型,并将其应用于语音识别这个自然语言处理的子领域。最终人们将语音识别这个一直被认为几乎无法实现的技术,做到了极高的可用性。
尽管如此,仅仅通过简单的统计学方法,依旧难以应付大千世界语义的复杂。它们的研究也只能限于感知层面,而无法在认知层面上取得进展。
其实这与AI整体遇到的困境类似,虽然有了理论,但是由于网络结构和数据量的限制,早期并没有十分亮眼的突破。始终徘徊于“能做,但做不好”的状态。
1.2.3.1 N-gram
在基于统计的自然语言方法里,一个你会经常听到的概念就是“语言模型”,无论是基于统计的语言模型(N-gram模型)、基于神经网络的语言模型(循环神经网络、Transformer)、基于预训练的语言模型(GPT、BERT)、大语言模型,都没有超出语言模型的范畴。既然如此,它们必然有一个共性存在:根据历史上下文对下一时刻的词进行预测。
也可以说,它们都是在试图把语文问题转化为数学问题。
尽管NLP发展了几十年,技术也演进了好几代,但是其本质原理仍然和最初的N-gram(N-gram Language Model,N元语言模型)一样。那么N-gram具体指的是什么呢?
要回答这个我们,我也要先抛开N-gram,回归到语言模型本身,如果让你做一个基于概率统计的语言模型,你会怎么做?
根据我们的直觉,最简单的语言模型就是把一句话拆成一个个单元,比如一个词序列被拆成了
w
1
w
2
w
3
.
.
.
.
.
.
w
m
w_1w_2w_3......w_m
w1w2w3......wm
我们要想知道
w
m
w_m
wm是什么,就要知道在
w
1
w
2
w
3
.
.
.
.
.
.
w
m
−
1
w_1w_2w_3......w_{m-1}
w1w2w3......wm−1出现的情况下,后面有可能出现什么词,每个词出现的概率是多少,概率最大的那个,就是我们认为最“正确”的
w
m
w_m
wm。
所以语言模型的目标就是构建它的概率分布
P
(
w
1
w
2
w
3
.
.
.
.
.
.
w
m
)
P(w_1w_2w_3......w_m)
P(w1w2w3......wm)
但是,计算联合概率十分困难,所以会通过链式法则对概率的求解过程进行分解。
但是,计算联合概率十分困难,所以会通过链式法则对概率的求解过程进行分解。为了尽量少写公式,我们举个例子,假设全世界只有下面这几句话:“陌小北喜欢喝奶茶”,“陌小北喜欢跑步”,“陌小北爱看书”,“陌小北喜欢古诗词”,“陌小北是程序员”,“陌小北去霸王茶姬点了一杯伯牙绝弦然后回到工位继续写bug”
用链式法则分解下的表现形式为:
P(陌小北喜欢喝奶茶)= P(陌小北)× P(喜欢|陌小北) ×P(喝|陌小北喜欢)×P(奶茶|陌小北喜欢喝)
陌小北后面跟着“爱”“喜欢”“是””去“的概率分别是0.166,0.5,0.166,0.166,“陌小北喜欢”后面跟着“喝”“跑步”“古诗词”的概率分别是0.333,0.333,“陌小北喜欢喝”后面跟着“奶茶”的概率是1,
P(陌小北喜欢喝奶茶)= 0.5 × 0.333 × 1 = 0.1665
这样看着还比较简单,那么看下面这句:
P(陌小北去霸王茶姬点了一杯伯牙绝弦然后回到工位继续写bug)= P(陌小北)× P(去|陌小北)×P(霸王茶姬|陌小北去)× P(点了|陌小北去霸王茶姬)× P(一杯|陌小北去霸王茶姬点了)× ...... × P(bug|陌小北去霸王茶姬点了一杯伯牙绝弦然后回到工位继续写)
中间我还省略了很多…,这还是在假设我们设定了全世界只有这6句话的前提下,可想而知,随着语料集的增大,这个参数量是巨大的。《现代汉语词典(第7版)》有7万个词条,假设平均每句话20个词,模型的参数量将达到,跟这个量级一比,现在的万亿参数都显得如此娇小可爱,恐怕在量子计算机实现之前,我们是实现不了让机器理解语言这个梦想了。
并且还有一个问题,随着句子变长,后面的句子出现的次数会越来越少,概率也极有可能为0,此时再去计算概率也没有意义了
所以我们需要简化,简化的思路是,没有必要统计整句,一个词出现的概率只与它前面的几个词有关系,这就是N-gram的基本假设:“下一个词出现的概率只依赖于它前面n−1个词”,这被称为马尔可夫假设(Markov Assumption)。
具体和前面几个词有关系,这个N就是几。当n=1时,不依赖前面的任何词,就是unigram,n=2时,只依赖前面一个词,就是bigram,n=3时,是trigram。n的取值越大,考虑的历史信息越完整,结果越精确,同时计算量也越大。
根据上面的定义,我们把这个长句改为bigram:
P(陌小北去霸王茶姬点了一杯伯牙绝弦然后回到工位继续写bug)= P(陌小北)× P(去|陌小北)×P(霸王茶姬|去)× P(点了|霸王茶姬)× P(一杯|点了)× ...... × P(bug|写)
通过上面的例子不难看出,训练N-Gram模型的过程其实是统计频率的过程。它并没有用到深度学习和神经网络,只是一些统计出来的概率值。这种方式是不是看起来很简单,其实早期的NLP就是采用的都是这种模式,只是在技术细节上会有优化,知道了真相后,你是不是知道为什么早期很多对话机器人那么智障了…
另一个问题就是“陌小北喜欢喝奶茶”和“陌小北爱喝奶茶”两句话,其实是一个意思,但后者的概率就是0,这显然是不合理的。
从语言模型的角度来看,N元语言模型存在明显的缺点。首先,模型容易受到数据稀疏的影响,一般需要对模型进行平滑处理;其次,无法对长度超过N的上下文依赖关系进行建模。
这时,NLP需要另一个骑士来拯救…
1.2.4 基于神经网络的语言模型(1990年代中期-至今)
神经网络的发展同NLP一样,一路也是历经坎坷,直到本世纪初才逐渐回暖,1.1节已经讲过不再赘述。
相比于传统的N-gram的概率统计计算,神经网络通过拟合一个概率函数代替了通过统计频率对概率值的估算过程。它通过多层的特征转换,可以将原始数据转换为更抽象的表示,所以这个简单的结构理论上可包万物。所以在其发展到一定阶段后,自然会向这颗“人工智能皇冠上的明珠”发起探索。
随后的事实也一步步证明,利用神经网络的语言模型展现出了比N-gram更强的学习能力。
接下来以时间顺序介绍这一阶段的标志事件,如果你之前没有相关基础,在本节你只需要记住几个关键概念:词向量、RNN、Transformer。
正如《技术的本质》这本书里关于“技术循环”的描述那样:为解决老问题去采用新技术,新技术又引起新问题,新问题的解决又要诉诸更新的技术。周而复始…
基于神经网络的模型基本遵循如下的方式:首先设定一个目标,通过大量数据反复训练,直到让其拟合出目标函数,通俗来说,训练过程就是先让机器“蒙”一个答案,然后算出距离正确答案差多远(损失函数),给机器一个反馈,再让它继续蒙,重复多次直到它蒙对。
不同的神经网络模型,其实就是所设计的目标函数不同,我们设计不同目标函数的目的,无非就是努力让模型的表达能力更强,更能发挥硬件优势…
1.2.4.1 前馈神经网络
2003年,约书亚·本吉奥(Yoshua Bengio)团队在论文《A neural probabilistic language model》中提出了“基于神经概率语言学模型”。这是一个浅层前馈神经网络。
前馈神经网络由输入层、词向量层、隐含层和输出层构成。如下图,输入层传入待预测词的前N个词,可以理解为前N个词的语义影响了这个词的输出。
从原理来说,神经网络语言模型沿用了马尔可夫假设,即下一个时刻的词只与过去n-1个词相关,其目标可以表示为输入历史词,输出词𝑤𝑖在词表上的概率分布。前馈神经网络语言模型一个明显的问题是,对下一个词的预测需要回看多长的历史是由超参数N决定的,这个N是固定的。这样处理最大的一个问题是:现实情况下,不同的词语对历史长度N的期望往往是变化的。

1.2.4.2 循环神经网络模型(RNN)
循环神经网络模型(RNN) 正是为了处理这种不定长依赖而设计的一种语言模型。循环神经网络的提出就是为了处理序列数据的,正好满足自然语言这一场景。它在每一时刻都维护一个隐含状态,该状态蕴含了当前词的所有历史信息,且与当前词一起被作为下一时刻的输入。
从2010年,Tomas Mikolov及其合作者发表论文《Recurrent neural network based Ianguage model》提出了基于循环神经网络,自这时起,同时伴随深度学习带来的本轮人工智能热潮,自然语言处理进入了高速发展时期。
简单来说,循环神经网络可以看作一个具有"记忆"的神经网络。RNN的基本原理是通过循环来传递隐藏状态信息,从而实现对序列数据的建模。循环神经网络语言模型不再基于马尔可夫假设,每一时刻的词都会考虑到过去所有时刻的词,词之间的依赖通过隐藏层状态来获取,这刚好解决了语言模型需要动态依赖的问题。

但循环神经网络仍然存在一些问题:
首先,RNN需要顺序执行,也就是在上一个词处理完之前,无法进行下一个词的计算,这限制了机器的并行处理能力,从而导致计算效率缓慢。
其次,在处理长序列时,RNN无法捕捉到长距离之间的依赖关系,这是因为整个原始句被压缩成一个固定维度的隐藏状态向量,如果句子过长,这个固定维度显然无法准确表达每个词的特征。
另外在处理长序列时,训练这样的循环神经网络可能会遇到梯度消失或梯度爆炸的问题,导致无法进行有效的训练。
1.2.4.3 词向量
讲到这里,我们先从语言模型中跳出来,想一想,自然语言处理核心要做哪几件事?概括来讲,是两件事:第一,将文字进行数字化;第二,让数字化后的数值表达出语义关系。
如果用一句话概括神经网络是如何处理语言问题的,那就是:使用词向量,寻找相似度。
在上一部分介绍基于统计的语言模型时,我们忽略了一个非常关键的问题:自然语言在计算机中如何被数字化?
我们知道计算机的底层是二进制,传统的字符编码只考虑了存储与表示,并未考虑文字的实际语义。而人工智能则不然,它需要理解文字承载的”意义“。具体采用的技术就是“向量化”。
通过这种方式,计算机不需要真正理解每个词的实际意义,而是利用相似度来建立了另一种意义:把每个词都表示为向量,然后把它们放到一个多维坐标里面,词和词之间的空间关系,就会把它们语义上的关系表示出来。
语言学家约翰·R .弗斯(John R. Firth, 1957)也有一句名言佐证此假设:“要知道一个单词的含义就要看它周围是什么单词”。这在自然语言处理领域,被称为“分布式假设”。
基于分布式假设,后续发展出两种实现方法:一种是基于计数的方法;另一种是基于推理的方法。 基于计数的方法一次性处理全部学习数据;反之,基于推理的方法使用部分学习数据逐步学习。
基于计数的方法的思想是:根据一个单词周围的单词的出现频数来表示该单词。 这类技术的代表包括采用奇异值分解的隐式语义分析。
基于推理的方法,实现方法是使用神经网络来处理单词。首先将单词用独热编码表示为向量,接下来将这些向量传递给神经网络的各个层,通过全连接层对其进行变换。2013年,谷歌团队提出了Word2Vec的词向量技术。从此,以词向量(Word Embedding)为代表的分布式表示的语言模型深刻地影响了自然语言处理领域的其他模型及其应用的变革。
这种将任意文本(或非文本符号)表示成稠密向量的方法,统称Embedding。Embedding可以说是NLP领域甚至于深度学习领域最基础的技术。哪怕到了2023年,大模型爆发式增长,NeurIPS仍是将时间检验奖颁给了Word2Vec。
从Word2Vec(“词到向量”)这个名字上就可以看出来,他的关注点不是语言模型本身,得到词向量这个副产物成为了主要的目的,所以严格意义来说,它不是一个语言模型。词向量的学习主要利用了语料库中词与词之间的共现信息,其背后的核心思想是就是上面提到的分布式语义假设。在一个文本序列中,每个词的动态词向量实际上是对该词的上下文进行语义组合后的结果。
向量中的空间方向,有承载语义的作用。
我们用一个更直观的例子来说明词向量,来说明为什么它在NLP领域如此重要。首先,我们假设向量空间是二维的,尽管这种简化与实际情况不符(例如GPT-3中的向量维度是12288),但这样更便于我们直接观察。
通过这种向量化的方式,一是完成了文字在计算机内的存储,而是便于寻找”规律“,意义相近的词语的空间位置更近。

将词映射到向量还有一个好处在于,通过词语间的空间关系反映了它们在现实世界的实际关系。比如「男人」和「女人」这两个向量的向量差,可能与「爸爸」和「妈妈」的向量差是相近的。也就是这两组字的语义差,可以在向量空间中转为向量差。
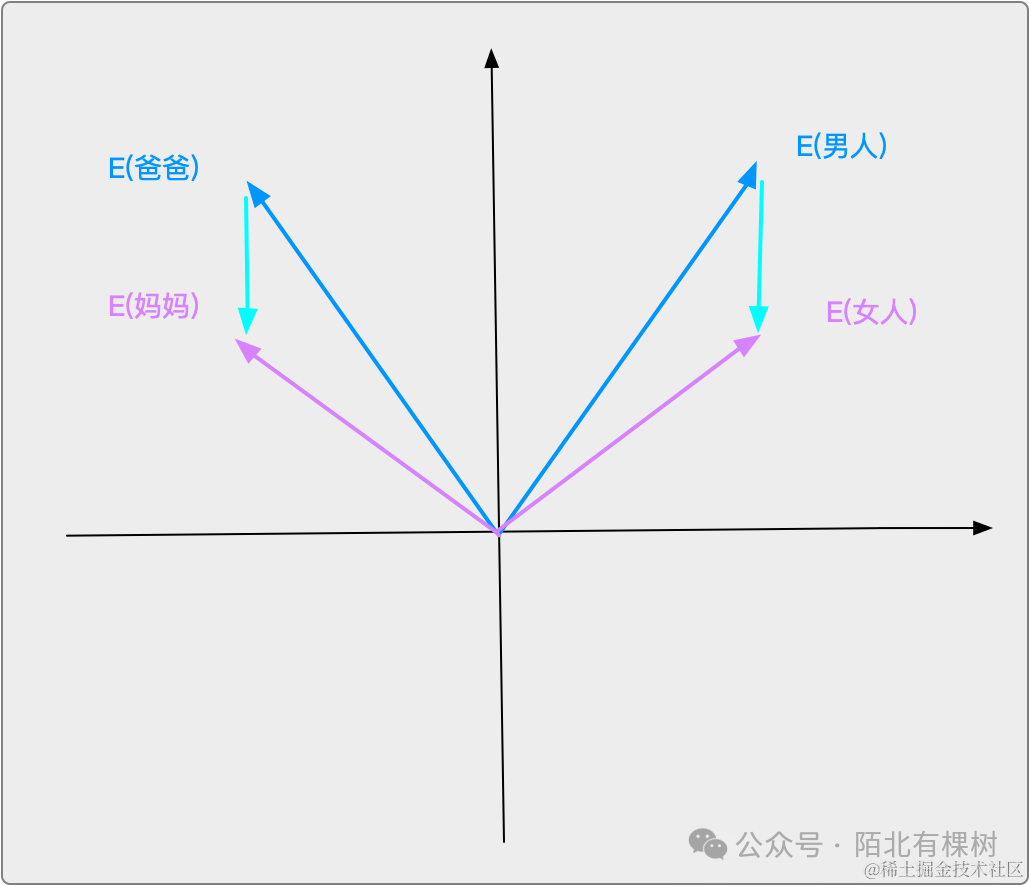
所以,整个训练过程可以描述如下:先将词表里面的词(Token)随机分布在这个向量空间中,然后根据输入的语料,不断调整每个词(Token)的位置,直到模型损失函数减小到一定范围内,每个词都找到了在空间内的”正确“位置。
前面提到的浅层前馈神经网络,循环神经网络,本质上都是在让每个词找出”正确“的位置,但都或多或少存在一些问题,比如如何更好地将一句话的上下文信息融合到向量的坐标中…
1.2.4.4 注意力机制
自2013年Word2Vec诞生直到现在,每一代模型的目标本质上都是:如何让词语在多维向量空间里找到”正确“的位置,并通过计算位置的相似度完成下一个词词的预测。
由于Transformer的影响力,以至于很多人会将注意力机制和Transformer深深绑定在一起,认为注意力机制是Transformer中首次提出,但其实是有偏差的。
在NLP领域,注意力机制首先被引入用于Seq2Seq模型,Seq2Seq模型具有“编码器-解码器”架构,Seq2Seq模型最广泛的应用场景是机器翻译领域,但其实也可以被应用在序列到序列相关的所有场景。
Seq2Seq模型是2014年Ilya Sutskever等人在论文《Sequence to Sequence Learning with Neural Networks》中提出,接着在2015年,在Yoshua Bengio团队在《Neural Machine Translation by Jointly Learning to Align and Translate》中将注意力机制引入Seq2Seq模型。
所谓注意力机制,简单来说就是对于输入序列,计算出一组能够表达重要性程度的值向量——注意力权重,然后通过这个权重对数据项进行加权求和,此时,应用的还是循环神经网络,只是将注意力机制融入了进去,
1.2.4.5 Transformer
2017年,Transformer以划时代的姿势横空出世,之所以用划时代这个词,是因为以Transformer作为分水岭,在这之前,注意力机制的实现方式都是RNN架构,而在此之后,全部都是基于自注意力机制的Transformer,真的正如Transformer论文的标题《Attention Is All You Need》那样,你只需要注意力机制,还隐藏了后半句,你不再需要RNN了。
利用丰富的训练语料、自监督的预训练任务以及Transformer等深度神经网络结构,使预训练语言模型具备了通用且强大的自然语言表示能力,能够有效地学习到词汇、语法和语义信息。
2018年,BERT和GPT的诞生,标志着开启了基于预训练的语言模型时代,将预训练语言模型应用于下游任务时,不需要了解太多的任务细节,不需要设计特定的神经网络结构,只需要“微调”预训练语言模型,即使用具体任务的标注数据在预训练语言模型上进行监督训练,就可以获得显著的性能提升。
2020年,GPT-3出现,又是一个分界点,从此后进入大语言模型时代。
此后的故事,就是我们正在经历的现在…
虽然GPT的复杂程度,早已非最开始的N-gram所能比,但细究其本质你会发现,两者的工作模式始终未变:根据前面的词去预测后续的词,而这也正是语言模型的核心目标。
关于Transformer的细节以及后面的演进,是本系列的重点,但是由于篇幅原因,不在本篇展开,敬请期待后续…
【关键参考文献】
[1] First Links in the Markov Chain[EB/OL]. [BRIAN HAYES]. www.americanscientist.org/article/first-links-in-the-markov-chain.
[2]Shannon C E. A mathematical theory of communication[J]. The Bell system technical journal, 1948, 27(3): 379-423.
[3] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[4] MIKOLOV T, KARAFIÁT M, BURGET L,et al. Recurrent neural network based Ianguage model.[C]//Interspeech: volume 2.[S.I.]: Makuhari, 2010: 1045-1048.
[5] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
[6] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[J]. Advances in neural information processing systems, 2014, 27.
[7] 张奇 / 桂韬 / 黄萱菁. 自然语言处理导论[M]. 电子工业出版社, 2023-8.
[8] 车万翔 / 崔一鸣 / 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021-7.
[9] Russell S, Norvig P. 人工智能:现代方法(第四版)[M]. 人民邮电出版社, 2022.