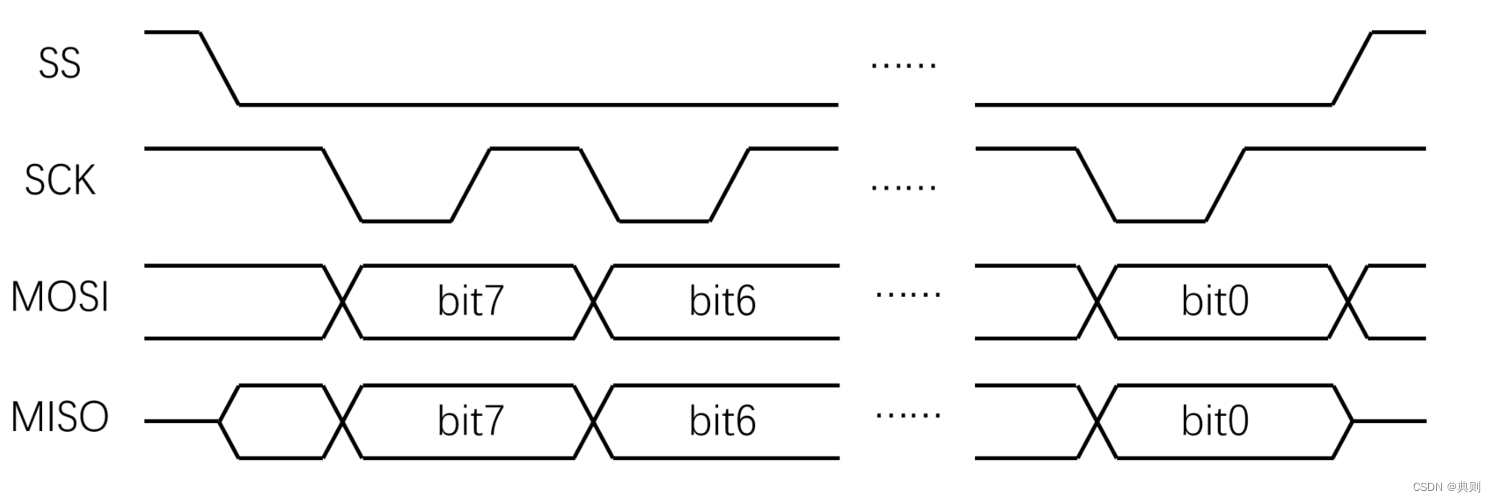
目录
Stabilized Propensity Weights
Pseudo-Populations
Stabilized Propensity Weights
将经过处理的样本按 加权,就会产生一个与原始样本大小相同的伪群体,但就好像每个人都经过了处理。这意味着权重之和与原始样本大小大致相同。同样,对照组的权重为
,创建的伪群体就好像每个人都有对照组一样。
如果您有机器学习背景,您可能会将 IPW 视为重要性抽样的一种应用。在重要度抽样中,您的数据来自原点分布 ,但您希望从目标分布
中进行抽样。将此引入 IPW 的语境,用
对干预进行加权,实质上意味着您正在获取来自
的数据--如果 X 也会导致 Y,那么这些数据就是有偏差的--然后重建
,其中的干预概率不依赖于 X,因为它只是 1。这也解释了为什么重新加权后的样本表现得好像原始样本中的每个人都接受了干预。
另一种方法是注意到干预和未干预的权重之和与原始样本量非常接近:
print("Original Sample Size", data_ps.shape[0])
print("Treated Pseudo-Population Sample Size", sum(weight_t))
print("Untreated Pseudo-Population Sample Size", sum(weight_nt))
Original Sample Size 10391
Treated Pseudo-Population Sample Size 10435.089079197916
Untreated Pseudo-Population Sample Size 10354.298899788304只要权重不是太大,这样做是没有问题的。但如果干预的可能性很小, 就可能很小,这可能会给计算带来一些问题。一个简单的解决方案是使用干预的边际概率
来稳定权重:
有了这些权重,低概率干预的权重就不会很大,因为小分母会被同样小的分子所平衡。这不会改变您之前得到的结果,但在计算上更加稳定。此外,稳定的权重会重建一个伪群体,在这个伪群体中,治疗组和对照组的有效规模(权重之和)分别与原始治疗组和对照组的有效规模相匹配。再次与重要度抽样做个比较,使用稳定化权重,你是来自一个干预取决于 X、 的分布,但重建的是边际
:
p_of_t = data_ps["intervention"].mean()
t1 = data_ps.query("intervention==1")
t0 = data_ps.query("intervention==0")
weight_t_stable = p_of_t/t1["propensity_score"]
weight_nt_stable = (1-p_of_t)/(1-t0["propensity_score"])
print("Treat size:", len(t1))
print("W treat", sum(weight_t_stable))
print("Control size:", len(t0))
print("W treat", sum(weight_nt_stable))
Treat size: 5611
W treat 5634.807508745978
Control size: 4780
W treat 4763.116999421415同样,这种稳定化保持了原始倾向得分的平衡特性。您可以验证它得出的 ATE 估计值与之前的完全相同:
nt = len(t1)
nc = len(t0)
y1 = sum(t1["engagement_score"]*weight_t_stable)/nt
y0 = sum(t0["engagement_score"]*weight_nt_stable)/nc
print("ATE: ", y1 - y0)
ATE: 0.26597870880761176Pseudo-Populations
我已经提到过伪群体,但更好地理解它们将有助于你理解 IPW 如何消除偏差。让我们先从 的角度思考一下偏倚的含义。如果干预是以概率随机分配的,比如说 10%,那么你就知道干预不会依赖于 X,或者说
。如果确实存在这种偏差,那么某些单位获得干预的几率就会更高。例如,与团队参与度不高的管理者相比,已经拥有一支非常投入的团队、非常有激情的管理者更有可能参加培训(
值更高)。
如果按干预状态绘制 的分布图,由于管理人员参加培训的机会不一样(干预不是随机的),因此受干预的个体的
会更高。 从下图左边的图中可以看出,
的干预分布图有点向右偏移:

与右边的图形成对比。这里,在低 区域,治疗单位加权,对照单位减权。同样,当
较高时,治疗单位的权重降低,而对照组的权重提高。这些变化使得两个分布重叠。它们重叠的事实意味着,在加权数据上,干预单位和对照单位获得干预或对照的机会相同。换句话说,干预分配看起来与随机分配一样好(当然,假设没有未观察到的混杂因素)。
这也说明了 IPW 在做什么。通过获取被治疗者的结果 ,并对那些
值较低的结果进行加权,而对那些
值较高的结果进行减权,您就可以得出
的结果。类似的论证还可以说明,通过对对照样本重新加权
,您也在试图了解