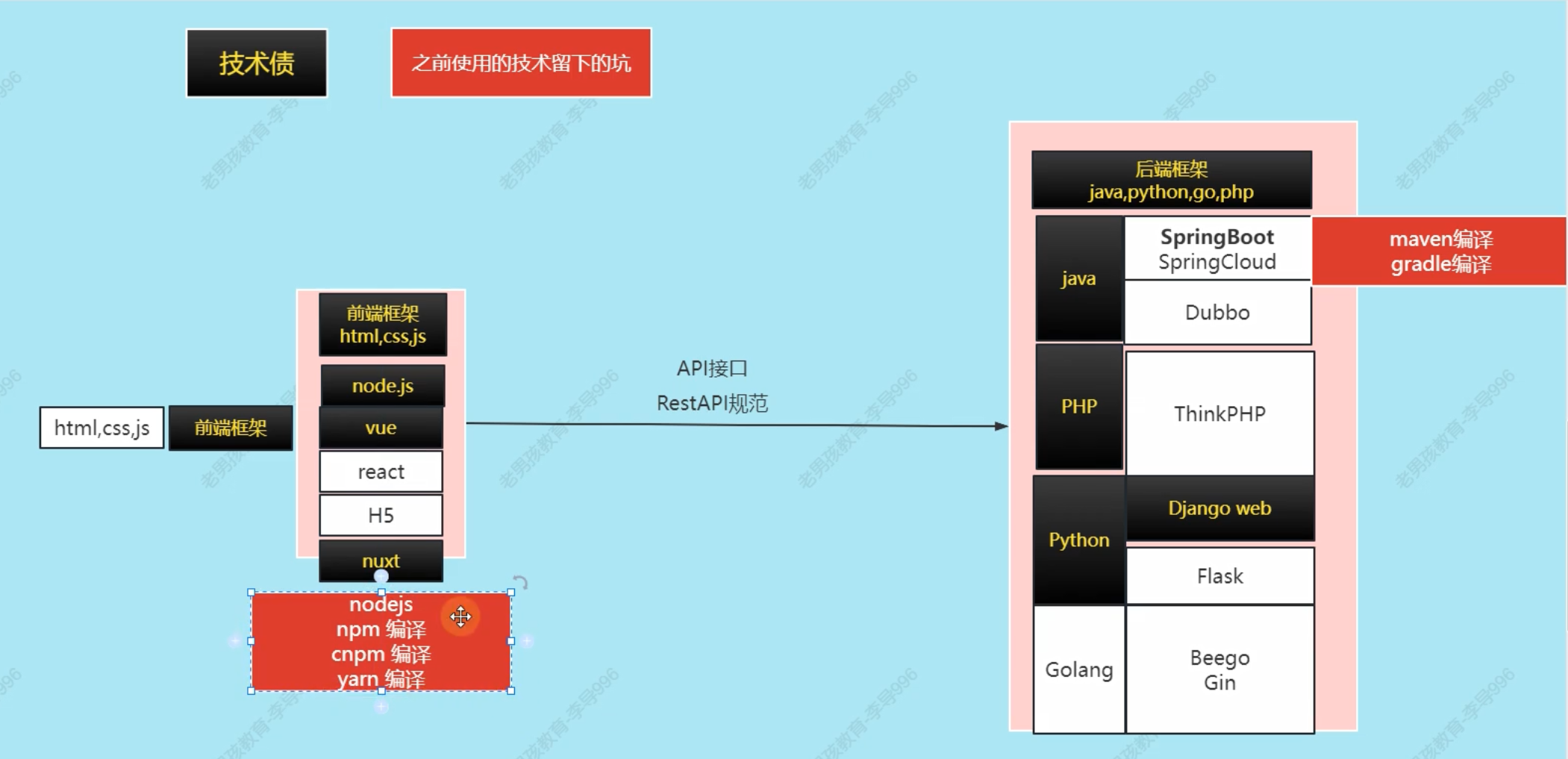
不同类型的链表
专栏内容:
- postgresql使用入门基础
- 手写数据库toadb
- 并发编程
个人主页:我的主页
管理社区:开源数据库
座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物.
文章目录
- 不同类型的链表
- 概述
- 1. 数据类型识别
- 1.1 TLV格式介绍
- 1.2 结构体分层定义
- 1.3 定义抽象数据类型
- 2. 链表定义
- 2.1 数据节点定义
- 2.2 链表类型定义
- 节点解析
- 链表遍历
- 多级树链表
- 总结
- 结尾
概述
在实际使用中,会存在不同的数据类型,有基本类型,有自定义的结构体的复杂类型。
当这么丰富的数据出现时,只能记录到动态扩展的链表中,同时还能够查找,并按正确的类型取出。
本节就来介绍,在同一个链表中如何记录如此丰富的数据资源,分别从
- 数据类型识别;
- 链表的定义;
- 节点解析;
- 链表遍历
四个方面来展开介绍。
1. 数据类型识别
要识别出不同的数据类型,这里介绍一种数据结构的定义格式TLV。
1.1 TLV格式介绍
TLV(tag-length-value)是一种用于以结构化方式表示数据的二进制格式。TLV在计算机网络协议、智能卡应用以及其他数据交换场景中经常被使用。TLV由以下三部分组成:
-
标签(Tag):唯一标识数据的类型。它通常是一个单字节或一小段字节序列, 可以是不同bit代表不同含义,也可以是整体表示序列。
-
长度(Length):数据字段的字节长度。在某些协议中,标签和长度字段的长度也会被包含在内。
-
值(Value):实际传输的数据,可以是任何类型或格式。

这种格式通过明确区分数据的类型、长度和具体内容,使得数据的解析和处理变得更加清晰和高效。
1.2 结构体分层定义
- 首先定义复合类型,一般使用枚举类型进行定义。
在手写数据库toadb的src/sqlcore/node/nodeType.h文件中就有用到这种定义。
这里举例定义如下:
typedef enum NodeType
{
T_START,
/* parser nodes */
T_List,
T_MANAGER,
T_HR,
T_EMPLOYEE
}NodeType;
- 然后在各复合类型的结构定中,前两个字段采用公共字段。
这里定义经理,HR,员工三个结构体类型,每个人都有一个sno员工号的数据,他们的个性化数据有:
- 经理,有管理多少个员工;
- HR,新入职了多少新员工;
- 员工,对应的部门经理的工号;
typedef struct stManager
{
NodeType type;
int size;
int sno;
int employeeNum;
}stManager;
typedef struct stHr
{
NodeType type;
int size;
int sno;
int newEmployeesNum;
}stHr;
typedef struct stEmployee
{
NodeType type;
int size;
int sno;
int partMgr;
}stEmployee;
1.3 定义抽象数据类型
自定义的数据结构太多了,为了在使用中统一和简化,这里定义Node数据类型,是对上述数据类型的统称。
/* common type, real size is just by type. */
typedef struct Node
{
NodeType type;
int size;
}Node;
Node数据结构中包含两个公共的字段,类型和大小。
这样在参数引用,链表节点引用时,都可以用这个抽象的类型来代表以上众多的数据类型。
当然,有这个抽象结构定义之后,ListCell中的数据指针类型可以用Node类型代替,而不是之前定义的void。
2. 链表定义
既然是链表,肯定采用指针的方式串连起来,以往都是定义一种明确的数据类型作为链表的节点。
而面对如此多的数据类型,链表节点的结构如何定义呢?
2.1 数据节点定义
数据节点中存储真实的数据,由链表指针将数据节点串连起来。
它的定义如下:
/* tree list cell */
typedef struct ListCell
{
void* pValue;
struct ListCell *next;
}ListCell;
- 数据类型不确定,所以定义为
void *; - 单链表的形式,
next指向下一个节点;
2.2 链表类型定义
部门的结构是一个多层级形式,每个层级又是多个员工,也是一个链表。
因此,数据类型中,除了实际意义的数据类型,如上面定义的经理,HR,员工外,还需要增加链表的数据类型。
/* tree list node */
typedef struct List
{
NodeType type;
int size;
int length; /* number of ListCell struct */
ListCell *head;
}List;
链表的数据类型中,数据有两个:
- length, 链表中的节点个数;
- head,链表头;
节点解析
数据的多样性,增加了链表节点类型解析工作,因为之前采用了统一类型定义,所以类型的解析变得简单。
采用统一的接口对类型进行解析, 分发到对应的类型进行处理。
static void ShowNode(Node *n)
{
if(NULL == n)
{
return;
}
switch(n->type)
{
case T_List:
ShowNodList(n);
break;
case T_MANAGER:
ShowNodManager(n);
break;
case T_HR:
ShowNodHR(n);
break;
case T_EMPLOYEE:
ShowNodEmployee(n);
break;
default:
break;
}
}
这里定义了一个展示各节点信息的接口,根据节点类型再调用各自的接口进行展示。
链表遍历
经过上面的抽象类型之后,链表的遍历就非常简单,这里以链表的节点的显示为例。
void TravelListCell(List *list)
{
ListCell *tmpCell = NULL;
List *l = list;
if(NULL == l)
{
return;
}
/* list cell node show */
for(tmpCell = l->head; tmpCell != NULL; tmpCell = tmpCell->next)
{
Node *node = (Node *)(tmpCell->pValue);
ShowNode(node);
}
return;
}
说明:
- 传入的是一个List的指针,这里会包含一个链表;
- 从成员head开始遍历,直到链表节点的next为空,也就是链尾;
- 将链表节点的数据成员转为抽象类型Node *, 传入统一的处理接口;
多级树链表
将经理的数据成员增加一项,除了下属成员数量外,还列出下属的员工信息;
typedef struct stManager
{
NodeType type;
int size;
int sno;
int employeeNum;
Node *employeeList;
}stManager;
这里有个特别的地方,对于T_List类型的数据,内部会递归调用TravelListCell,这样就是一个多级链表树。

如同一个公司的组织架构一样,顶层由HR,高级经理列表组成,每个高级经理下属由员工,中级经理组成;
而中级经理下属由多名员工组成,整体组成一个公司的树形组织架构图。
对于T_LIst类型的节点,它的显示处理函数如下:
void ShowNodList(Node *n)
{
if(NULL == n)
return ;
TravelListCell((List *) n);
}
其实是深度优先的图递归遍历,其它数据节点的显示就相对简单,打印成员信息即可,这里不再列举。
总结
本文介绍了链表节点为不同数据类型时的处理方法,定义了抽象类型后使引用的类型统一,同时在遍历树形链表时,对于成员仍为链表时,采用深度优先的递归遍历。
这种链表在数据库内核中应用比较广泛,比如在SQL语法解析时,将语法的各子句解析成不同的数据类型,而像select子句,可以写多个列名,该子句内部又以链表形成存储列信息。
结尾
非常感谢大家的支持,在浏览的同时别忘了留下您宝贵的评论,如果觉得值得鼓励,请点赞,收藏,我会更加努力!
作者邮箱:study@senllang.onaliyun.com
如有错误或者疏漏欢迎指出,互相学习。
注:未经同意,不得转载!