训练营进入第十四天,今天学的内容是Pix2Pix图像转换,记录一下学习内容:
Pix2Pix概述
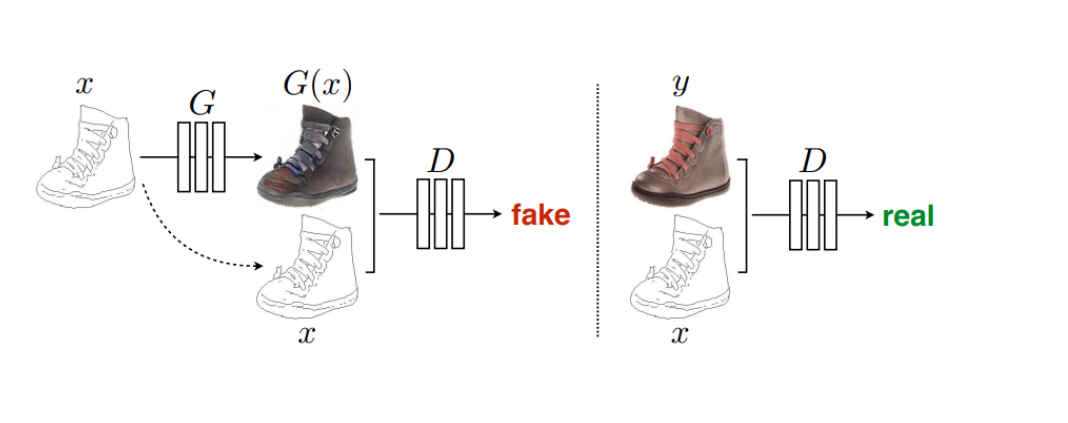
Pix2Pix是基于条件生成对抗网络(cGAN, Condition Generative Adversarial Networks )实现的一种深度学习图像转换模型,该模型是由Phillip Isola等作者在2017年CVPR上提出的,可以实现语义/标签到真实图片、灰度图到彩色图、航空图到地图、白天到黑夜、线稿图到实物图的转换。Pix2Pix是将cGAN应用于有监督的图像到图像翻译的经典之作,其包括两个模型:生成器和判别器。
传统上,尽管此类任务的目标都是相同的从像素预测像素,但每项都是用单独的专用机器来处理的。而Pix2Pix使用的网络作为一个通用框架,使用相同的架构和目标,只在不同的数据上进行训练,即可得到令人满意的结果,鉴于此许多人已经使用此网络发布了他们自己的艺术作品。
基础原理
cGAN的生成器与传统GAN的生成器在原理上有一些区别,cGAN的生成器是将输入图片作为指导信息,由输入图像不断尝试生成用于迷惑判别器的“假”图像,由输入图像转换输出为相应“假”图像的本质是从像素到另一个像素的映射,而传统GAN的生成器是基于一个给定的随机噪声生成图像,输出图像通过其他约束条件控制生成,这是cGAN和GAN的在图像翻译任务中的差异。Pix2Pix中判别器的任务是判断从生成器输出的图像是真实的训练图像还是生成的“假”图像。在生成器与判别器的不断博弈过程中,模型会达到一个平衡点,生成器输出的图像与真实训练数据使得判别器刚好具有50%的概率判断正确。
在教程开始前,首先定义一些在整个过程中需要用到的符号:
- x x x:代表观测图像的数据。
- z z z:代表随机噪声的数据。
- y = G ( x , z ) y=G(x,z) y=G(x,z):生成器网络,给出由观测图像 x x x与随机噪声 z z z生成的“假”图片,其中 x x x来自于训练数据而非生成器。
- D ( x , G ( x , z ) ) D(x,G(x,z)) D(x,G(x,z)):判别器网络,给出图像判定为真实图像的概率,其中 x x x来自于训练数据, G ( x , z ) G(x,z) G(x,z)来自于生成器。
cGAN的目标可以表示为:
L c G A N ( G , D ) = E ( x , y ) [ l o g ( D ( x , y ) ) ] + E ( x , z ) [ l o g ( 1 − D ( x , G ( x , z ) ) ) ] L_{cGAN}(G,D)=E_{(x,y)}[log(D(x,y))]+E_{(x,z)}[log(1-D(x,G(x,z)))] LcGAN(G,D)=E(x,y)[log(D(x,y))]+E(x,z)[log(1−D(x,G(x,z)))]
该公式是cGAN的损失函数,D想要尽最大努力去正确分类真实图像与“假”图像,也就是使参数
l
o
g
D
(
x
,
y
)
log D(x,y)
logD(x,y)最大化;而G则尽最大努力用生成的“假”图像
y
y
y欺骗D,避免被识破,也就是使参数
l
o
g
(
1
−
D
(
G
(
x
,
z
)
)
)
log(1−D(G(x,z)))
log(1−D(G(x,z)))最小化。cGAN的目标可简化为:
a r g min G max D L c G A N ( G , D ) arg\min_{G}\max_{D}L_{cGAN}(G,D) argGminDmaxLcGAN(G,D)
为了对比cGAN和GAN的不同,我们将GAN的目标也进行了说明:
L G A N ( G , D ) = E y [ l o g ( D ( y ) ) ] + E ( x , z ) [ l o g ( 1 − D ( x , z ) ) ] L_{GAN}(G,D)=E_{y}[log(D(y))]+E_{(x,z)}[log(1-D(x,z))] LGAN(G,D)=Ey[log(D(y))]+E(x,z)[log(1−D(x,z))]
从公式可以看出,GAN直接由随机噪声 z z z生成“假”图像,不借助观测图像 x x x的任何信息。过去的经验告诉我们,GAN与传统损失混合使用是有好处的,判别器的任务不变,依旧是区分真实图像与“假”图像,但是生成器的任务不仅要欺骗判别器,还要在传统损失的基础上接近训练数据。假设cGAN与L1正则化混合使用,那么有:
L L 1 ( G ) = E ( x , y , z ) [ ∣ ∣ y − G ( x , z ) ∣ ∣ 1 ] L_{L1}(G)=E_{(x,y,z)}[||y-G(x,z)||_{1}] LL1(G)=E(x,y,z)[∣∣y−G(x,z)∣∣1]
进而得到最终目标:
a r g min G max D L c G A N ( G , D ) + λ L L 1 ( G ) arg\min_{G}\max_{D}L_{cGAN}(G,D)+\lambda L_{L1}(G) argGminDmaxLcGAN(G,D)+λLL1(G)
图像转换问题本质上其实就是像素到像素的映射问题,Pix2Pix使用完全一样的网络结构和目标函数,仅更换不同的训练数据集就能分别实现以上的任务。本任务将借助MindSpore框架来实现Pix2Pix的应用。
准备环节
配置环境文件
本案例在GPU,CPU和Ascend平台的动静态模式都支持。
准备数据
在本教程中,我们将使用指定数据集,该数据集是已经经过处理的外墙(facades)数据,可以直接使用mindspore.dataset的方法读取。
数据展示
调用Pix2PixDataset和create_train_dataset读取训练集,这里我们直接下载已经处理好的数据集。
from mindspore import dataset as ds
import matplotlib.pyplot as plt
dataset = ds.MindDataset("./dataset/dataset_pix2pix/train.mindrecord", columns_list=["input_images", "target_images"], shuffle=True)
data_iter = next(dataset.create_dict_iterator(output_numpy=True))
# 可视化部分训练数据
plt.figure(figsize=(10, 3), dpi=140)
for i, image in enumerate(data_iter['input_images'][:10], 1):
plt.subplot(3, 10, i)
plt.axis("off")
plt.imshow((image.transpose(1, 2, 0) + 1) / 2)
plt.show()
创建网络
当处理完数据后,就可以来进行网络的搭建了。网络搭建将逐一详细讨论生成器、判别器和损失函数。生成器G用到的是U-Net结构,输入的轮廓图 x x x编码再解码成真是图片,判别器D用到的是作者自己提出来的条件判别器PatchGAN,判别器D的作用是在轮廓图 x x x的条件下,对于生成的图片 G ( x ) G(x) G(x)判断为假,对于真实判断为真。
生成器G结构
U-Net是德国Freiburg大学模式识别和图像处理组提出的一种全卷积结构。它分为两个部分,其中左侧是由卷积和降采样操作组成的压缩路径,右侧是由卷积和上采样组成的扩张路径,扩张的每个网络块的输入由上一层上采样的特征和压缩路径部分的特征拼接而成。网络模型整体是一个U形的结构,因此被叫做U-Net。和常见的先降采样到低维度,再升采样到原始分辨率的编解码结构的网络相比,U-Net的区别是加入skip-connection,对应的feature maps和decode之后的同样大小的feature maps按通道拼一起,用来保留不同分辨率下像素级的细节信息。
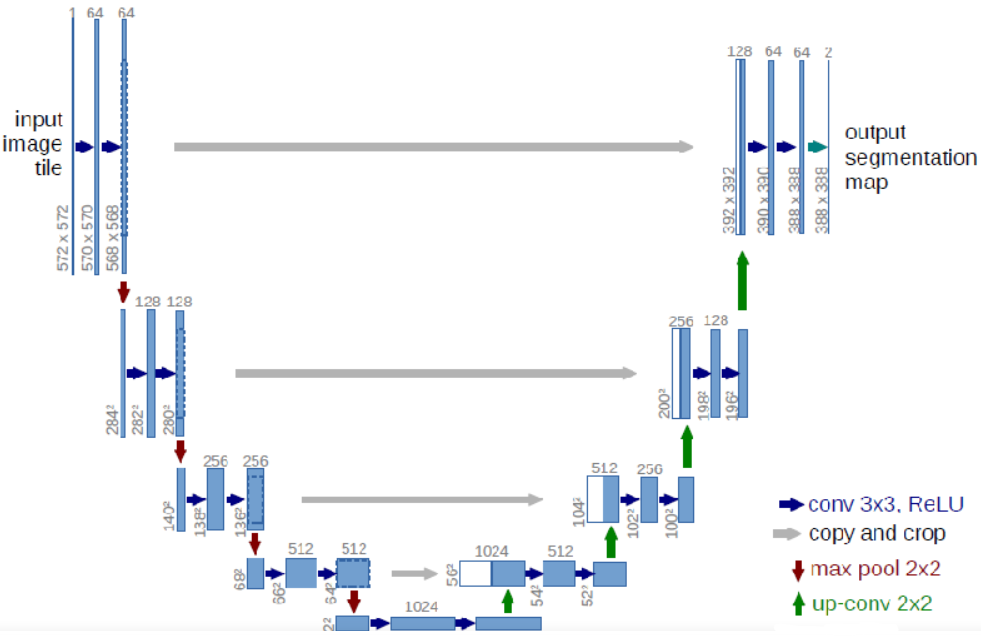
定义UNet Skip Connection Block
基于UNet的生成器
原始cGAN的输入是条件x和噪声z两种信息,这里的生成器只使用了条件信息,因此不能生成多样性的结果。因此Pix2Pix在训练和测试时都使用了dropout,这样可以生成多样性的结果。
基于PatchGAN的判别器
判别器使用的PatchGAN结构,可看做卷积。生成的矩阵中的每个点代表原图的一小块区域(patch)。通过矩阵中的各个值来判断原图中对应每个Patch的真假。
Pix2Pix的生成器和判别器初始化
实例化Pix2Pix生成器和判别器。
训练
训练分为两个主要部分:训练判别器和训练生成器。训练判别器的目的是最大程度地提高判别图像真伪的概率。训练生成器是希望能产生更好的虚假图像。在这两个部分中,分别获取训练过程中的损失,并在每个周期结束时进行统计。
推理
获取上述训练过程完成后的ckpt文件,通过load_checkpoint和load_param_into_net将ckpt中的权重参数导入到模型中,获取数据进行推理并对推理的效果图进行演示(由于时间问题,训练过程只进行了3个epoch,可根据需求调整epoch)。
各数据集分别推理的效果如下