一、目录
- 算法模型介绍
- 模型使用训练
- 模型评估
- 项目扩展
二、算法模型介绍
图像识别是计算机视觉领域的重要研究方向,它在人脸识别、物体检测、图像分类等领域有着广泛的应用。随着移动设备的普及和计算资源的限制,设计高效的图像识别算法变得尤为重要。MobileNetV2是谷歌(Google)团队在2018年提出的一种轻量级卷积神经网络模型,旨在在保持准确性的前提下,极大地减少模型的参数数量和计算复杂度,从而适用于移动设备和嵌入式系统等资源受限的场景。
背景:
MobileNetV2是MobileNet系列的第二代模型,而MobileNet系列是谷歌团队专门针对移动设备和嵌入式系统开发的一系列轻量级卷积神经网络。MobileNetV2是MobileNetV1的改进版本,它在保持轻量级特性的同时,进一步提高了模型的准确性和效率。
MobileNetV2算法的提出旨在应对传统卷积神经网络在移动设备上表现不佳的问题,如大量的计算量和参数数量,导致模型无法在资源受限的环境中高效运行。
原理:
MobileNetV2算法通过一系列技术策略来实现高效的图像识别。主要包括:
1. 基础构建块:倒残差结构
MobileNetV2使用了一种称为“倒残差结构”的基础构建块,即Inverted Residual Block。这种结构与传统的残差块相反,通过先降维(用1x1卷积减少通道数)再升维(用3x3深度可分离卷积增加通道数),以实现轻量化和模型复杂度的降低。
2. 激活函数:线性整流线性单元(ReLU6)
MobileNetV2采用了ReLU6作为激活函数,相比于传统的ReLU函数,ReLU6在负值部分输出为0,在正值部分输出为最大值6,使得模型更容易训练且更加鲁棒。
3. 深度可分离卷积
MobileNetV2广泛采用深度可分离卷积(Depthwise Separable Convolution),将标准卷积操作分解为深度卷积和逐点卷积,从而大大减少了计算量和参数数量。
4. 网络架构设计
MobileNetV2通过引入多个不同分辨率的特征图来构建网络。在不同层级上使用这些特征图,使得网络能够在不同尺度下学习到图像的语义特征,提高了图像识别的准确性。
应用:
MobileNetV2由于其轻量级特性和高效的计算能力,被广泛应用于移动设备和嵌入式系统上的图像识别任务。在实际应用中,我们可以使用预训练的MobileNetV2模型,将其迁移到特定的图像识别任务中,从而在资源有限的情况下实现高质量的图像识别。
MobileNetV2在图像分类、目标检测、人脸识别等任务中表现出色,成为了移动端图像识别的首选算法之一。
三、模型使用和训练
在本文中为了演示如何实现一个图像识别分类系统,通过选取了5种常见的水果数据集,其文件夹结构如下图所示。


在完成数据集的收集准备后,打开jupyter notebook平台,导入数据集通过以下代码可以计算出数据集的总图片数量。本次使用的数据集总图片约为400张。
import pathlib
data_dir = "./dataset/"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)
然后通过构建算法模型,由于在TensorFlow中内置了MobileNetV2预训练模型,所以我们可以直接导入该模型。

这段代码的作用是构建一个基于MobileNetV2的图像识别模型,并加载预训练的权重,同时冻结MobileNetV2的卷积部分的权重。后续可以在此基础上进行微调(Fine-tuning),训练该模型以适应特定的图像识别任务。
然后导入训练集、测试集指定其迭代次数,开始训练。
history = model.fit(train_ds,
validation_data=val_ds,
epochs=30
)
其训练过程如下图所示:

四、模型评估
如下图所示,通过命令查看最后通过model.save方法保存好的模型大小。

模型相比ResNet系列,VGG系列等动辄好几百M的大小相比缩小了许多,便于移动设备的移植安装。
通过打印LOSS图和ACC曲线图观察其模型训练过程,如下图所示。


五、项目扩展
在完成模型训练后,通过model.save方法保存模型为本地文件,然后就可以基于改模型开发出非常多的应用了,比如开发出API接口给别人调用等。
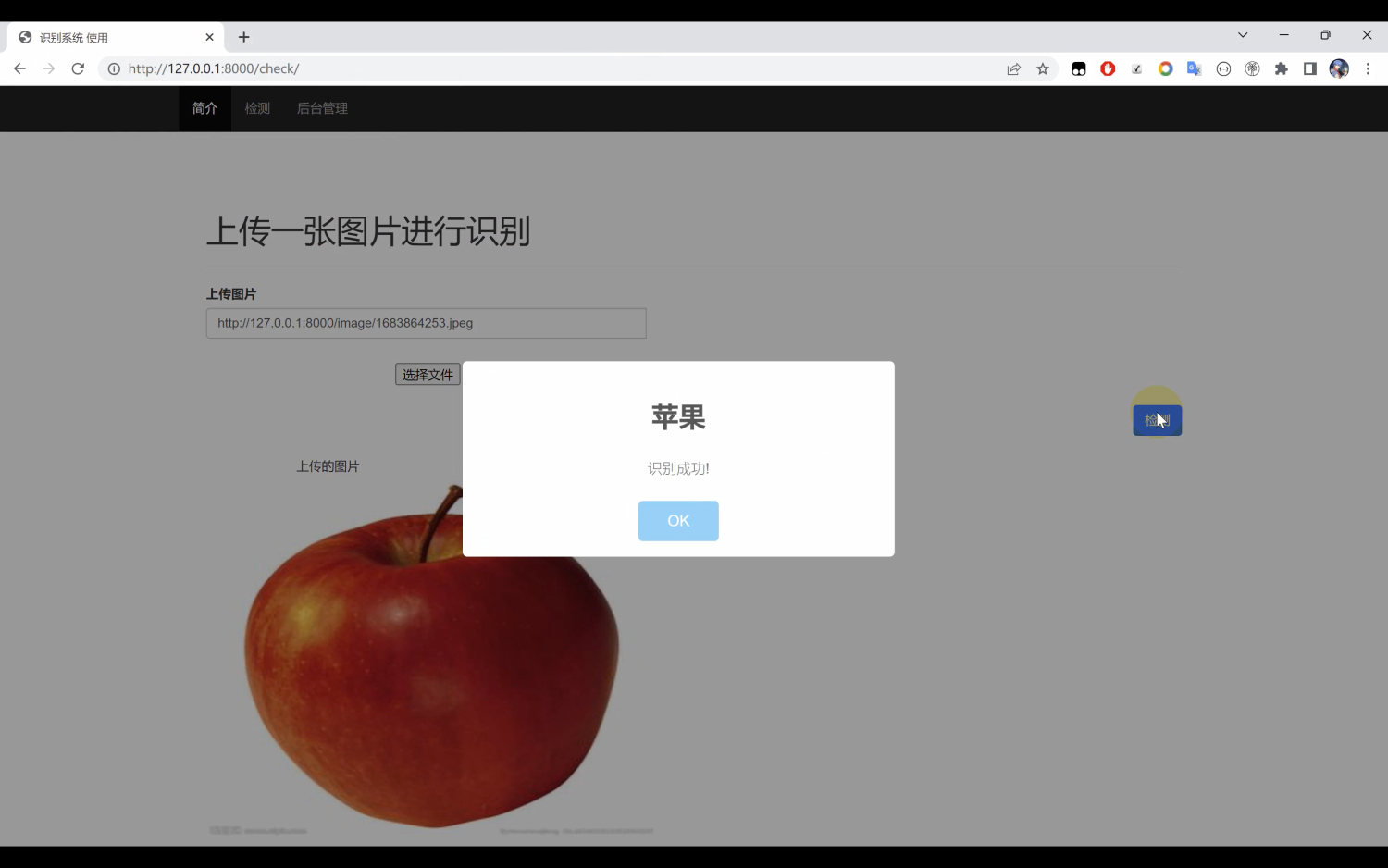
在本项目中基于Django框架开发了一个网页版的识别界面,在该网页界面系统中,用户可以点击鼠标上传一张图片,然后点击按钮进行检测。同时可以将相关识别的相关信息保存在数据库中,管理员通过登录后台可以查看所有的识别信息,为模型优化提供数据支持。
演示视频+代码:
https://www.yuque.com/ziwu/yygu3z/sr43e6q0wormmfpv