前言
mysql用count方法查全表数据,在不同的存储引擎里实现不同,myisam有专门字段记录全表的行数,直接读这个字段就好了。而innodb则需要一行行去算。
比如说,你有一张短信表(sms),里面放了各种需要发送的短信信息。
sms建表sql:
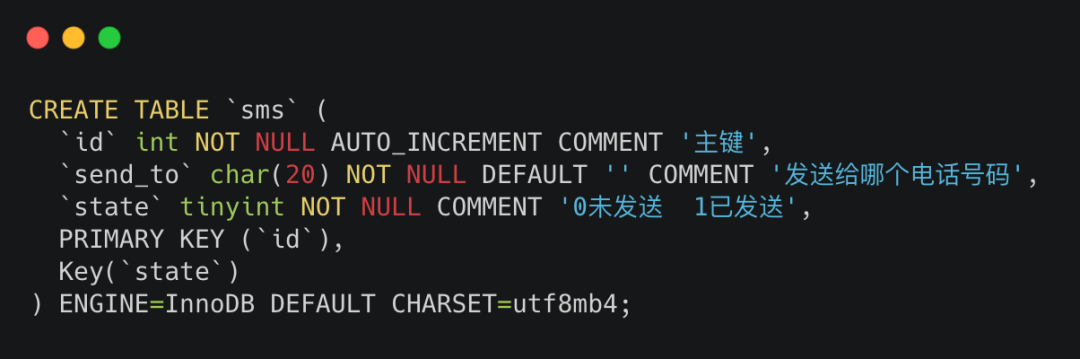
sms表;

需要注意的是state字段,为0的时候说明这时候短信还未发送。
此时还会有一个异步线程不断的捞起未发送(state=0)的短信数据,执行发短信操作,发送成功之后state字段会被置为1(已发送)。也就是说未发送的数据会不断变少。
异步线程发送短信:
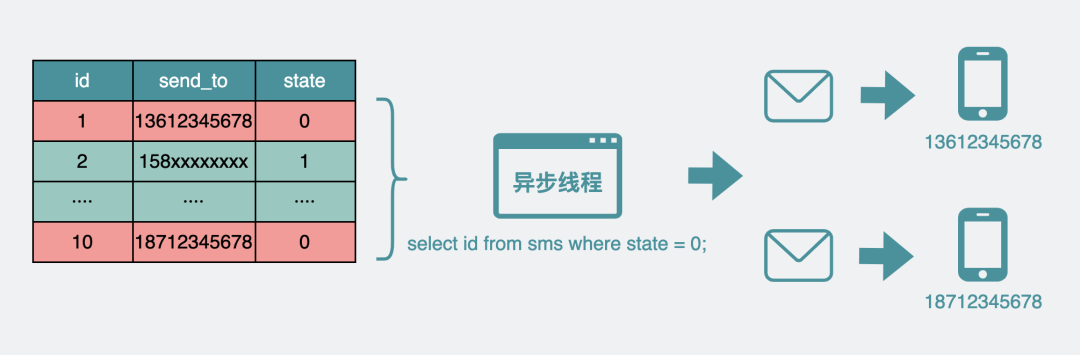
假设由于某些原因,你现在需要做一些监控,比如监控的内容是,你的sms数据表里还有没有state=0(未发送)的短信,方便判断一下堆积的未发送短信大概在什么样的一个量级。
为了获取满足某些条件的行数是多少,我们一般会使用count()方法。
这时候为了获取未发送的短信数据,我们很自然就想到了使用下面的sql语句进行查询。
| 1 |
|
然后再把获得数据作为打点发给监控服务。
当数据表小的时候,这是没问题的,但当数据量大的时候,比如未发送的短信到了百万量级的时候,你就会发现,上面的sql查询时间会变得很长,最后timeout报错,查不出结果了。
为什么?
我们先从count()方法的原理聊起。
count()的原理
count()方法的目的是计算当前sql语句查询得到的非NULL的行数。
我们知道mysql是分为server层和存储引擎层的。
Mysql架构:
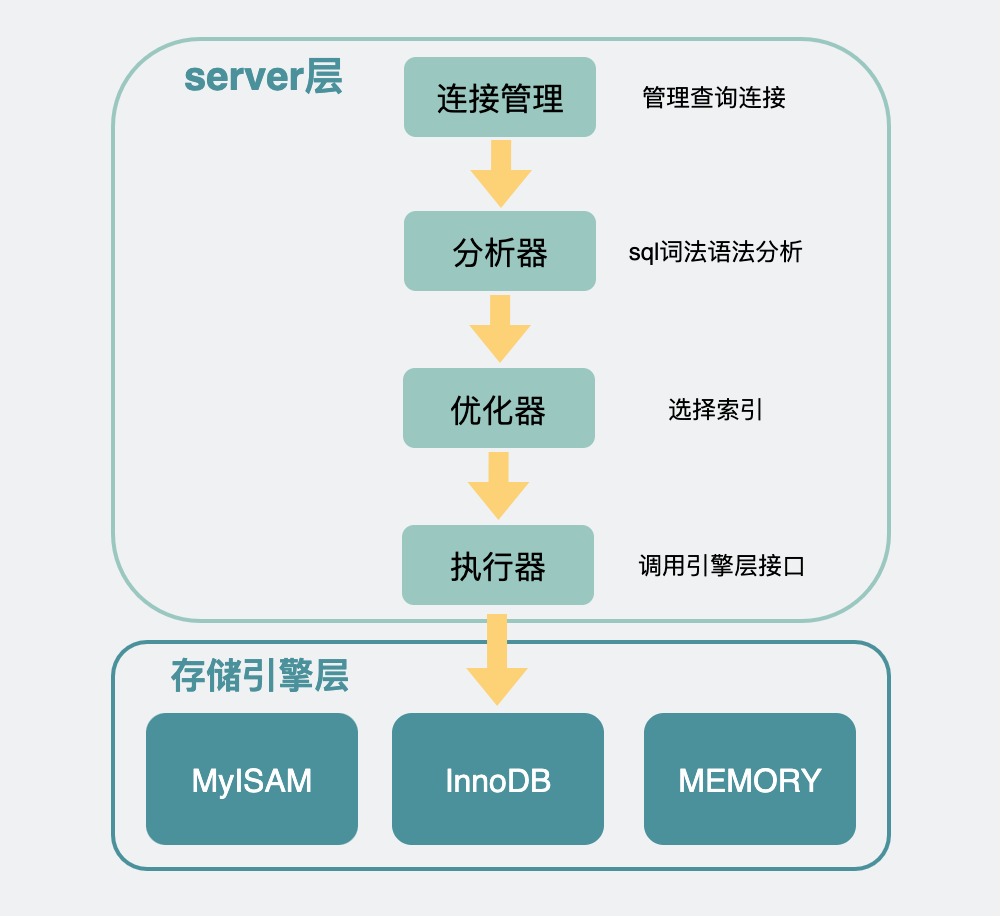
存储引擎层里可以选择各种引擎进行存储,最常见的是innodb、myisam。具体使用哪个存储引擎,可以通过建表sql里的ENGINE字段进行指定。比如这篇文章开头的建表sql里用了ENGINE=InnoDB,那这张表用的就是innodb引擎。
虽然在server层都叫count()方法,但在不同的存储引擎下,它们的实现方式是有区别的。
比如同样是读全表数据 select count(*) from sms;语句。
使用 myisam引擎的数据表里有个记录当前表里有几行数据的字段,直接读这个字段返回就好了,因此速度快得飞起。
而使用innodb引擎的数据表,则会选择体积最小的索引树,然后通过遍历叶子节点的个数挨个加起来,这样也能得到全表数据。
因此回到文章开头的问题里,当数据表行数变大后,单次count就需要扫描大量的数据,因此很可能就会出现超时报错。
那么问题就来了。
为什么innodb不能像myisam那样实现count()方法
myisam和innodb这两个引擎,有几个比较明显的区别,这个是八股文常考了。
其中最大的区别在于myisam不支持事务,而innodb支持事务。
而事务,有四层隔离级别,其中默认隔离级别就是可重复读隔离级别(RR)。
四层隔离级别:
innodb引擎通过MVCC实现了可重复隔离级别,事务开启后,多次执行同样的select快照读,要能读到同样的数据。
于是我们看个例子:为什么innodb不单独记录表行数?

对于两个事务A和B,一开始sms表假设就2条数据,那事务A一开始确实是读到2条数据。事务B在这期间插入了1条数据,按道理数据库其实有3条数据了,但由于可重复读的隔离级别,事务A依然还是只能读到2条数据。
因此由于事务隔离级别的存在,不同的事务在同一时间下,看到的表内数据行数是不一致的,因此innodb,没办法,也没必要像myisam那样单纯的加个count字段信息在数据表上。
那如果不可避免要使用count(),有没有办法让它快一点?
各种count()方法的原理
count()的括号里,可以放各种奇奇怪怪的东西,想必大家应该看过,比如放个星号*,放个1,放个索引列啥的。
我们来分析下他们的执行流程。
count方法的大原则是server层会从innodb存储引擎里读来一行行数据,并且只累计非null的值。但这个过程,根据count()方法括号内的传参,有略有不同。
count(*):server层拿到innodb返回的行数据,不对里面的行数据做任何解析和判断,默认取出的值肯定都不是null,直接行数+1。
count(1):server层拿到innodb返回的行数据,每行放个1进去,默认不可能为null,直接行数+1.
count(某个列字段):由于指明了要count某个字段,innodb在取数据的时候,会把这个字段解析出来返回给server层,所以会比count(1)和count(*)多了个解析字段出来的流程。
如果这个列字段是主键id,主键是不可能为null的,所以server层也不用判断是否为null,innodb每返回一行,行数结果就+1.
如果这个列是普通索引字段,innodb一般会走普通索引,每返回一行数据,server层就会判断这个字段是否为null,不是null的情况下+1。当然如果建表sql里字段定义为not null的话,那就不用做这一步判断直接+1。
如果这个列没有加过索引,那innodb可能会全表扫描,返回的每一行数据,server层都会判断这个字段是否为null,不是null的情况下+1。同上面的情况一样,字段加了not null也就省下这一步判断了。
理解了原理后我们大概可以知道他们的性能排序是
| 1 |
|
所以说count(*),已经是最快的了。
知道真相的我眼泪掉下来。
那有没有其他更好的办法?
允许粗略估计行数的场景
我们回过头来细品下文章开头的需求,我们只是希望知道数据库里还有多少短信是堆积在那没发的,具体是1k还是2k其实都是差不多量级,等到了百万以上,具体数值已经不重要了,我们知道它现在堆积得很离谱,就够了。因此这个场景,其实是允许使用比较粗略的估计的。
那怎么样才能获得粗略的数值呢?
还记得我们平时为了查看sql执行计划用的explain命令不。
其中有个rows,会用来估计接下来执行这条sql需要扫描和检查多少行。它是通过采样的方式计算出来的,虽然会有一定的偏差,但它能反映一定的数量级。
explain里的rows
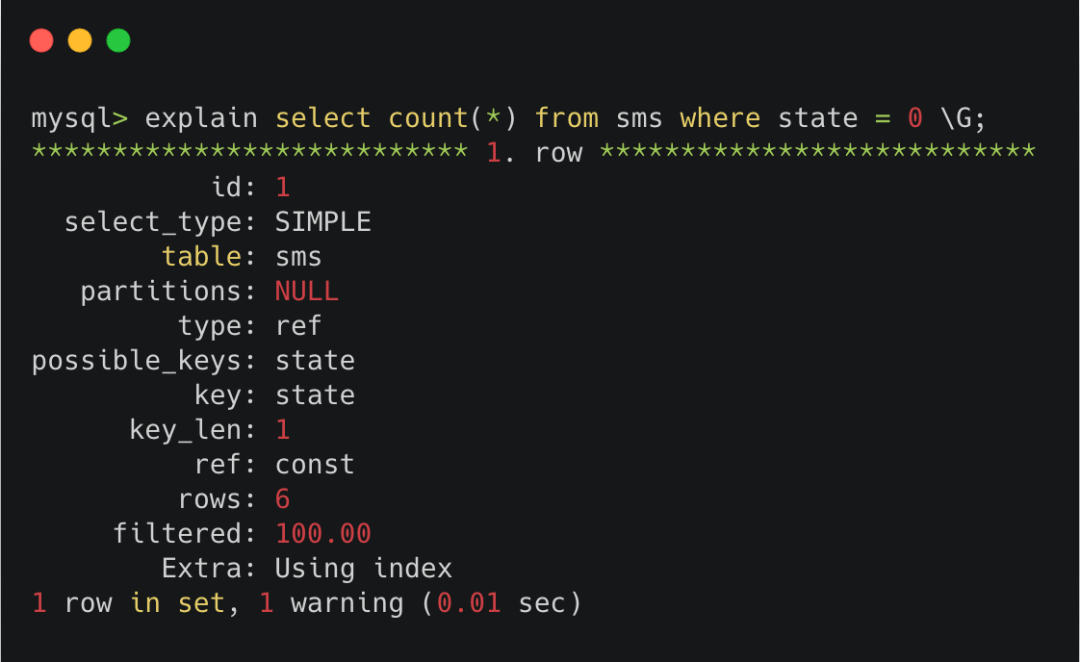
有些语言的orm里可能没有专门的explain语法,但是肯定有执行raw sql的功能,你可以把explain语句当做raw sql传入,从返回的结果里将rows那一列读出来使用。
一般情况下,explain的sql如果能走索引,那会比不走索引的情况更准 。单个字段的索引会比多个字段组成的复合索引要准。索引区分度越高,rows的值也会越准。
这种情况几乎满足大部分的监控场景。但总有一些场景,它要求必须得到精确的行数,这种情况该怎么办呢?
必须精确估计行数的场景
这种场景就比较头疼了,但也不是不能做。
我们可以单独拉一张新的数据库表,只为保存各种场景下的count。
| 1 2 3 4 5 6 7 |
|
count_table表保存各种场景下的count
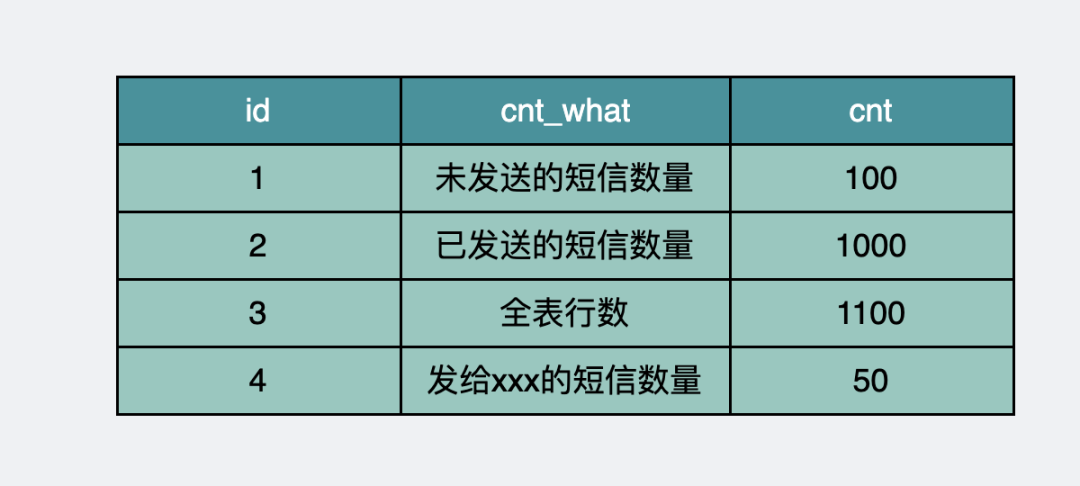
当需要获取某个场景下的cout值时,可以使用下面的sql进行直接读取,快得飞起。
| 1 |
|
那这些count的结果值从哪来呢?这里分成两种情况。
实时性要求较高的场景
如果你对这个cnt计算结果的实时性要求很高,那你需要将更新cnt的sql加入到对应变更行数的事务中。比如我们有两个事务A和B,分别是增加未发送短信和减少未发送短信。
将更改表行数的操作放入到事务里
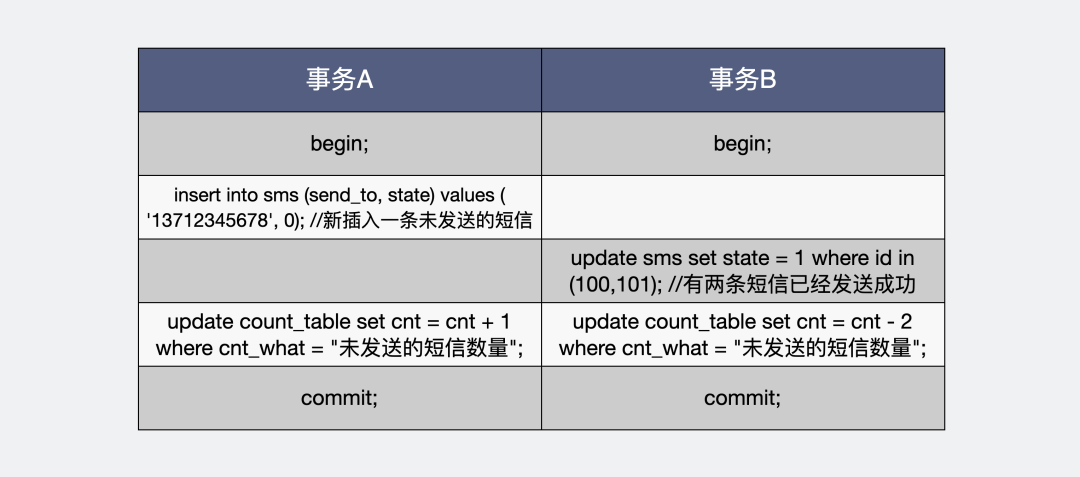
这样做的好处是事务内的cnt行数依然符合隔离级别,事务回滚的时候,cnt的值也会跟着回滚。
坏处也比较明显,多个线程对同一个cnt进行写操作,会触发悲观锁,多个线程之间需要互相等待。对于高频写的场景,性能会有折损。
实时性没那么高的场景
如果实时性要求不高的话,比如可以一天一次,那你可以通过全表扫描后做计算。
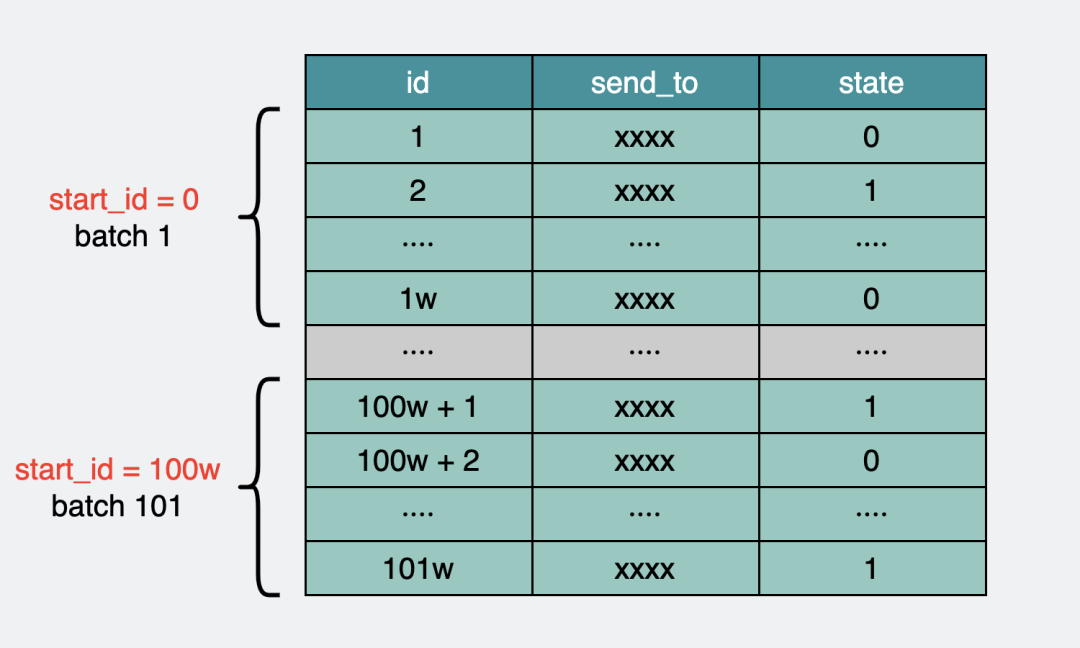
举个例子,比如上面的短信表,可以按id排序,每次取出1w条数据,记下这一批里最大的id,然后下次从最大id开始再拿1w条数据出来,不断循环。
对于未发送的短信,就只需要在捞出的那1w条数据里,筛选出state=0的条数。
batch分批获取短信表
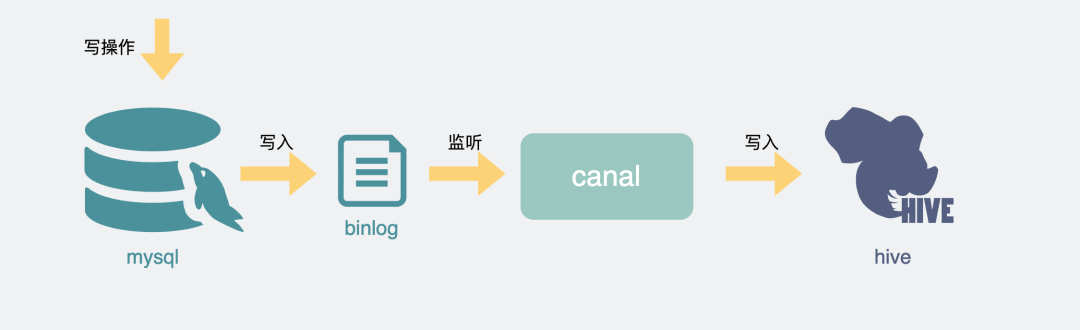
当然如果有条件,这种场景最好的方式还是消费binlog将数据导入到hive里,然后在hive里做查询,不少公司也已经有现成的组件可以做这种事情,不用自己写脚本,岂不美哉。
mysql同步hive
总结
mysql用count方法查全表数据,在不同的存储引擎里实现不同,myisam有专门字段记录全表的行数,直接读这个字段就好了。而innodb则需要一行行去算。
性能方面 count(*) ≈ count(1) > count(主键id) > count(普通索引列) > count(未加索引列),但哪怕是性能最好的count(*),由于实现上就需要一行行去算,所以数据量大的时候就是不给力。
如果确实需要获取行数,且可以接受不那么精确的行数(只需要判断大概的量级)的话,那可以用explain里的rows,这可以满足大部分的监控场景,实现简单。
如果要求行数准确,可以建个新表,里面专门放表行数的信息。
如果对实时性要求比较高的话,可以将更新行数的sql放入到对应事务里,这样既能满足事务隔离性,还能快速读取到行数信息。
如果对实时性要求不高,接受一小时或者一天的更新频率,那既可以自己写脚本遍历全表后更新行数信息。也可以将通过监听binlog将数据导入hive,需要数据时直接通过hive计算得出。